使用Dataset创建和读取数据集,作为TensorFlow模型创建输入管道的新方式,使用性能比使用feed_dict或队列式管道的性能高很多,使用也更加简洁容易。也是google强烈推荐的数据读取方式,对于TensorFlow而言,十分重要。
Dataset是什么?
Dataset的定义 : 它是一个含有相同类型元素且有序的可迭代对象。为了方便理解,也可以看作是相同类型元素的有序列表。实际使用时,单个元素可以是向量,也可以是字符串、图片,甚至是数组或者字典。
Dataset的作用 : 为了更加高效便携的读取数据。读取数据的过程中,它可以从内存或者硬盘文件中读取加载数据组成数据集(Dataset),并同时对数据集进行一系列变换操作,最终将数据集提供给其他API使用。
Google官方给出的Dataset API是由以下图中所示的类组成:
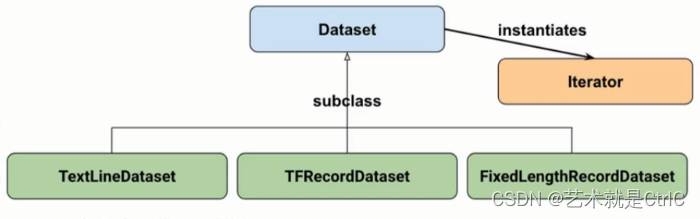
Dataset有三个子类,分别是TextLineDataset、TFRecordDataset、FixedLengthRecordDataset,实例化类是迭代器Iterator。其中TextLineDataset用于读取文本数据,TFRecordDataset用于读取tfrecord数据,FixedLengthRecordDataset用于读取二进制文件数据。
使用方法如下:
tf.data.TFRecordDataset(filenames,compression_type = None,buffer_size = None,num_parallel_reads = None)
tf.data.TextLineDataset(filenames,compression_type = None,buffer_size = None,num_parallel_reads = None)
tf.data.FixedLengthRecordDataset(filenames,record_bytes,header_bytes = None,footer_bytes = None,buffer_size = None,compression_type = None,num_parallel_reads = None)
TextLineDataset和TFRecordDataset只需要输入文件名即可,FixedLengthRecordDataset需要输入文件名和每个样本的字节长度。
除此之外,还有一种加载数据生成Dataset的方式,即从内存中获取数据源构造dataset,常用的方法有:tf.data.Dataset.range()、tf.data.Dataset.from_tensors()或者tf.data.Dataset.from_tensor_slices()
Dataset数据的转换
在初步构建生成一个dataset后,可以根据需要,通过Transformation将其转换成一个新的Dataset。转换过程中,可以对原先的Dataset进行数据变换(map),打乱(shuffle),重复(repeat),组成一批数据(batch)等一系列操作。
数据变换(map)操作:
map操作接收的参数是一个函数,Dataset中的每个元素都会被当作该函数的输入,通过函数运行,最终将函数返回值作为新的Dataset。
示例代码如下:
import tensorflow as tf
def fun(x,arg):
return x * arg
var = tf.constant(3,dtype = tf.int64)
ds1 = tf.data.Dataset.range(8)
for line in ds1:
print(line)
ds2 = ds1.map(lambda x:fun(x,var))
for line in ds2:
print(line)
打乱(shuffle)操作:
该操作可以打乱dataset中的元素。在机器学习中训练模型经常需要将数据打乱,这样可以保证每批次训练所用到的数据集是不一样的,从而提高模型训练的效果。
shuffle操作有一个参数buffersize,表示打乱时使用的buffer的大小,不设置会报错。当buffersize = 1时,表示不打乱顺序,既保持原序,当buffersize>1时,值越大,打乱程度越大。
示例代码如下:
import tensorflow as tf
def fun(x,arg):
return x * arg
var = tf.constant(3,dtype = tf.int64)
ds1 = tf.data.Dataset.range(8)
for line in ds1:
print(line)
ds2 = ds1.map(lambda x:fun(x,var))
for line in ds2:
print(line)
print("---------------")
ds3 = ds2.shuffle(3)
for line in ds3:
print(line)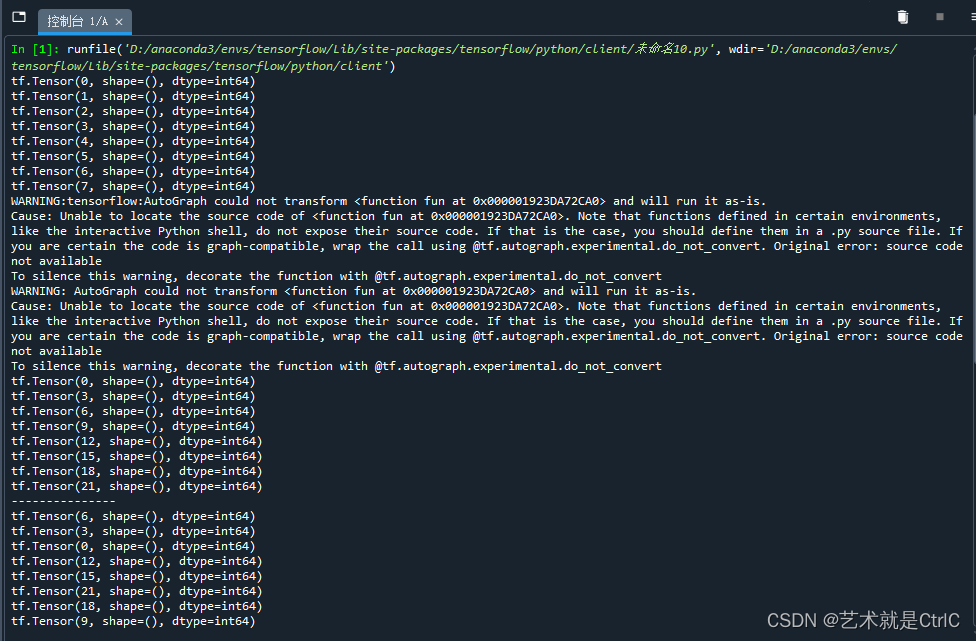
重复(repeat)操作:
该操作是将整个数据重复多次,主要用来处理机器学习中的每次训练(epoch)。比如,如果原先的数据是一次训练(epoch)数据,使用repeat(2)就可以将之变成2个训练数据。使用repeat操作时,可以设置重复次数,也可以不设置。不设置时,程序会一直进行重复操作,直到将其停止。
示例代码如下:
import tensorflow as tf
def fun(x,arg):
return x * arg
var = tf.constant(3,dtype = tf.int64)
ds1 = tf.data.Dataset.range(8)
for line in ds1:
print(line)
print("---------------")
ds2 = ds1.repeat(2)
for line in ds2:
print(line)
分批(batch)操作:
该操作可以将数据集按照指定的元素个数分成多个批次。
示例代码如下:
import tensorflow as tf
def fun(x,arg):
return x * arg
var = tf.constant(3,dtype = tf.int64)
ds1 = tf.data.Dataset.range(8)
for line in ds1:
print(line)
print("---------------")
ds2 = ds1.batch(2)
for line in ds2:
print(line)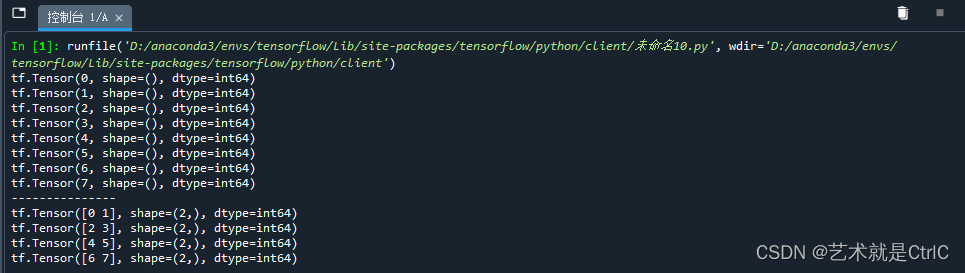
Dataset的遍历
Dataset生成后,接下来需要构建迭代器Iterator获取数据。TensorFlow目前支持以下几种迭代器Iterator:one-shot iterator、initializable iterator、reinitializable iterator、feedable iterator。
one-shot iterator:该遍历器只支持遍历结构单一的数据集dataset,且不需要显式的初始化。应用的场景非常广。
示例代码如下:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
ds1 = tf.data.Dataset.range(8)
#实例化make_one_shot_iterator对象,该对象只能读取一次
iterator = tf.data.make_one_shot_iterator(ds1)
next_elem = iterator.get_next()
with tf.Session() as sess:
for i in range(8):
num = sess.run(next_elem)
print(num)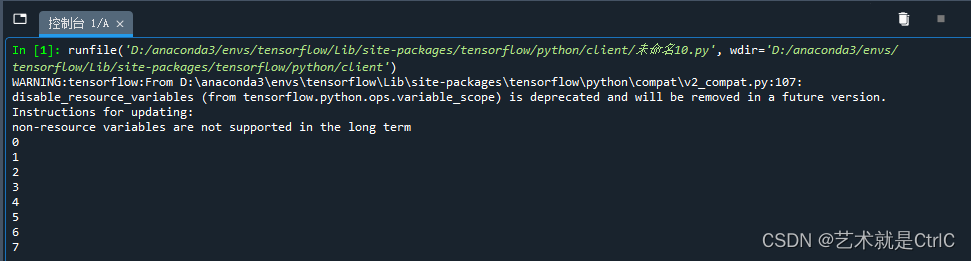




![php伪协议 [ACTF2020 新生赛]Include1](https://img-blog.csdnimg.cn/96ad35304c5c41bcaebfed30e3d225eb.png)