前言:
网络初始:对于网络有一个直观的大体的认识
网络编程:让我们真正通过代码感受网络通信程序
网络原理:进一步的理解网络是如何工作的,以理论为主,很多比较抽象的东西,同时这里也包含大量的面试题(考点,工作不常用!)
网络原理:
按照网络协议这个几个层次来展开的!
- 应用层
- 传输层
- 网络层
- 数据链路层
- 物理层
应用层,传输层(重点介绍);
网络层,数据链路层(简单了解)
物理层(直接跳过)
应用层:
此处先简单介绍,预计后面有一个专门的章节《HTTP协议》,应用层的代表协议,应用层和代码直接相关一层,决定了数据要传输什么,拿到数据之后,如何使用!
应用层这里,虽然存在一些现有的协议(HTTP),但是也有很大情况,需要程序员自定制协议(和吃饭喝水一样,非常容易)
约定应用层数据报,数据格式就是在自定义协议:
如何约定??
- 确定要传输哪些信息》》(根据需求定的)
- 确定数据按照啥样的格式来组织(随意约定的),在实际开发中,有一些现成的格式,可以直接使用的!
一种典型的格式XML,之前流行的格式,现在用的比较少,但是也还会经常遇到!通过标签的形式来组织的!
请求:
<request>
<userd>100</userd>
<userPos>
100-100
</userPos>
</request>在XML中包含了很多标签,<request>(开始标签) </request>(结束标签)是一对标签,标签之间可以嵌套,标签之间放内容!
XML中的标签都是用户自定义的,每个标签的名字乐意叫啥就叫啥!!
HTMl可以视为XML的特殊情况!Html的标签有哪些??标签的含义是什么??都是人家有一回标准委员会大佬约定的!咱们只能遵守!!
另一种非常流行的格式:json(XML用的少了,主要就是json了)
{
userd:100,
userPos:100_100
}使用{}大括号作为标识,
{}大括号里面是若干个键值对,
每个键值对之间使用,(逗号)分割,
键和值之间使用:(冒号)分割,
键必须是字符串,
值可以是数字,字符串,数组,另一个json……
重点掌握json,后面程序/代码会用到!
数据组织的方式,有无数种,只不过比较常见的为:XML和json
传输层:
UDP和TCP是两个比较重要的协议(重点)更多详情,可见笔者上篇文章:TCP VS UDP-CSDN博客
学一个协议,其中最重要的环节,就是认识协议报文格式(具体怎么组织的这个数据)
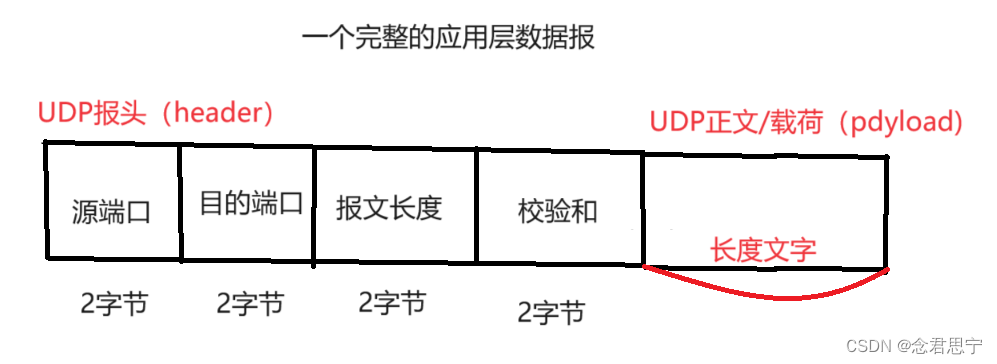
源IP
源端口:数据从哪里来??
目的IP
目的端口:数据到哪里来??
唐僧自我介绍:
贫僧自东土大唐而来,到西天拜佛求经!
源端口:贫僧
源IP:自东土大唐而来
目的IP:到西天
目的端口:拜佛求经
每个端口号在UDP报文里,占两个字节,其实端口号的取值范围为:0~~65535,小于1024的端口,称为“知名端口号”,给一些名气比较大的服务器预留,这部分端口咱们在写代码的时候,不应该使用,当然,用也没事,可能需要提供管理员权限!
报文长度:2字节:比较小!
2字节表示的范围0~~65535(64KB),则一个UDP报文最大长度为64KB
万一真的需要传输一个比较大的数据咋办??
- 可以把一个大的数据拆分为多个部分,使用多个UDP数据报来传输,虽然可行,但是比较麻烦!
- 不用UDP,直接使用TCP,TCP没有限制!
因此:使用UDP编程的时候,需要注意:UDP数据报不能太长,否则会有问题!!
校验和
网络传输并非那么稳定,可能会出现什么幺蛾子!
如:通过网络传输——》电信号(电信号使用高低电平,表示0,1
但是,如果外部环境干扰,强磁场之类的,就可以导致低电平——》高电平,或者高电平——》低电平,比特翻转——》数据传输就出错了!!
校验和最大的意义:就是用来判定当前传输的数据是否出错,如果校验和不对,此时你的数据一定不对,如何校验和对,但是数据也有一定概率是错的!!
为了让校验和能够识别率更高一些,计算的时候通常会以数据内容作为参数来进行计算(可用的计算公式有很多),数据内容发生变化,校验和也会发生变化!
TCP:
有链接,可靠传输(TCP存在的初心),面向字节流,全双工
TCP如何实现的可靠传输!!
所谓的可靠传输,并不是说100%就能传输过去!(要求太高了!)是尽可能的传输过去,如果传不过去,发送方至少能知道自己没传过去!!
核心机制:在于接收方收到了或者没收到,会有个应答!!
确认应答:是实现可靠性的最核心机制!!
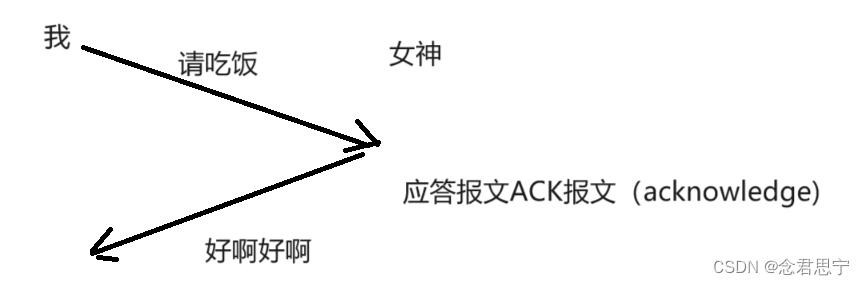
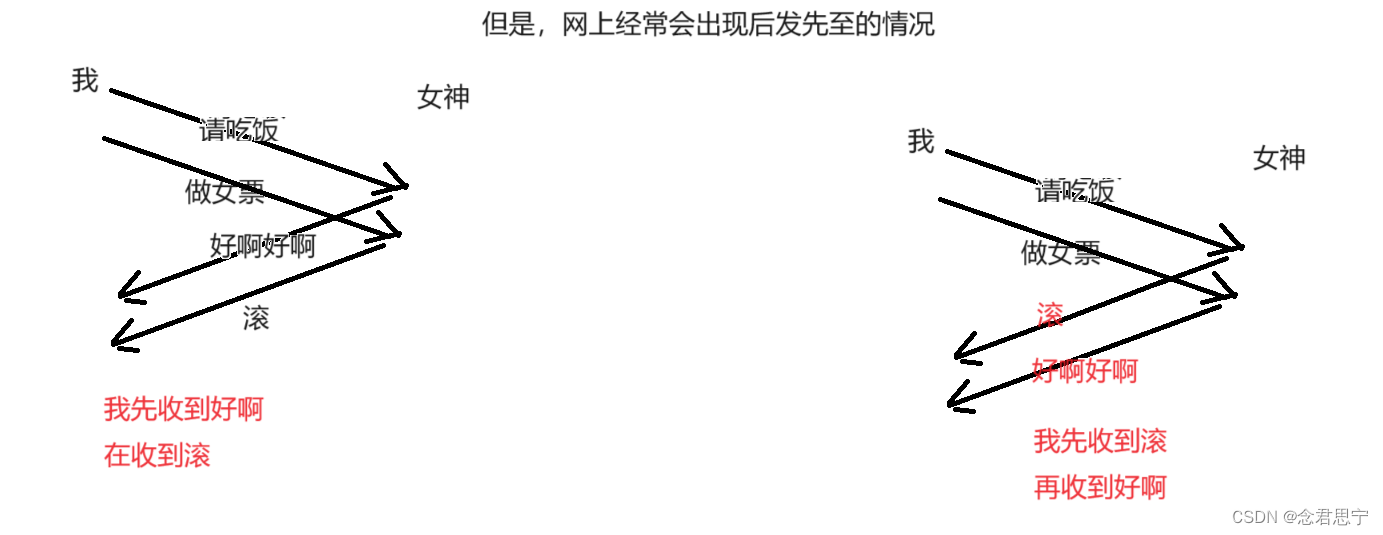
为了解决上述问题,就需要针对消息进行编号!!给发送的信息进行编号!!同时给出应答报文,给出确定序号!!
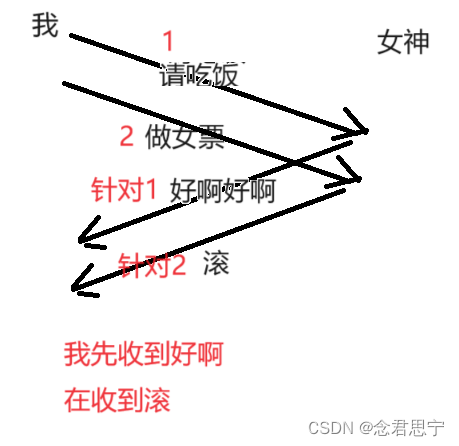
真实的TCP数据传输也是引入了序号和确认序号!
TCP将每个字节的数据都进行了编号,即为序列号!
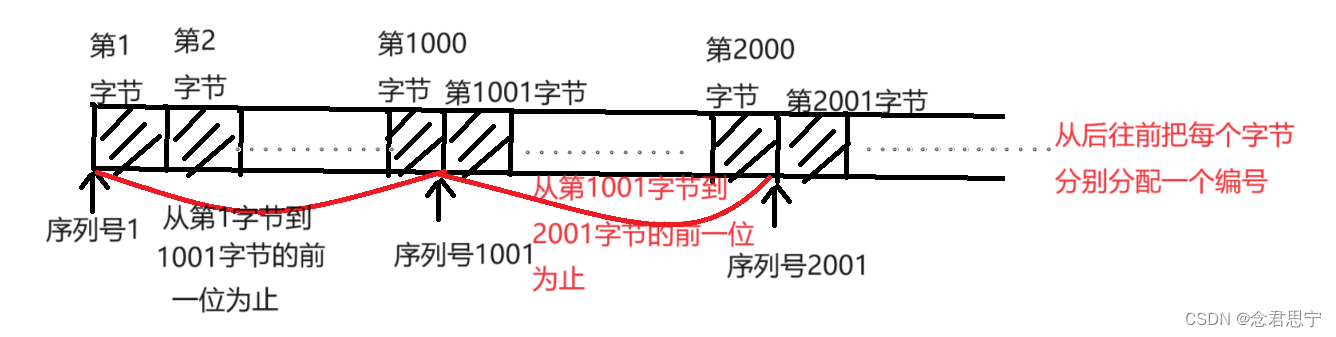
TCP是针对每个字节都去编号(TCP并没有“一条消息,两条消息”这样的说法~)
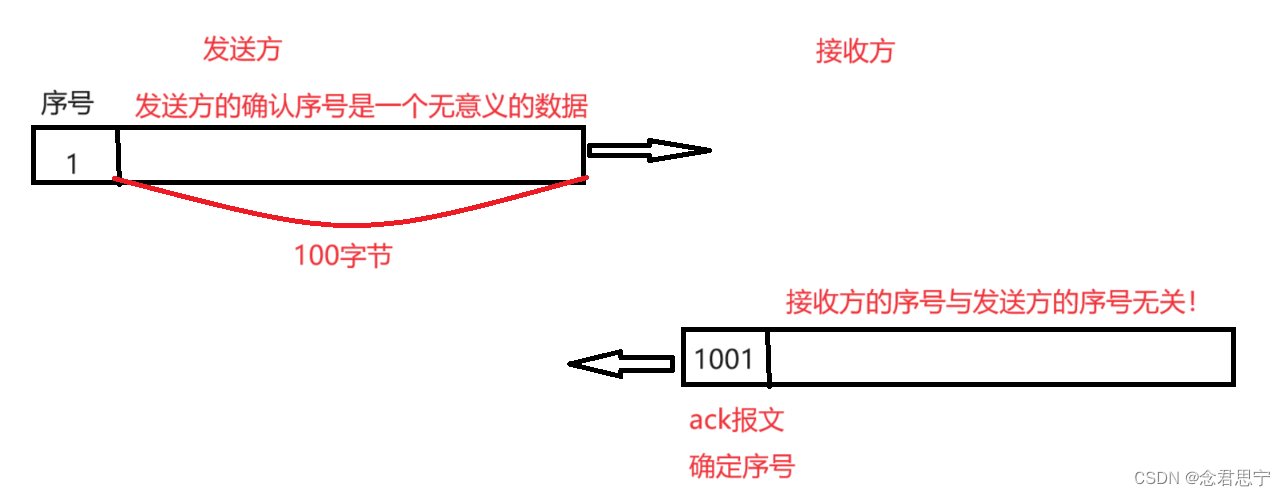
注意:确定序列号的规则:
并不是说,发送方的序列号是啥,确认序号就是啥!!而是取的是发送方发过来的数据,最后一个字节的下一个字节的序号!!
确认序号1001的含义:(这种规则的优势,在我们后面的博客学习中可以体会到!)
- 小于1001的数据我们已经收到
- 我接下来想向发送方索要从1001开始的数据
接收方就可以通过ack的确认序号,告诉发送方哪些数据已经收到了!
其实,后发先至的情况还是很常见的!!(结亲——》结婚)
结亲的车队,在开的时候,很难保证顺序,经常是车头还在很远地方,后面的车就先到了,然后在门口等待,等车都到齐了,再重新整队!!
对于TCP来说,自身也承担了整队的任务!
TCP会有个接收缓冲区(一块内核中的内存空间)
每个socket都有一份自己的缓冲区
TCP就可以按照序列号针对收到的信息进行整队(优先级序列),这也是TCP序号的一个重要用途!
如果一切顺利,就可以直接确认应答了,可靠性自然得到了支持!
丢包:
对于丢包也是网络上非常典型的情况!
那么,为啥会发生丢包呢??
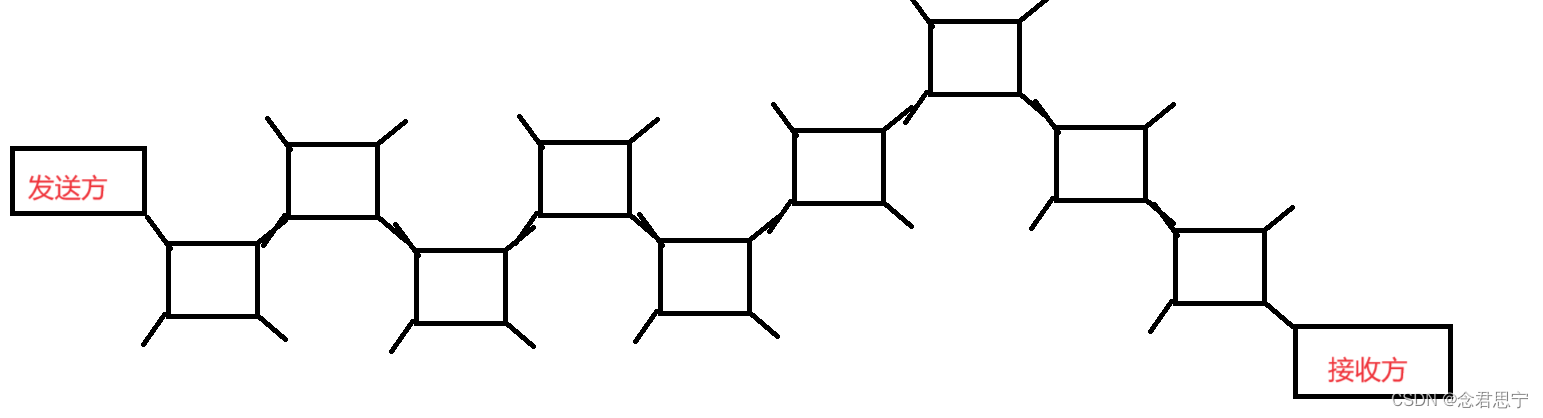
从发送方到接收方之间,需要进行多个服务器的转化,如果中间任何一个节点出现了问题,都可能导致丢包!!
每个设备都是再承担很大的转发任务的!每个设备的转发能力都是有上限的,某一时刻,某一设备上面的流量达到峰值,就可能会引起部分数据的丢包!
其实这种情况下是非常容易出现的,概率性丢包的!!
看视频,看直播,对于丢包是不敏感的(看视频提前有预缓冲)
打游戏,尤其是对抗性的游戏,对于丢包是非常敏感的!
如果丢包了,接收方就收不到了,自然就不会返回ack
发送方就迟迟拿不到应答报文,等待一段时间后,还是没有收到应答报文,发送方就视为刚才的数据丢包了,就会重新再发送一遍!!(超时重传)
网络丢包是概率性事件,上个包丢了,重传还是有很大机会传过去的!!
发送方对于丢包的判定是在一定的时间内没有收到对应的ack
- 数据直接丢了,接收方没有收到,自然不会发送ack
- 接收方收到数据了,返回的ack丢了
发送方是区分不了这两个情况,只能都进行重传!

对于情况1:这种丢包问题不大
对于情况2:这种丢包,虽然是重新发送数据,但也会出现问题(发送方发送的是:转账请求)
当然对于这个问题,TCP非常贴心的帮助咱们处理好了!会在接收缓冲区中根据收集到的数据序号,自动去重(重复数据),保证了应用程序读到的数据仍然只有一份!——》哪有什么岁月静好,只不过TCP在给咱们负重前行!
当然,对于重复的数据,有没有可能又丢了呢??当然,这个也是有可能的!!一旦出现连续丢包,这种情况下,多半你的网络出现了非常严重的问题(网络故障)
TCP针对多个包丢失的处理思路是:继续超时重传!!
但是,每丢包一次,超时等待时间都会变长(重传的频率降低了!)
TCP觉得重传怕也是没戏,干脆就摆烂摸鱼了!反正重传也没啥卵用!(网络已经出现严重问题)
连续多次重传都没有得到ack,此时TCP就会尝试重置连接(相当于尝试重连),如果重置连接也失效,TCP就会关闭连接——》放弃网络通信了(跟我们打电话是一个道理,如果打不通,就停一会在打,如果还打不通………)能重传就重传,实在传不了,就关闭连接了,尽最大可能完成传输!!
TCP可靠性的基石!!
- 一切顺利:使用确认应答,保证可靠
- 出现丢包:使用超时重传作为补充
问:TCP是如何实现可靠性的??
答:确认应答+超时重传
连接管理:
TCP建立连接,和TCP断开连接的流程!(连接管理和TCP可靠性之间,并没有非常直接的关系)
- TCP建立连接:三次握手
- TCP断开连接:四次挥手
TCP最核心的考点,也是整个网络原理最核心的考点(建立连接,断开连接)
三次握手:建立连接——》一定是客户端主动先发起的!
握手(handshake)指☞:通信双方进行一次网络交互,相当于客户端和服务器之间,通过三次交互,建立连接关系(客户端与服务器双方各自记录对方的信息)
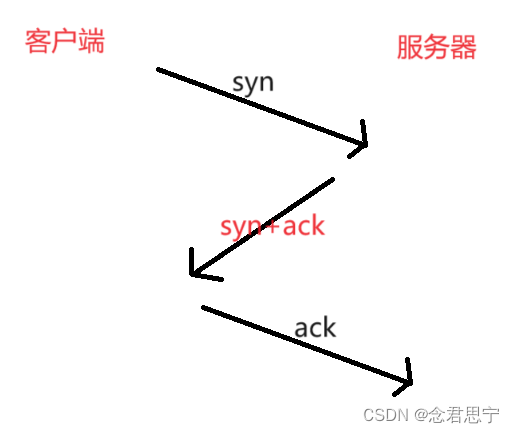
该过程是内核自动完成的,应用程序干预不了!!等到连接完成了,服务器accept把建立好的连接从内核拿到应用程序中!
syn称为:同步报文段:意思就是:一方要向另一方申请建立连接!
知道了三次握手,还得了解下三次握手起到了啥样的效果??达成了什么目标??三次握手这个过程,本质上是投石问路!验证了客户端和服务器各自的发送能力和接收能力是否正常!!
四次挥手:断开连接——》客户端和服务器都有可能主动先发起通信双方各自给对方发送一个FIN(结束报文),再各自给对方返回一个ACK
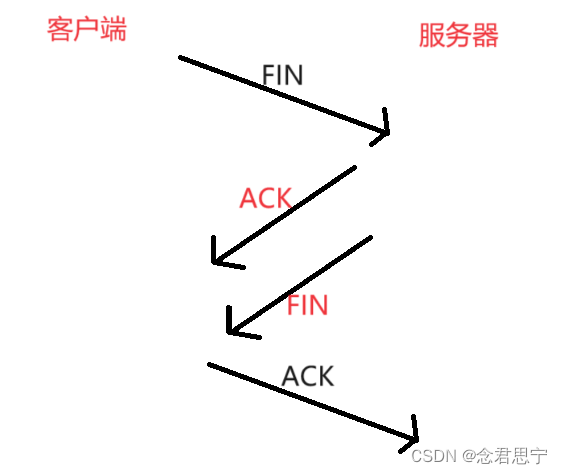
锲约解除,双方都恢复自由之身。
在上述的过程中,服务器发送的ACK和FIN有一定概率合并成一个,但是通常情况下是不可能的!!
为啥三次握手可以100%合并??四次挥手就不能合并??
三次握手:ack和syn是同一个机制触发的!(都是内核来完成的!)
四次会是:ack和syn则是不同时机触发的!(ack是内核完成的,会在收到fin的时候,第一时间返回;fin则是应用程序代码控制的,在调用到socket的close方法的时候才会触发!
TCP要保证的不仅仅是可靠性,还有效率(提升可靠性,往往意味着损失效率)
要想提高效率,就要缩短等待时间——》批量发送数据!(一次发送多条数据,一次等多个ack)
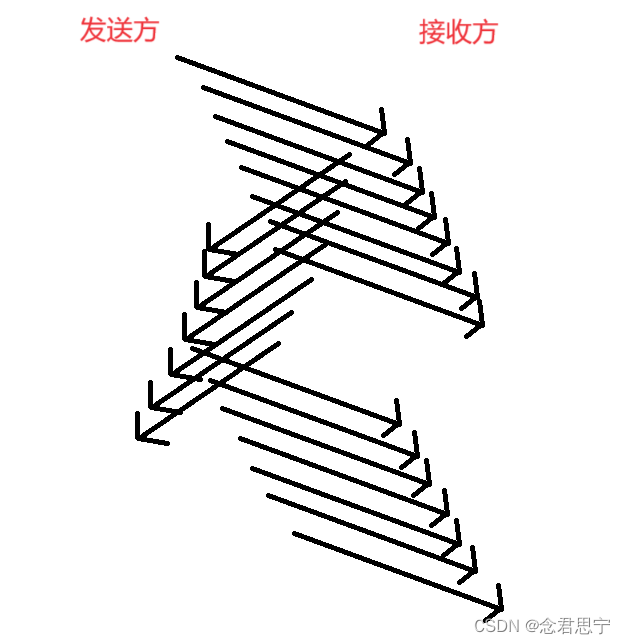
这里就是批量发送数据,发送完之后,统一等待ack,每当收到一个ack后,就立即发送下一条(不是收到全部ack数据——》浪费时间)
批量发送不是无限发送,是发送到一定程度就等待ack,不等待直接发送的数据量是有上限的!!而是回来一个ack,就立即发下一条,相当于总的要等待的数据是一致的(把批量等待数据的数量,就称为窗口大小)
在批量发送的过程中,如果出现了丢包咋办??(可靠性第一,效率靠后),丢包有两种可能
- 数据报已经到达,ack丢了!
- 数据丢了
情况一:数据报已经到达,ack丢了!具体过程如下图所示:
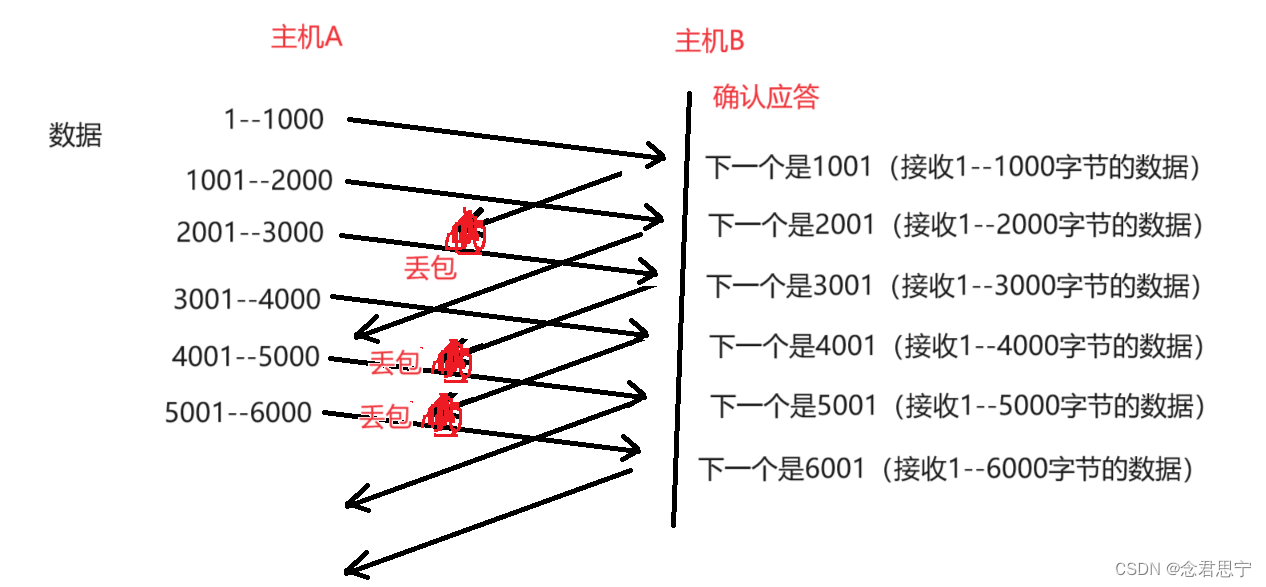
在这个图中,相当于一半的ack都丢了,算是相当高的丢包率了!!
注意在这种情况下,啥事都没有,即使丢了这么多ack,对于可靠性没有任何影响,这就是确认序号的含义了!!(表示该序号之前的数据都已经收到了,后一个ack能够涵盖前一个ack的意思!
当收到2001这个ack的时候,此时发送方就知道2001之前的数据都收到了,1--1000这个数据也收到了,至于1001这个ack丢了就丢了,无所谓!!当然,如果最后一个数据丢了,照样超时重传即可!!
情况二:数据包丢了!!具体过程如下图所示:
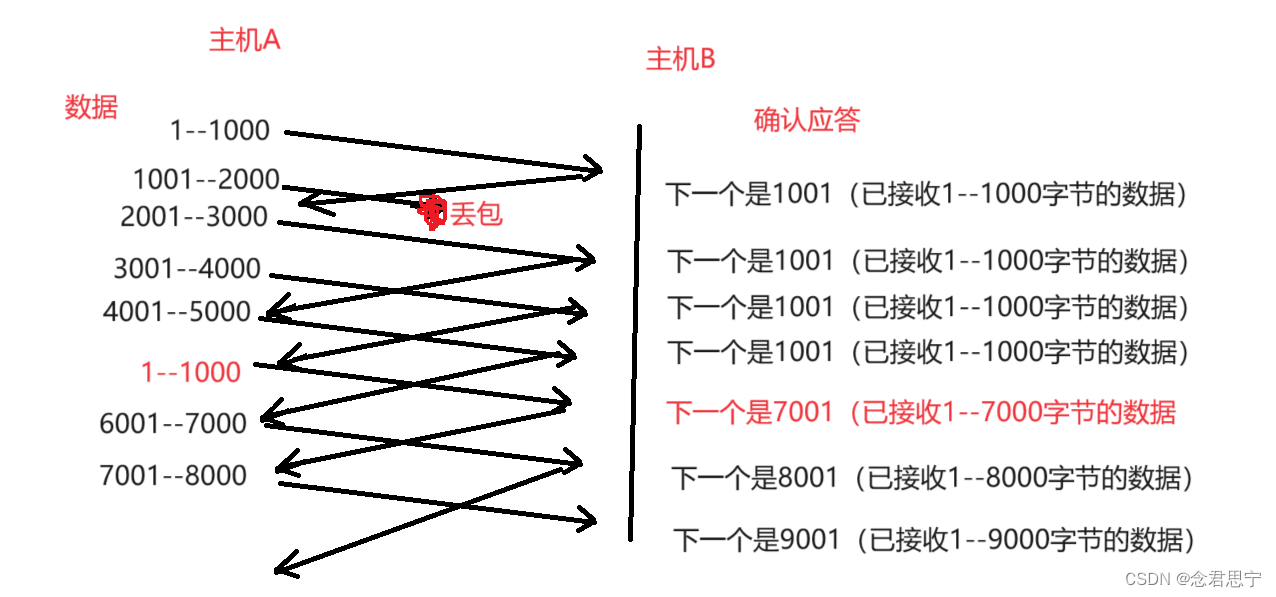
在该过程中,由于刚才1001--2000这个数据丢了,所以接收方仍然再索要1001,不会说因为收到的是2001--3000就返回3001了,因此在接下来的几次数据的ack,确认序号都是1001,主机B在向主机A反复索要1001这个数据,主机A这边连续收到几个1001之后,就知道可能会丢包了!!因此,主机A就重传了1001--2000这个数据。
当主机A把1001--2000这个数据重传之后,主机B 收到了,返回的序号是7001,而不是2001,原因在于:2001--7000这些数据,B都已经收到过了,再上述重传过程,没有任何的冗余操作!!只有丢了数据,才会重传,不丢的数据不必重传,因此整体的速度还是比较快的!!那么,该重传的过程也称为:快速重传!!
滑动窗口,超时重传是再批量传输大量数据的时候,会采取的措施,如果你就只传输一条,两条,少量的,低频的操作,就不会按滑动窗口这么搞了,仍然是前面的确认应答和超时重传了!
在此推荐一本靠谱的书籍:《图解TCP/IP》,网络原理相关书籍!