一、实验介绍
本实验实现了实现深度残差神经网络ResNet,并基于此完成图像分类任务。
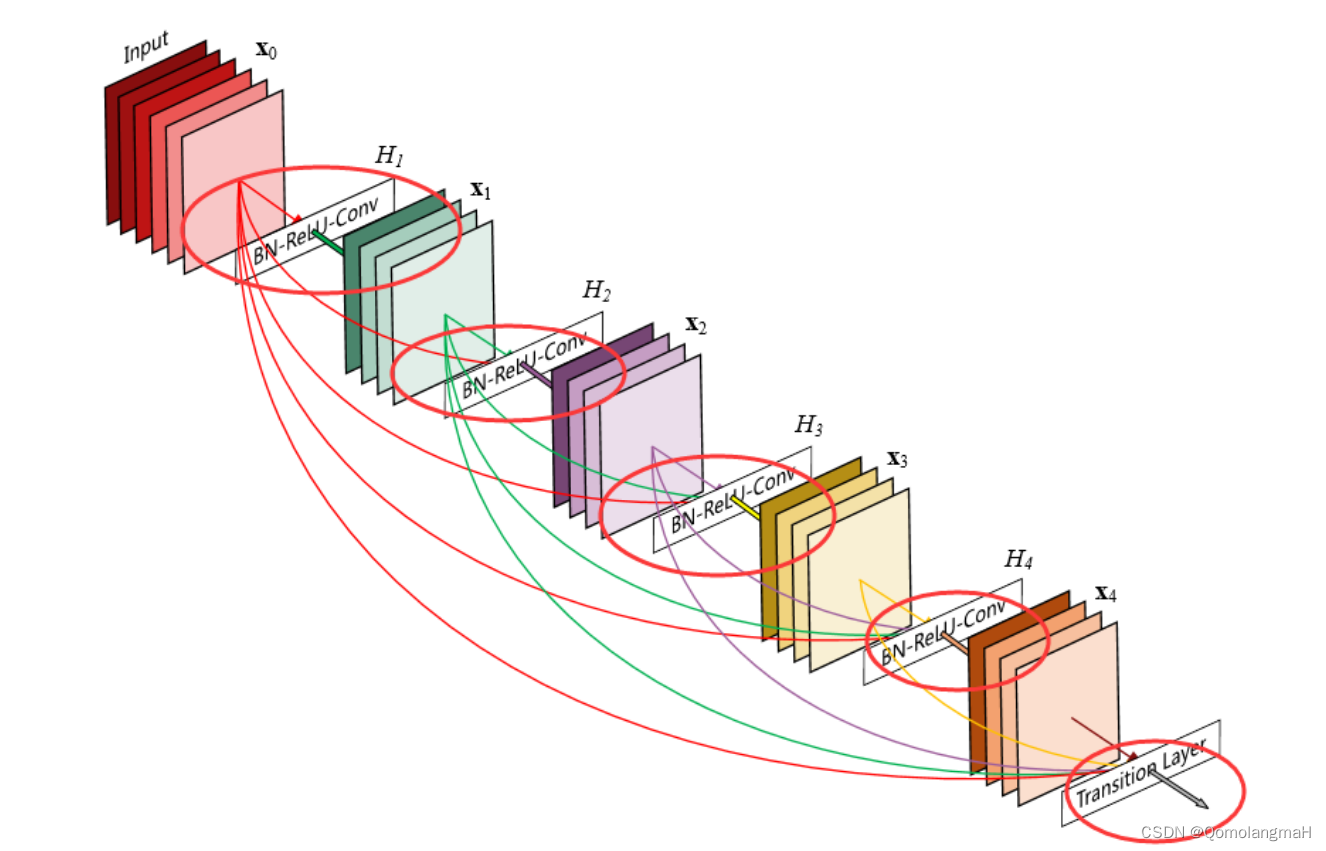
残差网络(ResNet)是一种深度神经网络架构,用于解决深层网络训练过程中的梯度消失和梯度爆炸问题。通过引入残差连接(residual connection)来构建网络层与层之间的跳跃连接,使得网络可以更好地优化深层结构。
残差网络的一个重要应用是在图像识别任务中,特别是在深度卷积神经网络(CNN)中。通过使用残差模块,可以构建非常深的网络,例如ResNet,其在ILSVRC 2015图像分类挑战赛中取得了非常出色的成绩。
在ResNet中,每个残差块由一个或多个卷积层组成,其中包含了跳跃连接。跳跃连接将输入直接添加到残差块的输出中,从而使得网络可以学习残差函数,即残差块只需学习将输入的变化部分映射到输出,而不需要学习完整的映射关系。这种设计有助于减轻梯度消失问题,使得网络可以更深地进行训练。
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
0. 导入必要的工具包
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision.io import read_image1. 构建数据集(CIFAR10Dataset)
CIFAR10数据集共有60000个样本,每个样本都是一张32*32像素的RGB图像(彩色图像),每个RGB图像又必定分为3个通道(R通道、G通道、B通道)。CIFAR10中有10类物体,标签值分别按照0~9来区分,他们分别是飞机( airplane )、汽车( automobile )、鸟( bird )、猫( cat )、鹿( deer )、狗( dog )、青蛙( frog )、马( horse )、船( ship )和卡车( truck )。为减小运行时间,本实验选取其中1000张作为训练集。
数据集链接:
CIFAR-10 and CIFAR-100 datasets (toronto.edu)![]() http://www.cs.toronto.edu/~kriz/cifar.html
http://www.cs.toronto.edu/~kriz/cifar.html
a. read_csv_labels()
从CSV文件中读取标签信息并返回一个标签字典。
def read_csv_labels(fname):
"""读取fname来给标签字典返回一个文件名"""
with open(fname, 'r') as f:
# 跳过文件头行(列名)
lines = f.readlines()[1:]
tokens = [l.rstrip().split(',') for l in lines]
return dict(((name, label) for name, label in tokens))-
使用
open函数打开指定文件名的CSV文件,并将文件对象赋值给变量f。这里使用'r'参数以只读模式打开文件。 -
使用文件对象的
readlines()方法读取文件的所有行,并将结果存储在名为lines的列表中。通过切片操作[1:],跳过了文件的第一行(列名),将剩余的行存储在lines列表中。 -
列表推导式(list comprehension):对
lines列表中的每一行进行处理。对于每一行,使用rstrip()方法去除行末尾的换行符,并使用split(',')方法将行按逗号分割为多个标记。最终,将所有行的标记组成的子列表存储在tokens列表中。 -
使用字典推导式(dictionary comprehension)将
tokens列表中的子列表转换为字典。对于tokens中的每个子列表,将子列表的第一个元素作为键(name),第二个元素作为值(label),最终返回一个包含这些键值对的字典。
b. CIFAR10Dataset
class CIFAR10Dataset(Dataset):
def __init__(self, folder_path, fname):
self.labels = read_csv_labels(os.path.join(folder_path, fname))
self.folder_path = os.path.join(folder_path, 'train')
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
img = read_image(self.folder_path + '/' + str(idx + 1) + '.png')
label = self.labels[str(idx + 1)]
return img, torch.tensor(int(label))-
构造函数:
-
接受两个参数
-
folder_path表示数据集所在的文件夹路径 -
fname表示包含标签信息的文件名。
-
-
调用
read_csv_labels函数,传递folder_path和fname作为参数,以读取CSV文件中的标签信息,并将返回的标签字典存储在self.labels变量中。 -
通过拼接
folder_path和字符串'train'来构建数据集的文件夹路径,将结果存储在self.folder_path变量中。
-
-
def __len__(self)-
这是
CIFAR10Dataset类的方法,用于返回数据集的长度,即样本的数量。
-
-
def __getitem__(self, idx): 这是CIFAR10Dataset类的方法,用于根据给定的索引idx获取数据集中的一个样本。它首先根据索引idx构建图像文件的路径,并调用read_image函数来读取图像数据,将结果存储在img变量中。然后,它通过将索引转换为字符串,并使用该字符串作为键来从self.labels字典中获取相应的标签,将结果存储在label变量中。最后,它返回一个元组,包含图像数据和经过torch.tensor转换的标签。
2. 构建模型(FeedForward)
参考前文:
【深度学习实验】卷积神经网络(七):实现深度残差神经网络ResNet-CSDN博客![]() https://blog.csdn.net/m0_63834988/article/details/133705834
https://blog.csdn.net/m0_63834988/article/details/133705834
3.整合训练、评估、预测过程(Runner)
参考前文:
【深度学习实验】前馈神经网络(九):整合训练、评估、预测过程(Runner)_QomolangmaH的博客-CSDN博客![]() https://blog.csdn.net/m0_63834988/article/details/133219448?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63834988/article/details/133219448?spm=1001.2014.3001.5501
4. __main__
if __name__ == '__main__':
batch_size = 20
# 构建训练集
train_data = CIFAR10Dataset('cifar10_tiny', 'trainLabels.csv')
train_iter = DataLoader(train_data, batch_size=batch_size)
# 构建测试集
test_data = CIFAR10Dataset('cifar10_tiny', 'trainLabels.csv')
test_iter = DataLoader(test_data, batch_size=batch_size)
# 模型训练
num_classes = 10
# 定义模型
model = ResNet(num_classes)
# 定义损失函数
loss_fn = F.cross_entropy
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
runner = Runner(model, optimizer, loss_fn, metric=None)
runner.train(train_iter, num_epochs=10, save_path='chapter_5')
# 模型预测
runner.load_model('chapter_5.pth')
x, label = next(iter(test_iter))
predict = torch.argmax(runner.predict(x.float()), dim=1)
print('predict:', predict)
print(' label:', label)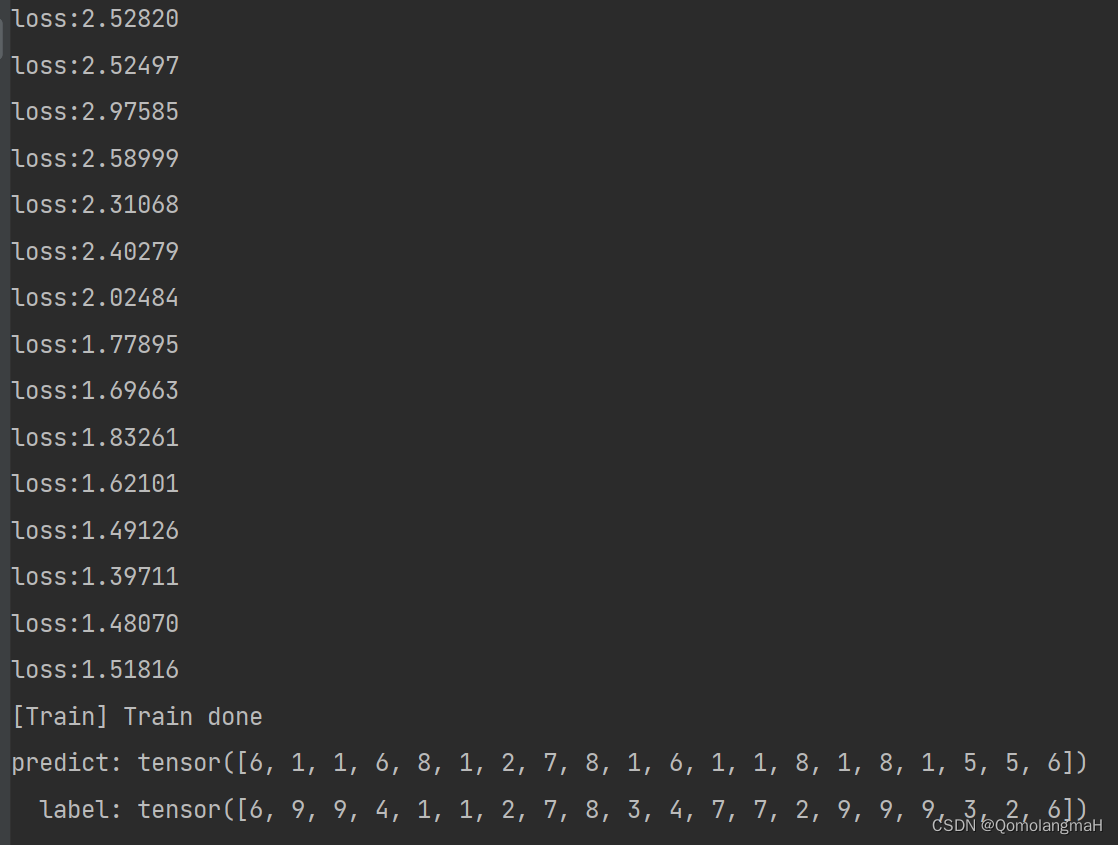
5. 代码整合
# 导入必要的工具包
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision.io import read_image
# 残差连接, 输入和输出的维度有时是相同的, 有时是不同的, 所以需要 use_1x1conv来判断是否需要
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)
else:
self.conv3 = None
# 批量归一化层,将会在第7章讲到
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
# 残差网络是由几个不同的残差块组成的
def resnet_block(input_channels, num_channels, num_residuals, first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
class ResNet(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
self.b3 = nn.Sequential(*resnet_block(64, 128, 2))
self.b4 = nn.Sequential(*resnet_block(128, 256, 2))
self.b5 = nn.Sequential(*resnet_block(256, 512, 2))
self.head = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)), nn.Flatten(), nn.Linear(512, num_classes))
def forward(self, x):
net = nn.Sequential(self.b1, self.b2, self.b3, self.b4, self.b5, self.head)
return net(x)
import os
def read_csv_labels(fname):
"""读取fname来给标签字典返回一个文件名"""
with open(fname, 'r') as f:
# 跳过文件头行(列名)
lines = f.readlines()[1:]
tokens = [l.rstrip().split(',') for l in lines]
return dict(((name, label) for name, label in tokens))
class CIFAR10Dataset(Dataset):
def __init__(self, folder_path, fname):
self.labels = read_csv_labels(os.path.join(folder_path, fname))
self.folder_path = os.path.join(folder_path, 'train')
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
img = read_image(self.folder_path + '/' + str(idx + 1) + '.png')
label = self.labels[str(idx + 1)]
return img, torch.tensor(int(label))
class Runner(object):
def __init__(self, model, optimizer, loss_fn, metric=None):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
# 用于计算评价指标
self.metric = metric
# 记录训练过程中的评价指标变化
self.dev_scores = []
# 记录训练过程中的损失变化
self.train_epoch_losses = []
self.dev_losses = []
# 记录全局最优评价指标
self.best_score = 0
# 模型训练阶段
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型设置为训练模式,此时模型的参数会被更新
self.model.train()
num_epochs = kwargs.get('num_epochs', 0)
log_steps = kwargs.get('log_steps', 100)
save_path = kwargs.get('save_path', 'best_model.pth')
eval_steps = kwargs.get('eval_steps', 0)
# 运行的step数,不等于epoch数
global_step = 0
if eval_steps:
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
if self.metric is None:
raise RuntimeError('Error: Metric can not be None')
# 遍历训练的轮数
for epoch in range(num_epochs):
total_loss = 0
# 遍历数据集
for step, data in enumerate(train_loader):
x, y = data
logits = self.model(x.float())
loss = self.loss_fn(logits, y.long())
total_loss += loss
if step % log_steps == 0:
print(f'loss:{loss.item():.5f}')
loss.backward()
self.optimizer.step()
self.optimizer.zero_grad()
# 每隔一定轮次进行一次验证,由eval_steps参数控制,可以采用不同的验证判断条件
if eval_steps != 0:
if (epoch + 1) % eval_steps == 0:
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f'[Evalute] dev score:{dev_score:.5f}, dev loss:{dev_loss:.5f}')
if dev_score > self.best_score:
self.save_model(f'model_{epoch + 1}.pth')
print(
f'[Evaluate]best accuracy performance has been updated: {self.best_score:.5f}-->{dev_score:.5f}')
self.best_score = dev_score
# 验证过程结束后,请记住将模型调回训练模式
self.model.train()
global_step += 1
# 保存当前轮次训练损失的累计值
train_loss = (total_loss / len(train_loader)).item()
self.train_epoch_losses.append((global_step, train_loss))
self.save_model(f'{save_path}.pth')
print('[Train] Train done')
# 模型评价阶段
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为验证模式,此模式下,模型的参数不会更新
self.model.eval()
global_step = kwargs.get('global_step', -1)
total_loss = 0
self.metric.reset()
for batch_id, data in enumerate(dev_loader):
x, y = data
logits = self.model(x.float())
loss = self.loss_fn(logits, y.long()).item()
total_loss += loss
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
self.dev_losses.append((global_step, dev_loss))
dev_score = self.metric.accumulate()
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型预测阶段,
def predict(self, x, **kwargs):
self.model.eval()
logits = self.model(x)
return logits
# 保存模型的参数
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
# 读取模型的参数
def load_model(self, model_path):
self.model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))
if __name__ == '__main__':
batch_size = 20
# 构建训练集
train_data = CIFAR10Dataset('cifar10_tiny', 'trainLabels.csv')
train_iter = DataLoader(train_data, batch_size=batch_size)
# 构建测试集
test_data = CIFAR10Dataset('cifar10_tiny', 'trainLabels.csv')
test_iter = DataLoader(test_data, batch_size=batch_size)
# 模型训练
num_classes = 10
# 定义模型
model = ResNet(num_classes)
# 定义损失函数
loss_fn = F.cross_entropy
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
runner = Runner(model, optimizer, loss_fn, metric=None)
runner.train(train_iter, num_epochs=15, save_path='chapter_5')
# 模型预测
runner.load_model('chapter_5.pth')
x, label = next(iter(test_iter))
predict = torch.argmax(runner.predict(x.float()), dim=1)
print('predict:', predict)
print(' label:', label)