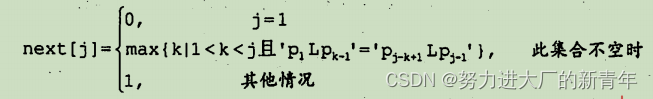利用共享缓存和操作系统缓存利用 RAM
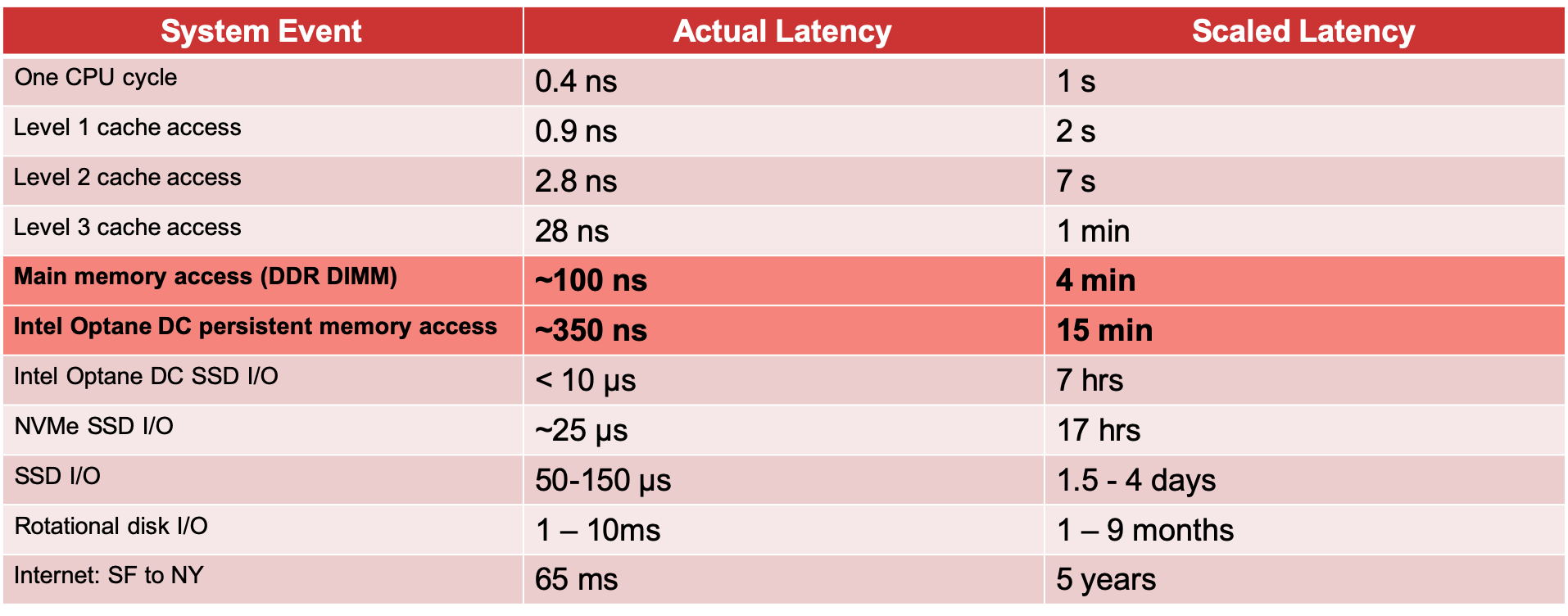
Postgres 是一个基于磁盘的数据库,即使您的整个架构是围绕磁盘访问设计的,利用 RAM 也很重要。如果按照人类规模的延迟来判断,这可以将延迟从几天缩短到几分钟(图 1)。只需看一下下表即可看出,与磁盘 I/O 相比,访问 RAM 或英特尔傲腾 DC PM 的速度要快得多。
标准 Postgres 部署有两种常见的解决方案 - 共享缓冲区缓存和通用 操作系统页面缓存。前者缓存数据和关系索引,Postgres 完全管理该组件,而后者由操作系统提供给所有应用程序,只是将文件页面/块保留在内存中。哪一种更好取决于用例。
然而,如果 Postgres 在具有足够 RAM 的单台机器上运行并且不需要横向扩展,那么这些缓存技术就足够了。但是,一旦数据量和负载超过了即使是最强大的机器的容量,我们就会开始寻找另一种解决方案。好吧,如果共享缓冲区或操作系统页面缓存适用于所有场景,我们就不会拥有分布式内存数据库。
使用 Pgpool-II 进行负载平衡
让我们暂时忘记高级缓存解决方案,假设单机 Postgres 无法承受不断增长的负载,这是一个经典的负载平衡问题。
Pgpool II需要作为第一个可能的选项进行审查,特别是如果您的用例读取量很大。如图所示,您需要部署多个 Postgres 实例,将它们放在 Pgpool 协调器实例后面,并让它负载平衡查询。
但是,有几点需要考虑并制定架构清单:
- 拥有的副本越多,更新速度就越慢。主数据库实例必须保持从数据库同步。对于许多场景,如果无论哪个副本将服务于请求,都必须为应用程序保留 ACID 保证,则复制需要同步。
- 拥有副本意味着解决方案的有用容量受到主实例上可用存储空间的限制。例如,在具有三个副本的集群中,即使每台 Postgres 计算机运行 2 TB 磁盘(总共 6 TB),您也无法存储超过 2 TB 的应用程序生成的唯一数据。如果需要存储更多,则需要分配容量更大的机器。
那么,我们如何才能以弹性和无限的可扩展性来支持写入密集型或混合工作负载呢?让我们在下一节中回顾一下。
使用 Postgres-XL 和云解决方案进行扩展
分片和分区让Postgres从单机数据库转变为纯粹的分布式存储。Postgres-XL可以将数据均匀地分配到集群的整个存储空间,从而支持写入密集型和混合工作负载,并且有可能能够存储无限的数据集。
此类解决方案的架构没有显着差异。请参阅 Postgres-XL 架构(图 3),该架构由存储分布式数据集的数据节点、了解数据分布并处理应用程序请求的协调器以及在集群中强制执行事务一致性的全局事务管理器组成。
但即使这些解决方案也不足以满足所有使用场景。那么还缺少或需要什么呢?答案是——记忆。这些解决方案仍然基于磁盘,尽管可以为每个数据节点启用共享缓冲区和操作系统页面缓存,但这种配置将很笨拙且难以管理以确保大规模一致且可预测的延迟。
最后,我们来谈谈专为 RAM 和英特尔傲腾 DC PM 设计的分布式内存存储,以确保我们能够充分发挥分布式内存存储的潜力。
使用内存数据网格进行缓存和扩展
内存数据网格是一种分布式内存存储,可以部署在 Postgres 之上,并通过直接从 RAM 处理应用程序请求来卸载后者。网格有助于将可扩展性和缓存结合在一个系统中,以大规模地利用它们。
Apache Ignite和GridGain是此类解决方案的示例之一,如下图所示,它们与 Postgres 互连并使其与内存中数据集保持同步:
Ignite 和 GridGain 分区数据的方式与 Postgres-XL 的方式类似,只有一个例外:内存成为主存储,而 Postgres 则保留为辅助磁盘存储。Ignite 和 Gridgain 都支持无限的水平可扩展性、SQL、分布式事务等。您实际上可以在 RAM 中存储 TB 级和 PB 级的数据。
总之,我们总结一下讨论的用于增强和扩展 Postgres 的所有选项:
- 共享缓冲区和操作系统页面缓存非常适合单机部署,作为利用内存的一种方式。
- Pgpool-II 完美解决了读取繁重的工作负载的负载平衡问题。
- Postgres-XL 和类似的解决方案将 Postgres 转变为基于磁盘的分布式数据库,用于处理大量写入和混合工作负载。
- Apache Ignite 和 GridGain 作为内存中的数据网格,让我们能够大规模地分布式并利用内存,同时将 Postgres 保留为磁盘存储。