分类目录:《深入理解强化学习》总目录
强化学习的目标
在动态环境下,智能体和环境每次进行交互时,环境会产生相应的奖励信号,其往往由实数标量来表示。这个奖励信号一般是诠释当前状态或动作的好坏的及时反馈信号,好比在玩游戏的过程中某一个操作获得的分数值。整个交互过程的每一轮获得的奖励信号可以进行累加,形成智能体的整体回报(Return),好比一盘游戏最后的分数值。根据环境的动态性,我们可以知道,即使环境和智能体策略不变,智能体的初始状态也不变,智能体和环境交互产生的结果也很可能是不同的,对应获得的回报也会不同。因此,在强化学习中,我们关注回报的期望,并将其定义为价值(Value),这就是强化学习中智能体学习的优化目标。
价值的计算有些复杂,因为需要对交互过程中每一轮智能体采取动作的概率分布和环境相应的状态转移的概率分布做积分运算。强化学习和有监督学习的学习目标其实是一致的,即在某个数据分布下优化一个分数值的期望。不过,经过后面的分析我们会发现,强化学习和有监督学习的优化途径是不同的。
强化学习中的数据
接下来我们从数据层面谈谈有监督学习和强化学习的区别。
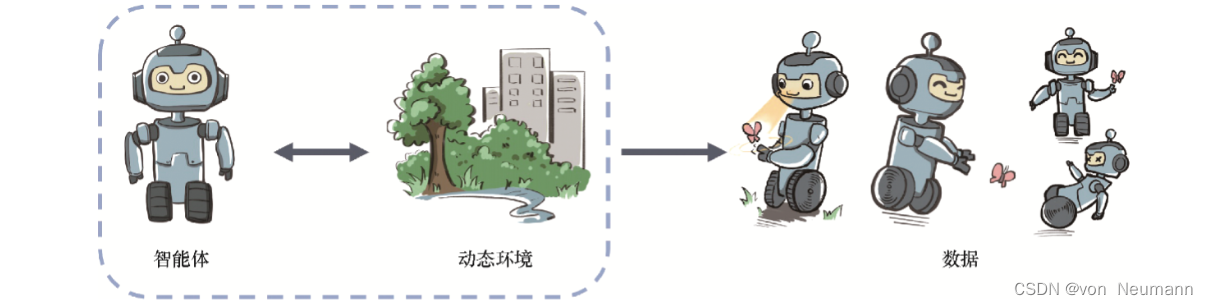
有监督学习的任务建立在从给定的数据分布中采样得到的训练数据集上,通过优化在训练数据集中设定的目标函数(如最小化预测误差)来找到模型的最优参数。这里,训练数据集背后的数据分布是完全不变的。而在强化学习中,数据是在智能体与环境交互的过程中得到的。如果智能体不采取某个决策动作,那么该动作对应的数据就永远无法被观测到,所以当前智能体的训练数据来自之前智能体的决策结果。因此,智能体的策略不同,与环境交互所产生的数据分布就不同,如下图所示:
具体而言,强化学习中有一个关于数据分布的概念,叫作占用度量(Occupancy Measure),其具体的数学定义和性质会在后面的文章中讨论,在这里我们只做简要的陈述:归一化的占用度量用于衡量在一个智能体决策与一个动态环境的交互过程中,采样到一个具体的状态动作对(State-action Pair)的概率分布。
占用度量有一个很重要的性质:给定两个策略及其与一个动态环境交互得到的两个占用度量,那么当且仅当这两个占用度量相同时,这两个策略相同。也就是说,如果一个智能体的策略有所改变,那么它和环境交互得到的占用度量也会相应改变。
根据占用度量这一重要的性质,我们可以领悟到强化学习本质的思维方式:
- 强化学习的策略在训练中会不断更新,其对应的数据分布(即占用度量)也会相应地改变。因此,强化学习的一大难点就在于,智能体看到的数据分布是随着智能体的学习而不断发生改变的。
- 由于奖励建立在状态动作对之上,一个策略对应的价值其实就是一个占用度量下对应的奖励的期望,因此寻找最优策略对应着寻找最优占用度量。
参考文献:
[1] 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 人民邮电出版社, 2022.
[2] Richard S. Sutton, Andrew G. Barto. 强化学习(第2版)[M]. 电子工业出版社, 2019
[3] Maxim Lapan. 深度强化学习实践(原书第2版)[M]. 北京华章图文信息有限公司, 2021
[4] 王琦, 杨毅远, 江季. Easy RL:强化学习教程 [M]. 人民邮电出版社, 2022