接触Vulkan大概也有大半年,概述一下自己这段时间了解到的东西。本文实际上是杂谈性质而非综述性质,带有严重的主观认知,因此并没有那么严谨。
使用Vulkan会带来什么呢?简单来说就是对底层更好的控制。这意味着我们能够有更多的手段去提升绘制的效率。这里Vulkan主要能够提升的是CPU端的效率,GPU端的效率是无法直接提升的。
这里所说的提升CPU的效率,实际上描述的是Vulkan能够更好地控制渲染数据的准备,那么这个渲染数据的准备具体来说就是完成渲染指令的编码。
那么作为开发者来说,在已经封装好的Vulkan框架下,还有必要了解Vulkan的实现细节吗?在我看来,还是很有必要的。一个通用的引擎提供的是比较普适性的封装,这意味着它基本不会出错,但并不会考虑到每个项目的实际情况,进而没有办法发挥出Vulkan本身的优越性。
编码渲染指令
Vulkan的工作简单来看就是编码渲染数据,提交给GPU,如此反复。编码渲染数据是在CPU段发生的事情,因此会消耗CPU时间。而直到数据被提交到GPU,GPU才会知道自己需要做什么。
在Vulkan中,Command Buffer就是用于记录绘图操作、内存传输以及计算调度等任务的缓冲区。我们所谓的编码渲染数据,就是填充Command Buffer,所谓的提交到GPU,就是把Command Buffer从CPU传输到GPU,整个过程从另外一个角度来看就是一个数据流的过程。
从这里可以看出来,我们之所以说Vulkan提供了更底层的控制,也就是说它其实把渲染的本质暴露了出来:填充编码了渲染任务的缓冲区,并把这个缓冲区数据传输到GPU。而在传统图形API中,Command Buffer的概念是隐藏的,我们只能指定要做什么,而我们指定的事情看起来就像是GPU即时去做的。
从功能性上来看,Command Buffer包含如下三种类:
① 编码绘制指令
② 编码计算指令
③ 编码上传指令
Command Buffer提交频率
把Command Buffer暴露出来,一个好处就是它更贴近底层实际在做的事情,第二个就是我们可以直观地去控制CPU和GPU的调度。
一个Command Buffer可以编码非常多个指令,这意味着我们可以在一帧的所有指令都放到一个Command Buffer中去编码。
由于频繁提交Command Buffer本身是耗时的,我们可以仅在必要的时候去拆分Command Buffer。我们多次提交Command Buffer是为了GPU尽快地响应我们的任务。
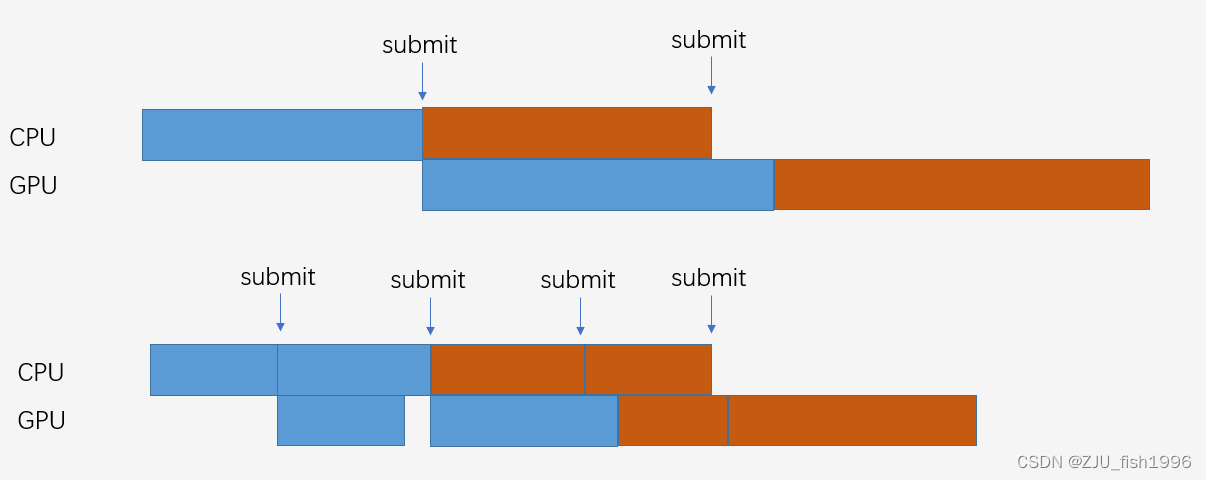
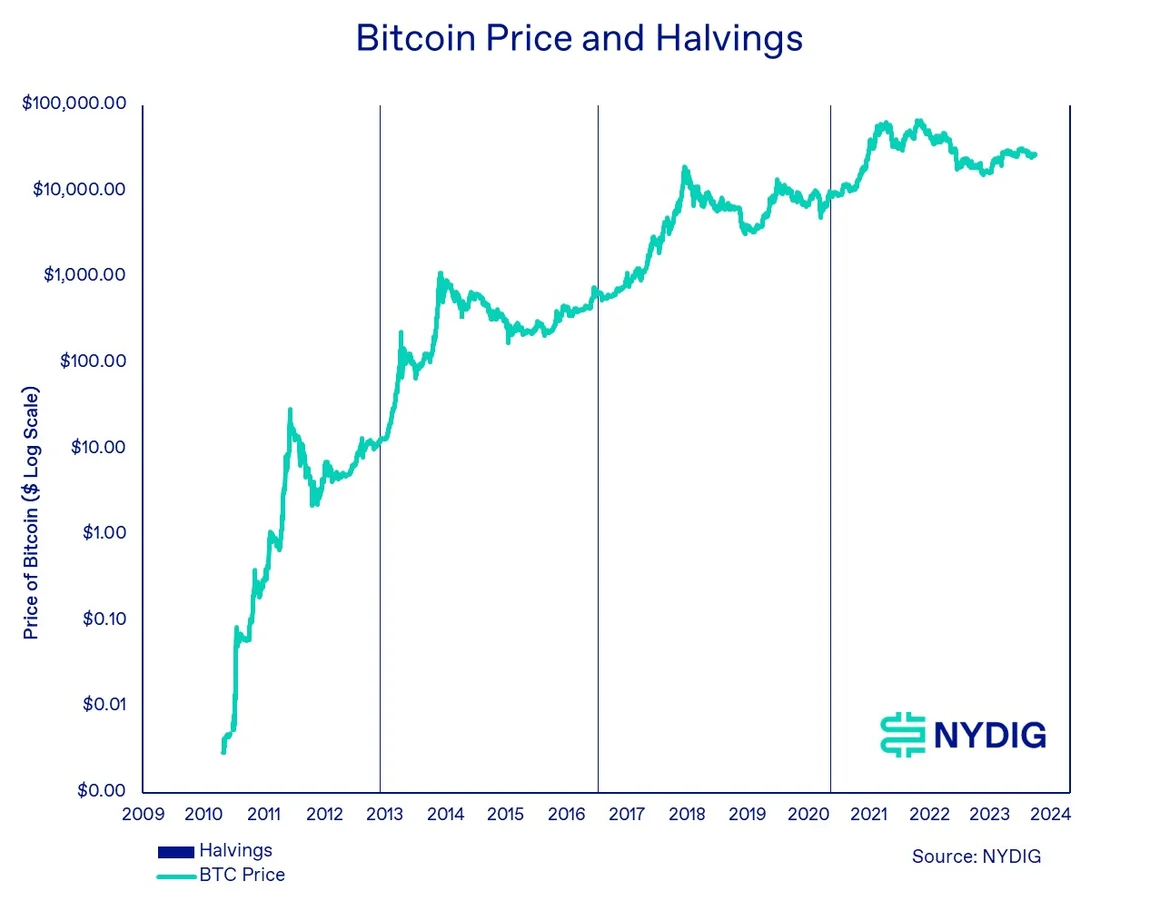
如图1所示,在我们不限帧的理想情况下,把一帧拆成两个Command Buffer使得整个绘制流程变得更紧凑了,GPU能够尽早地结束绘制任务,屏幕也能更快地拿到需要绘制的数据。这个越紧凑,那么拖累后续流程造成等待的情况也就越少。
这里实际上有一个容易让人产生误会的点,因为哪怕是仅用1个Command Buffer来提交,看起来CPU和GPU的利用率也没有直观上的下降,因为GPU只是较晚开始执行当前帧的任务,并不是完全停摆了,因为在当前帧CPU还没有准备好数据时,GPU可能还在执行上一帧的任务,整个流程仅仅是“滞后”了。
所以这里想要描述的Command Buffer数量的影响并不直接体现在利用率上,而是体现在周期上。也就是从CPU开始准备数据,到GPU结束的周期变短了,流程越短可能出现的卡顿越少。当我们后面讨论到交换链的时候,应该会对此有更好的理解。

再来考虑另外一个极端的现象,如果我们把Command Buffer的粒度设置的足够小,那么整个渲染周期也会变得足够短,这相当于CPU端发起一个任务,GPU端立即执行一个任务。但是我们需要考虑到渲染指令的提交本身会产生一些额外的成本,这类似于文件系统多次少量写入效率会低于少次大量写入一样。所以通常来说我们会取一个折中的数值。
我们来看ue4引擎中对于Command Buffer拆分的设计。
它把传输指令(Upload)和渲染指令(Graphics,Compute)分配到不同的Command Buffer中,因为我们在执行渲染前通常需要保证数据都上传了,所以在Render Command Buffer提交前,需要确保Upload Command Buffer全部提交。
这样的话可以有效地把数据传输和图形渲染隔绝开,不过也仅仅是时序上的隔绝,ue4默认并没有添加额外的屏障,资源屏障需要我们上层正确的设置。但它也提供了相关的调试接口让我们来排除资源有效性的问题。
Upload Command Buffer什么时候提交,实际上ue4也并没有明确,而是提供了两种选项,一个是编码完成一个资源后立即提交,这是默认的选项;另一个是等到执行渲染指令的时候再去提交前面的Upload Command Buffer。前者的弊端是在纹理流式加载的时候,帧首可能会出现大量的Submit,这个是非常耗时的;后者的弊端是资源提交的过晚会阻塞渲染任务的提交,这里如何改进是一个值得思考的地方。
而对于其它渲染指令(Graphics,Compute),ue4默认拆分成两个Command Buffer,它首先会在Render主函数中的中间部分显式调用一次Submit,然后会在present之前强制调用一次Submit(不然无法保证正确性)。
在ue4默认的情况下,我们会有2个绘制的Command Buffer,至少一个Upload Command Buffer,CPU端可能会有多帧数据引用不同帧的Command Buffer,那么整体的一个Command Buffer画面静止情况下是个位数,在移动的过程中会涨到两位数。
Upload Command Buffer
我们刚刚说到默认情况下移动过程中Command Buffer会上涨,这里主要说的是Upload Command Buffer。我想对于绘制Command Buffer,由于它每帧都比较固定,大家不会有什么疑问。但是,究竟是什么情况下需要使用Upload Command Buffer呢?
首先需要明确一个前提,虽然Vulkan提供了桌面端的支持,但是绝大部分我们使用Vulkan的场景是在移动端,也就是统一内存(unified memory)环境。
Vulkan中资源的类型我们可以认为就是两种,Buffer和Texture,之所以这么区分是因为它们的内存排布不一样,Buffer是线性的,Texture可能是zigzag形状排列的,这是为了GPU端相邻四个像素访问的连续性。
这里的Buffer我们根据功能来说可能有Index Buffer, Vertex Buffer, Uniform Buffer, Texture Buffer。但这些对于上传来说都不重要,重要的是这个数据是否是Voliate的,也就是说它是否是单帧使用的。
如果它是多帧使用的,比如Index Buffer我们基本上不会去变动它,那么考虑到统一内存架构,我们在创建这个Buffer后就能直接拿到它映射后的CPU内存指针,可以直接进行内存操作,也不需要借助于Upload Command Buffer,因为我们可以在统一内存上操作,就不需要涉及到CPU到GPU的交互了。
而对于单帧使用的场景,我们可能会把它们标记为Voliate,比较常见的就是Uniform Buffer了,因为我们会有一些shader参数需要经常更新。这里最大的区别是非Voliate的Buffer会有固定的CPU句柄,而Voliate的Buffer会映射到一些临时分配的Buffer上,这样的话可以尽可能节约一些内存空间。为了降低Voliate类型的Uniform Buffer的临时缓冲区管理成本,ue也引入了业内常见的Ring Buffer方案。

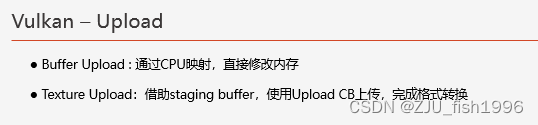
但无论是什么类型的Buffer,在统一内存架构的情况下都是不需要Upload Command Buffer的。而纹理就比较特殊了,我们在前面说到纹理的GPU内存排布一般都不是线性的,但是我们在CPU中通常要么按行要么按列去存储纹理。这就涉及到一个转换问题,我们要保证上传到GPU的数据是正确排序的,这就需要依赖于硬件层提供的transition layout。
对于共享内存来说,我们实际上做的事情是直接操纵GPU端最终可以访问到的内存,但问题在于我们并不知道纹理在GPU中的排布方式,因为这可能和硬件的实现有关,并没有统一的标准,所以我们没有办法通过获取CPU映射的方式直接拷贝并修改纹理布局,而只能借助于Upload Command Buffer上传,使用ImageLayoutTransition设置格式转换,调用vkCmdCopyBufferToImage完成数据的拷贝。
因此,在这堆长篇大论之下的结论其实非常简单,目前只有纹理是需要Upload Command Buffer的。而在我们移动过程中,可能会触发纹理的streaming或新纹理的出现,这个时候才会出现Upload Command Buffer。
Command Buffer的管理

上面这张官方文档的图片比较清晰地描述了单个Command Buffer的生命周期。我们在使用Command Buffer的时候,也遵循以下的调用顺序:
① 初始化
vkAllocateCommandBuffers :在初始化的时候,首先需要分配内存。
② 编码
vkBeginCommandBuffer,vkEndCommandBuffer:调用这两个函数来标记编码的开始和结束,我们提交Command Buffer前一定要确保编码已经完成了。
③ 提交
vkQueueSubmit:提交Command Buffer需要借助于vkQueue来完成,
④ 回收
vkFreeCommandBuffer,vkResetCommandBuffer:对于已经提交的Command Buffer来说,首先我们需要回收内存,然后可以重置并继续使用,如果我们选择重置的话,意味着我们不需要重新申请一个新的Command Buffer。
重置的话我们可以单个重置,也可以整个pool进行重置,后者的性能会更好一些,但这和具体的业务情况有关,在对我们需要对Command Buffer做更精细管理的情况下,我们会去选择单个重置。
我们来看ue4中对于Command Buffer是怎么管理的。
对于每帧固定的提交来说,Command Buffer是可以一直复用的,比如ue4中每帧有两次固定的提交,这意味着我们只需要申请两个Command Buffer,每次使用前重置就可以了。对于上传而言,如果我们固定只在帧首上传一次,那么也只需要一个就够了。
但是在维护Command Buffer的时候,还需要考虑一些特殊情况,比如说通常我们认为数据在帧首一次性上传是一个比较好的选择,一个是数据尽早地准备好不会影响渲染等待,另外一次性提交也会更加高效。
假如说我们在执行渲染任务的中间,再去执行上传,这个时候如果我们Lock的是一个Buffer,我们会在渲染时序中看到一个Blit,这个传输的时间如果安排不合理的话可能会切断一些GPU的任务。
但如果我们Lock的是一个纹理,那么这个时候由于涉及到了Upload Command Buffer,ue4会先暂停Render Command Buffer的编码,而是先去编码并立即提交这个Upload Command Buffer,因为它有可能在接下来的渲染被使用。这样的话表现就是有一个额外的提交打断了Render Command Buffer。

此外,如果我们对每个上传任务单独使用一个Upload Command Buffer,那么在上传比较密集的时候,这个时候可能没有那么多Command Buffer,所以ue4就会去分配,这个时候就会产生一个耗时上的峰值。这些分配出来的Command Buffer可能只会在这一帧使用,之后如果比较长一段时间没有使用这些Command Buffer,ue4还会将它们销毁,那么这个时候又会产生一个耗时的峰值。
对于所有的Command Buffer来说,在使用前都是需要重新分配内存,在使用完成后都需要释放内存。ue4在这里设计了两个Command Buffer数组,一个是普通的Command Buffer数组,一个是Free Command Buffer数组,这两者之间可以相互转化。
简单来说,当我们需要使用Command Buffer的时候,就会从Free Command Buffer列表中找到一个类型匹配的,这个时候它就转化为正在使用的Command Buffer。当我们很长一段时间没有使用Command Buffer的时候,它就会释放内存并转化为Free Command Buffer。特别地,对于刚刚提交的Command Buffer,我们不能立即释放它的内存,因为这个时候可能会存在一些CPU端的引用,所以通常来说并不是理想中的第n帧的Command Buffer释放后立即给第n+1帧使用,而可能会同时存在多帧的Command Buffer,它们在几帧后才会被回收利用。
SwapChain
Vulkan在实现绘制前必须要做的一件事情就是创建交换链,这个交换链创建之后可以一直使用,除非分辨率发生了变化或者经过了旋转。在移动设备上分辨率一般都是固定的,即使我们可能会以低分辨率渲染,最终显示到屏幕上依然会上采样到原始分辨率。
SwapChain里面会包含了我们绘制的多个图像,这里我们称作BackBuffer,我们可以将其看作是等待显示的图像,屏幕刷新的时候会交换BackBuffer和FrontBuffer。一般来说我们会维护多个BackBuffer,ue4中的数量是3个。这样的话,在屏幕刷新的时候,我们能确保拿到的图像是完整的,这样就避免了画面的撕裂;另一方面,也可以让刷新和Buffer的填充同时进行。
那么整个的绘制流程如下所示:
① 请求图像
因为整个Swapchain最多只有3个图像,所以在绘制的时候,需要请求可用的图像,通过调用vkAcquireNextImage获取下一帧绘制图像的ImageIndex。
这个时候如果并没有空余的图像,整个渲染流程暂时还不会停滞,因为我们仅仅是需要拿到一个ImageIndex而已。只有当渲染指令被提交到GPU后,才真正需要BackBuffer。所以这个时候我们会先同时申请一个ImageIndex空闲的信号量,我们称为信号量A。
ue4设计了多种执行AcquireNextImage的时机。我们可以直接请求,也就是发生在比较早的时期,也可以惰性请求,直到我们第一次需要下标的时候再去申请;还有一个比较特别的是我们可以延迟请求,就是完成了渲染之后,下一帧再去请求。
② (可选)CopyToBackBuffer
在我们选择延迟请求ImageIndex的时候(DelayAcquire), 我们就需要额外申请一个RenderingBackBuffer,渲染实际上是画在这个临时的RenderingBackBuffer上的。
我们在需要使用当前帧的RenderingBackBuffer之前,才去把上一帧的RenderingBackBuffer拷贝到实际的BackBuffer中。
这种做法会带来一些额外的带宽消耗,但是会降低我们等待可用图像的时间。
③ EndCommandBuffer
结束当前的编码,准备提交。
④ SubmitCommandBuffer
在执行提交前,我们需要保证GPU有可用的BackBuffer,所以这里就需要等待ImageIndex空闲的信号量A。
提交了编码好的缓冲区指令后,可以申请一个信号量用于GPU通知CPU绘制完成,我们称为信号量B。
⑤ Present
我们执行Present操作,并且对Present事件绑定GPU绘制完成的信号量B。这意味着Present也不是在调用后立即触发的,因为它至少需要等待GPU把BackBuffer填充完成才能将其显示到视口。

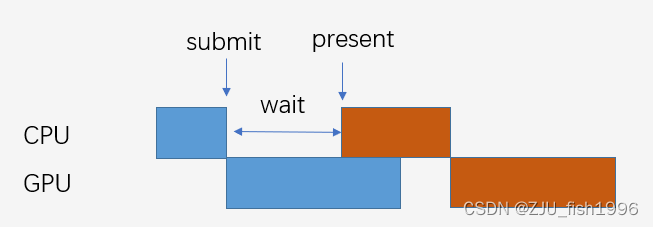
在以上流程中出现了两个信号量,一个是AcquireNextImage的信号量,它可能会导致CPU的停滞。另一个是Present的信号量,它影响的是绘制,所以不会直接导致CPU的停滞,但是只有在Present完成后,BackBuffer才能得到释放。
那么,应用程序什么时候会卡在AcquireNextImage上,也就是什么时候会出现三张图像都不可用的情况呢?这可能是CPU执行的足够快,但GPU处理得很慢,这时Present还在等待GPU完成第n帧的绘制,而CPU已经完成了n+2帧的编码。这个时候CPU就被迫停下来等待GPU。
这个时候延迟请求ImageIndex可能会有所缓解,不过更优的做法一个是优化GPU的时间,另一个就是限帧(锁帧)和稳帧,这也是对于硬件的保护和画面流畅性的保障。
平滑帧率
CPU和GPU之间像一条单向的流水线,也就是说CPU一直都是快于GPU的,当GPU在处理第n帧的事情时,CPU可能已经开始执行第n+1帧的数据了。这意味着更优的方式是让CPU单向控制GPU,也就是CPU端只负责提交任务,GPU端只负责执行任务。
在这种情况下,我们一般极力避免CPU当帧回读GPU的数据,因为这相当于强制同步CPU和GPU,CPU必须等待GPU完成任务之后,才能执行下一帧的任务。

比如上图中,CPU本来可以在GPU执行任务的时候开始下一帧的编码,却由于我们在中间发起了一个回读,导致CPU停滞等待GPU,严重影响了性能。所以我们通常会避免这样的设计,或者尽可能改成回读上一帧或者上两帧的数据。
我们的初衷是提高CPU和GPU的利用率。我们在游戏性能测评的时候,有时候会看到这样的说法:GPU利用率高,说明榨干了GPU的性能,是优化好的一种表现,这样的说法实际上是片面的。
每个工程的情况都会有所差异,但是不外乎就是CPU Bound或者GPU Bound,因为总会有一个跑的比另一个慢。
完全没有Bound的情况也是存在的,那就是CPU和GPU都跑的非常快,而屏幕的刷新率是有限的,比如60Hz,也就是一秒刷新60次,这个时候我们可以认为是Display Bound。这个时候我们就可以锁帧,比如锁到60帧,这样的话整个绘制图像就是这样的比较平稳的:
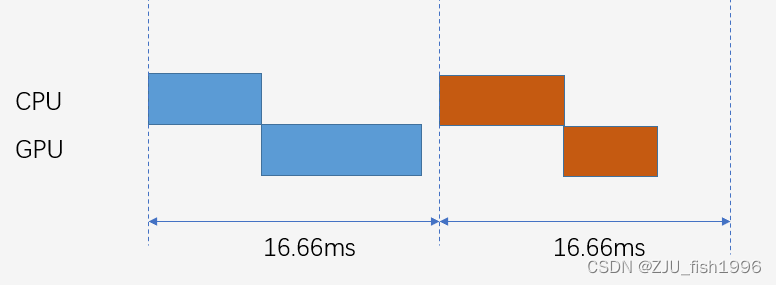
在限帧的情况下,如果CPU和GPU都没有瓶颈,那么我们就认为在当前限帧下属于优化到位的情况。但是这个时候CPU和GPU可能都是没有完全跑满的,所以CPU和GPU的利用率不能作为优化是否到位的衡量指标。
我们在绘制前一般会考虑两个因素,一个是稳定帧率,另一个是垂直同步。考虑垂直同步时,一般可以在逻辑层上设置60Hz和30Hz两种情况,一般会根据项目的实际帧率来设置,如果整体高于60帧,那么就可以设置为60Hz,相当于限帧到60帧;同样的,如果跑不满60帧,那么就可以设置为30Hz,相当于限帧到30帧。相当于强制让画面的渲染和屏幕显示同步。
但如果连30帧都跑不满,那么这个时候应该也没有时间去考虑刷新的事情,当务之急是降低CPU和GPU的绝对耗时。
由于要考虑到屏幕刷新,我们一般以屏幕刷新的时间去衡量一帧的结束,换言之就是GPU尽可能在此之前完成不多于一帧的绘制,如果离下一次显示还有很长的一段时间,那么CPU就可以先等待休息。处理不得当就可能出现丢帧的现象,也就是说GPU辛苦算出的一帧完全没有被绘制;这样的话,如果我们锁定在30Hz,那么项目有可能实际上跑不满30fps,哪怕CPU和GPU耗时并没有那么高。
最原始的稳帧算法就是设置固定的时间间隔,每次Present之前确保和上一次Present间隔了一定长的时间,否则就在执行Present操作前等待;更加完善的做法是结合屏幕刷新时间和GPU绘制完成时间去判断在Present之前需要等待多久。
在合理的稳帧算法下,基本上就比较难出现前面所说的卡在AcquireImageIndex的情况了,它更多地出现在不限帧或者跑不满限帧的情况,比较理想的情况下我们甚至不会用满三张BackBuffer,除非帧间插入了一个非常耗时的任务打断了这种同步。
对于Vulkan运行的移动平台而言,减少CPU和GPU在特定时间内的工作量,可以有效地降低设备的功耗。因为无论是计算还是带宽,都会带来功耗的增加。
内存管理
移动平台由于Unified Memory的存在会让内存管理变得更简单,因为不需要考虑到太多CPU和GPU交互的事情,这一部分的内容在Upload Command Buffer这一节已经详细的阐述了。
内存管理这边主要说的是这几件事,一个是内存怎么分配,另外一个是内存的可访问性。
Vulkan这边管理内存的主要特点是子分配(SubAllocate),也就是一次申请一大块内存,然后具体使用的时候再划出一小块使用,这个做法在内存池中非常常见,这样可以避免频繁申请带来的开销。
如果我们去截帧的话我们就会发现很多不同的Buffer共享同一个Buffer Id,只是设置了不同的偏移。
这是因为ue4中大部分的Buffer都是从Buffer Pool分配而来的,它会维护很多分配好的Buffer,假如我们需要分配内存的对象的属性一样的话,并且内存池中还有可用的类型匹配的Buffer,那么这些数据就可能分配到同一个Buffer上。而不同类型的Buffer,比如Uniform Buffer、Index/Vertex Buffer,或者说不同访问属性,比如仅GPU可访问,以及CPU和GPU都能访问的内存,它们的对齐要求是不一样的。
这样的设计让我们可以在不切换绑定的Buffer的情况下,通过动态偏移(dynamic offset)去访问到不同的数据,这个特性非常重要。
而纹理和Buffer则有一些差异,纹理虽然也是SubAllocate的,但是每张纹理都是独立调用vkCreateImage创建的,因为纹理没有偏移的概念。我们只能在上层通过手动制作Atlas贴图,但由于纹理特殊的内存排布,这可能会让采样的性能下降。此外,在不少设备上会提供纹理专用内存,这意味着我们的纹理有别于Buffer,在特有内存上分配。
接下来我们来讨论资源的访问性。

一种是主机内存,我们可以理解为CPU上的内存;另一种就是设备内存,我们理解为GPU上的内存;这里我们主要讨论的还是设备内存。
比较简单的就是只会在GPU访问的内存了(Device local),一般来说,我们只有在初始化这段Buffer的时候会执行一次Lock/Unlock去初始化它的数据,比如一些不会变的贴图,顶点数据。
较为麻烦的是CPU也能够访问的内存,这些通常是我们需要频繁从CPU端更新的一些数据。在Unified Memory下之所以说相对简单,是源于我们对于这种需要频繁更新的数据只需要将其标记为Host Visible和Host Coherent就可以了,因为我们访问的实际上就是统一内存的数据;而对于非统一内存,如果我们想要完成GPU内存的更新,则需要借助于Staging Buffer(共享内存)来传输。
设备内存如果是Host Visible的,那么意味着我们可以拿到它的CPU映射句柄(vkMapMemory),如果是Coherent的,意味着能够自动维持双端的一致性,如果是Cache的,意味着这段内存会缓存(手动维持双端一致性)。
对于缓存的内存而言,如果是非统一内存,那么同一个数据在CPU和GPU上就有两份,有两份就意味着可能存在不同的现象,也就是可能会持有一份过时的缓存,众所周知,缓存是万恶之源。为了保证数据一致性,就需要在必要的时间去刷新缓存。

移动端的Vulkan开发在一块比较友好,我们在创建资源前,只需要问一问自己,创建后还会更新吗(Static还是Dynamic)?一帧临时使用还是多帧使用(是否Volatile)?虽然移动端有Unified Memory,并不意味着Staging Buffer就毫无用处,比如对于Device Local的数据,此时如果需要更新它的数据,只能借助于Staging Buffer。
Descriptor
在Vulkan中,我们使用Descriptor来描述不同类型的资源,可以简单地把它理解为资源的引用,包括Buffer, Texture, Sampler,Uniform Buffer,Input Attachment。比如对于Texture来说,它的描述符就是ImageView,我们可以通过ViewId去唯一标识它,对于Buffer来说,它的描述符就是Buffer View,我们可以用ViewId和Offset去唯一标识它。
Descriptor比较复杂的地方在于更新。这里涉及到一个事实就是,假如Descriptor引用的资源如果更新,那么View也需要重新创建,这两者的生命周期是强绑定的,毕竟View是作为引用存在的。由于这一部分内容涉及到了绑定,我会在接下来的一个章节阐述这一点。
Descriptor Set
我认为资源绑定是Vulkan中比较重要的一个环节,比如说dx12的资源绑定设计的就比较复杂,不得不说Root Signature,Resource Table这一堆奇奇怪怪的名词非常的劝退。Vulkan的资源绑定看上去会更加纯粹一些,因为它就是不同Descriptor的集合,也就是只有一个Descriptor Set。
你可以认为Vulkan的设计就是万物皆数据,什么渲染指令的提交?就是往GPU上传存储指令的缓冲区;什么又是资源绑定?也就是往GPU上传存储资源句柄的缓冲区。
因为我们会把单个资源的句柄称作描述符(Descriptor),那么一次绑定的所有资源就是描述符集(Descriptor Set),描述符集的每个描述符的具体类型我们使用描述符集布局(Descriptor Set Layout)来概述。

Descriptor Set本身的概念比较简单,它比较麻烦的我们如何去管理Descriptor Set,一个比较直接的做法就是为每个drawcall分配一个独立的Descriptor Set。这个做法下,一个是Descriptor的数量会随着drawcall的增加而增加,另一个是调用Allocate DescriptorSet/Update Descriptor的频率会增加,而实测下来会发现Allocate/Update DS的调用在CPU端上非常耗时。
既然我们知道Descriptor Set本质上是一个记录资源句柄的缓冲区,那这就意味着如果两个不同的drawcall如果使用了相同的资源,那它们可以共享Descriptor Set;另一方面,如果前后帧同一个drawcall的资源绑定没有发生变化,这个Descriptor Set也是可以复用的。针对Descriptor Set复用的优化我们称为Descriptor Set Cache。
对于后者来说我想比较好理解,对于静态材质的物件,它的资源基本上是不变的,或者说我们只要确保它绑定资源的id和offset不发生变化即可。
而对于前者来说,不同drawcall绑定相同资源这件事情看起来有些难以实现,即使是两个使用了相同材质实例的物件,最起码它们的一些私有Uniform Buffer是不一样的(比如记录位置信息的Primitivie Uniform Buffer)。
针对这种情况,我们可以考虑使用Dynamic Offset来优化,也就是先确保Uniform都分配在同一个Buffer上,这样Id就是一致的,Descriptor Set中记录的Offset设置为0,直到调用BindDescriptorSet后才去指定Dynamic Offset。

这样的话,使用的Uniform不一样,但其它资源(纹理、采样器)一样的物件,都可以共享Descriptor Set了,这就大大提高了Descriptor Set的复用率,动态偏移的使用仅仅会对GPU带来一些非常小的影响。
我们刚刚讨论了Descriptor Set Cache,并描述了它在不同drawcall之间的复用,那么它在不同帧之间的复用又是怎样的一个情况呢?
在shader编程中,我们应该会发现资源输入是比较死板的,我们必须在编写特定shader的时候,就把所有输入格式以及对应的插槽位置都指定好。如果有些数据是不定长的,那么我们也必须指定一个上限,有些纹理只在有些情况下需要去访问,我们也必须传输一个内容,这个时候就会出现blackdummy/whitedummy这样奇怪的贴图。既然这些数据在GPU中都是可见的,我为什么不能自由的决定访问哪些内容呢?在这样的疑问下,bindless出现了,不过这并不是我们今天讨论的重点。
在这样“固定”输入格式的情况下,Descriptor Set唯一可能发生变化的情况就是Descriptor本身发生了变化。
我们来看不同的情况,对于Uniform Buffer来说,如果我们开启了Dynamic Offset,对于Volatile类型的,我们使用Ring Buffer更新,只要Ring Buffer的句柄没有发生变化就能够复用,这意味着即使我们使用动态材质更新了一些常量,可能并不会影响缓存;而对于非Volatile类型的,我们借助staging buffer进行拷贝,这也没有破坏句柄。
同理,对于Buffer,由于我们可以直接拿到CPU映射更新,也不会让Descriptor变化;除非我们切换了绑定的Buffer对象,或者说我们把Buffer指定为Volatile的。
对于纹理而言,就会稍微复杂点,除了我们主动在逻辑层去切换的纹理,还有Texture Mipmap Steaming机制也会影响TextureView,这个机制简单来说,就是虽然GPU会为我们自动计算合适的mipmap,但在物件比较远的时候,用到的mipmap一般都是比较高级别的,这个时候去全部加载mipmap就会占用过多的内存,这个时候我们就可以只加载到最低级别的mipmap。这实际上就是一个牺牲运行时效率去换取内存占用的优化,如果我们在游戏中看到有贴图突然由模糊变得清晰,这就是texture streaming机制在加载。
mipmap在运动中可能会发生切换,这个切换不仅会生成新的Upload Command Buffer,还会导致纹理的句柄发生变化,Texture View重新创建,进而破坏Descriptor Set Cache。
所以我们会发现,在运动过程相比起静止过程会更卡,逻辑层上它可能在加载新的内容,做一些缓存的计算更新;渲染层上它可能由于新的物件进入视野或者资产发生变化,在做一些渲染数据的更新。
还有一个值得探讨的问题,那就是一个drawcall实际上可以绑定多个Descriptor Set,我们应该如何把数据拆分到不同Descriptor Set。像Vulkan的一些教程中可能会给出这样的建议,那就是按照资源的更新频率去设置,比如所有物件共享、逐材质共享、逐物件专享的数据分别放到不同的DS里,这样可以尽可能复用公共数据。
这种建议实际上和ue4最终采取的做法差的比较远,ue4这里要么把所有数据都放到同一个Descriptor Set里,要么可以选择按照vertex shader和pixel shader拆开放到两个Descriptor Set,它也提供了公共数据拆成独立的Descriptor Set的可选项。这有可能和移动端支持最多绑定的Descriptor Set数量比较少有关(最多4个),使得基于DS拆分的设计没有什么施展的空间。
像vs和ps分开存储的做法,有一个好处就是对于使用了相同母材质,不同材质实例(可能切换了纹理)的物件来说,vs的Descriptor Set有可能是可以复用的,因为变化的纹理大部分都是在ps里采样的。而vs和ps合并存储的话,一些vs和ps共享的数据就不用记录两遍,整体Buffer的大小可能会小于vs和ps加起来的大小。
我们创建Descriptor Set,一般是从Descriptor Pool中去创建的。如果是走了Descriptor Set Cache的对象,我们可以用多个DS共用一个Pool去分配,在Pool不够用时通过增加Pool数量的方式去扩容。
而如果没有走Descriptor Set Cache,我们通常认为绑定中含有Volatile的资源(主要是Buffer,我们不考虑Uniform和texture),这就意味着资源会每帧更新,这样的话,Descriptor Set Cache在不同帧之间一定无法复用,所以就没有必要去走Descriptor Set Cache了。
对于这类不走缓存的Descriptor Set,ue4会为其维护一个独立的Descriptor Pool,这样的话,每帧就会反复产生创建Descriptor Pool和重置Descriptor Pool产生的开销,如果我们在截帧工具中在一帧结束的时候看到大量ResetDescriptorPool的调用,意味着没有走Descriptor Set Cache的drawcall比较多,如果我们看到绘制中大量AllocateDescriptorSet和UpdateDescriptorSet的调用,意味着没有命中Descriptor Set Cache的drawcall比较多。

默认情况下,ue4为所有Graphics的绘制开启了Descriptor Set Cache,而对Compute默认不执行,因为它认为Compute大概率会有Volatile的资源,因此我们在profile的过程中会发现Compute的性能可能总是要差一点,有一部分的问题可能就出在这里。
渲染调用
在完成一次drawcall前,我们通常需要:
① bind pipeline state
② bind index buffer, vertex buffer
③ bind descriptor set
④ set render state (viewport, scissor等)
⑤ draw
大部分渲染状态量都封装在pipeline state中,大部分参数都封装在descriptor set中,但需要注意的是ib和vb的设置是独立于descriptor set的。
对于Vulkan而言,它所做的事情可以大致分为两个阶段,一个是准备并更新资源(比如更新纹理、Buffer、Uniform Buffer等数据),这个事情一般都是在渲染开始前完成的,这样的话可以不阻塞后续的渲染流程。
第二个阶段就是执行drawcall了,每个drawcall所做的事情就是完成上述的绑定,drawcall数量越多,理论上CPU的耗时也会越高。
由于图形管线的状态机机制,在数据没有发生变化的时候,我们不需要重新绑定,比如第n个drawcall和第n+1个drawcall使用的是相同的pipeline,那么我们可以不重复绑定pipeline。因此良好的排序可以让我们更好地利用状态的缓存。
实际上绑定本身,也就是调用bindxxx的消耗并不算太高,比较麻烦的是绑定对象的创建。比如pipeline state的创建就非常耗时,所以我们通常都选择预收集pso的做法。
另一方面,我们可能会听到过这样的说法,CPU中资源绑定是非常耗时的。这里比较耗时的实际上是准备资源绑定的buffer,也就是我们前面说的allocateDS和updateDS。
这个记录资源绑定的buffer对于传统图形API而言是隐藏起来的,因此它可能无条件地为每次drawcall都创建并填充新的buffer,从感官上就会觉得资源绑定非常耗时。而Vulkan层开放了descriptor set后,我们就有办法显式复用这个绑定buffer,从而降低资源绑定的消耗。
从优化的角度来看,带给我们的启示就是:
① 合理排序,复用状态设置,合理设计架构去规避冗余绑定
② 复用descriptor set
③ 减少每个shader绑定的内容,降低单个descriptor set更新的时间
Barrier
Barrier是对于资源安全性的保护。因为GPU在执行任务的时候,只要线程是空闲的,就会从队列中取出下一个任务执行,而不会考虑资源的可用性,因此这个依赖关系需要我们人为指定告知GPU。
GPU一般都是按照一定顺序执行,看起来似乎不会出现资源不可用的现象,比如我们一般都会在前一个pass写入数据,在后面的pass读取数据,理论上在后面pass读取数据的时候资源应该准备好了。但实际上由于GPU中复杂的缓存机制,我们不能保证读到的数据就是最新的,因此barrier是必要存在的。
另一方面,一些GPU硬件中可能会支持多个硬件插槽,比如vertex, fragment, compute这三个计算单元可能是独立的,那么这三者是可以并行执行任务的。这时候,假设前一个pass的fragment正在执行,此时vertex插槽可能就会去取下一个pass的任务开始执行,如果不幸这个vertex需要访问上一个fragment写入的数据,而没有正确设置屏障,这个时候可能会发生device lost。在这个例子中,如果屏障正确设置,那就意味着vertex和fragment没有办法并行,GPU执行效率下降,也就是说屏障会带来安全,但更优的设计是避免屏障导致的等待,比如这里就可以调整渲染顺序,把vertex中读取数据的pass安排在和它没有ps->vs的依赖关系的pass之后。

Vulkan中包括执行屏障和内存屏障,前者只保证了顺序的先后,后者能够保证内存读写的安全性,内存屏障根据内存对象的不同又分为全局屏障、纹理屏障和缓冲区屏障。
我们在设置Barrier的时候,通常会去指定访问形式(Access),比如读或者写,还有访问阶段(Stage),比如vertex,pixel,compute,这个粒度可以到某个stage的前后,比如执行vertex之前。
Access和Stage的设置通常需要我们指定开始和结束的阶段,这个阶段范围越精确,比如说开始的越晚,结束的越早,那么它可能带来阻塞的概率就会下降。如果设置得不够准确,可能会导致一些不必要的等待,降低GPU的性能。
ue4中对于屏障的设置就是相对宽泛的,也就是说它确保了正确性,但并没有确保最优性。我们在渲染逻辑编写的时候,ue4也开放了Transition的设置,但是它开放的参数并不多,我们只能描述一下资源和它大致所处的阶段,而无法直接设置Access和Stage。而ue4的翻译对于Access和Stage的设置都是以性能不一定好但绝不会出错为原则来设置的。ue4最新的RDG系统甚至让我们省去了Transition设置的工作,但是这样的二次封装也让barrier的冗余变得更严重。
barrier这个东西本身设置有开销,但更为严重的一个是barrier本身设置错误导致的异常访问,另一个是barrier设置的过于宽松带来的gpu stall。但barrier只是一种保护,所以大部分情况下如果资源是安全的,并不会触发stall,所以我们可以仅在出现了明显不合理设置导致停滞时再去考虑优化。
compute阶段的屏障有一些比较特别的地方,因为假如我们连续请求多个compute任务,它在GPU中可以合并到一个Surface中,也就是说不同的compute任务是可以并行执行的,除非它们之间有依赖关系,比如下一个compute需要读取上一个compute的UAV。这就是compute的优势所在,它既可以和外部并行,也可以在内部并行(但并行情况可能会因机型而异,有些可能不支持)
如果我们需要强制不同任务不能并行,这个时候执行屏障就能够派上用场,ue4对于compute中的UAV会统一翻译成全局屏障。
RenderPass和SubPass
Render Pass是我们在Vulkan层指定的,一般来说如果切换了Render Target,通常就需要我们切换Render Pass。每个pass结束后我们会把数据写入到系统内存,这就会产生带宽消耗,所以我们当然是期望pass越少越好的,这里的一个Pass就会对应GPU中的一个Surface。
我们应该都知道移动平台有Tile Memory这样的机制,对于一个Pass来说会自动选择Direct或是Tile的执行形式。如果选择了Tile的绘制形式,那么会根据设备的情况和渲染的thread memory负载来计算拆分成多少个Tile来执行。在实际的绘制中,会先完成Binning阶段(顶点处理),再进入Rendering阶段,逐个Tile执行Render,每个Tile执行完成后直接把当前Tile的内容写入到系统内存。
所以我们看到的一个Surface内,GPU执行顺序就是先把所有顶点处理完,再去一块块的绘制。

也正是因为有了Tile Memory,我们可以引入subpass的概念,如果一些数据仅仅作为下一个pass相同像素位置的输入,并不需要实际写入系统内存,最终输出的Render Target是固定的,那么我们就可以把这几个步骤做为subpass,避免切换Render Target和Load Store带来的消耗。
假如我们引入了subpass,那么GPU上的绘制顺序时,就会先去执行第一个Tile的多个subpass,再去执行第二个Tile的多个subpass,表现上还是一块块的画完。
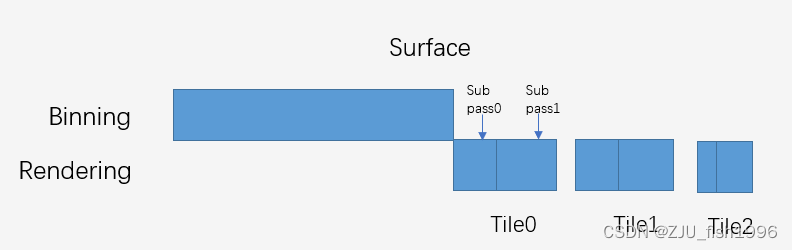
ue4对subpass的封装并没有那么彻底,这意味着假如我们增加删减subpass,都可能需要改动到Vulkan层的一些Layout的东西。
subpass可以设置的内容还是比较丰富的,因为不同subpass可能会有自己的输入输出,所以我们可以去设置InputAttachments和OutputAttachments;另外比较重要的就是可以去设置subpass中Attachment的屏障,类似资源的barrier,我们可以指定Stage和Access属性。对于存在数据依赖的subpass之间屏障如果设置不正确,那么就很可能会发生严重的渲染错误甚至崩溃。