导语
一开始我们就说过Kafka是一款开源的高吞吐、分布式的消息队列系统,那么今天我们就来说下它的分布式架构和高可用性以及双/多中心部署。
Kafka 体系架构简介
以下是 Kafka 的软件架构,整个 Kafka 体系结构由 Producer、Consumer、Broker、ZooKeeper 组成。Broker 又由 Topic、分区、副本组成。
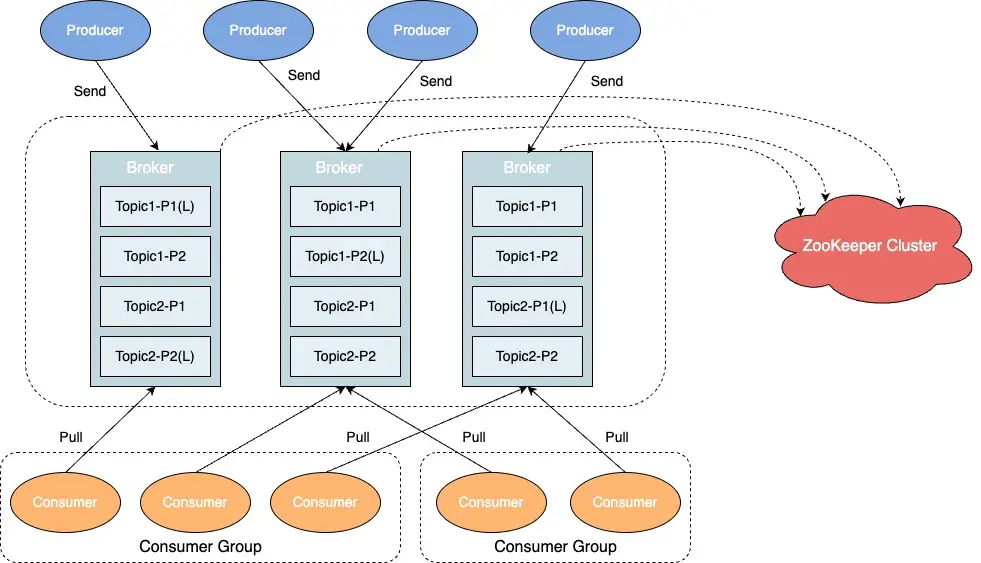
详细可以参考 Kafka 官方文档,Kafka introduction。
分布式与高可用
Kafka通过其分布式架构来实现高可用性。以下是Kafka分布式架构与高可用性之间的关系:
-
分布式数据存储:Kafka的主题被分为多个分区,每个分区都可以有多个副本。这些副本可以分布在不同的Broker节点上,形成分布式的数据存储。这种分布式存储使得数据在多个节点上冗余存储,即使某个节点发生故障,其他副本仍然可用,保证了数据的高可用性。
-
冗余备份:Kafka中的每个分区都可以配置多个副本,这些副本被分布在不同的Broker节点上。当一个Broker节点发生故障时,其他副本可以接管该分区并继续提供服务。这种冗余备份机制保证了即使多个节点发生故障,系统仍然可以继续工作,避免了单点故障,提高了可用性。
-
ISR机制:Kafka使用ISR(In-Sync Replicas)机制来保证数据的可靠性和一致性。ISR是指与Leader副本保持同步的副本集合。当消息被写入Leader副本后,必须等待ISR中的所有副本完成写入操作,才会返回确认给生产者。这样可以保证消息的复制和同步,提高数据的可靠性和一致性。
-
动态的故障转移:Kafka具备自动故障转移能力。当一个Broker节点发生故障时,ISR中的其他副本会参与到Leader选举过程中,自动选举新的Leader副本,并进行分区重平衡。这样可以快速恢复系统的可用性,保证生产者和消费者能够无缝地继续工作。
-
水平扩展:Kafka的分布式架构支持水平扩展。通过增加更多的Broker节点,可以扩展Kafka集群的吞吐量和容量。水平扩展提高了系统的伸缩性,使得Kafka能够处理大规模的数据流和高并发的读写请求。
-
多中心数据互为灾备:即一般为了避免天灾人祸大型项目都会在不同地域部署相同的数据数据中心,彼此之间互为灾备。
多中心相关术语
-
RTO(Recovery Time Objective):即数据恢复时间目标。指如果发生故障,发生故障转移时业务系统所能容忍的最长停止服务时间。如果需要 RTO 越低,就越要避免手工操作,只有自动化故障转移才能实现比较低的 RTO。
-
RPO(Recovery Point Objective):即数据恢复点目标。指如果发生故障,故障转移需要从数据历史记录中的哪个点恢复。换句话说,有多少数据会在故障期间丢失。
-
灾难恢复(Disaster Recovery): 涵盖所有允许应用程序从灾难中恢复的体系结构、实现、工具、策略和过程的总称,在本文档的上下文中,是指整个区域故障。
-
高可用性(High Availability): 一个高度可用的系统即使在出现故障的情况下也可以连续运行。在多区域架构的上下文中,高可用性应用程序即使在整个区域故障期间也可以运行。HA 应用程序具有灾难恢复策略。
发生故障的场景
不论是在虚拟化或容器化架构下,还是在提供成熟服务的云厂商上,但都有可能因为各种因素发生局部和系统故障,因此就需要考虑整体系统容灾能力及可用性。
下面列出一些典型的故障场景
| 序号 | 故障场景 | 影响 | 缓解措施 |
|---|---|---|---|
| 1 | 单节点故障 | 单个节点或托管在该节点上的 VM 的功能丧失 | 集群部署 |
| 2 | 机架或交换机故障 | 该机架内托管的所有节点/虚拟机(和/或连接)丢失 | 集群部署分布在多个机架和/或网络故障域中 |
| 3 | DC/DC-机房故障 | 在该 DC/DC 机房内托管的所有节点/虚拟机(和/或连接)丢失 | 扩展集群、复制部署 |
| 4 | 区域故障 | 该区域内托管的所有节点/虚拟机(和/或连接)丢失 | 地理延伸集群(延迟相关)和/或复制部署 |
| 5 | 全球性系统性中断(DNS 故障、路由故障等) | 影响客户和员工的所有系统和服务完全中断 | 离线备份;第三方域中的副本 |
| 6 | 人为行为(无意或恶意) | 在检测之前,人为行为可能会破坏数据和任何同步副本的可用性 | 离线备份 |
这篇文章重点围绕故障场景2、3、4说明 Kafka 中有哪些方案来应对这几类故障场景。第1种单节点故障,Kafka 集群高可用可以应对;第5、6种故障可以考虑将数据存储到第三方系统,如果在云上可以转储到 COS。
双/多中心的应用场景
-
跨地域复制
在项目比较大的时候,可能需要在多个地域部署中心服务,以增加系统的容灾能力和业务能力,每个数据中心都有自己的 Kafka 集群,这里就涉及到应用和Kafka集群之间的访问,是本地访问还是跨中心访问。 -
灾备
任何集群服务都会收到天灾、人祸等因素影响稳定性,比如地震,火灾,高温、超低温等等,Kafka 集群可能因为这些不可预估的原因导致不可用,这时就需要有另外的与第一个集群完全相同的集群。如果有任何一个集群出现不可用情况,其他中心可以及时顶上,也就是所谓的互为灾备。 -
集群的物理隔离
多环境设置,数据隔离部署。 -
云迁移和混合云部署
在云计算流行的今天,部分公司会将业务同时部署在本地 IDC 和云端。本地 IDC 和每个云服务区域可能都会有 Kafka 集群,应用程序会在这些 Kafka 集群之间传输数据。例如,云端部署了一个应用,它需要访问 IDC 里的数据,IDC 里的应用程序负责更新这个数据,并保存在本地的数据库中。可以捕获这些数据变更,然后保存在 IDC 的 Kafka 集群中,然后再镜像到云端的 Kafka 集群中,让云端的应用程序可以访问这些数据。这样既有助于控制跨数据中心的流量成本,也有助于提高流量的监管合规性和安全性。 -
法律和法规要求
见题知意。
跨数据中心Kafka的部署形态
一般来说,Kafka 跨数据中心部署大体分两种形态:Stretched Cluster和Connected Cluster。
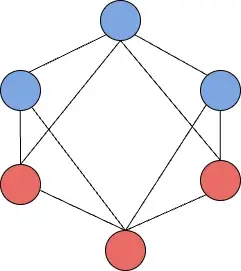
Stretched Cluster
延展集群,它本质上是单个集群,是使用Kafka内置的复制机制来保持broker副本的同步。通过配置min.insync.replicas和acks=all,可以确保每次写入消息时都可以收到至少来自两个数据中心的确认。
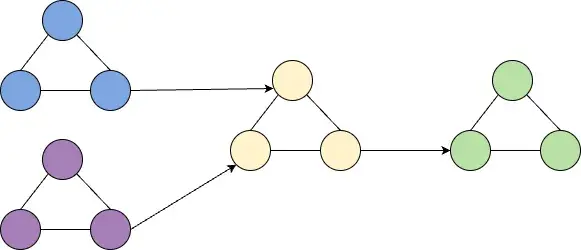
Connected Cluster
连接集群,一般通过异步复制完成多地域复制,并且使用外部工具将数据从一个(或多个)集群复制到另一个集群。该工具中会有Kafka消费者从源集群消费数据,然后利用Kafka生产者将数据生产到目的集群。但Confluent提供了一种不使用外部工具实现此功能的连接集群,在下面介绍商业化方案的时候再详细说明。
下面是这两种部署形态的对比
| 部署形态 | 数据传输方式 | Offset 保留 | 延迟 | RTO&RPO | 何时使用 |
|---|---|---|---|---|---|
| Stretched Cluster | 同步 | 可以 | 无 | 0 | 数据中心距离较短 |
| Connected Cluster | 异步 | 可以 | 取决于网络 | >0 | 数据中心较远 |
以这两种部署形态可以形成多种部署方式,有兴趣的朋友可以深入研究下。
顶尖架构师栈
关注回复关键字
【C01】超10G后端学习面试资源
【IDEA】最新IDEA激活工具和码及教程
【JetBrains软件名】 最新软件激活工具和码及教程
工具&码&教程
本文由 mdnice 多平台发布



![2023年中国隆鼻行业发展历程及趋势分析:隆鼻手术市场将实现进一步增长[图]](https://img-blog.csdnimg.cn/img_convert/cf14dba05537c50b6ba1485af1e28ce8.png)



![web:[护网杯 2018]easy_tornado](https://img-blog.csdnimg.cn/904763e802da4e8ebc98bd713a803ad2.png)