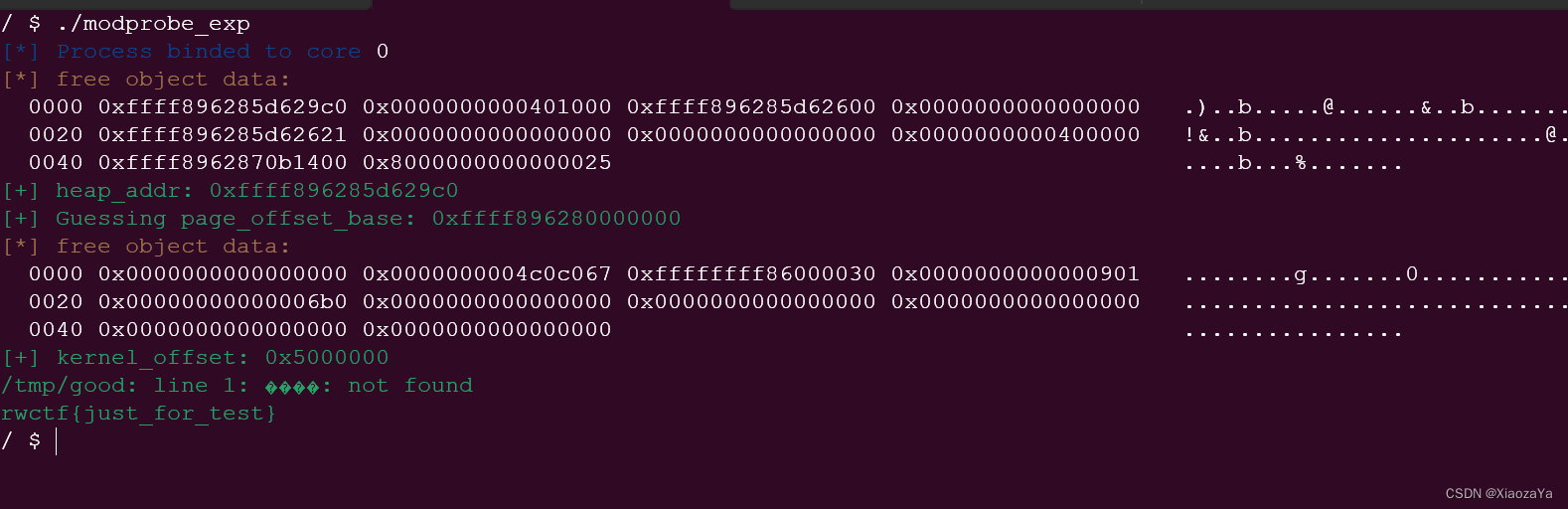
在进行数据采集和信息提取的过程中,XPath是一种非常强大且灵活的工具。它可以在HTML或XML文档中定位和提取特定的数据,为数据分析和应用提供了良好的基础。本文将介绍XPath的基本概念和语法,并分享一些实际操作,帮助您充分了解XPath的威力,并学会在数据采集中灵活运用。
第一部分:XPath的基本概念和语法
1. XPath是什么?
XPath(XML Path Language)是一种用于在XML文档中定位和提取数据的语言。它基于节点、路径和属性等概念,通过路径表达式来定位和选择目标节点。
2. XPath语法:
- 路径表达式:通过一系列的节点选择器和谓语表达式,指定了节点的路径和属性。
- 节点选择器:
- `/`:从根节点开始选择。
- `//`:选择文档中的所有匹配的节点。
- `.`:当前节点。
- `..`:父节点。
- `@`:属性选择。
- 谓语表达式:用于进一步筛选节点。
- `[]`:筛选特定条件的节点。
- `[@属性名='值']`:根据属性值来选取节点。
第二部分:XPath在数据采集中的强大威力与灵活运用
1. 定位元素:
- 使用XPath,可以通过节点选择器准确地定位到目标元素。
示例代码:
```python
from lxml import etree
html = """
<html>
<body>
<div class="content">
<h1>Title</h1>
<p>Content</p>
</div>
</body>
</html>
"""
# 创建XPath解析对象
selector = etree.HTML(html)
# 定位到标题元素
title = selector.xpath('//h1/text()')
print(title) # 输出:['Title']
```
2. 提取属性:
- 使用XPath的属性选择器,可以提取元素的特定属性。
示例代码:
```python
from lxml import etree
html = """
<html>
<body>
<div class="content">
<a href="https://www.example.com">Link</a>
</div>
</body>
</html>
"""
# 创建XPath解析对象
selector = etree.HTML(html)
# 提取链接元素的href属性值
link = selector.xpath('//a/@href')
print(link) # 输出:['https://www.example.com']
```
3. 多层数据提取:
- 使用XPath的路径表达式,可以方便地连续提取多层嵌套的数据。
示例代码:
```python
from lxml import etree
html = """
<html>
<body>
<div class="content">
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
</div>
</body>
</html>
"""
# 创建XPath解析对象
selector = etree.HTML(html)
# 提取每个列表项的文本
items = selector.xpath('//ul/li/text()')
print(items) # 输出:['Item 1', 'Item 2', 'Item 3']
```
XPath通过灵活的语法和路径表达式,帮助我们准确地定位和提取目标数据,为数据采集和信息提取提供了强有力的支持。希望本文对您在使用XPath进行数据采集方面的学习和实践有所帮助,祝您在数据分析和应用的道路上取得成功!