😀前言
本篇博文是关于SpringCloud Sleuth --链路追踪 + Zipkin–数据搜集/存储/可视化的基本介绍和使用,希望你能够喜欢
🏠个人主页:晨犀主页
🧑个人简介:大家好,我是晨犀,希望我的文章可以帮助到大家,您的满意是我的动力😉😉
💕欢迎大家:这里是CSDN,我总结知识的地方,欢迎来到我的博客,感谢大家的观看🥰
如果文章有什么需要改进的地方还请大佬不吝赐教 先在此感谢啦😊
文章目录
- SpringCloud Sleuth+Zipkin
- Sleuth/ZipKin 基础
- 官网
- Sleuth/Zipkin 是什么?
- 概述(两张图)
- Sleuth 和Zipkin 的简单关系图
- Sleuth 工作原理
- Span和Trace 在一个系统中使用Zipkin 的过程-图形化
- 梳理
- spans 的parent/child 关系图形化
- 梳理
- Sleuth/ZipKin-搭建链路监控实例
- 需求说明/图解
- 安装/使用Zipkin
- 下载
- 运行
- 访问
- 服务提供方集成Sleuth/Zipkin
- 服务消费方集成Sleuth/Zipkin
- 测试
- 查看监控&分析结果
SpringCloud Sleuth+Zipkin
Sleuth/ZipKin 基础
官网
官网地址:https://github.com/spring-cloud/spring-cloud-sleuth
Sleuth/Zipkin 是什么?
概述(两张图)
- 在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用, 来协同产生最后的请求结果,每一个请求都会形成一条复杂的分布式服务调用链路。
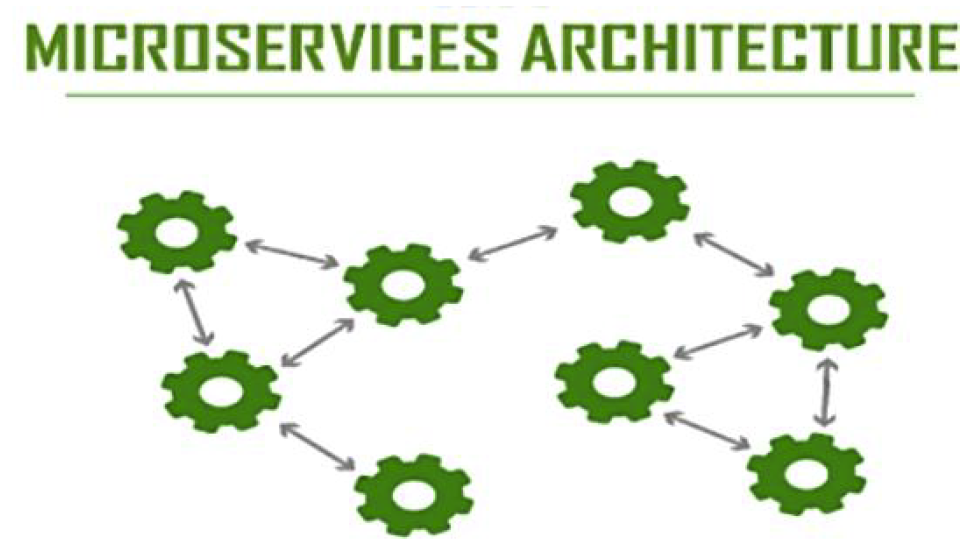
- 链路中的任何一环出现高延时或错误都会引起整个请求最后的失败, 因此对整个服务的调用进行链路追踪和分析就非常的重要。
Sleuth 和Zipkin 的简单关系图
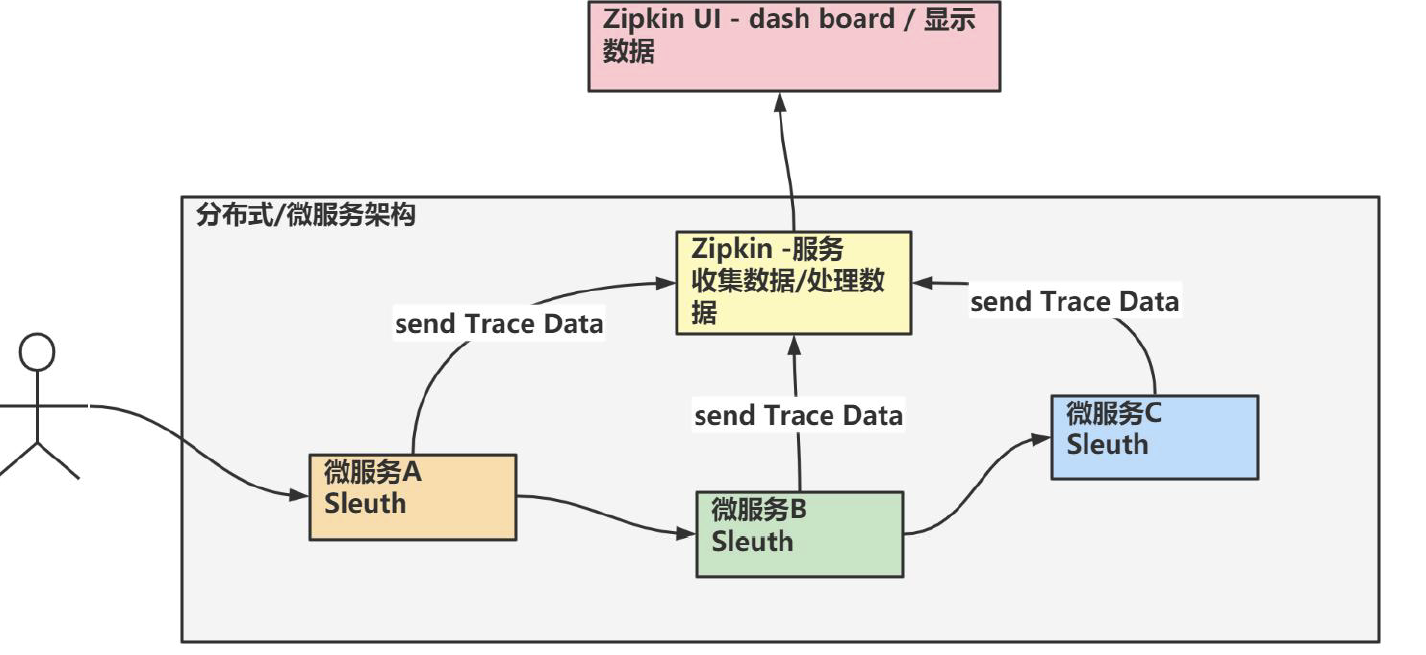
说明:Sleuth 提供了一套完整的服务跟踪的解决方案并兼容Zipkin。
梳理: Sleuth 做链路追踪, Zipkin 做数据搜集/存储/可视化
Sleuth 工作原理
Span和Trace 在一个系统中使用Zipkin 的过程-图形化
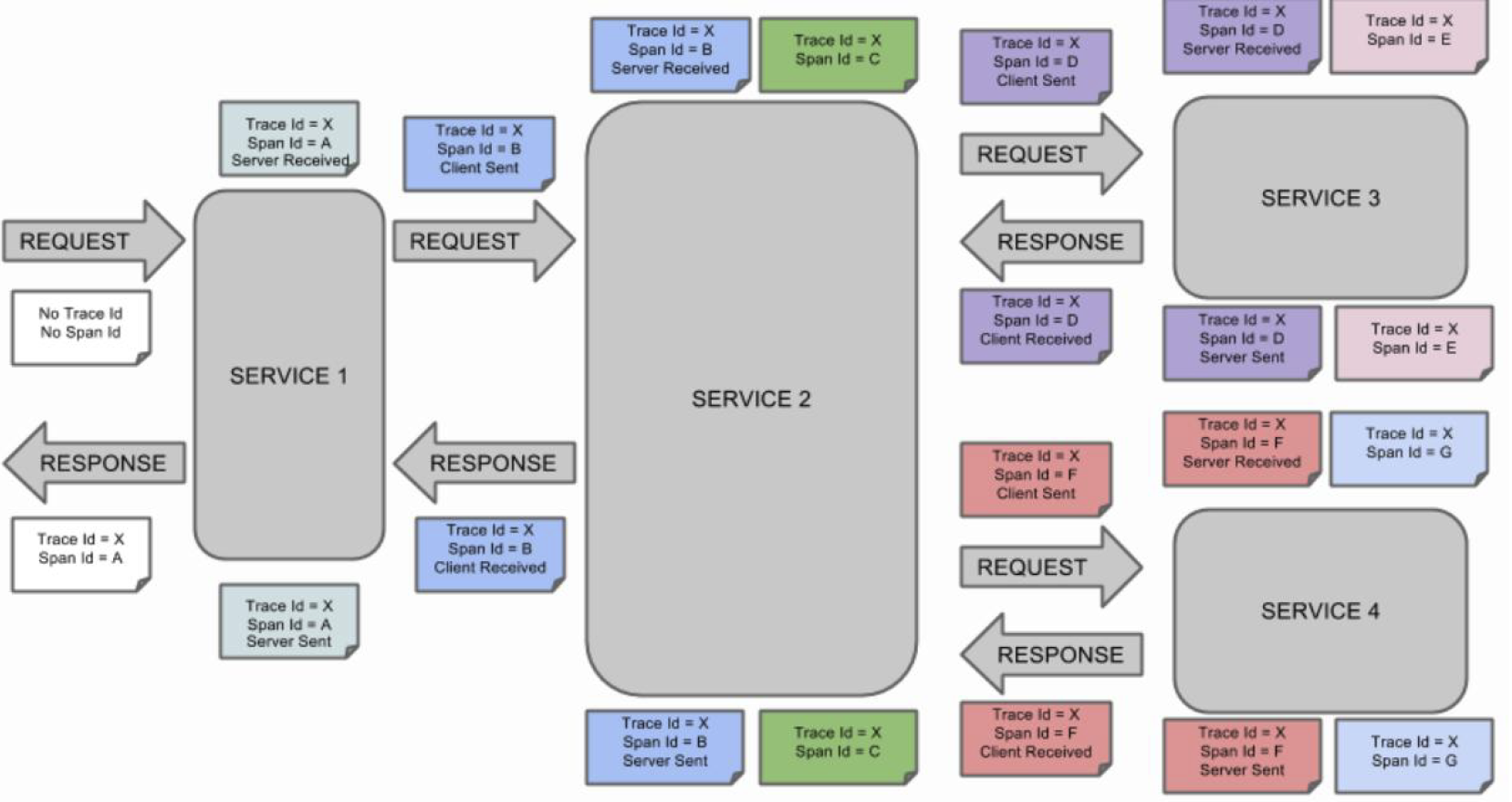
梳理
- 表示一请求链路,一条链路通过Trace Id唯一标识, Span标识发起的请求信息,各span通过parent id关联起来。
- Trace:类似于树结构的Span集合,表示一条调用链路,存在唯一标识。
- Span:基本工作单元,表示调用链路来源,通俗的理解span就是一次请求信息。
spans 的parent/child 关系图形化
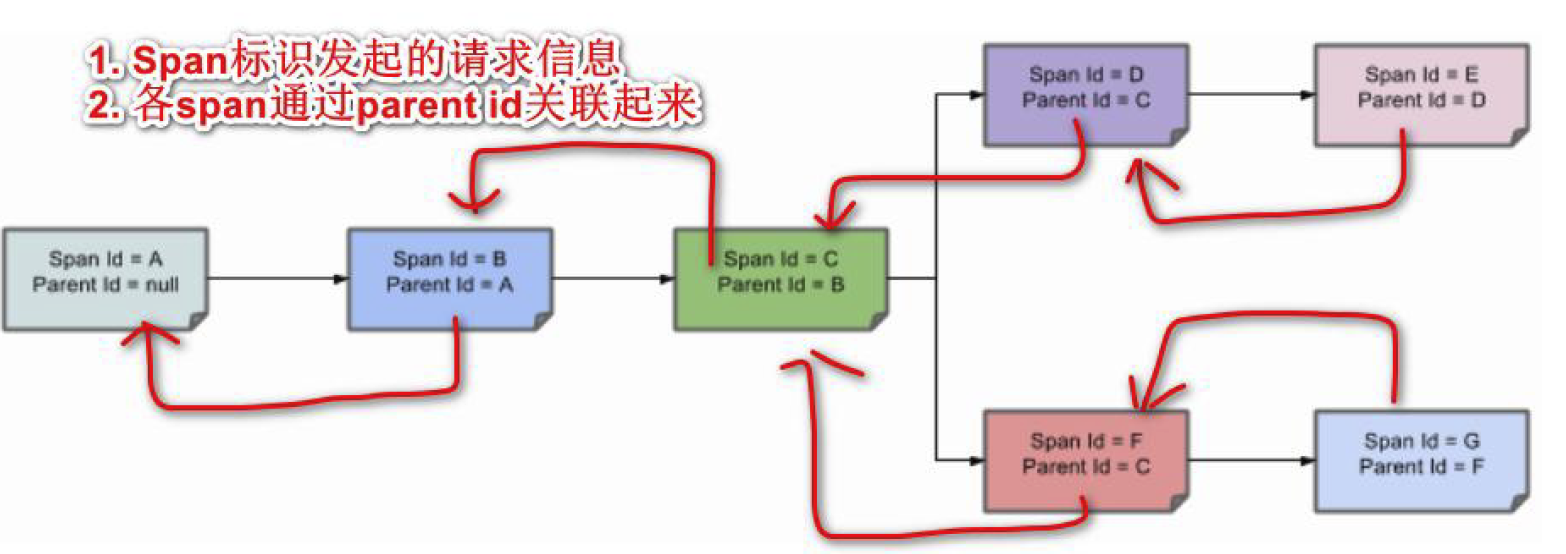
梳理
- 注意看标识的红线,后一个span节点的parentId 指向/记录了上一个Span解读。
- span就是一次请求信息。
- 多个Span集合就构成一条调用链路。
- 在span=C 这个节点存在分支。
Sleuth/ZipKin-搭建链路监控实例
需求说明/图解
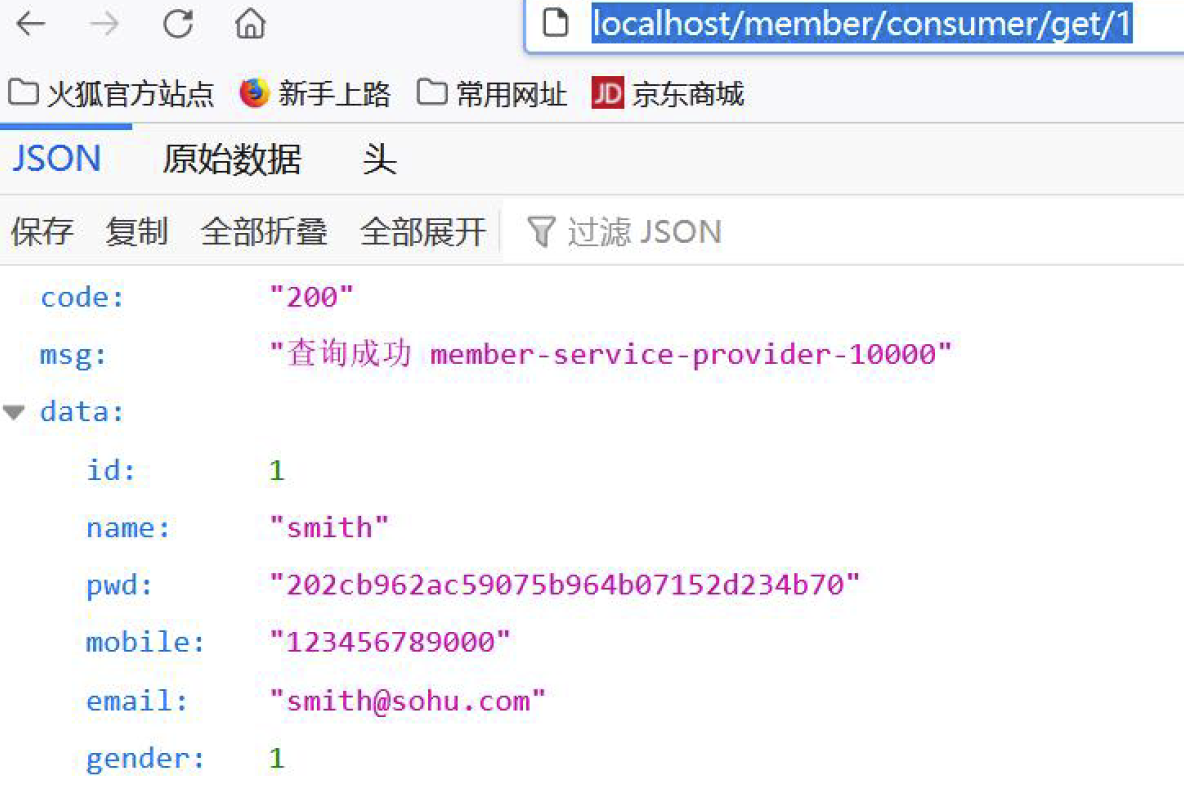
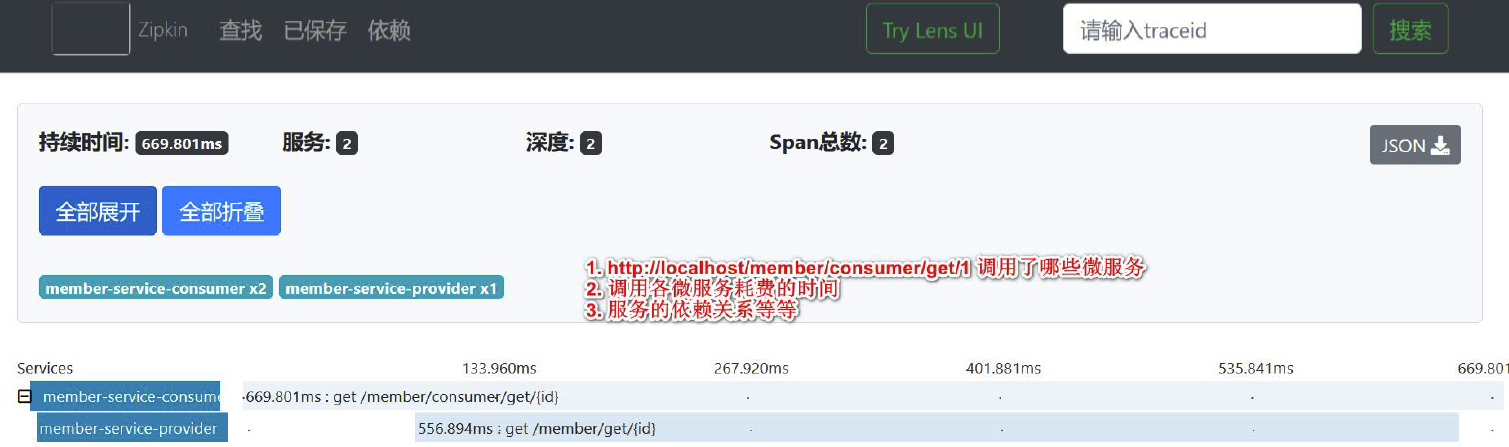
- 在浏览器输入: http://localhost/member/consumer/get/1 , 会返回对应的结果(如图)
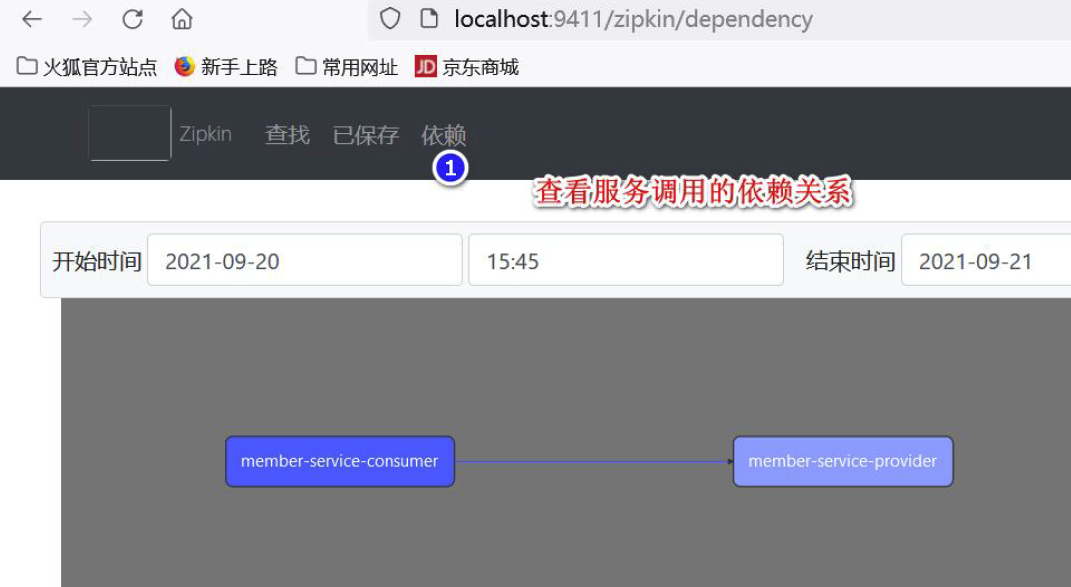
- 要求: 通过Sleuth 和Zipkin 可以对服务调用链路进行监控, 并在Zipkin 进行显示(如图)
安装/使用Zipkin
下载
- https://repo1.maven.org/maven2/io/zipkin/java/zipkin-server/2.12.9/
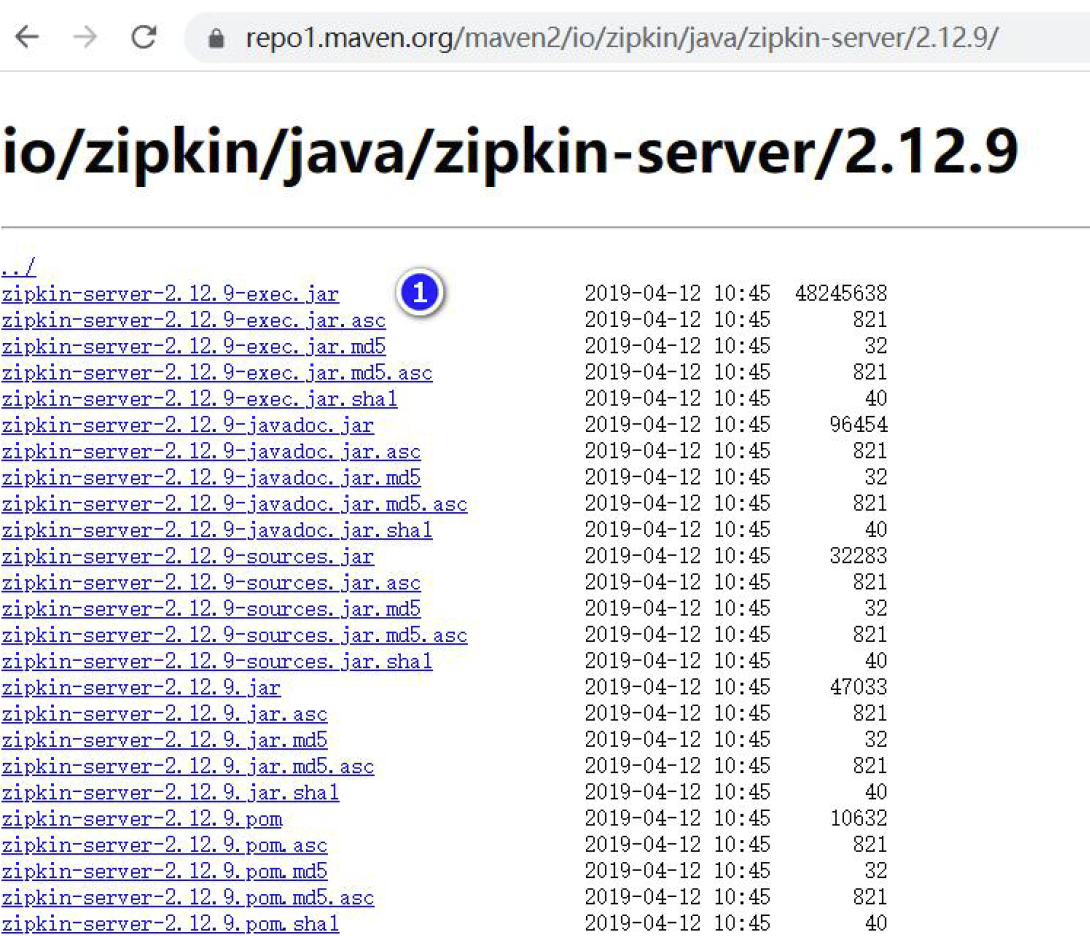
2.下载得到: zipkin-server-2.12.9-exec.jar
运行
- 把zipkin-server-2.12.9-exec.jar 放到指定的目录, 比如D:\program\zipkin
- 进入cmd , 执行指令运行: java -jar zipkin-server-2.12.9-exec.jar
访问
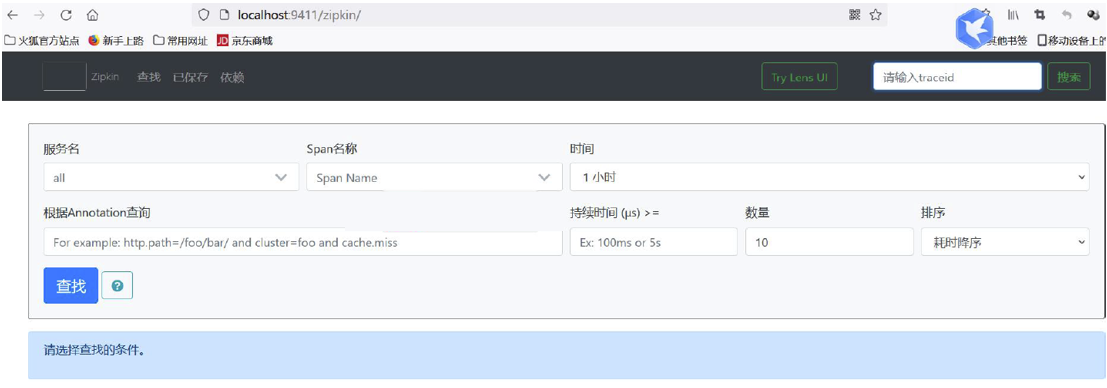
- 浏览器输入:http://localhost:9411/zipkin/
服务提供方集成Sleuth/Zipkin
- 修改member-service-provider-10000 的pom.xml , 增加引入sleuth+zipkin
<!--包含了sleuth+zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<!-- 引入eureka-client 依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
- 修改member-service-provider-10000 的appliaction.yml , 指定Zipkin
server:
port: 10000
spring:
application:
name: member-service-provider #配置应用的名称
#配置sleuth 和 zipkin
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
#采样率 在0-1之间, 1表示全部采集
probability: 1
datasource:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/e_commerce_center_db?useSSL=true&useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456
服务消费方集成Sleuth/Zipkin
- 修改member-service-consumer-80 的pom.xml , 增加引入sleuth+zipkin
<!--包含了sleuth+zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<!-- 引入eureka-client 依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
- 修改member-service-consumer-80 的appliaction.yml , 指定Zipkin
spring:
application:
name: member-service-consumer #配置应用的名称
#配置sleuth 和 zipkin
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
#采样率 在0-1之间, 1表示全部采集
probability: 1
测试
启动e-commerce-eureka-server-9001
启动member-service-provider-10000
启动member-service-consumer-80
浏览器: 浏览器输入: http://localhost/member/consumer/get/1
- 浏览器输入: http://localhost/member/consumer/get/1 , 多访问几次,方便看监控结果
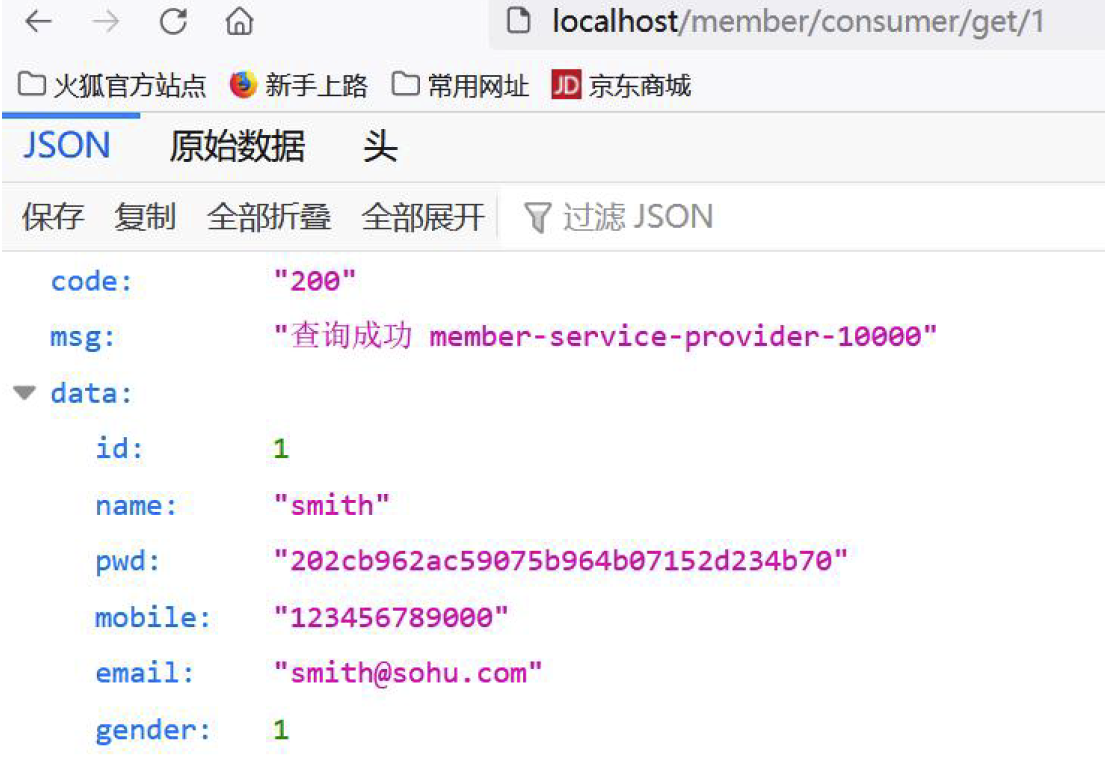
查看监控&分析结果
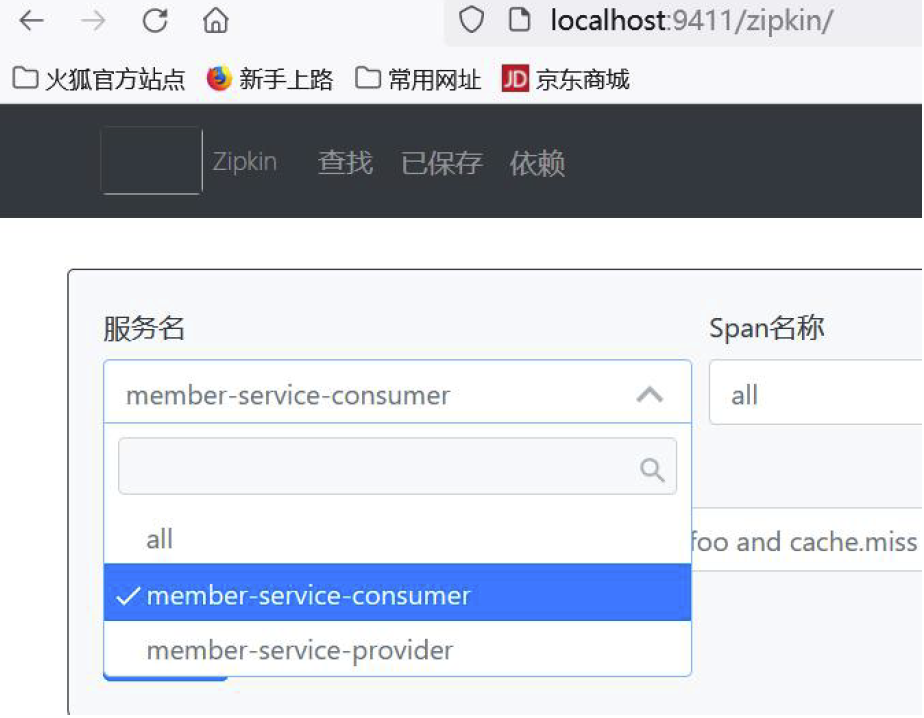
- 查看Zipkin : http://localhost:9411/zipkin/
- 选择某个服务,看结果
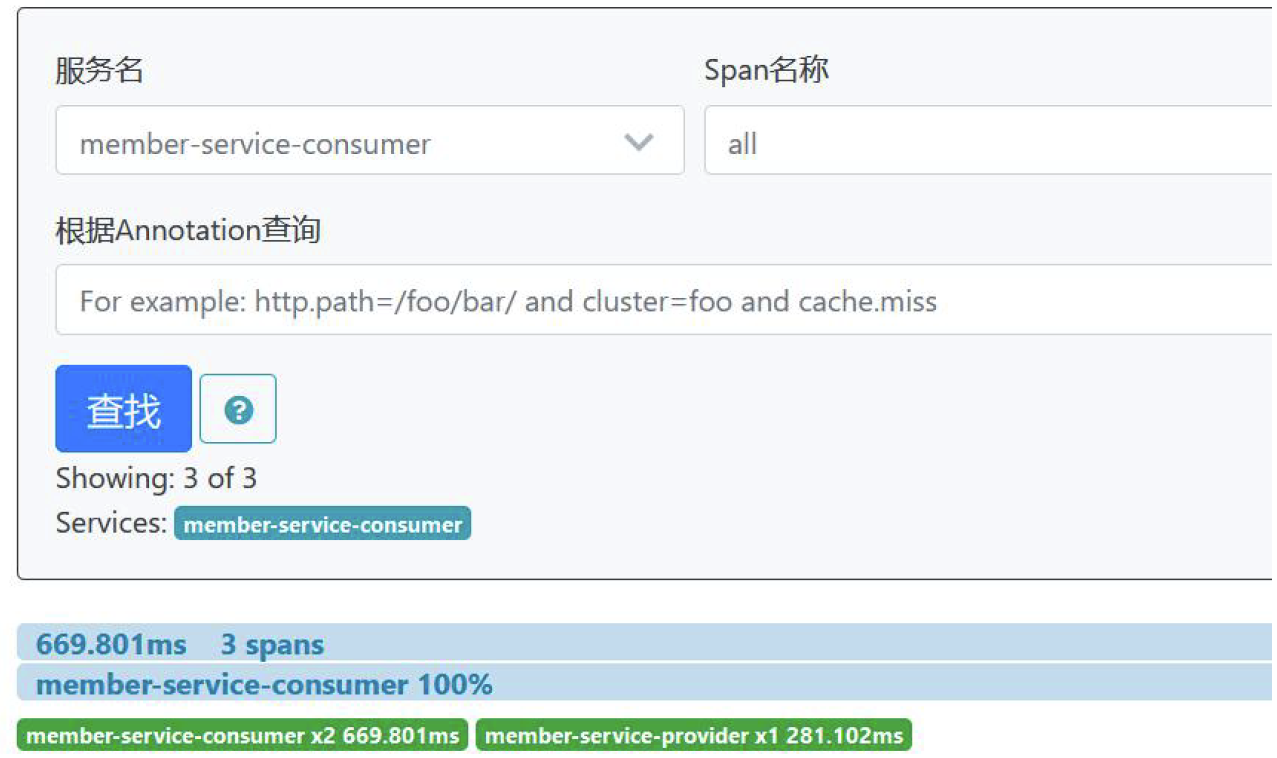
- 查看一次调用链路的深度,以及该链路包含请求, 各个请求耗时,找到请求瓶颈,为优化提供依据(重要)
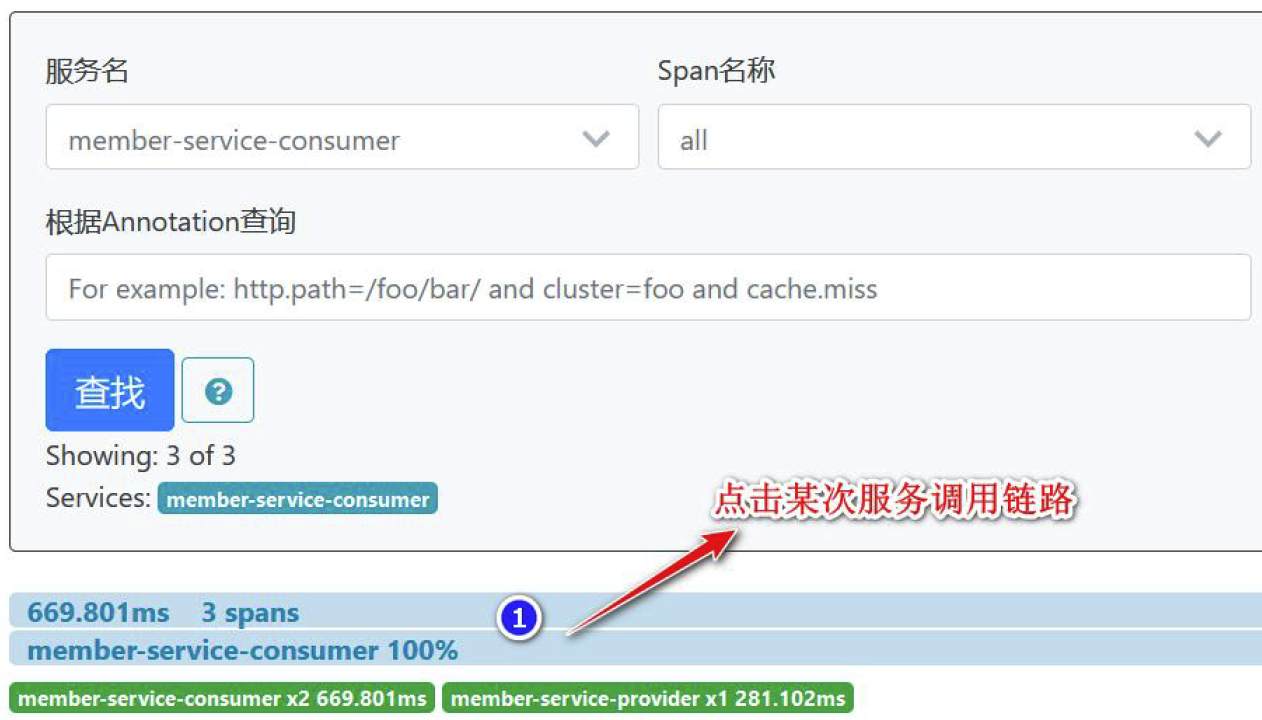

- 查看服务调用的依赖关系
文章到这里就结束了,如果有什么疑问的地方请指出,诸大佬们一起来评论区一起讨论😁
希望能和诸大佬们一起努力,今后我们一起观看感谢您的阅读🍻
如果帮助到您不妨3连支持一下,创造不易您们的支持是我的动力🤞