前言
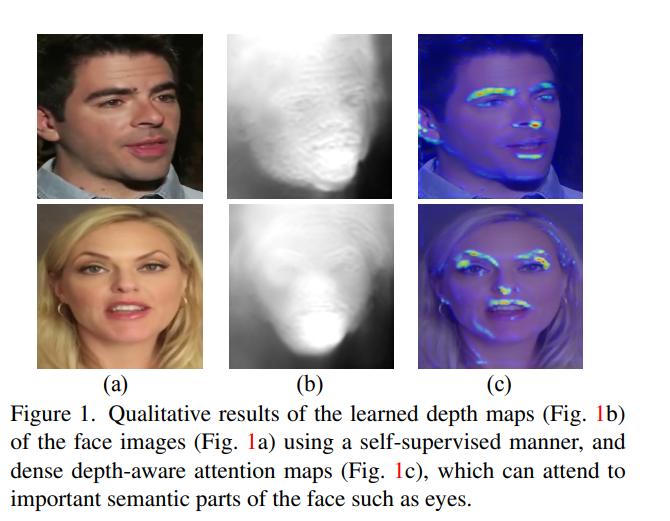
口播视频生成旨在合成具有源图像和驱动视频的身份和姿势信息的协同人脸视频。现有方法主要依赖于从输入图像中学到的二维表示(如外观和运动),但密集的三维面部几何信息(如像素深度)对任务至关重要。这有助于生成准确的三维面部结构,同时在复杂背景中区分噪声。然而,获取密集的三维几何标注通常成本高昂,难以用于视频生成。
一、论文解读
1.论文简介
在DaGAN这篇论文中,作者首先介绍了一种自监督的几何学习方法,可从人脸视频中自动还原密集的三维几何(深度),无需昂贵的三维标注数据。基于获得的密集深度图,进一步提出了一种方法,用于估计稀疏的面部关键点,以捕捉人类头部的关键运动。此外,利用深度信息来学习3D感知的跨模态注意力,以指导运动场景的生成,从而改进源图像的表示。
这些创新构成了一个全新的深度感知生成对抗网络,该网络基于估计的稀疏面部关键点以及用于生成说话头像的姿势工作(DaGAN)。广泛的实验结果表明,DaGAN提出的方法能够生成高度逼真的人脸,并在未见过的人脸上取得显著的成功。
这项研究的贡献在于克服了密集三维几何标注的挑战,以及提供了一种更精确和逼真的口播视频生成方法,有望在虚拟角色制作和其他人工智能应用中产生积极影响。
在DaGAN中,作者主要目标是利用一个人的源图像和一个可能来自另一个人的驱动视频,以生成高质量的合成口播视频。这项任务在现实世界中有广泛的实际应用,包括角色扮演的视频游戏和虚拟主播领域。
最近几年,通过生成对抗网络(GANs),口播视频生成方面取得了显著的进展,不仅在质量上有所提高,而且在鲁棒性方面也取得了重要突破。研究中的一个成功方法是将身份和姿势信息从面部图像中解耦出来。这包括一些开创性工作,如模型化两张人脸图像之间的相对姿势,并将其用于生成密集的运动场,以扭曲源图像的特征图以驱动合成图像。此外,有研究专门学习姿势和身份的两个潜在代码,然后将它们输入到设计的生成器网络中,用于合成人脸视频。此外,一些数据增强策略也被研究,以更有效地分离姿势和身份信息。尽管这些方法在任务上表现出了很好的性能,但它们仍然过于依赖于从输入图像中学习更具代表性的2D外观和运动特征。然而,对于人脸视频生成来说,三维密集几何信息对任务至关重要,但目前的方法中很少涉及。
密集的三维几何信息(如像素级深度图)对口播视频生成有多重好处。首先,由于视频捕捉的是真实三维物理世界中移动的头像,三维几何学可以极大地提高对三维人脸结构的准确恢复能力。这对于生成高质量的人脸视频至关重要。其次,密集几何信息有助于模型更稳健地区分噪声背景信息,特别是在复杂背景条件下生成图像时。最后,密集的几何信息还对模型识别与表情相关的微小运动非常有用。然而,利用三维密集几何信息来提升生成性能面临一个严重挑战,即三维几何标注通常昂贵且难以获取,不适用于这项任务。
为了解决这一问题,本文首先提出了一种自监督学习方法,通过几何扭曲和光度一致性从训练人脸视频中自动恢复像素级深度图,而无需昂贵的三维几何标注。基于学习到的密集深度图,我们进一步提出了两种机制,以更有效地利用深度信息,从而生成更逼真的对话式视频。第一个机制是深度引导的面部关键点检测,通过结合从深度图中学到的几何信息和从图像中学到的外观信息,以提高面部关键点的准确性。第二个机制是跨模态注意力机制,用于指导运动场的学习。由于运动场可能包含来自杂乱背景的噪声信息,并且不能有效地捕捉与表情相关的微动,我们提出了学习深度感知的注意力机制,以对运动场进行像素级的三维几何约束,从而生成更精细的面部结构和运动细节。这些方法的综合应用有望显著提高口播视频生成的质量和逼真度。
上述所有贡献构成了作者提出的深度感知生成对抗网络(DaGAN),用于推进口播视频的生成。广泛地在两个不同的数据集,即VoxCeleb1和CelebV上进行了实验,对DaGAN模型进行了定性和定量的评估。实验结果表明,自监督深度学习策略能够准确地恢复源和目标人脸图像的深度图。与当前最先进的方法相比,DaGAN模型能够生成更高质量的合成人脸图像。具体而言,DaGAN的模型能够更好地保留面部细节,生成具有更准确表情和姿势的合成人脸。综上所述,DaGAN主要贡献包括以下三个方面:
- 创新性自监督学习方法:DaGAN首次引入了一种自监督学习方法,从人脸视频中准确地恢复密集的三维几何信息(深度图),并将其用于口播视频的生成。这种方法不需要昂贵的三维几何标注,为任务提供了一种高效且有效的解决方案。
- 深度感知生成对抗网络(DaGAN):DaGAN提出了一种新型的生成对抗网络,专门用于生成口播视频。DaGAN包括两个关键机制,即深度引导的面部关键点估计和跨模态注意力学习,这些机制有效地融入了深度信息,提高了生成网络的性能和准确性。
- 出色的生成性能:DaGAN的实验结果表明,DaGAN的方法能够准确地恢复人脸图像的深度信息,并在生成合成人脸图像方面表现出卓越性能。相对于当前最先进的技术,DaGAN模型能够更好地保留面部细节,生成具有更准确表情和姿势的合成人脸图像。
2.DaGAN相关工作
生成式对抗网络(GAN)是由Goodfellow等人首次提出的,用于在某些条件下生成高质量的图像。这一领域吸引了广泛的关注,研究者们在图像合成、文本到图像的转换以及图像绘制等任务中应用了GAN技术。在DaGAN的论文中,重点是利用GAN来引导口播视频生成,其中以无监督的方式学习了三维面部深度图,而无需事先具备深度信息的真实标签。
深度估计方面已经有许多研究,用于解决立体图像或视频序列的深度估计问题。其中一些方法采用了端到端的学习方法,通过视图合成作为监督信号,无监督地估计单眼视频序列的深度图。其他工作则处理了帧之间的遮挡问题,并使用自动掩码损失来处理静止像素,从而获得更好的深度估计结果。还有一些工作尝试学习相机的本征参数,以进行深度推断。然而,DaGAN的工作不同之处在于,DaGAN专注于以无监督的方式学习面部深度图,而这些深度图可以用于关键点检测,并在口播视频生成任务中引导模型生成更具细节和逼真度的人脸图像。
在口播视频生成领域,存在多种不同的驱动策略,包括图像驱动、地标驱动和音频驱动方法。图像驱动方法试图通过预测源图像和驱动图像的关键点来模拟局部运动,以排除脸部的身份信息。地标驱动方法使用面部地标来编码姿势信息,而音频驱动方法则从音频中提取姿势信息。与这些方法相比,DaGAN的工作以自监督的方式学习像素级深度图,为口播视频生成提供了有益的三维密集几何信息,从而使生成模型更准确地感知人脸的三维结构,并生成更细致的人脸细节。这一方法在口播视频生成任务中具有潜在的优势。
3.论文概述
DaGAN提出的方法包括一个生成器和一个判别器。DaGAN的生成器的核心网络结构在图2中描述,而判别器的实现直接受FOMM的启发。DaGAN的生成器网络可以分成三个部分:
- 自监督深度信息学习子网络Fd,从视频中两个连续帧自监督学习深度估计;然后固定Fd进行整个网络训练;
- 深度信息引导的稀疏关键点检测子网络Fkp;
- 特征扭曲模块利用关键点生成变化区域,其将扭曲源图特征已将外观信息与运动信息结合,得到扭曲特征Fw ;为确保模型关注细节及面部微表情,进一步学习关注深度信息的attention map,其精细化Fw得到Fg,用于生成图像;

二、项目源码与部署
项目源码地址:https://github.com/harlanhong/CVPR2022-DaGAN
1. 环境安装
官方建议的环境:
Python >= 3.7 (Recommend to use Anaconda or Miniconda)
PyTorch >= 1.7
NVIDIA GPU + CUDA
Linux
我当前的环境是win10,GPU是N卡3060,使用cuda 11.8,cudnn 8.5,为了之后方便封装,使用conda来安装环境:
conda crate -n dagan python=3.10
activate dagan
conda install pytorch2.0.0 torchvision0.15.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
下载项目:
git clone https://github.com/harlanhong/CVPR2022-DaGAN.git
cd CVPR2022-DaGAN
安装依赖:
pip install -r requirements.txt
cd face-alignment
pip install -r requirements.txt
python setup.py install
2.模型下载
模型从OneDrive下载:
3.数据准备
要剪切使用来驱动人脸图像的视频,和准备要驱动的图像,我这里剪切的大小是256*256,然后:
然后运行:
python demo.py --config config/vox-adv-256.yaml --driving_video dataset/20.mp4 --source_image dataset/41.jpg --checkpoint model/DaGAN_vox_adv_256.pth.tar --relative --adapt_scale --kp_num 15 --generator DepthAwareGenerator
4.运行效果