python学习——各种模块argparse、os、sys、time、re、sched、函数体
- 各种模块学习
- 1. python脚本
- 2. argparse模块:撰写帮助文档,命令行参数定义等
- 3. os模块:用于文件/目录路径或名字的获取
- 4. sys模块:用于对命令行参数进行获取处理
- 5. time模块
- 6. re模块:一个特别重要的字符串处理模块,与正则表达式共同使用
- 7. 自定义函数
各种模块学习
python模块=perl模板=R包,别人写好的脚本程序,直接使用。你也可以自己写一个,后续学习。
pip install numpy 下载安装python包(一个命令行命令)
import numpy 导入numpy包(在python脚本或python交互界面中使用)
import numpy as np 导入numpy包,并重新命名为np
1. python脚本
在linux下,生成一个空白文件,命名为test.py(touch test.py)。使用vim进行编辑
这个文件最上面一行,通常是#!/usr/bin/python3,用于指定python解析器的位置。
情况一:
使用chmod 775 test.py,修改文件权限,使其可执行。如果这时,使用./test.py,则是使用这一行指定的解析器
情况二:
不修改文件权限,使用home/zhaohuiyao/miniconda3/bin/python3 ./test.py,则是使用命令前面指定解析器,与文件内指定无关
2. argparse模块:撰写帮助文档,命令行参数定义等
- 导入:import argparse
- 主要有三个函数:
parser=argparse.ArgumentParser(),其中参数用于描述帮助文档
parser.add_argument(),具体每一个参数的具体的信息,包括名称,类型,是否必须等等信息
args=parser.parse_args(),将所有的参数添加到一起,后续使用args.参数名。 - 这些信息会在执行python test.py --help/-h时出现
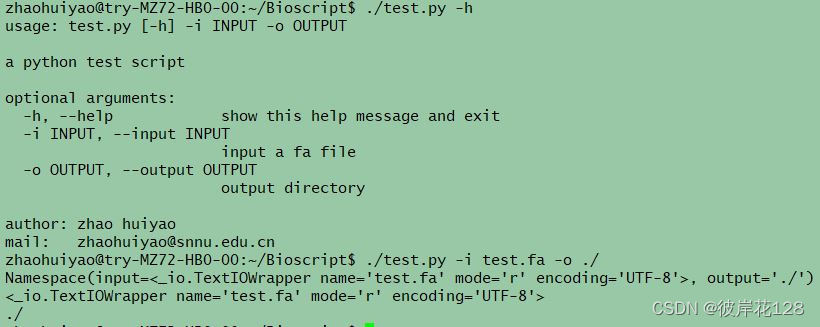
** 直接上例子,这是一个通用模板,你的所有python脚本都可以这样写 **
touch test.py
vim编辑
#!/usr/bin/python3
#一个python测试脚本
import argparse #导入模块
#将在该脚本帮助文档中显示,该python脚本撰写人和邮件
__author__='zhao huiyao'
__mail__='zhaohuiyao@snnu.edu.cn'
def main():
parser=argparse.ArgumentParser(description='a python test script',formatter_class=argparse.RawDescriptionHelpFormatter,epilog='author:\t{0}\nmail:\t{1}'.format(__author__,__mail__))
parser.add_argument('-i','--input',help='input a fa file',type=argparse.FileType('r'),dest='input',required=True)
parser.add_argument('-o','--output',help='output directory',required=True)
args=parser.parse_args()
print(args)
print(args.input);print(args.output)
#调用主函数
if __name__ == '__main__':
main()
chmod 775 ./test.py
./test.py -h
./test.py -i test.fa -o ./
3. os模块:用于文件/目录路径或名字的获取
- 导入:import os
- 在python脚本中,__file__表示该python脚本文件以及你在调用该脚本使用的路径。例如:python3 ./gc.py,为.gc.py;python3 /home/zhaohuiyao/python/gc.py,为/home/zhaohuiyao/python/gc.py
- 主要函数
os.path.basename():仅返回文件名字
os.path.dirname():返回文件相对路径。提供的不同,则返回值不同
os.path.abspath():返回路径或文件的绝对路径
os.path.exists():判断路径是否存在
os.path.splitext():对文件名进行切割,即以最后一个.为分割符。os.path.splitext(“test.fa”),得到一个元组(‘test’, ‘.fa’)。os.path.splitext(“test.fa”)[0]表示为test,即文件名。os.path.splitext(“test.fa.txt”),得到一个元组(‘test.fa’, ‘.txt’)。
os.path.join():连接,生成一个新的路径。output1_name=os.path.join(args.output, “result.fa”)
os.system():执行系统命令
os.system(‘mkdir -p /home/zhaohuiyao/test/python/os/’) #在运行python脚本时,遇到该语句,则执行其中的命令。如果你的命令中有参数,使用format函数。os.system(‘cp {0} /home/zhaohuiyao/test.txt’.format( file1))。其中file1在前面已经定义。
** 直接上例子 **
#!/usr/bin/python3 #python的位置
import os
file_name = os.path.basename(__file__) #python脚本文件名字
pydir = os.path.dirname(__file__) #python脚本文件相对路径,提供不同,则不同,一般直接取绝对路径
filedir = os.path.abspath(__file__) #python脚本文件绝对路径
bindir = os.path.abspath(os.path.dirname(__file__)) #python所在目录绝对路径
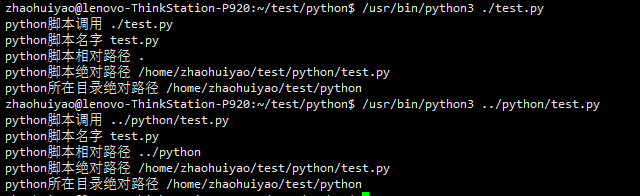
print ('python脚本调用', __file__) #调用python脚本文件是给的路径
print ('python脚本名字', file_name);print ('python脚本相对路径', pydir);print ('python脚本绝对路径', filedir);print ('python所在目录绝对路径', bindir)
4. sys模块:用于对命令行参数进行获取处理
- 导入:import sys
- sys.argv[]:表示命令行参数。执行python脚本:/usr/bin/python3 ./gc.py -i ./test.fa。其中sys.argv[0]:./gc.py;sys.argv[1]:-i;sys.argv[2]:./test.fa
#现在直接用前面提到的argparse模块中的命令,不常使用了,见到认识即可
5. time模块
- 导入:import time
- 这个模块用于时间获取和转换,通常是用于标准化流程中日志文件的描述。
我通常会在python流程脚本前面用到下面定义的两个函数,以方便自己在后续查看报错信息。
tt=time.time(),这个时间是一个浮点数的值(1658979946.3368537),不是我们常见的时间。这里用time.strftime(“%Y-%m-%d %H:%M:%S”)(2022-07-28 11:45:46),这两个时间是一样的。常用就是这样,当然还有如%y:两位数的年丰;%l:12小时制等
time.sleep(),表示实现程序的延时。time.sleep(0.02):延时20毫秒。再运行下面的内筒
import sys
import os
import time
def std( level, message ):
now_time = time.strftime("%Y-%m-%d %H:%M:%S")
string = '{0} - {1} - {2} - {3}\n'.format( now_time, file_name, level, message ) #一定格式的string
if level == 'ERROR':
sys.stderr.write( string ) #输出报错的string
else:
sys.stdout.write( string ) #输出正确的string
#判断文件或目录是否存在
def file_exists( file_or_dir ) :
target = os.path.abspath( file_or_dir )
if not os.path.exists( target ) :
std( 'ERROR', '{0} is not exists , program EXIT'.format( target ) )
sys.exit(0) #直接终止python脚本运行
else :
std( 'INFO', '{0} is exists'.format( target) )
return target
def main():
file_exists('/home/zhhuiyao/test/python/gc.py') #已知该文件存在
if __name__ == '__main__':
main()
#执行:/usr/bin/python3 ../python/test.py
#输出:2022-04-25 18:22:18 - test.py - INFO - /home/zhaohuiyao/test/python/gc.py is exists
6. re模块:一个特别重要的字符串处理模块,与正则表达式共同使用
- re.match(pattern, string),表示从字符串string的起始位置匹配一个模式pattern,如果不是起始位置匹配成功的话,match()就返回none。匹配成功re.match方法返回一个匹配的对象。
- re.compile(),用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
- re.split()函数。用正则表达式切割
str1=“he llo w o rld”
re.split(r’\s’,str1),用单个空白字符进行切割,得到列表[‘he’, ‘’, ‘llo’, ‘w’, ‘o’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘rld’]
re.split(r’\s+‘,str1),用任意长度空白字符进行切割,得到列表[‘he’, ‘llo’, ‘w’, ‘o’, ‘rld’]
re.split(r’\s.‘,str1),用任意长度空白字符进行切割,得到列表[‘he’, ‘llo’, ‘’, ‘’, ‘’, ‘’, ‘rld’]
re.split(r’‘,str1),用任意长度空白字符进行切割,得到列表[’', ‘h’, ‘e’, ’ ', ’ ', ‘l’, ‘l’, ‘o’, ’ ', ‘w’, ’ ', ‘o’, ’ ', ’ ', ’ ', ’ ', ’ ', ’ ', ‘r’, ‘l’, ‘d’, ‘’]。单个字符切割,且前后各一个空白字符
7. 自定义函数
前面例子中就在自定义main主函数。
def 函数名(参数1,参数2,参数3,······):
函数体
return 变量1,变量2,······
情况一:
使用return指定函数返回值。例如
def sum(a,b):
c=a+b
return c
result=sum(1,2) 得到结果result=3
def sum(a,b):
c=a+b
d=a-b
return c.d
result=sum(1,2) 得到结果result[0]=3;result[1]=-1
情况二:
没有使用return函数,则不返回任何结果,但是函数体会运行,如果有文件生成之类,则会完成。;例如
def sum(a,b,file):
c=a+b
out1=open(file, ‘w’)
out1.write(“第一个数={};第二个数={};两数之和={}\n”.format( a,b,c))
out1.close()
sum(1,2,“/home/zhaohuiyao/Bioscript/test.txt”)
#会生成文件/home/zhaohuiyao/Bioscript/test.txt