目录
数据操作
N维数组样例
访问元素
数据操作实现
入门
运算符
广播机制
节省内存
转换为其他Python对象
数据预处理实现
数据操作
N维数组是机器学习和神经网路的主要数据结构。
N维数组样例

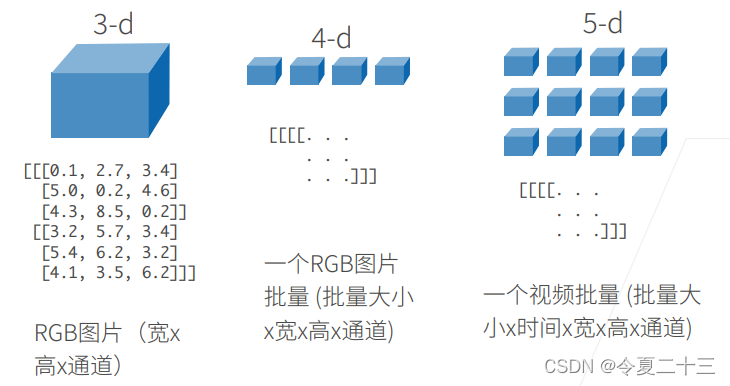
访问元素
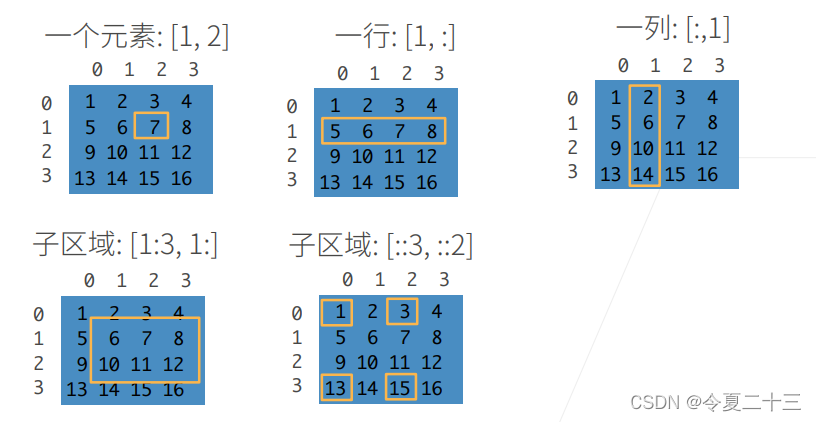
数据操作实现
下面介绍一下本课程中需要用到的PyTorch相关操作。
入门
import torch # 导入PyTorch库
x = torch.arange(12)# 创建一个长度为12的一维张量,元素从0到11
x.shape # 访问张量沿每个轴的长度,注意这里没有()
x.numel() # 张量的大小,也就是所有元素的数量
X = x.reshape(a, b) # 将张量的形状改为(a, b),其中a和b为整数,注意只是改变形状,不改变地址
torch.zeros((a, b, c)) # 创建一个形状为(a, b, c)的张量,所有元素都设置为0
torch.ones((a, b, c)) # 所有元素都设置为1
torch.randn(a, b) # 元素从均值为0、标准差为1的正态分布中随机采样运算符
import torch # 导入PyTorch库
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算
torch.exp(x) # 所有元素求对数
X = torch.arange(12, dtype=torch.float32).reshape((3,4)) # 所有元素设置为浮点数
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1) # 将两个矩阵在一维上连接起来
广播机制
当两个大小形状不同的矩阵做运算时,由于元素不能直接一一对应,所以会使用广播机制,通过适当复制元素来扩展一个或两个数组,以便在转换之后,两个张量具有相同的形状。
当然,触发广播机制是需要条件的:
- 两个张量必须不为空;
- 两个张量从最后一个维度比较,必须每个维度都满足这三个条件之一:两个相同,其中一个为1,其中一个为空。
import torch # 导入PyTorch库
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a + b
# tensor([[0, 1],
# [1, 2],
# [2, 3]])节省内存
import torch # 导入PyTorch库
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
Y = torch.tensor([[7, 8, 9], [3, 2, 1]])
before = id(Y)
Y = Y + X
id(Y) == before
# false
# 输出结果表明,这个加法操作改变了Y的指向,也就指向了新的内存地址
Z = torch.zeros_like(Y)
print('id(Z):', id(Z))
Z[:] = X + Y
print('id(Z):', id(Z))
# id(Z): 2219878943616
# id(Z): 2219878943616
# 将两个矩阵相加后赋值给同样大小的全零矩阵,内存地址就不会变了
# 这样就可以节省内存开销转换为其他Python对象
不同库里的张量的数据类型也不同,但是可以把表示张量的字符看作指针,不同库的指针可以指向同一个张量,也就是共享底层内存,因此,改变一个张量也可能同时改变另一个。
import torch # 导入PyTorch库
import numpy # 导入numpy库
X = torch.tensor([1, 2, 3])
A = X.numpy()
B = torch.tensor(A)
type(A), type(B)
# (numpy.ndarray, torch.Tensor)
a = torch.tensor([3.5])
a, a.item(), float(a), int(a)
# (tensor([3.5000]), 3.5, 3.5, 3)
# 用item函数可以将张量转换为python标量数据预处理实现
import os
os.makedirs(os.path.join('..', 'data'), exist_ok = True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
# 创建一个人工数据集,并存储在csv文件中
# csv文件是以逗号分隔值的表格文件
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名:房间数,是否有路,价格
f.write('NA,Pave,127500\n')
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
import pandas as pd
data = pd.read_csv(data_file) # 使用pandas里的pd函数读取数据
data
# NumRooms Alley Price
#0 NaN Pave 127500
#1 2.0 NaN 106000
#2 4.0 NaN 178100
#3 NaN NaN 140000
# 下面是处理缺失的插值法
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] # inputs为data的前两列,outputs为最后一列
inputs = inputs.fillna(inputs.mean()) # 对于inputs中缺失的数据,用同一列的均值替换“NaN”
print(inputs)
# 因为inputs中的离散值只有两个:Pave和NaN,所以可以把它们标准化为1和0
inputs = pd.get_dummies(inputs,dummy_na = True)
print(inputs)
import torch
X = torch.tensor(inputs.to_numpy(dtype=float)) # 将数据转换为张量格式
y = torch.tensor(outputs.to_numpy(dtype=float))
X, y以上是数据预处理的基本操作,还有很多进阶操作需要进一步学习,比如作业中的删除NaN值最多的列等,这些只是基础中的基础。
![2023年中国互联网本地生活服务行业发展历程及趋势分析:国内市场仍有增长潜力[图]](https://img-blog.csdnimg.cn/img_convert/6d00f3c30ae465626960c0107935b591.png)







![2023年中国喷头受益于技术创新,功能不断提升[图]](https://img-blog.csdnimg.cn/img_convert/0ba53a9924c5c1dc875170eb4d986c10.png)