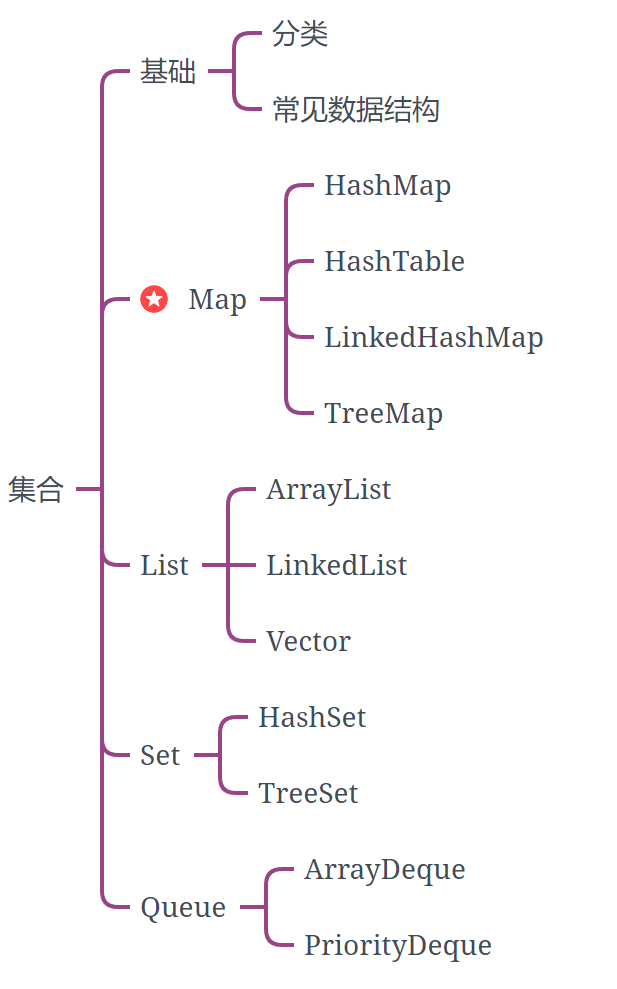
文章目录
- 1、HashMap基础
- 类属性
- node
- 容量
- 负载因子
- hash算法
- 2、数组+链表/树
- 为什么引入链表
- 为什么jdk1.8会引入红黑树
- 为什么一开始不就使用红黑树?
- HashMap的底层数组取值的时候,为什么不用取模,而是&
- 数组的长度为什么是2的次幂
- 如果指定数组的长度不为 2次幂,就破坏了数组的长度是2次幂的这个规则吗?
- 3、HashMap源码
- 构造方法
- put()方法
- get()方法
- HashMap扩容原理
- jdk1.7
- jdk1.8
- 经典面试题
- HashMap不安全的原因
- 常用方法
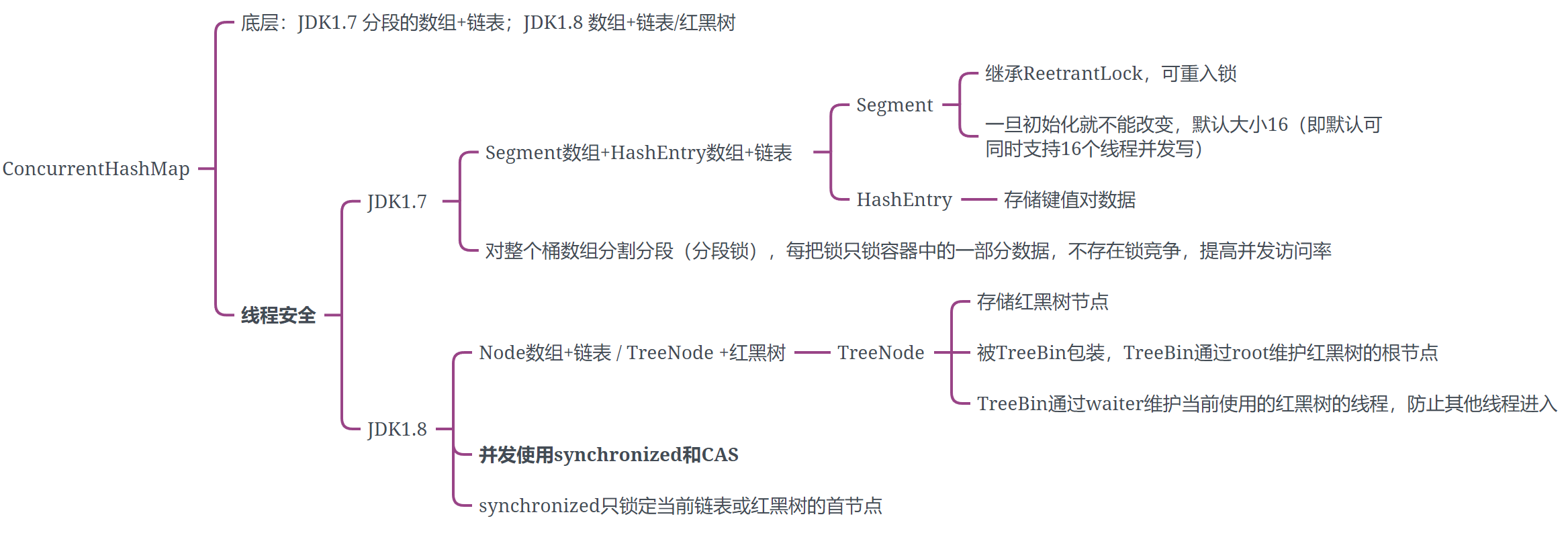
- 4、ConcurrentHashMap
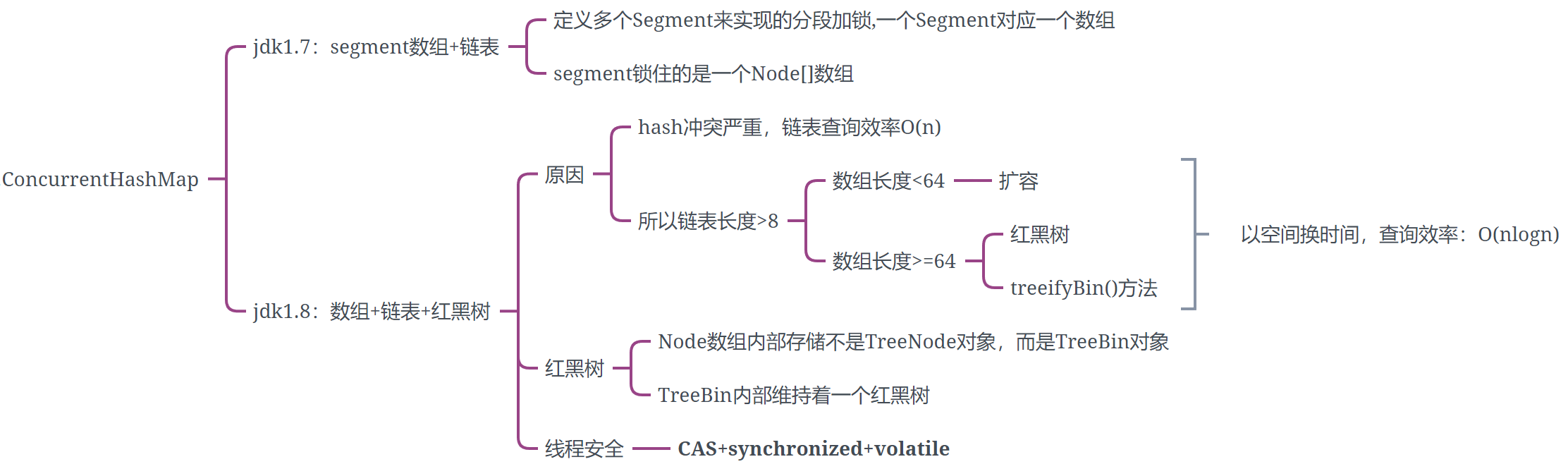
- 1.7
- 1.8
- 总结
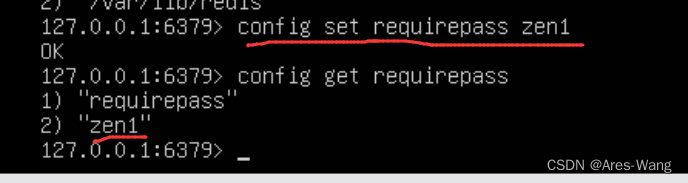
null作为key只能有一个,作为value可以有多个
1、HashMap基础
类属性
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列号
private static final long serialVersionUID = 362498820763181265L;
// 默认的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于等于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于等于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的table的最小容量
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储元素的数组,总是2的幂次倍
transient Node<k,v>[] table;
// 存放具体元素的集
transient Set<map.entry<k,v>> entrySet;
// 存放元素的个数,注意这个不等于数组的长度。
transient int size;
// 每次扩容和更改map结构的计数器
transient int modCount;
// 阈值(容量*负载因子) 当实际大小超过阈值时,会进行扩容
int threshold;
// 负载因子
final float loadFactor;
}
node
HashMap的内部类 Node<K, V> ,实现了Entry接口
// 属性
final int hash;
final K key;
V value;
Node<K,V> next;
next:记录下一个Node节点,通过next可顺序遍历链表所有节点
容量
默认16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
负载因子
默认0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
扩容触发:元素个数 > 容量 * 负载因子,扩容
hash算法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
1、先获取key的hashCode值——h
2、h与h右移16位做异或运算——低16位与高16位做异或运算,高16位参与hash,减少冲突
2、数组+链表/树
为什么引入链表
HashMap底层是数组,当进行put操作时,会进行hash计算,判断元素位置。当多个元素在同一个数组位置时,会引起hash冲突,因此引入链表,解决hash冲突
为什么jdk1.8会引入红黑树
当链表长度大于8时,遍历查找效率较慢,故引入红黑树
链表长度>8,且数组长度>64,才变成红黑树
为什么一开始不就使用红黑树?
红黑树相对于链表维护成本大,红黑树在插入新数据之后,可能会通过左旋、右旋、变色来保持平衡,造成维护成本过高,故链路较短时,不适合用红黑树
HashMap的底层数组取值的时候,为什么不用取模,而是&
i = (n - 1) & hash
计算机运算时,&比取模运算快
数组的长度为什么是2的次幂
1、减少hash冲突
数据均匀分布,可以减少hash冲突,所以使用hashCode%size可以最大程度的平均分配。当n为2的次幂时,(n-1)&hash=hash%n
2、&运算速度比%快,Java中快10倍左右
3、保证索引值在capacity中不会超出数组长度
如果指定数组的长度不为 2次幂,就破坏了数组的长度是2次幂的这个规则吗?
不会的,HashMap 的tableSizeFor方法做了处理,能保证n永远都是2次幂
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
//cap-1后,n的二进制最右一位肯定和cap的最右一位不同,即一个为0,一个为1,例如cap=17(00010001),n=cap-1=16(00010000)
int n = cap - 1;
//n = (00010000 | 00001000) = 00011000
n |= n >>> 1;
//n = (00011000 | 00000110) = 00011110
n |= n >>> 2;
//n = (00011110 | 00000001) = 00011111
n |= n >>> 4;
//n = (00011111 | 00000000) = 00011111
n |= n >>> 8;
//n = (00011111 | 00000000) = 00011111
n |= n >>> 16;
//n = 00011111 = 31
//n = 31 + 1 = 32, 即最终的cap = 32 = 2 的 (n=5)次方
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
3、HashMap源码
构造方法
// 默认构造函数
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
// 包含另一个“Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 指定“容量大小”和“负载因子”的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
// 初始容量暂时存放到 threshold ,在resize中再赋值给 newCap 进行table初始化
this.threshold = tableSizeFor(initialCapacity);
}
四个构造方法中,都初始化了负载因子 loadFactor。HashMap中没有 capacity字段,初始化容量initialCapacity 是通过tableSizeFor 将其扩容到与 initialCapacity 最接近的2的幂次方大小,然后暂时赋值给 threshold ,后续通过 resize 方法将 threshold 赋值给 newCap 进行 table 的初始化
put、get是jdk1.8时的情况
put()方法
1、key是null,直接插入
2、key不为null,判断key是否与put(key)相同,相同返回老key
3、key不为null,如果索引位置的值是树结构,调用putTreeVal()添加数据
4、key不为null,如果索引位置的值是链表结构,遍历链表,key相同时返回值;遍历到尾部也不同,尾插法插入数据
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果table为空,或者还没有元素时,则扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 如果首结点值为空,则创建一个新的首结点。
// 注意:(n - 1) & hash才是真正的hash值,也就是存储在table位置的index。在1.6中是封装成indexFor函数。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else { // 到这儿了,就说明碰撞了,那么就要开始处理碰撞。
Node<K,V> e; K k;
// 如果在首结点与我们待插入的元素有相同的hash和key值,则先记录。
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) // 如果首结点的类型是红黑树类型,则按照红黑树方法添加该元素
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { // 到这一步,说明首结点类型为链表类型。
for (int binCount = 0; ; ++binCount) {
// 如果遍历到末尾时,先在尾部追加该元素结点。
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 当遍历的结点数目大于8时,则采取树化结构。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 如果找到与我们待插入的元素具有相同的hash和key值的结点,则停止遍历。此时e已经记录了该结点
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 表明,记录到具有相同元素的结点
if (e != null) { // existing mapping for key
V oldValue = e.value;
// onlyIfAbsent表示如果当前位置已存在一个值,是否替换,false是替换,true是不替换
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // 这个是空函数,可以由用户根据需要覆盖
return oldValue;
}
}
++modCount;
// 当结点数+1大于threshold时,则进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict); // 这个是空函数,可以由用户根据需要覆盖
return null;
}
HashMap在put()的时候,如果put一个已经存在的key,那么会把老的key对应的value值返回
public static void main(String[] args) {
HashMap<Integer, Integer> map = new HashMap<>();
map.put(1,5);
Integer put = map.put(1, 8);
System.out.println(put); // 5
}
get()方法
1、获取key对应的数组位置 key?=key.hashCode()
2、节点为树节点,调用getTreeNode();不为树节点(链表节点),循环遍历链表查值
3、都没查到,返回null
public V get(Object key) {
//定义一个Node对象来接收
Node<K,V> e;
//调用getNode()方法,返回值赋值给e,如果取得的值为null,就返回null,否则就返回Node对象e的value值
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
//取hash值方法,HashMap的put方法的也是调用了这个方法,get方法也调用这个方法,保证存取时key值对应的hash值是一致的,这样才能正确对应
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final Node<K,V> getNode(int hash, Object key) {
//定义几个变量
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//首先是判断数组table不能为空且长度要大于0,同时把数组长度tab.length赋值给n
if ((tab = table) != null && (n = tab.length) > 0 &&
//其次是通过[(n - 1) & hash]获取key对应的索引,同时数组中的这个索引要有值,然后赋值给first变量
(first = tab[(n - 1) & hash]) != null) {
//这个first其实就是链表头的节点了,接下来判断first的hash值是否等于传进来key的hash值
if (first.hash == hash &&
//再判断first的key值赋值给k变量,然后判断其是否等于key值,或者判断key不为null时,key和k变量的equals比较结果是否相等
((k = first.key) == key || (key != null && key.equals(k))))
//如果满足上述条件的话,说明要找的就是first节点,直接返回
return first;
//走到这步,就说明要找的节点不是首节点,那就用first.next找它的后继节点 ,并赋值给e变量,在这个变量不为空时
if ((e = first.next) != null) {
//如果首节点是树类型的,那么直接调用getTreeNode()方法去树里找
if (first instanceof TreeNode)
//这里就不跟进去了,获取树中对应key的节点后直接返回
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//走到这步说明结构还是链表
do {
//这一步其实就是在链表中遍历节点,找到和传进来key相符合的节点,然后返回
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
//获取e节点的后继节点,然后赋值给e,不为空则进入循环体
} while ((e = e.next) != null);
}
}
//以上条件都不满足,说明没有该key对应的数据节点,返回null
return null;
}
HashMap扩容原理
jdk1.7
什么时候扩容?扩容多少?
重要成员变量:
- size:map中包含的Entry数量
- threshold:扩容的阈值,threshold = loadFactor * capacity
- capacity:桶的长度
1、当map中包含的Entry的数量大于等于threshold = loadFactor * capacity的时【size>=threshold】,且新建的Entry刚好落在一个非空的桶上,此刻触发扩容机制,将其容量扩大为2倍
2、当size大于等于threshold的时候,并不一定会触发扩容机制,但是会很可能就触发扩容机制,只要有一个新建的Entry出现哈希冲突,则立刻resize
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
// 当size大于等于某一个阈值thresholdde时候且该桶并不是一个空桶;
resize(2 * table.length);//将容量扩容为原来的2倍
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);//扩容后的,该hash值对应的新的桶位置
}
createEntry(hash, key, value, bucketIndex);//在指定的桶位置上,创建一个新的Entry
}
扩容过程
rezise大致思想:先计算新的容量和threshold,在创建一个新hash表,最后将旧hash表中元素rehash到新的hash表中
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
//最大容量为 1 << 30
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];//新建一个新表
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;//是否再hash
transfer(newTable, rehash);//完成旧表到新表的转移
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
//遍历同桶数组中的每一个桶
while(null != e) {
//顺序遍历某个桶的外挂链表
Entry<K,V> next = e.next;//引用next
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);//找到新表的桶位置;原桶数组中的某个桶上的同一链表中的Entry此刻可能被分散到不同的桶中去了,有效的缓解了哈希冲突。
e.next = newTable[i];//头插法插入新表中
newTable[i] = e;
e = next;
}
}
}
多线程下,transfer缺乏同步机制,可能出现大量线程对新桶数组进行transfer,造成死循环、数据丢失,因此HashMap不安全。
jdk1.8
相比于1.7,resize做了很大改进
1、参数:oldCap——原table长度,newCap——新table长度,newCap=2*oldCap
2、4个变量:loHead、loTail、hiHead、hiTail,用于计算table下标的新算法
- 正常情况:hash&(oldTable.length-1)
- 扩容之后:hash&(newTable.length-1)=hash&(2*oldTable.length-1)
e.hash & oldCap:用于计算位置b到底是0还是1用的,只要其结果是0,则新散列下标=原散列下标,否则新散列坐标要在原散列坐标的基础上加上原table长度
- loHead,下标不变情况下的链表头
- loTail,下标不变情况下的链表尾
- hiHead,下标改变情况下的链表头
- hiTail,下标改变情况下的链表尾
(e.hash & oldCap) == 0:代表散列下标不变的情况下,只使用了loHead和loTail两个参数,由他们组成了一个链表,否则将使用hiHead和hiTail参数
所以,只要loTail不是null,说明链表中的元素在新table中的下标没变,所以新table的对应下标中放的是loHead,另外把loTail的next设为null
hiTail不是null,说明链表中的元素在新table中的下标,应该是原下标加原table长度,新table对应下标处放的是hiHead,另外把hiTail的next设为null
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY) //注释1
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) { //注释2
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null) //注释3
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) { //注释4
if (loTail == null) //注释5
loHead = e;
else
loTail.next = e; //注释6
loTail = e; //注释7
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) { /注释8
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
经典面试题
1、计划用HashMap存1k条数据,构造时传1000会触发扩容吗
HashMap 初始容量指定为 1000,会被 tableSizeFor() 调整为 1024;但是它只是表示 table 数组为 1024;负载因子是0.75,扩容阈值会在 resize() 中调整为 768(1024 * 0.75)
会触发扩容,如果需要存储1k的数据,应该传入1000 / 0.75(1333)。tableSizeFor() 方法调整到 2048,不会触发扩容
2、计划用HashMap存1w条数据,构造时传10000会触发扩容吗
当我们构造HashMap时,参数传入进来 1w,经过 tableSizeFor() 方法处理之后,就会变成 2 的 14 次幂 16384负载因子是 0.75f,可存储的数据容量是 12288(16384 * 0.75f)。完全够用,不会触发扩容
HashMap不安全的原因
1、多线程put并发的时候可能造成数据的丢失
2、多线程put和get并发的时候,可能造成get为null
(线程1执行put时,因为元素个数超出threshold而导致rehash,线程2此时执行get,有可能导致这个问题)
jdk1.7中HashMap因为头插入,导致get时出现死循环;jdk1.8使用尾插法解决了死循环,但是还是会造成节点丢失问题
并发场景下,使用ConcurrentHashMap
常用方法
获取所有key:map.keySet()
获取所有value:map.values()
获取key对应的value:map.get(key)
遍历,同时获取key、value:
entrys = map.entrySet()
entry.getKey()
entry.getValue()
其他:
get、size、isEmpty、remove、replace、containsKey、containsValue
参考:https://blog.csdn.net/weixin_43689480/article/details/118752906
https://javaguide.cn/java/collection/hashmap-source-code.html
4、ConcurrentHashMap
详情请学习:https://javaguide.cn/java/collection/concurrent-hash-map-source-code.html
下面是一些知识点总结
1.7
1、存储结构
ConcurrentHashMap是由多个segment组合,每个segment内部是一个HashMap,HashMap内可进行扩容,但是segment初始化后不能更改,默认16个segment,也就是默认支持最多 16 个线程并发
segment数组+HashMap(HashEntry数组)+链表
2、初始化
// 无参构造
// initialCapacity-16默认初始化容量
// loadFactor-0.75f默认负载因子
// concurrencyLevel-16默认并发级别
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
// 有参构造
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
}
有参构造:
- 必要参数校验
- 校验并发级别 concurrencyLevel 大小,如果大于最大值,重置为最大值。无参构造默认值是 16.
- 寻找并发级别 concurrencyLevel 之上最近的 2 的幂次方值,作为初始化容量大小,默认是 16。
- 记录 segmentShift 偏移量,这个值为【容量 = 2 的 N 次方】中的 N,在后面 Put 时计算位置时会用到。默认是 32 - sshift = 28.
- 记录 segmentMask,默认是 ssize - 1 = 16 -1 = 15.
- 初始化 segments[0],默认大小为 2,负载因子 0.75,扩容阀值是 2*0.75=1.5,插入第二个值时才会进行扩容
3、put
- 计算要 put 的 key 的位置,获取指定位置的 Segment
- 如果指定位置的 Segment 为空,则初始化这个 Segment
- Segment.put 插入 key,value 值
初始化segment:
- 检查计算得到的位置的 Segment 是否为 null.
- 为 null 继续初始化,使用 Segment[0] 的容量和负载因子创建一个 HashEntry 数组
- 再次检查计算得到的指定位置的 Segment 是否为 null.
- 使用创建的 HashEntry 数组初始化这个 Segment.
- 自旋判断计算得到的指定位置的 Segment 是否为 null,使用 CAS 在这个位置赋值为 Segment
Segment 继承了 ReentrantLock**,所以** Segment 内部可以很方便的获取锁
scanAndLockForPut:不断自旋tryLock()获取锁;自旋次数>指定次数,lock()阻塞获取锁
4、rehash扩容
扩容到原来的2倍,要么位置不变,要么变为index+oldSize,扩容后使用链表头插法插入元素
5、get
- 计算得到 key 的存放位置
- 遍历指定位置查找相同 key 的 value 值
1.8
1、存储结构
Node数组+链表/红黑树
2、初始化
初始化是通过自旋和 CAS 操作完成的
变量:sizeCtl当前初始化状态
3、put
- 根据 key 计算出 hashcode
- 判断是否需要进行初始化
- 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功
- 如果当前位置的 hashcode == MOVED == -1,则需要进行扩容
- 如果都不满足,则利用 synchronized 锁写入数据
- 如果数量大于 TREEIFY_THRESHOLD 则要执行树化方法,在 treeifyBin 中会首先判断当前数组长度 ≥64 时才会将链表转换为红黑树
4、get
- 根据 hash 值计算位置
- 查找到指定位置,如果头节点就是要找的,直接返回它的 value
- 如果头节点 hash 值小于 0 ,说明正在扩容或者是红黑树,查找之
- 如果是链表,遍历查找之
总结





![2023年中国喷头受益于技术创新,功能不断提升[图]](https://img-blog.csdnimg.cn/img_convert/0ba53a9924c5c1dc875170eb4d986c10.png)