右值引用
我们先来了解什么是左值,什么是右值:
左值 和 有值 区分
首先,左值 和 右值 并不是完全意味着 在 "=" 左边的就是 左值 ; 在 "=" 右边的就是右值。这是不一定的。只能说,在左边的大概率是 左值,右边的可能是左值,也可能是右值:
int a = 1;
int b = a;如上述所示, a 是 左值,b 也是左值。
左值的概念:
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址,一般可以对它赋值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时const修饰符后的左值,不能给他赋值,但是可以取它的地址。左值引用就是给左值的引用,给左值取别名。
也就是说,可以获取地址的值,一般都是左值;
但是有一个例外,const 修饰的变量,不能对这个变量进行修改,但是可以对这个变量取地址,所以,这个变量还是左值,如下所示;
const int a = 1;
a += 1; // 编译报错如下所示,都是左值:
// 以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
// 以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;右值的概念:
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引用返回)等等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能取地址。右值引用就是对右值的引用,给右值取别名。
如下面例子都是右值:
double x = 1.1, y = 2.2;
// 以下几个都是常见的右值
10;
x + y;
fmin(x, y);上述的 10;
x+y 这个 x+y 表达式有一个返回值,这个返回值使用一个临时变量存储的,这里指的有值是 这个临时变量;
还有 fmin(x , y)函数当中的右值,是 函数当中传值返回的临时对象,
他们都有一个特点,都不能取地址。
如果强行取地址的话,就会被报错(必须是左值类似报错):

在了解 左右值 之后,我们来看 "xxxxxx"; 这个常量字符串是左值还是右值?
其实 常量字符串 是左值,就算我们如下面一种方式书写:
"xxxxxx";其实还是右值,虽然我们不能对这个常量字符串进行修改,但是我们能取到 这个字符串的地址:
const char* p = "xxxxxx";
cout << &("xxxxxx") >> endl;按照上述的 p 这个指针的理解,我们还是可以取到这个 字符串的 首字符地址。所以还是左值。
同样的 &p[2] 我们取出 常量字符串当中的 第三个 字符,还是可以取地址,说明,取出的 常量字符串的第三个 字符,还是左值。只是不能修改而已。
总结:可以取地址的就是左值;不能去取地址的就是右值;
左值引用 和 有值引用 区分
引用是取别名,左值引用 就是 对 左值取别名;右值引用 就是对 有值取别名。
// 左值引用
int a = 10;
int& pa = a;
// 右值引用
int&& p5 = 10;
double x = 1.1, y = 2.2;
double& r6 = x + y; // 编译报错
double&& r7 = x + y; // 编译通过如上所示: 类型& 是左值引用;而 类型&& 就是右值引用。
在上述例子当中的左值引用是没有办法给右值引用取别名的,但是如果是 const 的左值引用就可以给 右值 取别名:
const int& p = 10; // 编译通过所以,在之前写模版函数的时候,我们经常这样写:
template<class T> void func(const T& x) { ```````` }如果函数的参数是 模版的引用的话,都是建议加上 const 修饰的,因为加上const 的话,这个模版参数既可以接收 左值引用,有可以接收 右值引用。
那么右值引用,是否可以引用左值呢?
答案是可以。
但是也是不能直接 引用,加上 const 也不行,必须加上 move()函数,move一下:
int a = 1; int&& p1 = a; // 编译报错 int&& p2 = move(a); // 编译通过也就是说右值引用,可以引用 move 之后的左值,但是 右值 move 之后,虽然在上述例子当中没有什么问题,可正常使用,但是在一些情况下会出现问题,具体看下述说明。
左值引用的价值
在函数的参数传参,和 函数的返回值上,如果使用的是同类型的参数传参或者返回的话,是要构建一个临时变量来暂时存储要传入或者返回的值,然后再把 临时变量,拷贝给形参,或者是用于接收函数返回值的变量。如果是内置类型就还好,但如果是自定义的类型,一个对象需要的空间不小的话,那么拷贝就会造成不小的消耗。其中的消耗有空间上的,还有,如果是深拷贝的话,可能还有动态开辟当中的空间当中的值需要赋值,这就有时间上的消耗了。
那么在上述的过程当中肯定就会发生消耗,所以,我们可以使用左值引用的方式,使得传入的是实参(本对象),就是实参本身,所以是不用进行拷贝,函数当中的形参使用就是 传入实参本身。返回值也是一样,返回的是函数当中的 变量。
需要注意的是:如果返回的是,作用域在函数当中的变量,那么,当函数执行结束,这个变量也就跟着销毁了,如果我们返回的是这个 变量的引用的话,就会是野引用,和野指针的后果是一样。
int& func1(const int& x)
{
return x;
}
int main()
{
int x = 1;
int ret = func(x);
return 0;
}当然,左值引用带来很多的好处,但是也有左值引用做不到的事情:
就是上述的 函数的当中的变量,无法用 左值引用的方式来返回,在没有右值引用的情况下,我们只能直接传参返回,也就是要拷贝一个临时变量,然后赋值给外部的接收变量。
但是,我们知道,这样的拷贝返回代价不小,但是左值引用又不能解决,因为 函数当中的 变量已经销毁了,就算我们拿到 这个变量的地址,那么其中的数据也是非法的,而且,这个变量(对象)在销毁的时候会调用析构函数,那么我们拿到的这个块空间也是非法的。而且,如果我们在外部用一个 变量来接收的话,那么按道理,黑丝要拷贝两次的:
第一次是在函数栈帧销毁之前,就会要拷贝的对象,拷贝到临时对象当中,然后再把临时对象拷贝给我们接收的变量,但是有些编译器会对此处进行优化,直接就拿 函数当中要返回的对象直接对 外部 接受的变量进行拷贝,但是不是所有的编译器都会这样做的。
而且上述的优化是在一句语句当中的 连续的拷贝构造,如下所示:
string func()
{
string str;
cin << str;
return str;
}
int main()
{
string ret = func();
retrun 0;
}如果拷贝构造不是连续的,就不能进行优化了:
string func()
{
string str;
cin << str;
return str;
}
int main()
{
string ret;
// ·······
// 一些操作
ret = func();
retrun 0;
}上述情况就不能进行优化了。
左/右值引用 两者构成函数重载
如下函数所示,是构成函数重载的:
void func(int& x)
{
cout << "void func(int& x)" << endl;
}
void func(int&& x)
{
cout << "void func(inr&& x)" << endl;
}
int main()
{
int x = 1;
int y = 2;
func(x); // 左值引用
func(x + y); // 右值引用
return 0;
}输出:
void func(int& x)
void func(int&& x)发现重载关系已经匹配上了。
我们上述也说过,const 的 左值引用也是可以接收 右值的,那么 const 的左值引用 和 右值引用其实也是可以构成函数重载的:
void func(const int& x)
{
cout << "void func(int& x)" << endl;
}
void func(int&& x)
{
cout << "void func(inr&& x)" << endl;
}
int main()
{
int x = 1;
int y = 2;
func(x); // 左值引用
func(x + y); // 右值引用
return 0;
}输出:
void func(int&& x)
void func(int& x)发现,分别传入左右值引用,都是可以分别用重载函数接受的。
因为 const 的 左值引用,既可以接收左值引用,又可以接收 右值引用,如果上述例子,如果没有右值引用重载函数,也是可以接收的:
void func(const int& x)
{
cout << "void func(int& x)" << endl;
}
int main()
{
int x = 1;
int y = 2;
func(x); // 左值引用
func(x + y); // 右值引用
return 0;
}输出:
void func(int& x)
void func(int& x)而发生上述的 const 的左值引用 和 右值引用 调用两个重载函数的情况,就是编译器在匹配重载函数时候的选择,如果在重载函数当中有多个函数都可以接收 当前传入的参数,那么,编译器会选择一个最适合的重载函数进行调用,也就是实参和形参的参数 最符合的重载函数。
有右值引用的版本就会走跟匹配的 右值引用的版本。
右值引用的价值 - 移动拷贝 - 移动构造
我们看到,上述在函数当中返回一个对象,那么我们不能使用左值引用,不然会发生野引用;如果不使用 引用返回,直接还用 传值返回的话,我们肯定是要用一个变量来接收的,那么在函数返回值之前,也就是在函数栈帧销毁之前,会先深拷贝(如果是需要深拷贝的对象)一份临时对象,然后在把临时对象拷贝给 我们用于接收的变量上,相当与是要深拷贝两次。
而且,我们发现:
内置类型的右值,就是纯右值;而 自定义类型的右值,是 将亡值。
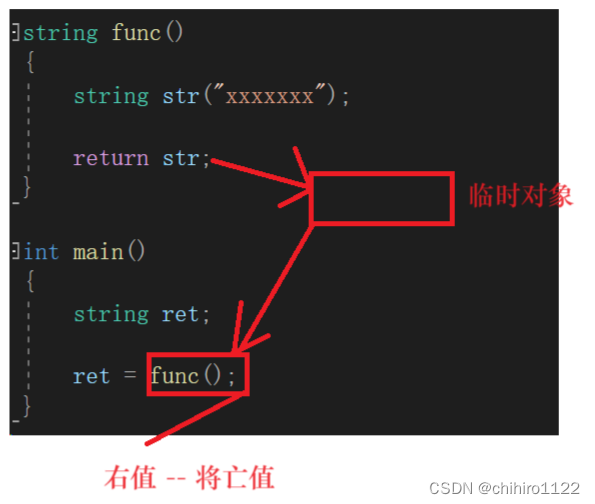
如上述所示,func()返回的是一个临时变量(对象),这个临时对象的作用域和 匿名对象是一样的,出了函数,临时对象就会销毁了。所以,func()函数的返回值本质上就是一个右值当中的将亡值,因为 func()的返回对象只有 ret = func(); 这一行,在下一行,这个临时对象就会被销毁。
在内置类型当中使用的 操作符本质上是 调用运算符重载函数,比如 string 当中的 对象 s1 + s2 ,那么两个 string 类型的对象相加,实际上是调用 了 operator+() 这个函数,还有像 to_string 一样也是用 调用函数,那么,这两种方式调用函数,使用传值返回都是会构造一个临时对象返回。
上述说明了 左/右值引用作为参数的函数,可以构成函数重载。
那么对于 operator=()这个函数,我们就可以写一个右值版本的,在这个版本当中,使用现代写法,既然 func()当中的临时变量出了函数是要销毁的,那么,就像直接使用 swap()函数把 临时对象当中的 成员信息都交换给 ret,那么 在临时对象当中的 成员数据就复制给 ret,那么 在临时变量被编译器销毁的时候,就把 原本在 ret 当中的成员和 动态开辟的空降给析构了。
而 ret 也成功的拿到了 临时变量当中的信息,没有进行第二次的深拷贝操作。
我们把上述的这种拷贝方式成为移动拷贝。
例如在 string 当中的 operator=()函数实现:
string& operator=(string&& s)
{
swap(s);
return *this;
}那么在外部使用的时候:
string ret = func();因为 func() 的返回值是右值,所以就会调用上述,函数参数类型是右值的函数,就使用现在写法,直接把 s 当中的成员信息拷贝给 当前对象(其中肯定有 string 当中字符串的指针,直接交换指针(浅拷贝)即可,那么交换之后,之前需要拷贝的字符串 (s)当中的字符就由当前对象的字符串指针所维护了,接着 s 出了自己的作用域,就会把 之前在 ret 当中的空间析构掉)
右值引用不是像左值引用一样,直接是这个变量(对象)的别名,而是该拷贝的还是得拷贝,但是,向上述一样的多次拷贝就不用了,拷贝一次就够用了,不用再进行多余的拷贝了。

上述提到 现代写法,其实还有传统写法,两种方法在在 string 当中其实都差不多,但是在上述右值引用当中就有大作用,具体可以看 下篇 对 string 的 operator=()重载运用符函数的讲解:
C++-string类的模拟实现_chihiro1122的博客-CSDN博客
像上述的右值引用加 现代写法(也就是 移动拷贝),不仅仅可以用于 operator=()重载运算符函数,还可以用于 构造函数,此时就叫做移动构造了
我们还可以写一个 本对象类型的右值引用 的重载构造函数,再去其中也可以使用 现代写法(例如string 当中的本对象类型的右值引用 的重载构造函数):
string (string&& s)
:_str(nullptr)
{
swap(s);
}上述也是使用 swap ()函数交换了 s 对象 和 当前对象当中的成员数据。
像上述的 当中的本对象类型的右值引用 的重载构造函数(拷贝函数) 是适用于下面这种情况的:
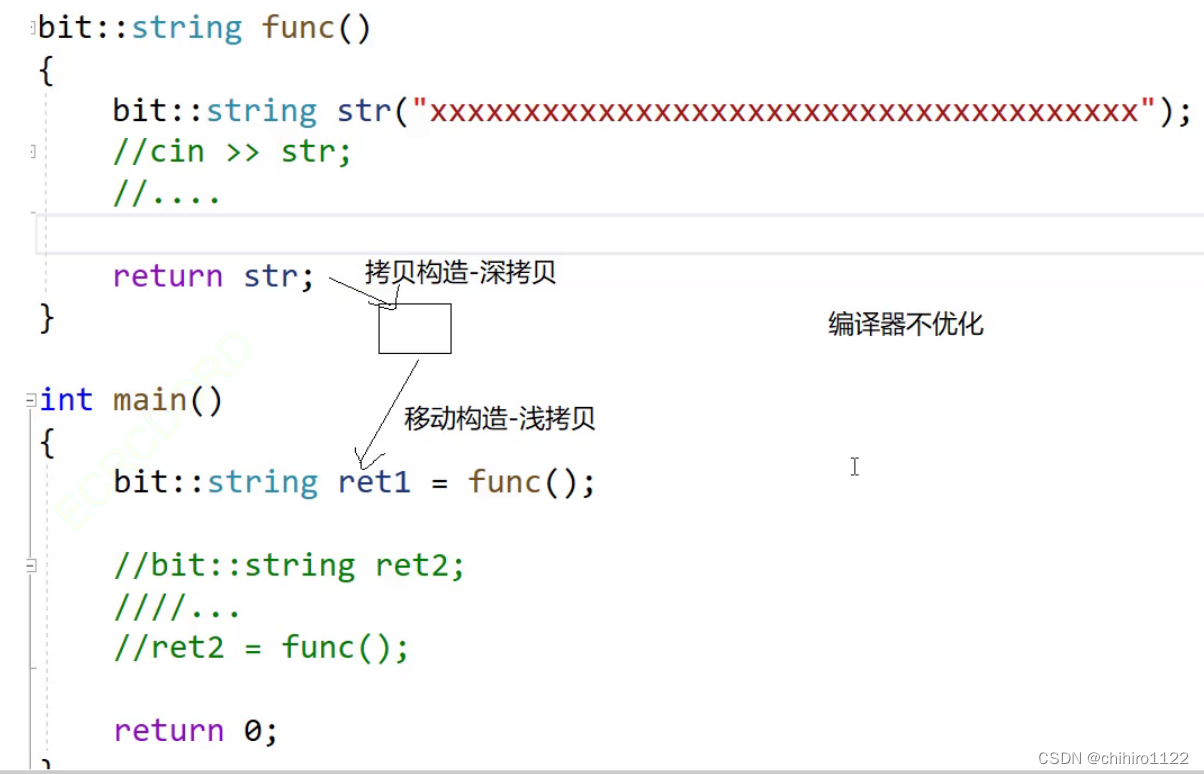
如果上述的代码编译器不进行优化, func()函数当中的 str 会先深拷贝一个 临时对象出来,因为重载了 operator=()函数,所以赋值给 ret1 是一个浅拷贝。那么,现在这种情况就是和最开始,编译器优化之后的结果了。
但是,如果编译器进行优化的(编译器的第一步优化),那么在上述两步就会合成一步,首先,合二为一的出来的一步,肯定不会是 移动构造的那一步,而是深拷贝(使用拷贝构造函数)的那一步。因为 str 又是一个左值,所以我们在 构造函数当中写的一定构造不起作用。
但是,上述场景太多了,编译器又对此进行优化(编译器第二步优化),从上述 func()函数来看,str 虽然是左值,但是 他是 符合将亡值的特征的,也就是出了 bit:string ret1 = func() 这个行代码之后,str 就会被析构。编译器会把 str 识别成 右值 当中的 将亡值。
所以,这个地方,在实现了上述 operator=() 和 构造函数的 右值重载函数之后,就只会调用一次 移动拷贝(在函数栈帧销毁之前,就会做拷贝):
在这里的话,本来是要拷贝两次的,但是现在一次都不用拷贝了,直接把 str 浅拷贝给了 ret1。
注意:在外部函数 如上述的 func 函数,返回值不能是 string&,因为是string 才能达到上述的优化效果,如果是 string& 就是 左值引用了,返回 string& 就不会做上述的优化的事情,因为返回的引用,只有传值返回才有上述的优化。str 会正常销毁,销毁之后返回的就是野指针了。
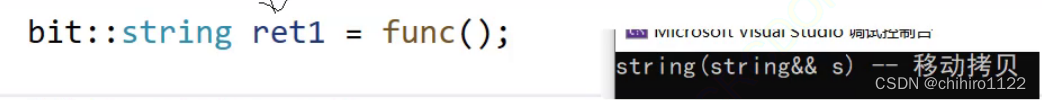
注意:上述的第二次优化,是因为我们函数返回的类型是传值返回,才有把 str 从原本的左值是被成右值,这一步优化。如果不进行第二次优化,是临时对象做的返回值。
(上述的第二次优化是所有的编译器都支持的,因为是C++对编译器实现的规定,如果编译器不这样进行优化的,右值引用带来的优化相当于砍掉了半条腿)
可以理解为,是编译器在这个地方做的特殊处理。
还有就是之前,编译器第一次优化都无法实现的,在实现 operator=()的右值引用函数之后,就被右值引用所优化了:
在 C++98 时候,没有右值引用,就不能使用上述方式来优化,直接传值返回的话代价就太大了,所以,一般是使用函数传参,传入引用的方式来解决的:

写过 C 的力扣题的都知道 这样写 是比较麻烦的。
move()函数的浅谈
由之前对 右值引用 引用 左值,使用用move()函数来实现的:
string ret = "xxxxxxxxxx";
string&& p1 = move(ret); 但是 下述方式不能 用到右值引用:
string ret1("xxxxxxxxxxxx");
move(ret1);
string copy1 = ret1;按照之前对 string当中 右值引用参数的 operator=()运算符重载函数的介绍,那么上述如果 ret1被 move 修改为 右值引用的话,就会调用 右值引用参数的 operator=()运算符重载函数。那么 copy1 就会继承 ret1 当中的各个数据,空间等等属性,而 ret1 就会被销毁。
但是,结果是并没有,就是原本的拷贝一份的 operator=()运算符重载函数。ret1 并没有销毁。
但是 下述代码,copy1 就会继承 ret1 当中的各个数据,空间等等属性,而 ret1 就会被销毁:
string ret1("xxxxxxxxxxxx");
string copy1 = move(ret1);也就是说,move()函数,不会修改到 ret1,也就是传入的参数,它只是返回一个 该参数的引用或者是指针,这个就是右值了,编译器就会识别为 右值,调用 右值引用参数的 operator=()运算符重载函数。
右值引用使用场景
从上述例子我么可以发现右值引用基本上是用于 自定义类型的拷贝优化,对于内置类型,右值引用的优化不大,因为内置类型最大就是才几个字节 ,而自定义类型可能会很大,比如在 位图 和 布隆过滤器当中的存储就可以达到 几个 G。
总之就是内置类型,或者是体积都比较小的自定义类型,是没必要使用右值引用来优化的;比如 Date 日期类,其中 就 只有几个 变量 比如 _year _day _ month ,除了这些变量,没有必要在动态开辟空间。那么对于 _year _day _ month ,我使用 右值引用就是交换值,那么使用拷贝构造函数也是一样的值拷贝,那么右值引用写来有 什么意义呢?两这之前没有什么区别。
所以,对于浅拷贝的类,移动构造不要实现,没有什么需要转移的资源(比如堆空间),直接拷贝就行。比如其中有 10 个 int 类型的成员变量,就只是 40 个字节,直接拷贝就行了。传值返回代价也不大,所以 右值引用的构造函数也不用写。
右值引用主要使用在 深拷贝的类当中,也就是需要深拷贝的对象,那么才需要右值引用来提升效率。
还有一个场景,我们在上篇博客当中说过了,在 C++11 之后就把 STL 容器当中的 push_back 函数给升级了,支持了右值引用的版本,所以,当我们在使用 容器嵌套容器的时候,就可以用move()函数强制右值引用,这样就可以使用移动构造,优化效率:
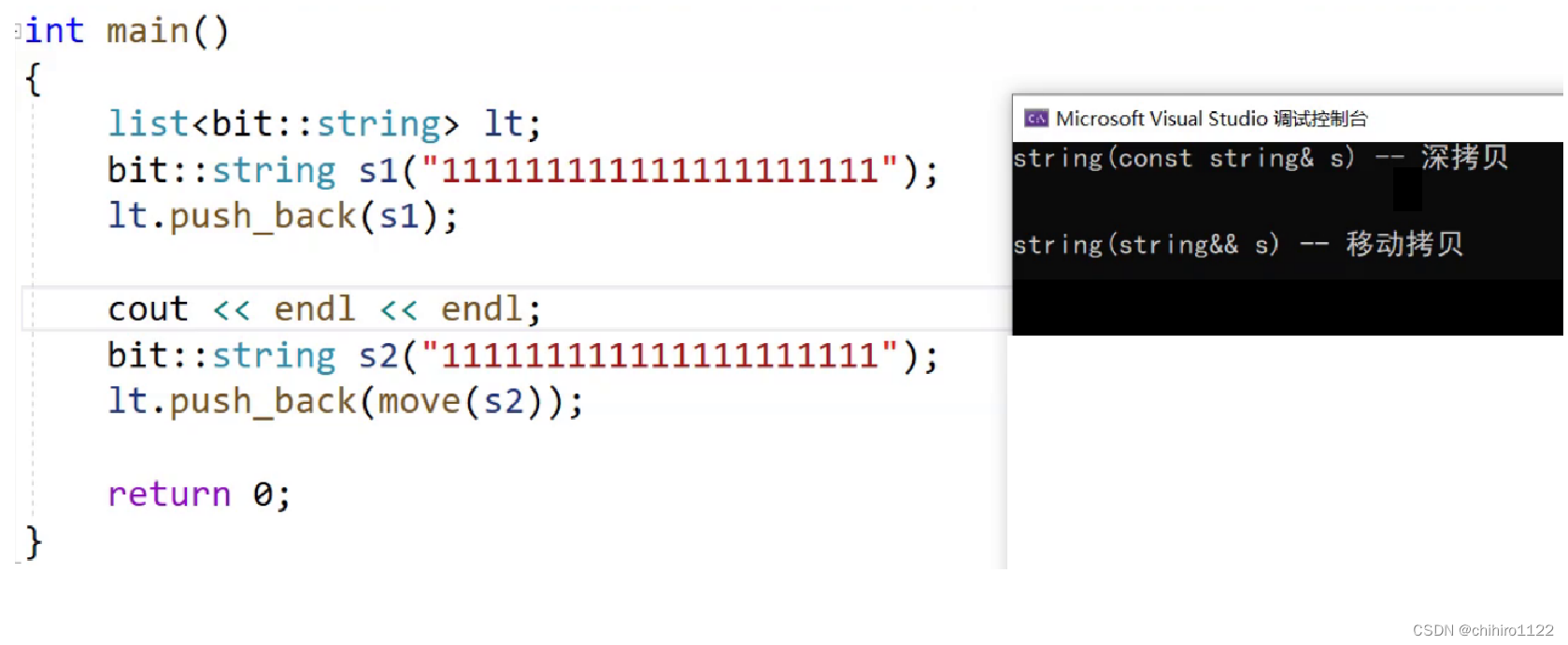
就是在 链表 Node 结点的构造函数当中 ,有对 val 的初始化,此时的 val 的类型是 string 类型,此时就有了类的深拷贝了,如果不使用 移动拷贝,就会调用string的拷贝构造函数,就会进行一次深拷贝,所以,此时就有了 右值引用版本的 push_back ()不用拷贝构造,直接把 s2 的空间等等属性给 到Node 结点当中:
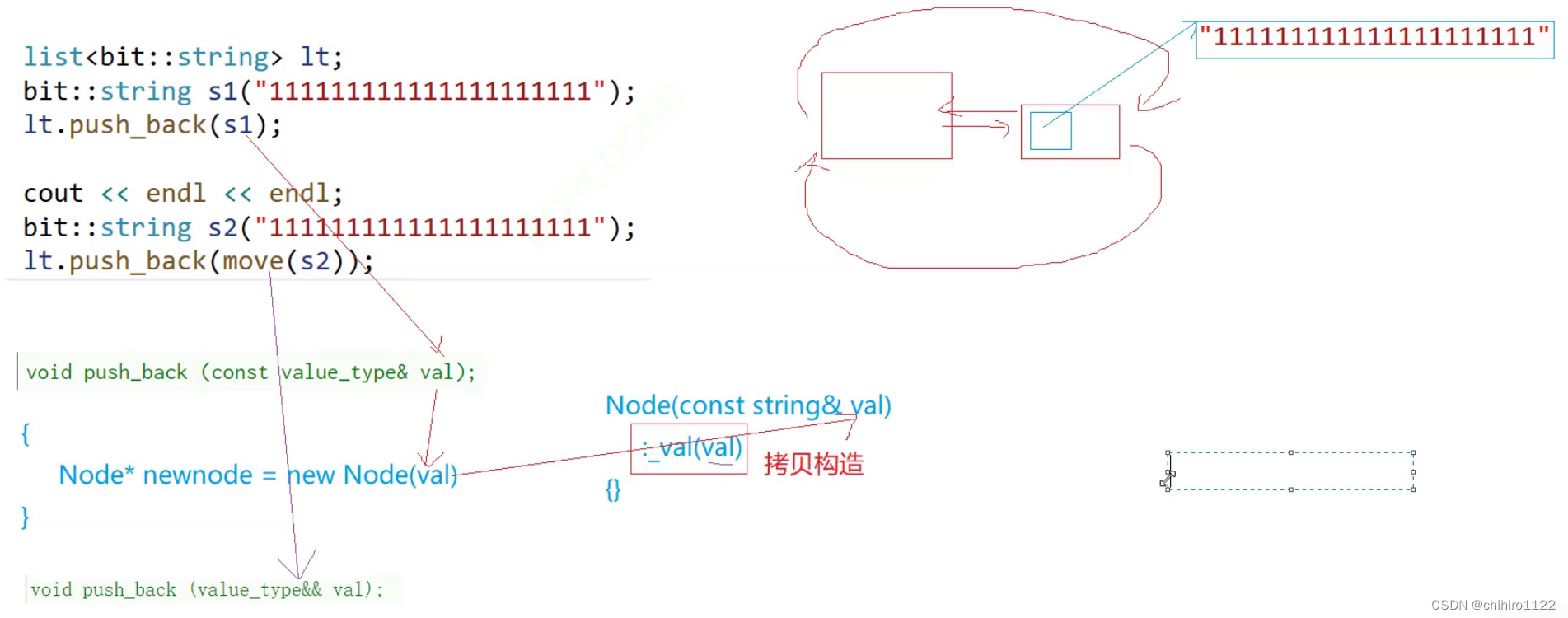
list<string> it;
it.push_back("1111111111")上述这个例子也是可以引发右值引用来优化的。
虽然 "1111111111" 这个字符串是一个常量字符串,我们之前说过,常量字符串是左值,虽然他可以写成 "11111111111"; 这样形式,但是这个常量字符串可以取出地址,所以是左值。
那么就有疑问了,左值为什么会调用 右值引用的函数来优化呢?
因为 常量字符串不能直接用于构造一个 list 的结点,上述 list 的结点当中 _val 的类型是 string,C++支持 单参数的隐式类型转换,用常量字符串,构造了一个 string对象给 _val,而 构造出来的 Node 结点,在传入 push_back ()函数的话,就是右值了。
像上述的三种插入情况,如果没有优化的话,如果把调用函数给打印出来的话,就是 先调用 string 的构造函数,Node 当中的 _val 是一个 string,也是需要调用构造函数构造的,然后调用 string 的拷贝构造给 Node 当中的 _val ,然后在调用 Node 的构造函数:
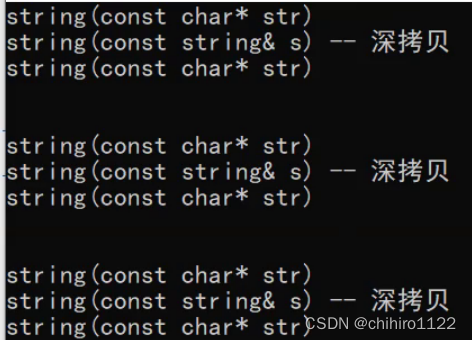
所以,有值解决的场景就是容器的插入接口,如果插入对象是右值,可以利用移动构造转移资源给数据结构当中的对象。可以减少深拷贝带来的消耗。
不只是 push_back()函数实现的有 右值引用的版本,每一个容器都实现了 insert()函数的右值引用版本。






![练[极客大挑战 2019]BuyFlag](https://img-blog.csdnimg.cn/img_convert/37f1e816ac26a118ca71fc88e73612e3.png)