一、File类
概念:代表物理盘符中的一个文件或者文件夹。
常见方法:
| 方法名 | 描述 |
|---|---|
| createNewFile() | 创建一个新文件。 |
| mkdir() | 创建一个新目录。 |
| delete() | 删除文件或空目录。 |
| exists() | 判断File对象所对象所代表的对象是否存在。 |
| getAbsolutePath() | 获取文件的绝对路径。 |
| getName() | 取得名字。 |
| getParent() | 获取文件/目录所在的目录。 |
| isDirectory() | 是否是目录。 |
| isFile() | 是否是文件。 |
| length() | 获得文件的长度。 |
| listFiles() | 列出目录中的所有内容。 |
示例:
//文件的相关操作
File f = new File("d:/aaa/bbb.java");
System.out.println("文件绝对路径:"+f.getAbsolutePath());
System.out.println("文件构造路径:"+f.getPath());
System.out.println("文件名称:"+f.getName());
System.out.println("文件长度:"+f.length()+"字节");
//创建文件 createNewFile()
File file=new File("d:\\file.txt");
//System.out.println(file.toString());
if(!file.exists()) {
boolean b=file.createNewFile();
System.out.println("创建结果:"+b);
}
System.out.println("是否时文件:"+file.isFile());
//文件夹的相关操作
File f2 = new File("d:/aaa");
System.out.println("目录绝对路径:"+f2.getAbsolutePath());
System.out.println("目录构造路径:"+f2.getPath());
System.out.println("目录名称:"+f2.getName());
System.out.println("目录长度:"+f2.length());
//创建文件夹
File dir=new File("d:\\aaa\\bbb\\ccc");
System.out.println(dir.toString());
if(!dir.exists()) {
//dir.mkdir();//只能创建单级目录
System.out.println("创建结果:"+dir.mkdirs());//创建多级目录
}
System.out.println("是否时文件夹:"+dir.isDirectory());
//遍历文件夹
File dir2=new File("d:\\图片");
String[] files=dir2.list();
System.out.println("--------------------------------");
for (String string : files) {
System.out.println(string);
}
FileFilter接口
FileFilter:文件过滤器接口
boolean accept(File pathname)。
当调用File类中的listFiles()方法时,支持传入FileFilter接口接口实现类,对获取文件进行过滤,只有满足条件的文件的才可出现在listFiles()的返回值中。
示例:
public class DiGuiDemo {
public static void main(String[] args) {
File f = new File("d:\\QF\\test");
printDir(dir);
}
public static void printDir(File dir) {
// 匿名内部类方式,创建过滤器子类对象
File[] files = dir.listFiles(new FileFilter() {
@Override
public boolean accept(File pathname) {
return pathname.getName().endsWith(".java")||pathname.isDirectory();
}
});
// 循环打印
for (File file : files) {
if (file.isFile()) {
System.out.println("文件名:" + file.getAbsolutePath());
} else {
printDir2(file);
}
}
}
}
二、什么是IO
生活中,你肯定经历过这样的场景。当你编辑一个文本文件,忘记了ctrl+s ,可能文件就白白编辑了。当你电脑上插入一个U盘,可以把一个视频,拷贝到你的电脑硬盘里。那么数据都是在哪些设备上的呢?键盘、内存、硬盘、外接设备等等。
我们把这种数据的传输,可以看做是一种数据的流动,按照流动的方向,以内存为基准,分为输入input 和输出output ,即流向内存是输入流,流出内存的输出流。
Java中I/O操作主要是指使用java.io包下的内容,进行输入、输出操作。输入也叫做读取数据,输出也叫做作写出数据。
三、IO分类
根据数据的流向分为:输入流和输出流。
输入流 :把数据从其他设备上读取到内存中的流。
输出流 :把数据从内存 中写出到其他设备上的流。
根据数据的类型分为:字节流和字符流。
字节流 :以字节为单位,读写数据的流。
字符流 :以字符为单位,读写数据的流。
| 输入流 | 输出流 | |
|---|---|---|
| 字节流 | 字节输入流 | |
| InputStream | 字节输出流 | |
| OutputStream | ||
| 字符流 | 字符输入流 | |
| Reader | 字符输出流 | |
| Writer |

四、字节流
一切皆为字节
一切文件数据(文本、图片、视频等)在存储时,都是以二进制数字的形式保存,都一个一个的字节,那么传输时一样如此。所以,字节流可以传输任意文件数据。在操作流的时候,我们要时刻明确,无论使用什么样的流对象,底层传输的始终为二进制数据。
字节输出流
java.io.OutputStream抽象类是表示字节输出流的所有类的超类,将指定的字节信息写出到目的地。它定义了字节输出流的基本共性功能方法。
public void close() :关闭此输出流并释放与此流相关联的任何系统资源。
public void flush() :刷新此输出流并强制任何缓冲的输出字节被写出。
public void write(byte[] b):将 b.length字节从指定的字节数组写入此输出流。
public void write(byte[] b, int off, int len) :从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。
public abstract void write(int b) :将指定的字节输出流。
FileOutputStream类
构造方法:
public FileOutputStream(File file):创建文件输出流以写入由指定的 File对象表示的文件。
public FileOutputStream(String name): 创建文件输出流以指定的名称写入文件。
1、写出字节:write(int b) 方法,每次可以写出一个字节数据
2、写出字节数组:write(byte[] b),每次可以写出数组中的数据
3、写出指定长度字节数组:write(byte[] b, int off, int len) ,每次写出从off索引开始,len个字节
示例:
// 使用File对象创建流对象
File file = new File("a.txt");
FileOutputStream fos = new FileOutputStream(file);
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("b.txt");
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 写出数据:虽然参数为int类型四个字节,但是只会保留一个字节的信息写出
fos.write(97); // 写出第1个字节
fos.write(98); // 写出第2个字节
fos.write(99); // 写出第3个字节
// 关闭资源
fos.close();
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 字符串转换为字节数组
byte[] b = "你好中国".getBytes();
// 写出字节数组数据
fos.write(b);
// 关闭资源
fos.close();
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 字符串转换为字节数组
byte[] b = "abcde".getBytes();
// 写出从索引2开始,2个字节。索引2是c,两个字节,也就是cd。
fos.write(b,2,2);
// 关闭资源
fos.close();
字节输入流
java.io.InputStream抽象类是表示字节输入流的所有类的超类,可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
public void close() :关闭此输入流并释放与此流相关联的任何系统资源。
public abstract int read(): 从输入流读取数据的下一个字节。
public int read(byte[] b): 从输入流中读取一些字节数,并将它们存储到字节数组 b中 。
FileInputStream类
构造方法:
FileInputStream(File file): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。
FileInputStream(String name): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name命名。
1、读取字节:read方法,每次可以读取一个字节的数据,提升为int类型,读取到文件末尾,返回-1
2、使用字节数组读取:read(byte[] b),每次读取b的长度个字节到数组中,返回读取到的有效字节个数,读取到末尾时,返回-1
示例:
// 使用File对象创建流对象
File file = new File("a.txt");
FileInputStream fos = new FileInputStream(file);
// 使用文件名称创建流对象
FileInputStream fos = new FileInputStream("b.txt");
// 使用文件名称创建流对象
FileInputStream fis = new FileInputStream("read.txt");
// 读取数据,返回一个字节
int read = fis.read();
System.out.println((char) read);
read = fis.read();
System.out.println((char) read);
read = fis.read();
System.out.println((char) read);
read = fis.read();
System.out.println((char) read);
read = fis.read();
System.out.println((char) read);
// 读取到末尾,返回-1
read = fis.read();
System.out.println( read);
// 关闭资源
fis.close();
// 使用文件名称创建流对象
FileInputStream fis = new FileInputStream("read.txt");
// 定义变量,保存数据
int b ;
// 循环读取
while ((b = fis.read())!=-1) {
System.out.println((char)b);
}
// 关闭资源
fis.close();
// 使用文件名称创建流对象.
FileInputStream fis = new FileInputStream("read.txt"); // 文件中为abcde
// 定义变量,作为有效个数
int len ;
// 定义字节数组,作为装字节数据的容器
byte[] b = new byte[2];
// 循环读取
while (( len= fis.read(b))!=-1) {
// 每次读取后,把数组的有效字节部分,变成字符串打印
System.out.println(new String(b,0,len));// len 每次读取的有效字节个数
}
// 关闭资源
fis.close();
综合案例:图片复制
示例:
//1创建流
//1.1文件字节输入流
FileInputStream fis=new FileInputStream("d:\\001.jpg");
//1.2文件字节输出流
FileOutputStream fos=new FileOutputStream("d:\\002.jpg");
//2一边读,一边写
byte[] buf=new byte[1024];
int count=0;
while((count=fis.read(buf))!=-1) {
fos.write(buf,0,count);
}
//3关闭
fis.close();
fos.close();
System.out.println("复制完毕");
五、字符流
字符输入流
java.io.Reader抽象类是表示用于读取字符流的所有类的超类,可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。
public void close():关闭此流并释放与此流相关联的任何系统资源。public int read(): 从输入流读取一个字符。public int read(char[] cbuf): 从输入流中读取一些字符,并将它们存储到字符数组 cbuf中 。
FileReader类
构造方法
FileReader(File file): 创建一个新的 FileReader ,给定要读取的File对象。FileReader(String fileName): 创建一个新的 FileReader ,给定要读取的文件的名称。
构造时使用系统默认的字符编码和默认字节缓冲区。
- 字符编码:字节与字符的对应规则。Windows系统的中文编码默认是GBK编码表。
idea中UTF-8- 字节缓冲区:一个字节数组,用来临时存储字节数据。
1、读取字符:read方法,每次可以读取一个字符的数据,提升为int类型,读取到文件末尾,返回-1,循环读取
2、使用字符数组读取:read(char[] cbuf),每次读取b的长度个字符到数组中,返回读取到的有效字符个数,读取到末尾时,返回-1
示例:
// 使用File对象创建流对象
File file = new File("a.txt");
FileReader fr = new FileReader(file);
// 使用文件名称创建流对象
FileReader fr = new FileReader("b.txt");
// 使用文件名称创建流对象
FileReader fr = new FileReader("read.txt");
// 定义变量,保存有效字符个数
int len ;
// 定义字符数组,作为装字符数据的容器
char[] cbuf = new char[2];
// 循环读取
while ((len = fr.read(cbuf))!=-1) {
System.out.println(new String(cbuf,0,len));
}
// 关闭资源
fr.close();
字符输出流
java.io.Writer抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地。它定义了字符输出流的基本共性功能方法。
void write(int c)写入单个字符。void write(char[] cbuf)写入字符数组。abstract void write(char[] cbuf, int off, int len)写入字符数组的某一部分,off数组的开始索引,len写的字符个数。void write(String str)写入字符串。void write(String str, int off, int len)写入字符串的某一部分,off字符串的开始索引,len写的字符个数。void flush()刷新该流的缓冲。void close()关闭此流,但要先刷新它。
FileWriter类
FileWriter(File file): 创建一个新的 FileWriter,给定要读取的File对象。FileWriter(String fileName): 创建一个新的 FileWriter,给定要读取的文件的名称。
构造时使用系统默认的字符编码和默认字节缓冲区。
1、写出字符:write(int b) 方法,每次可以写出一个字符数据
2、写出字符数组 :write(char[] cbuf) 和 write(char[] cbuf, int off, int len) ,每次可以写出字符数组中的数据,用法类似FileOutputStream
3、写出字符串:write(String str) 和 write(String str, int off, int len) ,每次可以写出字符串中的数据,更为方便
因为内置缓冲区的原因,如果不关闭输出流,无法写出字符到文件中。但是关闭的流对象,是无法继续写出数据的。如果我们既想写出数据,又想继续使用流,就需要
flush方法了。
示例:
// 使用File对象创建流对象
File file = new File("fw.txt");
FileWriter fw = new FileWriter(file);
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 写出数据
fw.write(97); // 写出第1个字符
fw.write('b'); // 写出第2个字符
fw.write('C'); // 写出第3个字符
fw.write(30000); // 写出第4个字符,中文编码表中30000对应一个汉字。
/*
【注意】关闭资源时,与FileOutputStream不同。
如果不关闭,数据只是保存到缓冲区,并未保存到文件。
*/
// fw.close();
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 写出数据,通过flush
fw.write('刷'); // 写出第1个字符
fw.flush();
fw.write('新'); // 继续写出第2个字符,写出成功
fw.flush();
// 写出数据,通过close
fw.write('关'); // 写出第1个字符
fw.close();
fw.write('闭'); // 继续写出第2个字符,【报错】java.io.IOException: Stream closed
fw.close();
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 字符串转换为字节数组
char[] chars = "你好中国".toCharArray();
// 写出字符数组
fw.write(chars);
// 写出从索引2开始,2个字节。索引2是'中',两个字节,也就是'中国'。
fw.write(b,2,2); //中国
// 关闭资源
fos.close();
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 字符串
String msg = "你好中国";
// 写出字符数组
fw.write(msg); //你好中国
// 写出从索引2开始,2个字节。索引2是'中',两个字节,也就是'中国'。
fw.write(msg,2,2); // 中国
// 关闭资源
fos.close();
六、缓冲流
概述
缓冲流,也叫高效流,是对4个基本的FileXxx 流的增强,所以也是4个流,按照数据类型分类:
- 字节缓冲流:
BufferedInputStream,BufferedOutputStream - 字符缓冲流:
BufferedReader,BufferedWriter
缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。

字节缓冲流
构造方法:
public BufferedInputStream(InputStream in):创建一个 新的缓冲输入流。public BufferedOutputStream(OutputStream out): 创建一个新的缓冲输出流。
示例:
// 创建字节缓冲输入流
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("bis.txt"));
// 创建字节缓冲输出流
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("bos.txt"));
效率PK
基本流示例:
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try (
FileInputStream fis = new FileInputStream("jdk8.exe");
FileOutputStream fos = new FileOutputStream("copy.exe")
){
// 读写数据
int b;
while ((b = fis.read()) != -1) {
fos.write(b);
}
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("普通流复制时间:"+(end - start)+" 毫秒");
缓冲流示例:
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("jdk8.exe"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.exe"));
){
// 读写数据
//int b;
//while ((b = bis.read()) != -1) {
//bos.write(b);
//}
// 读写数据
int len;
byte[] bytes = new byte[8*1024];
while ((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0 , len);
}
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("缓冲流复制时间:"+(end - start)+" 毫秒");
字符缓冲流
构造方法
public BufferedReader(Reader in):创建一个 新的缓冲输入流。public BufferedWriter(Writer out): 创建一个新的缓冲输出流。
示例:
// 创建字符缓冲输入流
BufferedReader br = new BufferedReader(new FileReader("br.txt"));
// 创建字符缓冲输出流
BufferedWriter bw = new BufferedWriter(new FileWriter("bw.txt"));
特有方法
字符缓冲流的基本方法与普通字符流调用方式一致,不再阐述,我们来看它们具备的特有方法。
- BufferedReader:
public String readLine(): 读一行文字。 - BufferedWriter:
public void newLine(): 写一行行分隔符,由系统属性定义符号。
示例1:
// 创建流对象
BufferedReader br = new BufferedReader(new FileReader("in.txt"));
// 定义字符串,保存读取的一行文字
String line = null;
// 循环读取,读取到最后返回null
while ((line = br.readLine())!=null) {
System.out.print(line);
System.out.println("------");
}
// 释放资源
br.close();
示例2:
// 创建流对象
BufferedWriter bw = new BufferedWriter(new FileWriter("out.txt"));
// 写出数据
bw.write("hello");
// 写出换行
bw.newLine();
bw.write("world");
bw.newLine();
bw.write("!");
bw.newLine();
// 释放资源
bw.close();
七、转换流
在IDEA中,使用FileReader 读取项目中的文本文件。由于IDEA的设置,都是默认的UTF-8编码,所以没有任何问题。但是,当读取Windows系统中创建的文本文件时,由于Windows系统的默认是GBK编码,就会出现乱码。
示例:
public class ReaderDemo {
public static void main(String[] args) throws IOException {
FileReader fileReader = new FileReader("E:\\File_GBK.txt");
int read;
while ((read = fileReader.read()) != -1) {
System.out.print((char)read);
}
fileReader.close();
}
}
输出结果:
���
那么如何读取GBK编码的文件呢?

InputStreamReader类
转换流java.io.InputStreamReader,是Reader的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法
InputStreamReader(InputStream in): 创建一个使用默认字符集的字符流。InputStreamReader(InputStream in, String charsetName): 创建一个指定字符集的字符流。
示例:
// 定义文件路径,文件为gbk编码
String FileName = "E:\\file_gbk.txt";
// 创建流对象,默认UTF8编码
InputStreamReader isr = new InputStreamReader(new FileInputStream(FileName));
// 创建流对象,指定GBK编码
InputStreamReader isr2 = new InputStreamReader(new FileInputStream(FileName) , "GBK");
// 定义变量,保存字符
int read;
// 使用默认编码字符流读取,乱码
while ((read = isr.read()) != -1) {
System.out.print((char)read); // ��Һ�
}
isr.close();
// 使用指定编码字符流读取,正常解析
while ((read = isr2.read()) != -1) {
System.out.print((char)read);// 大家好
}
isr2.close();
OutputStreamWriter类
转换流java.io.OutputStreamWriter ,是Writer的子类,是从字符流到字节流的桥梁。使用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法
OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。OutputStreamWriter(OutputStream in, String charsetName): 创建一个指定字符集的字符流。
示例:
// 定义文件路径
String FileName = "out.txt";
// 创建流对象,默认UTF8编码
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(FileName));
// 写出数据
osw.write("你好"); // 保存为6个字节
osw.close();
// 定义文件路径
String FileName2 = "out2.txt";
// 创建流对象,指定GBK编码
OutputStreamWriter osw2 = new OutputStreamWriter(new FileOutputStream(FileName2),"GBK");
// 写出数据
osw2.write("你好");// 保存为4个字节
osw2.close();
八、序列化
概述
Java 提供了一种对象序列化的机制。用一个字节序列可以表示一个对象,该字节序列包含该对象的数据、对象的类型和对象中存储的属性等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
反之,该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化。对象的数据、对象的类型和对象中存储的数据信息,都可以用来在内存中创建对象。
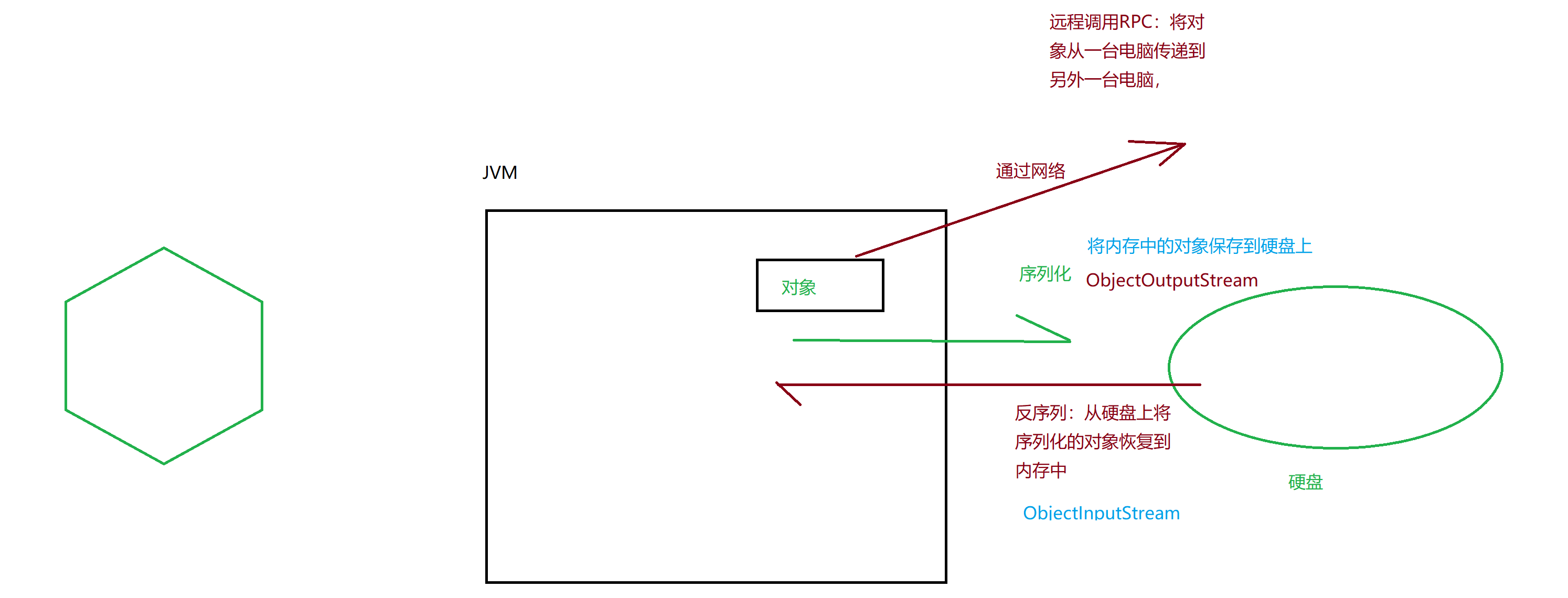
ObjectOutputStream类
java.io.ObjectOutputStream 类,将Java对象的原始数据类型写出到文件,实现对象的持久存储。
序列化操作
一个对象要想序列化,必须满足两个条件:
- 必须实现Serializable接口。
- 必须保证其所有属性均可序列化。(transient修饰为临时属性,不参与序列化)
写出对象方法
public final void writeObject (Object obj): 将指定的对象写出。
示例:
public class Employee implements java.io.Serializable {
public String name;
public String address;
public transient int age; // transient瞬态修饰成员,不会被序列化
public void addressCheck() {
System.out.println("Address check : " + name + " -- " + address);
}
}
public class SerializeDemo{
public static void main(String [] args) {
Employee e = new Employee();
e.name = "zhangsan";
e.address = "guangzhou";
e.age = 20;
try {
// 创建序列化流对象
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("employee.txt"));
// 写出对象
out.writeObject(e);
// 释放资源
out.close();
fileOut.close();
System.out.println("序列化完成"); // 姓名,地址被序列化,年龄没有被序列化。
} catch(IOException i) {
i.printStackTrace();
}
}
}
ObjectInputStream类
ObjectInputStream反序列化流,将之前使用ObjectOutputStream序列化的原始数据恢复为对象。
反序列化操作
如果能找到一个对象的class文件,我们可以进行反序列化操作,调用ObjectInputStream读取对象的方法,
public final Object readObject () : 读取一个对象。
示例:
public class DeserializeDemo {
public static void main(String [] args) {
Employee e = null;
try {
// 创建反序列化流
FileInputStream fileIn = new FileInputStream("employee.txt");
ObjectInputStream in = new ObjectInputStream(fileIn);
// 读取一个对象
e = (Employee) in.readObject();
// 释放资源
in.close();
fileIn.close();
}catch(IOException i) {
// 捕获其他异常
i.printStackTrace();
return;
}catch(ClassNotFoundException c) {
// 捕获类找不到异常
System.out.println("Employee class not found");
c.printStackTrace();
return;
}
// 无异常,直接打印输出
System.out.println("Name: " + e.name); // zhangsan
System.out.println("Address: " + e.address); // beiqinglu
System.out.println("age: " + e.age); // 0
}
}
注意:
对于JVM可以反序列化对象,它必须是能够找到class文件的类。如果找不到该类的class文件,则抛出一个
ClassNotFoundException异常。
当JVM反序列化对象时,能找到class文件,但是class文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个InvalidClassException异常。
发生这个异常的原因,该类的序列版本号与从流中读取的类描述符的版本号不匹配 ,serialVersionUID 该版本号的目的在于验证序列化的对象和对应类是否版本匹配。
serialVersionUID是一个非常重要的字段,因为 Java 的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM 会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。
一般来说,定义serialVersionUID的方式有两种,分别为:
采用默认的1L,具体为private static final long serialVersionUID = 1L;
在可兼容的前提下,可以保留旧版本号,如果不兼容,或者想让它不兼容,就手工递增版本号。
1->2->3…
根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段,例如 private static final long serialVersionUID = XXXL;
这种方式适用于这样的场景:
开发者认为每次修改类后就需要生成新的版本号,不想向下兼容,操作就是删除原有serialVesionUid声明语句,再自动生成一下。
第二种能够保证每次更改类结构后改变版本号,但还是要手工去生成
示例:
public class Employee implements java.io.Serializable {
// 加入序列版本号
private static final long serialVersionUID = 1L;
public String name;
public String address;
// 添加新的属性 ,重新编译, 可以反序列化,该属性赋为默认值.
public int eid;
public void addressCheck() {
System.out.println("Address check : " + name + " -- " + address);
}
}
九、Properties属性类
常用方法
public Object setProperty(String key, String value): 保存一对属性。public String getProperty(String key):使用此属性列表中指定的键搜索属性值。public Set<String> stringPropertyNames():所有键的名称的集合。public void load(InputStream inStream): 从字节输入流中读取键值对。
示例1:
// 创建属性集对象
Properties properties = new Properties();
// 添加键值对元素
properties.setProperty("filename", "a.txt");
properties.setProperty("length", "123");
properties.setProperty("location", "D:\\a.txt");
// 打印属性集对象
System.out.println(properties);
// 通过键,获取属性值
System.out.println(properties.getProperty("filename"));
System.out.println(properties.getProperty("length"));
System.out.println(properties.getProperty("location"));
// 遍历属性集,获取所有键的集合
Set<String> strings = properties.stringPropertyNames();
// 打印键值对
for (String key : strings ) {
System.out.println(key+" -- "+properties.getProperty(key));
}
示例2:
// 创建属性集对象
Properties pro = new Properties();
// 加载文本中信息到属性集
pro.load(new FileInputStream("read.txt"));
// 遍历集合并打印
Set<String> strings = pro.stringPropertyNames();
for (String key : strings ) {
System.out.println(key+" -- "+pro.getProperty(key));
}
小贴士:文本中的数据,必须是键值对形式,可以使用空格、等号、冒号等符号分隔。