0 微盟删库跑路
除了快、准和省,数据中台须安全,避免“微盟删库跑路”。
2020年2月23日19点,国内最大精准营销服务商微盟出现大面积系统故障,旗下300万商户线上业务全停,商铺后台所有数据被清。始作俑者是一位运维,在生产环境数据库删库,而刚上市不久的微盟就因此遭受巨大的损失,2月23日宕机以来,市值蒸发30亿港元。最贵的安全事件。数据中台咋防止类似事件?
- 如何解决数据误删除
- 如何解决敏感数据泄露
- 如何解决开发和生产物理隔离
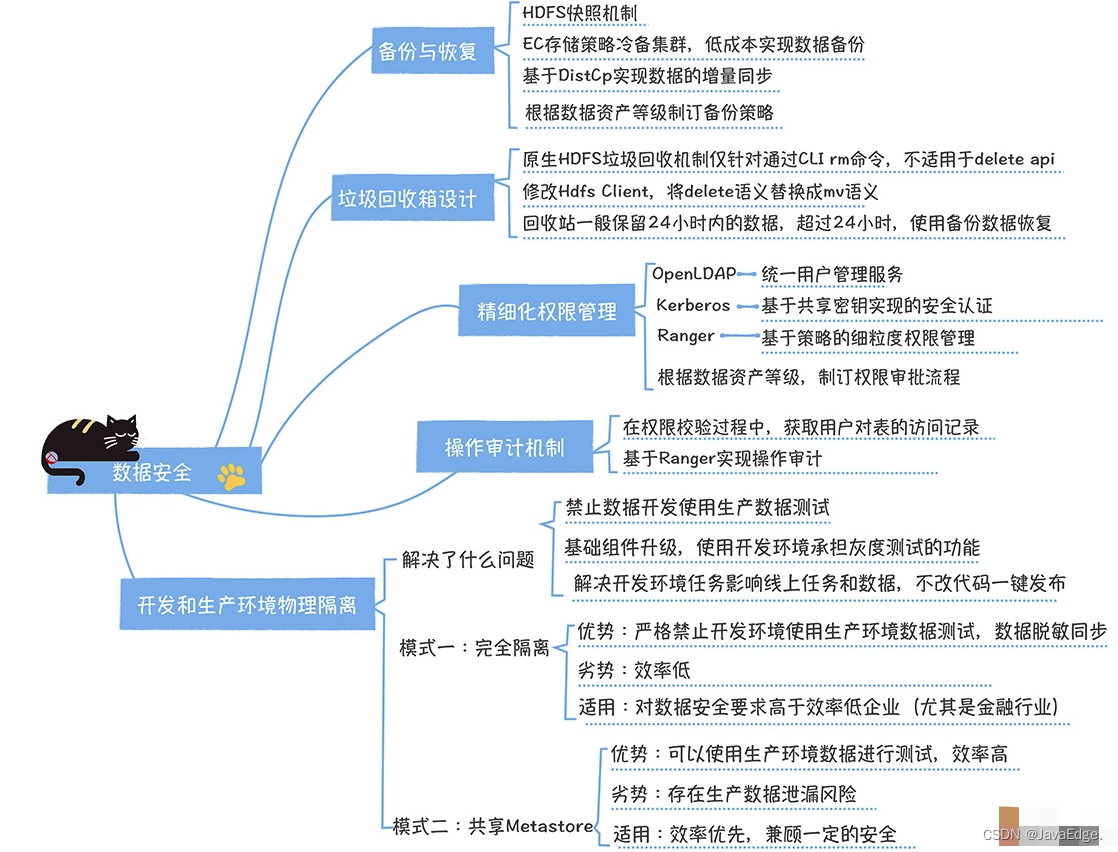
1 数据备份与恢复
数据中台的数据几乎都存储在HDFS,即使实时数据(存储于Kafka),也会归档HDFS,因为要保存历史数据进行回算或补数据。所以核心问题是HDFS数据备份。
HDFS数据备份可基于HDFS 快照 + DistCp + EC实现。
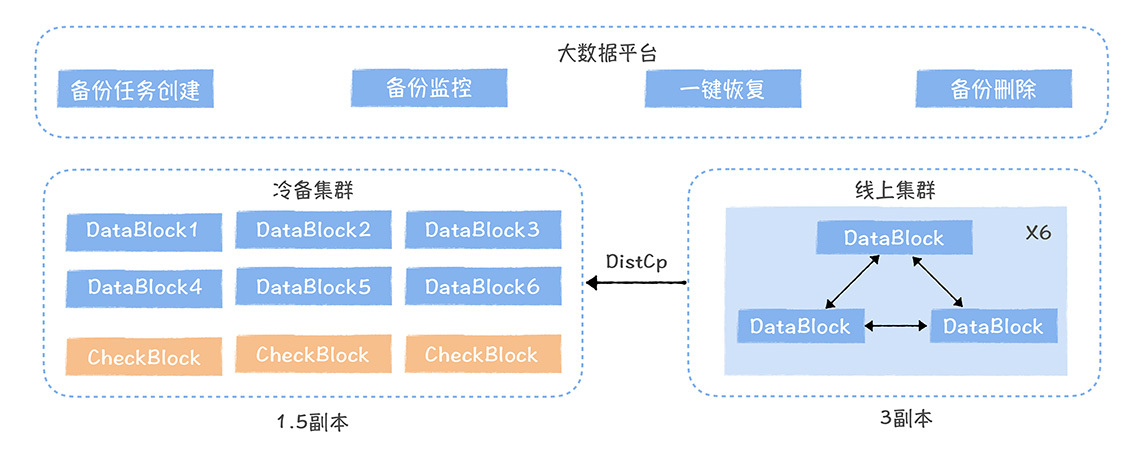
分为两个集群:
-
线上集群
数据加工任务访问
-
冷备集群
考虑存储成本,采用EC存储
存储采用HDFS默认的3副本。
EC存储原理图
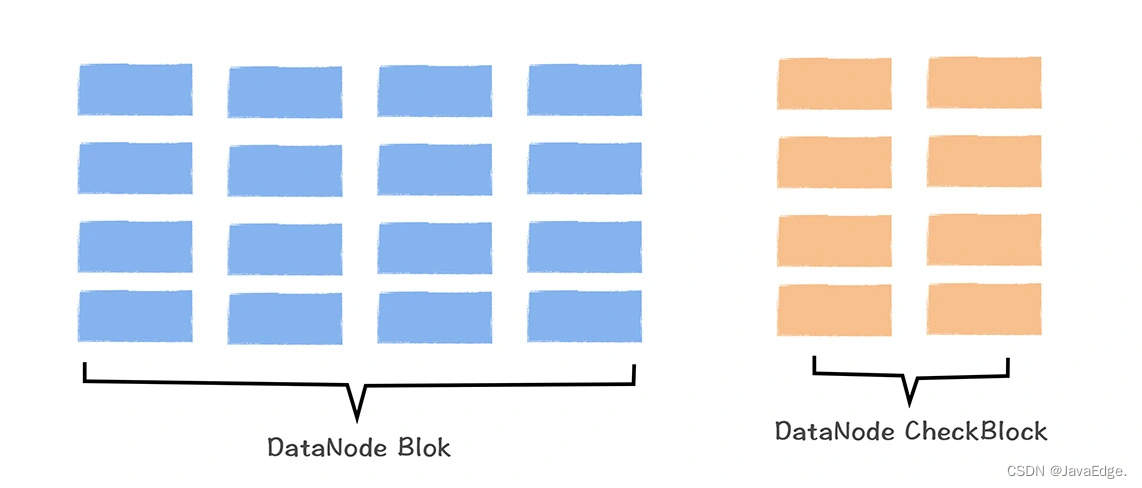
EC存储基本原理
Hadoop3.x正式引入EC存储,一种基于纠删码实现的数据容错机制,通过将数据分块,然后基于算法计算一些冗余校验块,当其中一部分数据块丢失时,可通过这些冗余校验块和剩余数据块,恢复丢失数据块。
案例
如有三个数据块,分别存储1、2和3。担心其中一个数据块坏了,丢失内容。所以增加一个块,这块存储内容是前面三个数据块之和。若任一数据块坏了,可根据现有数据块计算出丢失的数据块内容。
如1丢失,可根据6-3-2计算出1,当然这只是最简单EC算法,只能容忍一个数据块丢失,实际EC算法更复杂。
EC存储,在不降低可靠性前提下(与HDFS 3副本可靠性相同),通过牺牲一定计算性能(计算校验块消耗额外计算资源),将数据存储成本降低一半,适合低频访问的冷数据存储,如备份数据。
线上集群的数据同步到冷备集群
先了解快照基本原理,才能理解后续的数据同步。
Hadoop 2.x支持对某文件或目录创建快照,几s内完成一个快照操作。快照前,先要对某目录或文件启用快照,此时对应目录下会生成.snapshot文件夹:

上图对/helloword目录启用快照,然后创建一个s1的备份。此时,在.snapshot下存在s1文件。然后删除/helloword/animal/lion文件时,HDFS会在animal目录创建differ文件,并把diifer文件关联到s1备份,最后把lion文件移动到differ目录下。
HDFS快照实际只记录了产生快照时刻之后的,所有的文件和目录的变化,适合每天只有少数文件被更新的数据中台,代价和成本也低。
有了快照后,就要把快照拷贝到冷备集群,这里选择Hadoop自带的DistCp,因为它支持增量数据的同步。它有differ参数,可对比两个快照,仅拷贝增量数据。同时,DistCp是基于MapReduce框架实现的数据同步工具,可充分利用Hadoop分布式计算的能力,保证数据拷贝性能。
数据从线上集群拷贝到冷备集群
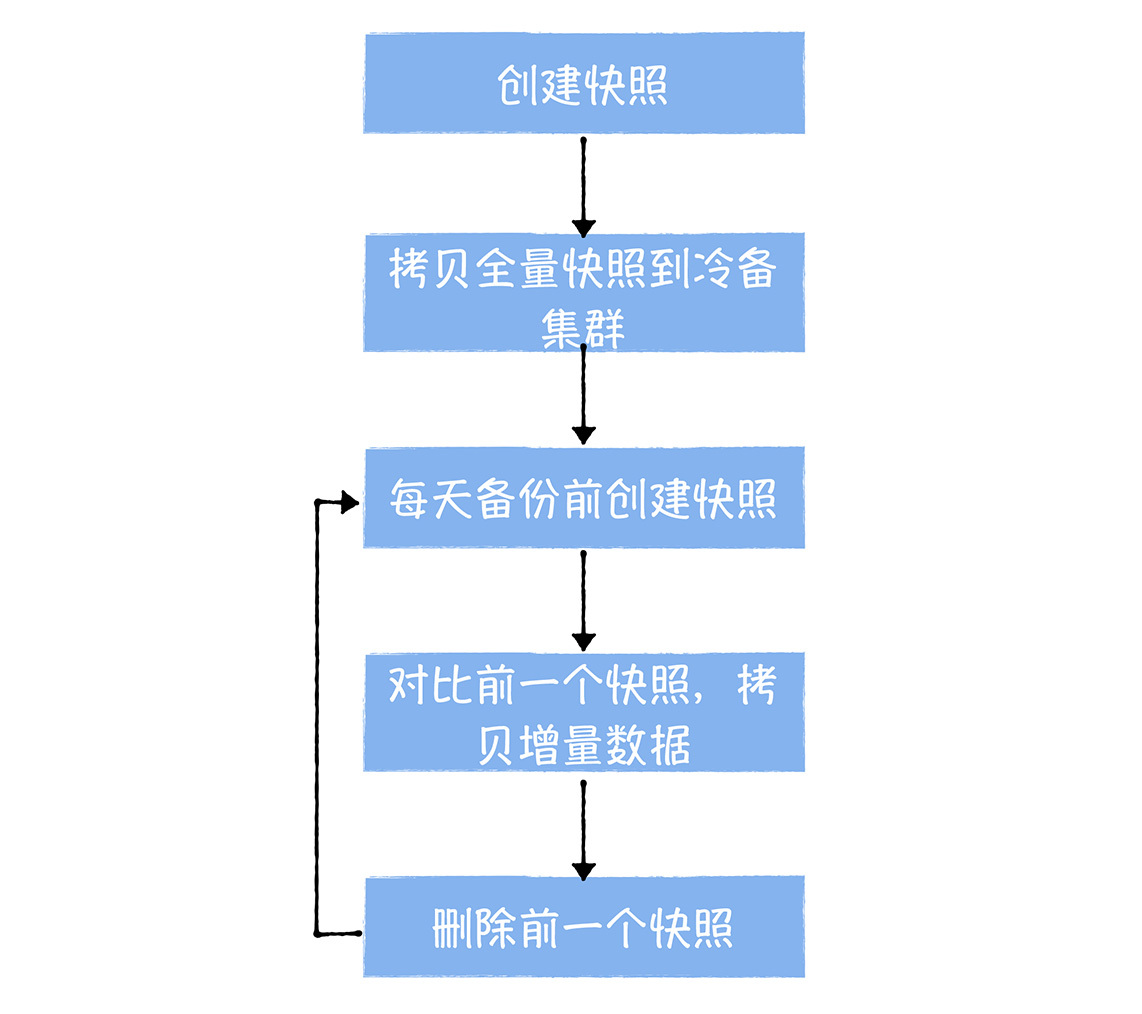
首先,对于第一次开始数据备份的文件,我们会先创建一个快照,然后利用DistCp 拷贝全量的备份数据到冷备集群。然后后续的每一天,我们都会定时生成一个快照,并和前一天的快照基于distcp --differ 参数进行对比,将有更新的部分再同步到冷备集群。同步完成以后,会删除前一天的快照,这样就完成了每日数据的增量同步。
这里需要特别注意的是,拷贝数据会对线上I/O 产生比较大的压力,所以尽量在任务运行的低峰期进行同步(比如白天12点到晚上24点之间的时间),同时DistCp的bandwidth参数可以限制同步的速率,你可以根据I/O 负载和数据同步速率,动态调整。比如说,I/O 利用率100%,应该限制数据拷贝带宽,为10MB/s。
数据中台中文件目录的备份光这些还不够,还要备份数据的产出任务,表相关的信息:
- 任务的备份,要保存任务代码、任务的依赖关系、任务调度配置及任务告警、稽核监控等信息
- 表的备份主要是备份表的创建语句
网易提供产品化解决方案,数据开发可在提供的数据管理平台,选择一张表,创建备份,然后系统自动完成任务、文件和表的备份。平台也提供一键恢复功能,系统自动帮数据开发创建任务和表,拷贝数据从冷备集群到线上集群。
什么样数据应备份?
数据的备份策略应和数据资产等级打通,对核心数据资产,数据中台应强制备份。
假如数据没备份,但误删除,还有补救方法? 试下这机制:
2 垃圾回收箱设计
HDFS本身提供垃圾回收站功能,意外删除的文件可在指定时间内进行恢复。
Core-site.xml添加如下配置开启,默认关闭:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
当HDFS一旦开启GC功能,用户通过命令行执行rm时,HDFS会将文件移到
/user/[用户名]/.trash/current/
目录。这目录下文件会在fs.trash.interval配置时间过期后,被系统自动删除。需恢复文件时,只需把
/user/[用户名]/.trash/current/
被删除文件移到要恢复的目录。
2.1 HDFS垃圾回收机制缺陷
只支持通过命令行执行rm,对在代码中通过HDFS API调用Delete接口时,会直接删除文件,GC机制并不生效。尤其Hive中执行drop table删除一个Hive内表,此时删除的数据文件并不会进入trash目录,巨大安全隐患。
改造后的HDFS回收站原理图:
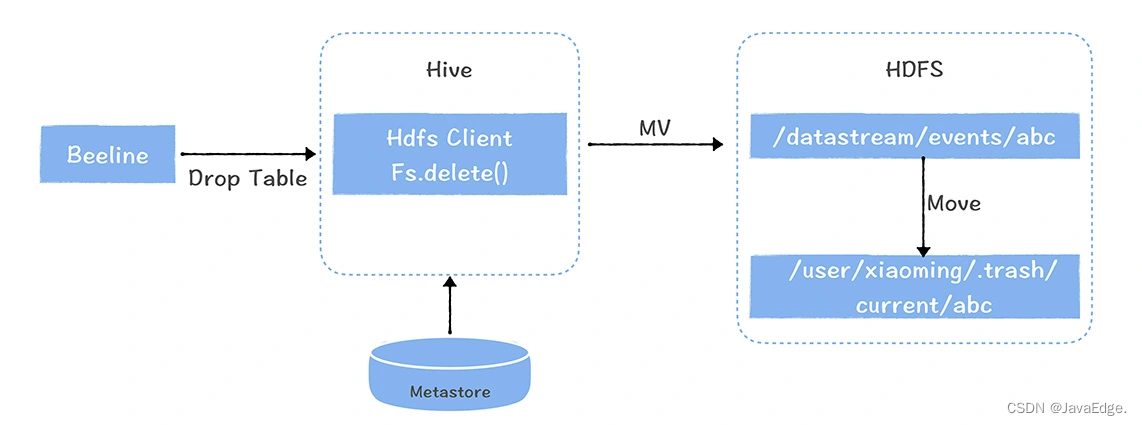
推荐对HDFS的Client修改,对Delete API通过配置项控制,改成跟rm相同语义。即把文件移到trash目录。对Hive上的HDFS Client进行替换,确保用户通过drop table删除表和数据时,数据文件能正常进入HDFS trash目录。
这样,即可解决数据误删问题。但HDFS回收站不宜保留时间过长,因为回收站中的数据还是三副本配置,会占用过多存储空间。所以配合解决方案:回收站保留24h内数据,解决数据还没来得及被同步到冷备集群,误删除的情况。
对一天以上数据恢复,建议采取基于冷备集群的数据备份来恢复。
3 精细化的权限管理
避免敏感数据泄露。数据权限是数据中台实现数据复用的前提和必要条件。若刚开始系统没开启权限,后期接入权限,任务改造成本很高,几乎涉及所有任务。权限问题,在数据中台构建之初,须提前规划好。
数据中台支撑技术体系基于OpenLDAP + Kerberos + Ranger 实现的一体化用户、认证、权限管理体系。
数据中台用户、认证、权限系统架构:

如有几千台机器,却没个统一的用户管理服务,当想添加一个用户,需到几千台服务器创建初始化用户,OpenLDAP解决了这问题。轻量化的目录服务,数据以树型结构存储,提供高性能查询服务,适合用户管理。
OpenLDAP 树型目录架构示意图
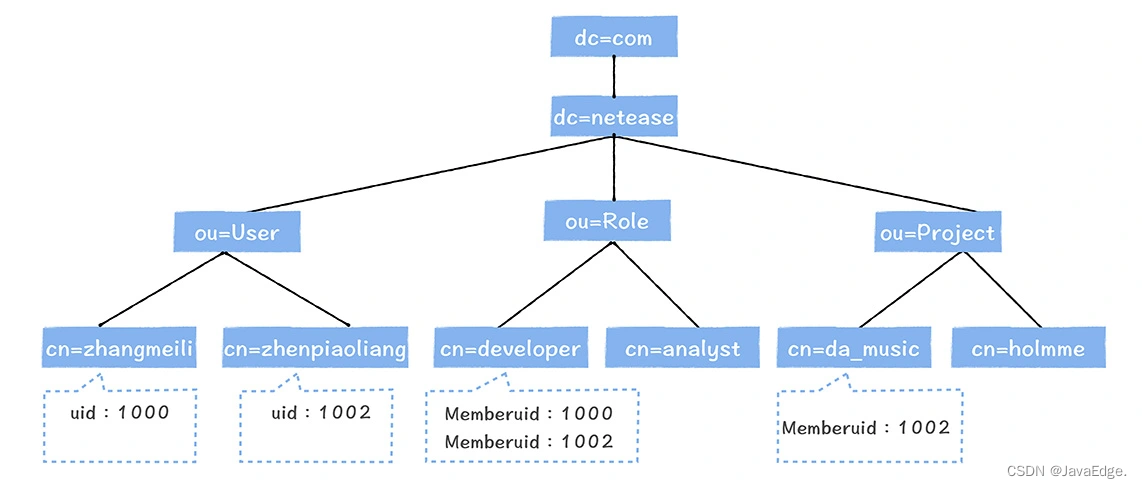
在OpenLDAP中,可创建用户(User)和组(Group),对于每个用户,会有唯一的uid,对于每个组,通过Memberuid,我们可以添加一个用户到一个组中。
大数据平台上注册一个用户,平台会自动生成一个OpenLDAP用户,当该用户加入某项目,会将该项目对应的Group下增加一个Memberuid。假设大漂亮加入da_music项目,da_music的Group下会增加Memberuid:1002。
Hadoop和OpenLDAP集成
Hadoop可使用LdapGroupsMappings同步LDAP创建的用户和用户组,在LDAP中添加用户和组时,会自动同步到Hadoop集群内的所有机器。
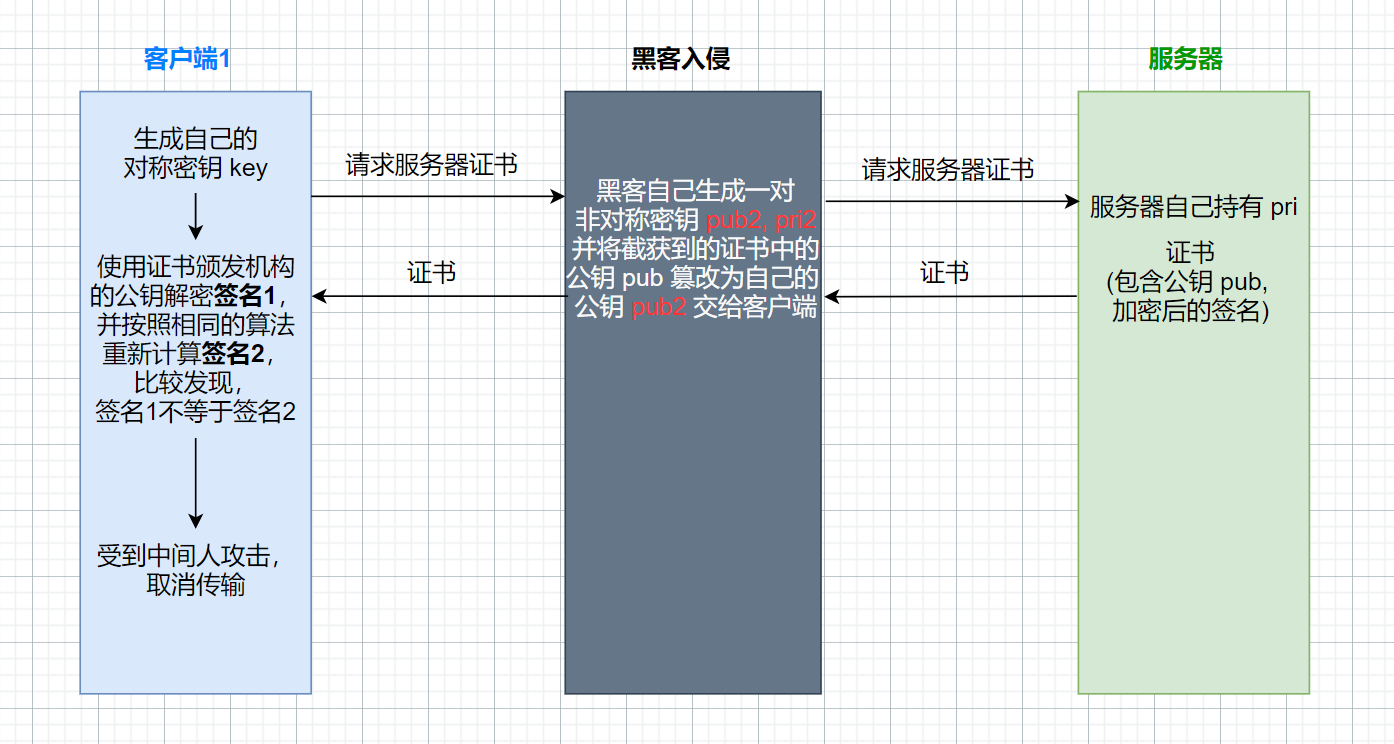
非安全网络中,除了客户端要证明自己是谁,对于服务端而言,同样也需要证明我是我。为实现双向认证,生产环境启用安全等级最高的基于共享密钥实现的Kerberos认证。
Kerberos认证原理
进游乐场,先要身份证实名购买与你身份绑定的门票。每个游乐设施前都有票据授权机器,刷门票,授权机器会生成该游乐设施的票据,就可玩这游乐设施。
想玩另外一个游乐设施,也要刷门票,生成对应游乐设施票据。门票有效期内尽情玩游乐设施,一旦超期,需重新购买门票。
Kerberos 认证原理
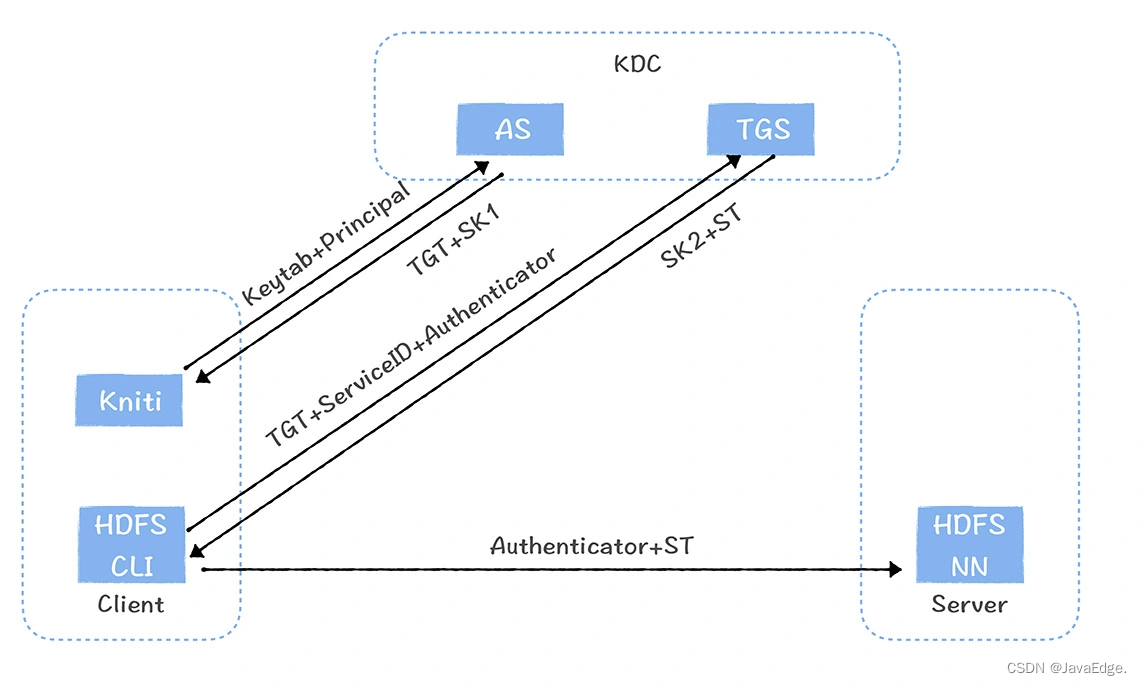
TGT(Ticket-granting ticket)可看作门票,Client首先使用自己的密钥文件Keytab和用户标识Principal去认证服务器(AS)购买TGT,认证服务器确认是合法的用户,Client会获得TGT,而这个TGT使用了TGS(Ticket-granting service)的Keytab加密,所以Client是没办法伪造的。
在访问每个Server前,Client需要去票据授权服务(TGS)刷一下TGT,获取每个服务的票据(ST),ST使用了Client要访问的Server的Keytab加密,里面包含了TGS 认证的用户信息,Client是无法伪造ST的。
最后基于每个服务的票据,以及客户端自己生成的加密客户认证信息(Autenticator)访问每个服务。每个Server都有归属于自己的Keytab,Server只有使用Server自己的Keytab才能解密票据(ST),这就避免了Client传给了错误的Server。
与此同时,解密后票据中包含TGS认证的客户信息,通过与Authenticator 中Client生成的客户信息进行对比,如果是一致的,就认为Client是认证通过的。
Hadoop中使用Kinit 工具完成TGT的获取,TGT 一般保存24小时内。Kerberos对Hadoop集群来说,是一个非常安全的认证实现机制。
Kerberos 使用的是Principal标识用户的,它又是
怎么和OpenLDAP中的用户打通的呢?
我们访问HDFS,使用Principal,Hadoop可通过配置hadoop.security.auth_to_local,将Principal映射为系统中的OpenLDAP的用户。用户注册时,平台会为每一个新注册的用户生成Principal以及相对应的Keytab文件。
认证完成后,要解决哪些客户可以访问哪些数据的问题。使用Ranger解决权限管理。
因为Ranger 提供了细粒度的权限控制(Hive列级别),基于策略的访问控制机制,支持丰富的组件以及与Kerberos的良好集成。权限管理的本质,可以抽象成一个模型:“用户-资源-权限”。
数据就是资源,权限的本质是解决哪些人对哪些资源有权限。
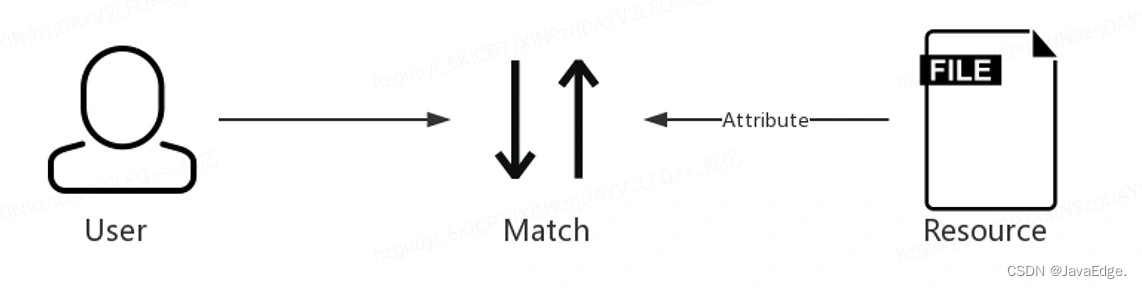
在Ranger中,保存了很多策略,每一个资源都对应了一条策略,对于每个策略中,包含了很多组许可,每个一个许可标识哪个用户或者组拥有CRUD权限。
讲完了用户、认证和权限实现机制,那你可能会问,权限的申请流程是什么样子的呢?
在数据中台中,每一张表都有对应的负责人,当我们在数据地图中找到我们想要的数据的时候,可以直接申请表的访问权限,然后就会发起一个权限申请的工单。表的负责人可以选择授权或者拒绝申请。申请通过后,就可以基于我们自己的Keytab访问该表了。
由于数据中台中会有一些涉及商业机密的核心数据,所以数据权限要根据数据资产等级,制订不同的授权策略,会涉及到不同的权限审批流程,对于一级机密文件,可能需要数据中台负责人来审批,对于一般的表,只需要表的负责人审批。
4 操作审计机制
进行到第三步,权限控制的时候,其实已经大幅降低了数据泄露的风险了,但是一旦真的出现了数据泄露,我们必须能够追查到到底谁泄露了数据,所以,数据中台必须具备审计的功能。
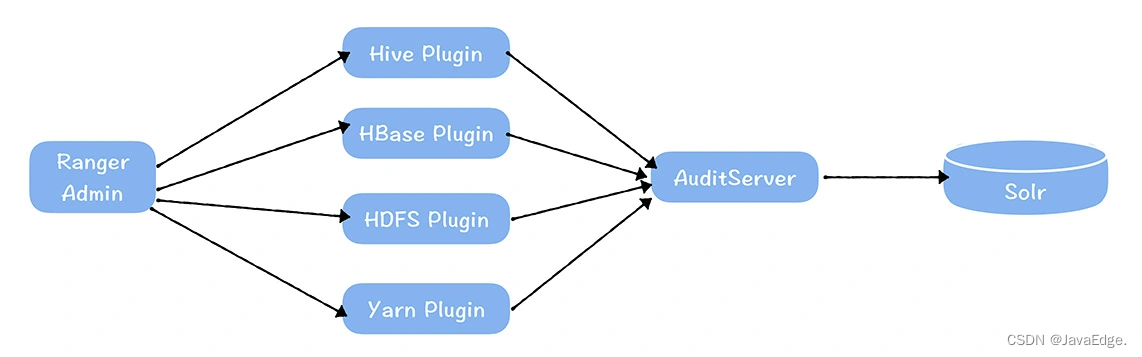
由于用户每次访问数据,都要对权限进行验证,所以在校验权限的同时,可以获取用户访问表的记录,Ranger支持审计的功能,用户的访问记录会由部署在各个服务(HDFS,HBase等等)上的插件推送到Audit Server上,然后存储在Solr中,Ranger提供了API接口查询表的访问记录。但是必须指出的是,Ranger开启Audit 后,会对服务内的插件性能产生影响。
除了敏感数据泄露的风险,我还看到一些企业想要对开发和生产环境进行物理隔离。为什么企业会有这个诉求呢?
首先,很多传统公司的数据开发都是外包人员,从企业的角度,不希望数据开发直接使用生产环境的数据进行测试,从安全角度,他们希望生产和测试从物理集群上完全隔离,数据脱敏以后,给开发环境进行数据测试。
其次,涉及一些基础设施层面的组件升级(比如HDFS、Yarn、Hive、Spark等),贸然直接在生产环境升级,往往会造成兼容性的事故,所以从安全性的角度,企业需要有灰度环境,而用开发环境承担灰度环境的职能,是一个不错的选择。
最后,虽然可以为生产和开发环境设置不同的库和队列,从而实现隔离,避免开发任务影响线上任务和数据,但会导致任务上线需要改动代码,所以最理想的,还是实现开发和生产环境两套集群,同一套代码,在开发环境对应的就是开发集群,提交上线后,就发布到生产集群。
这些就是企业希望开发和生产集群物理隔离的原因,那我们接下来看一看该如何满足。
5 开发、生产集群物理隔离
两类不同企业群体。
5.1 安全性要求>>效率
传统企业,尤其金融行业,严格禁止数据开发使用线上数据测试,他们希望有两套完全不同环境,包括操作平台,任务在开发环境进行开发,配置任务依赖,设置稽核规则和报警,然后由运维审核后,一键发布到生产环境。
当数据开发要对数据测试时,可同步生产环境的局部数据(部分分区),数据会脱敏。
该模式部署架构
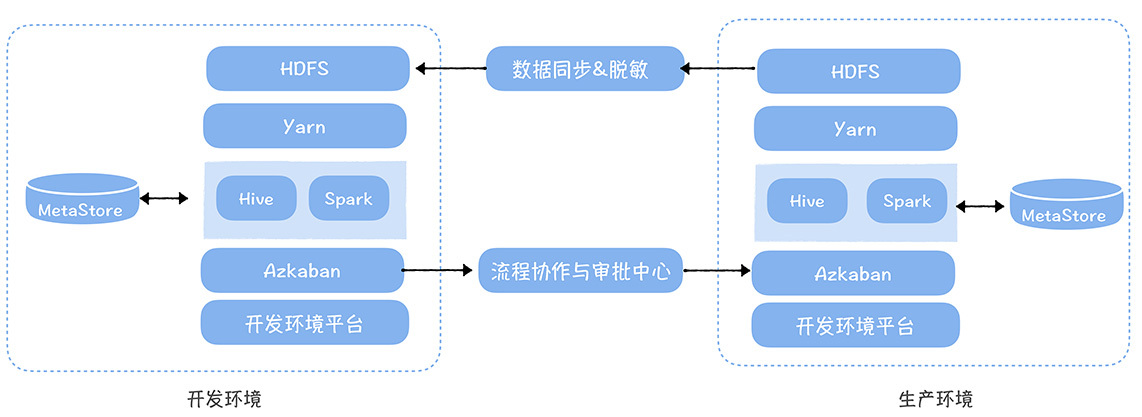
开发、测试环境本身是两套完全独立平台,因为每次数据测试,都要同步生产环境的数据,所以数据开发效率有较大影响,但优势在对数据安全实现最高保护。
很多企业需
5.2 兼顾安全、效率
他们没法接受同步生产环境数据,而是要在开发环境能直接使用线上数据测试。
部署架构
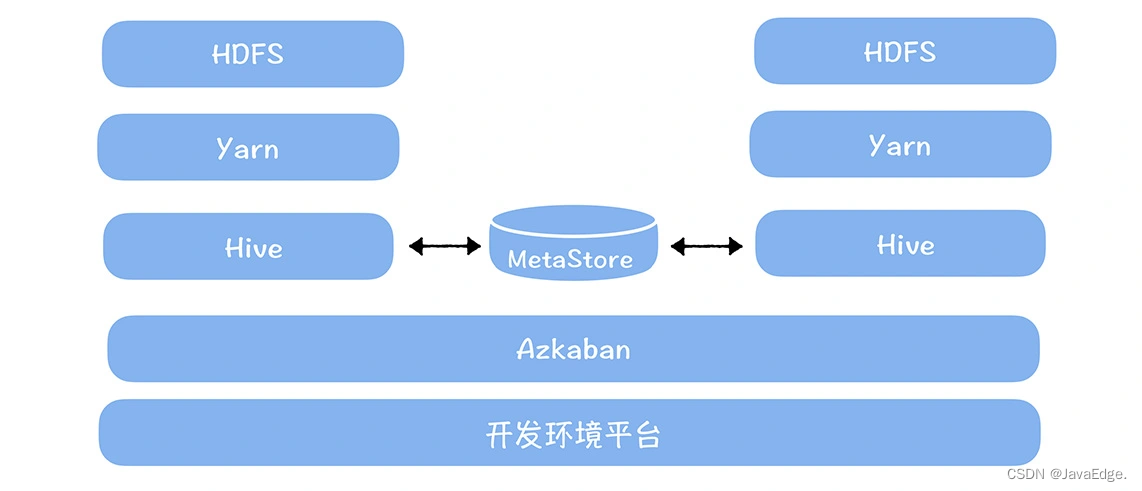
大数据平台和任务调度系统(Azkaban)都是一套,然后Hive、Yarn和HDFS都是两套,两套集群通过Metastore共享元数据。
好处
一个集群的Hive可直接访问另一个集群的数据。在同一Metastore中:
- 开发环境数据在dev库
- 生产环境数据在online库
用户在代码不需指定库,任务执行时,根据运行环境,自动匹配库。如:
- 在开发环境执行,Hive默认用dev库表
- 在生产环境执行,Hive默认用online库表
从而实现不需改代码实现一键发布。
5.3 选型
- 对安全性要求高,推荐第一
- 对效率要求高,同时兼顾一定安全性,推荐第二
6 总结
- 数据备份要兼顾备份性能、成本,推荐EC存储作为备份集群的存储策略
- 数据权限要实现精细化管理,基于OpenLDAP+Kerberos+Ranger可实现一体化用户、认证、权限管理
- 开发、生产环境物理隔离,两种部署模式,权衡效率、安全进行选择
参考
- HDFS EC 存储介绍