RabbitMQ集群搭建详细介绍以及解决搭建过程中的各种问题 + 配置镜像队列——实操型
- 1. 准备工作
- 1.1 安装RabbitMQ
- 1.2 简单部署搭建设计
- 1.3 参考官网
- 2. RabbitMQ 形成集群的方法
- 3. 搭建RabbitMQ集群
- 3.1 部署架构
- 3.2 rabbitmq集群基础知识
- 3.2.1 关于节点名称(标识符)
- 3.2.1.1 节点名称
- 3.2.1.2 主机解析
- 3.2.2 端口访问
- 3.2.3 群集中的节点
- 3.2.3.1 配置 Erlang Cookie
- 3.3 搭建集群(步骤)
- 3.3.1 开放4369端口、25672端口
- 3.3.2 修改每台机器的 /etc/hosts 文件
- 3.3.3 停止服务、配置 Erlang Cookie
- 3.3.4 启动独立节点
- 3.3.5 创建集群
- 3.3.5.1 创建集群步骤
- 3.3.5.2 遇到的问题
- 3.3.5.2.1 问题1:
- 3.3.5.2.1 问题2——移除节点之后重新加入的问题:
- 3.3.6 查看集群状态(命令查看)
- 3.3.7 查看集群状态(UI界面查看)
- 3.4 为集群创建用户
- 3.5 集群——简单实用
- 3.5.1 查看是否启用了自动集群发现机制
- 3.5.2 自动集群发现机制(简单演示)
- 3.6 解除集群节点
- 4. 镜像队列
- 4.1 普通模式集群存在的问题
- 4.1.1 演示问题——不能备份
- 4.1.2 引入镜像队列
- 4.2 配置镜像队列
- 4.2.1 命令式配置策略
- 4.2.1.1 指定复制系数配置策略
- 4.2.1.2 配置镜像到群集中的所有节点
- 4.2.1.3 镜像到群集中的特定节点
- 4.2.2 UI界面操作
- 4.2.3 小知识——ha
- 4.2.4 参考官网
1. 准备工作
1.1 安装RabbitMQ
- 准备3台机器,分别安装上RabbitMQ,这里就不多说了,关于安装可以参考下面的文章,里面写的很详细,如下:
RabbitMQ入门(RabbitMQ的安装 + 解决RabbitMQ安装过程中的版本等问题 + 解决启动RabbitMQ服务失败等问题 + Java客户端使用).
1.2 简单部署搭建设计
-
服务器情况
节点(理解用) 节点名称(计算生成) 主机名 主机IP node1 rabbit@VM-24-15-centos VM-24-15-centos 49.xxx.99 node2 rabbit@hello-TQ2 hello-TQ2 15xxxx212 node3 rabbit@hello_TQ1 hello_TQ1 43.xxx.116 -
部署设计,如下:
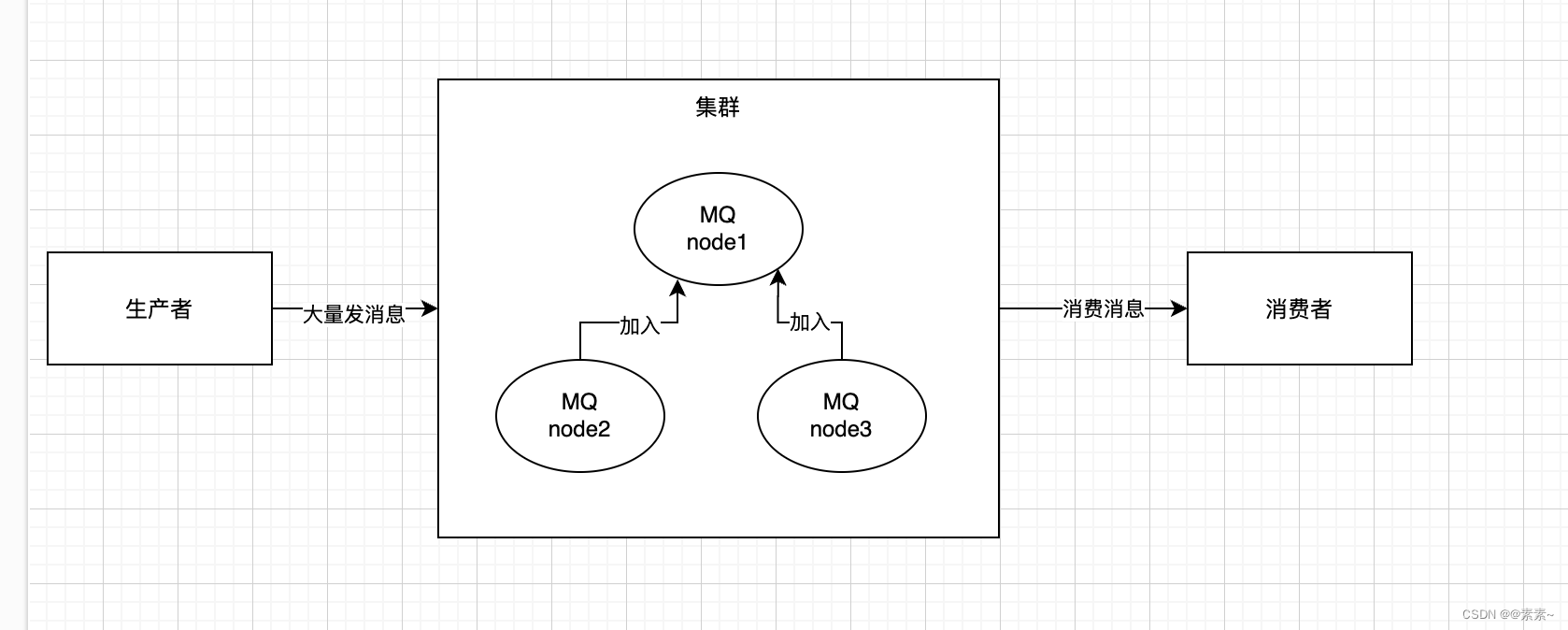
1.3 参考官网
- 找官网参考,如下:
https://www.rabbitmq.com/clustering.html#node-count.
2. RabbitMQ 形成集群的方法
- 官方说了以下几种,感兴趣的可以试试

- 接下来介绍的是最好一种,手动使用 rabbitmqctl
3. 搭建RabbitMQ集群
3.1 部署架构
- 这里详细见1.2中的介绍。
3.2 rabbitmq集群基础知识
3.2.1 关于节点名称(标识符)
3.2.1.1 节点名称
- RabbitMQ 节点由节点名称标识。节点名称由两部分组成,前缀(通常是 rabbit)和主机名。例如,
rabbit@node1.messaging.svc.local是一个节点名称,前缀为 rabbit,主机名为 node1.messaging.svc.local。再例如:rabbit@VM-24-15-centos、rabbit@hello_TQ1。 - 在群集中,节点使用节点名称相互标识和联系。这意味着必须解析每个节点名称的主机名部分。CLI 工具还使用节点名称识别和寻址节点。
- 当节点启动时,它会检查是否已为其分配节点名称。这是通过RABBITMQ_NODENAME环境变量完成的。如果未显式配置任何值,则节点将解析其主机名,并将 rabbit 附加到它以计算其节点名称。
3.2.1.2 主机解析
- 如下:

3.2.2 端口访问
- 开放
4369端口、25672端口,关于相关端口,如下:

3.2.3 群集中的节点
3.2.3.1 配置 Erlang Cookie
- CLI工具如何对节点进行身份验证(以及节点之间的身份验证)
- RabbitMQ 节点和 CLI 工具(例如 rabbitmqctl)使用 cookie 来确定它们是否被允许相互通信。为了使两个节点能够通信,它们必须具有相同的共享密钥,称为Erlang cookie。Cookie 只是一个字母数字字符字符串,最大为 255 个字符。它通常存储在本地文件中。该文件必须仅供所有者访问(例如,具有 600 或类似的 UNIX 权限)。每个群集节点必须具有相同的 Cookie。
- 关于cookie 文件的位置:
- RabbitMQ 服务启动时,erlang VM 会自动创建该 cookie 文件,cookie通常位于
/var/lib/rabbitmq/.erlang.cookie(由服务器使用)和$HOME/.erlang.cookie(由CLI工具使用)中。
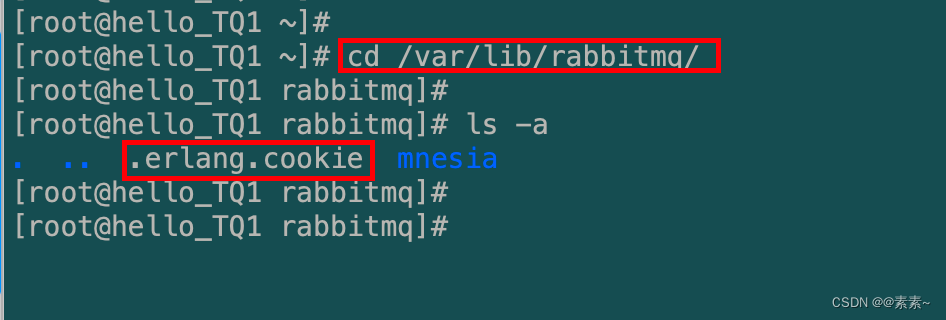
- RabbitMQ 服务启动时,erlang VM 会自动创建该 cookie 文件,cookie通常位于
- 所以,下面搭建集群时,需要统一一下.erlang.cookie文件(要求相同的 Cookie)
- 将node1机器上的.erlang.cookie文件分别拷贝到node2和node3上,拷贝时候记得停止RabbitMQ服务。
3.3 搭建集群(步骤)
3.3.1 开放4369端口、25672端口
- 云服务器的话,开放 4369、25672 端口,如果防火墙是开启的话,执行下面命令:
firewall-cmd --state # 查看防火墙的状态 sudo firewall-cmd --add-port=4369/tcp --permanent sudo firewall-cmd --add-port=25672/tcp --permanent firewall-cmd --reload firewall-cmd --list-all - 如果不开放此端口,后面执行
rabbitmqctl stop_app时报错,不能链接此端口。
3.3.2 修改每台机器的 /etc/hosts 文件
vim /etc/hosts,让集群节点间需能互相访问,故每个集群节点的hosts文件应包含集群内所有节点的信息以保证互相解析。- 需要注意的是:这里的主机名不是随便填写的,你要看你3台服务器的主机名是什么,比如,我在node1节点的主机名是VM-24-15-centos,node2节点的主机名是hello-TQ2,node3节点的主机名是hello_TQ1,所以我在每台服务器上的配置如下:
服务器IP1 VM-24-15-centos 服务器IP2 hello-TQ2 服务器IP3 hello_TQ1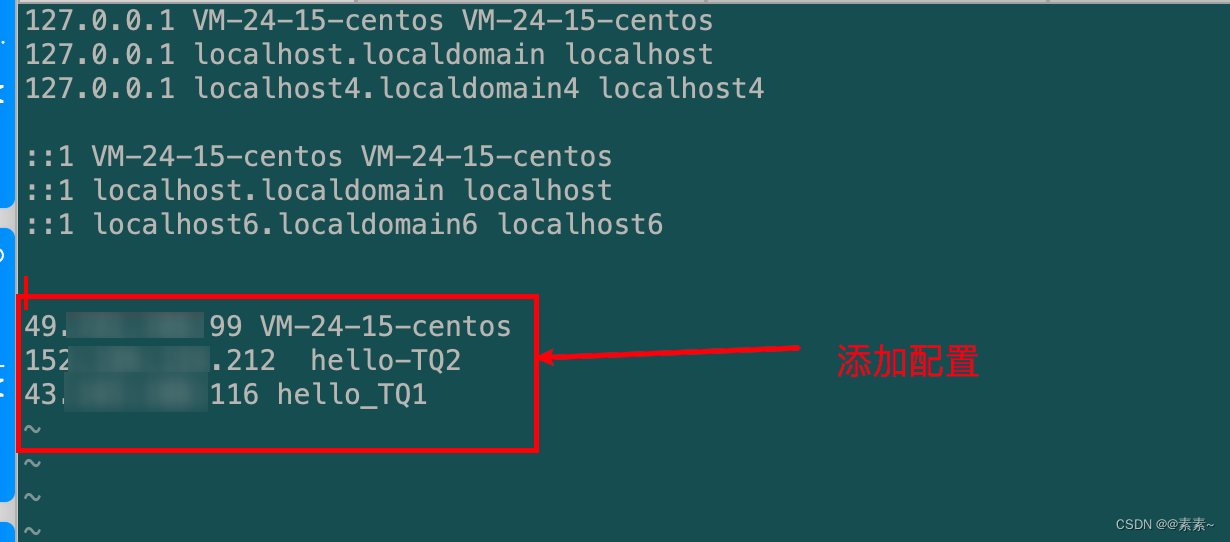
- 需要注意的是:这里的主机名不是随便填写的,你要看你3台服务器的主机名是什么,比如,我在node1节点的主机名是VM-24-15-centos,node2节点的主机名是hello-TQ2,node3节点的主机名是hello_TQ1,所以我在每台服务器上的配置如下:
- 重启网络,便于系统识别hosts
systemctl restart network - 备注:如果你是刚初始化的服务器,可以修改主机名,但是如果你服务器上已经装了很多东西,就没必要修改主机名了(谨慎修改),关于修改主机名的,可以看下面的文章:
云服务器修改主机名hostname.
3.3.3 停止服务、配置 Erlang Cookie
- 这个详细的话见上面说的,操作的话,只需将node1(我这里是VM-24-15-centos主机)上的
.erlang.cookie文件分别拷贝到 node2 和 node3 对应的机器上。 - 停止所有服务,构建Erlang的集群环境
systemctl stop rabbitmq-server 或 service rabbitmq-server stop - 开始拷贝.erlang.cookie
scp /var/lib/rabbitmq/.erlang.cookie root@node2服务IP:/var/lib/rabbitmq/ scp /var/lib/rabbitmq/.erlang.cookie root@node3服务IP:/var/lib/rabbitmq/
3.3.4 启动独立节点
- 启动三台RabbitMQ,以正常方式在所有节点上启动 RabbitMQ,启动命令:
rabbitmq-server -detached
3.3.5 创建集群
3.3.5.1 创建集群步骤
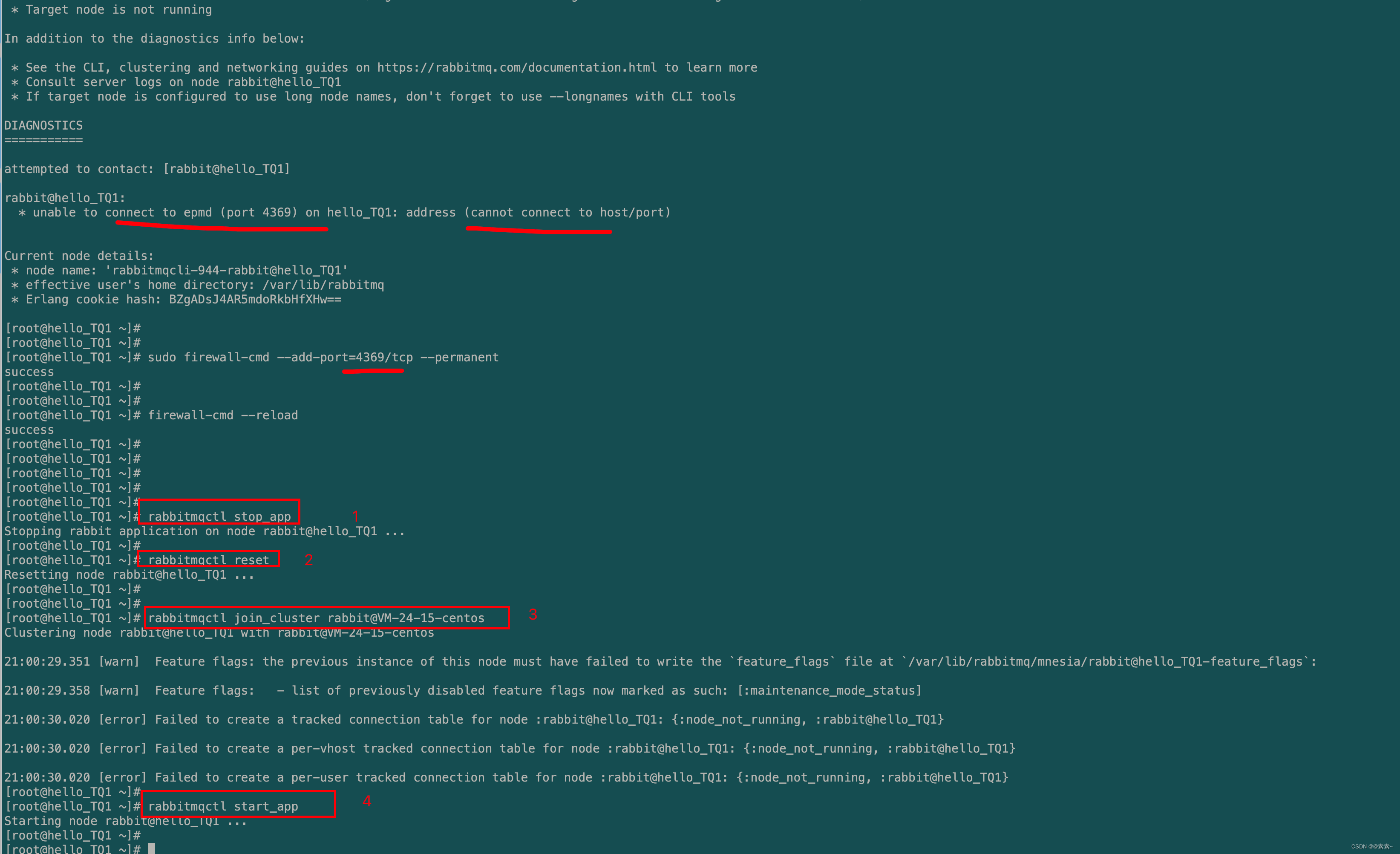
- 为了将集群中的三个节点连接起来,我们告诉其中两个节点,比如
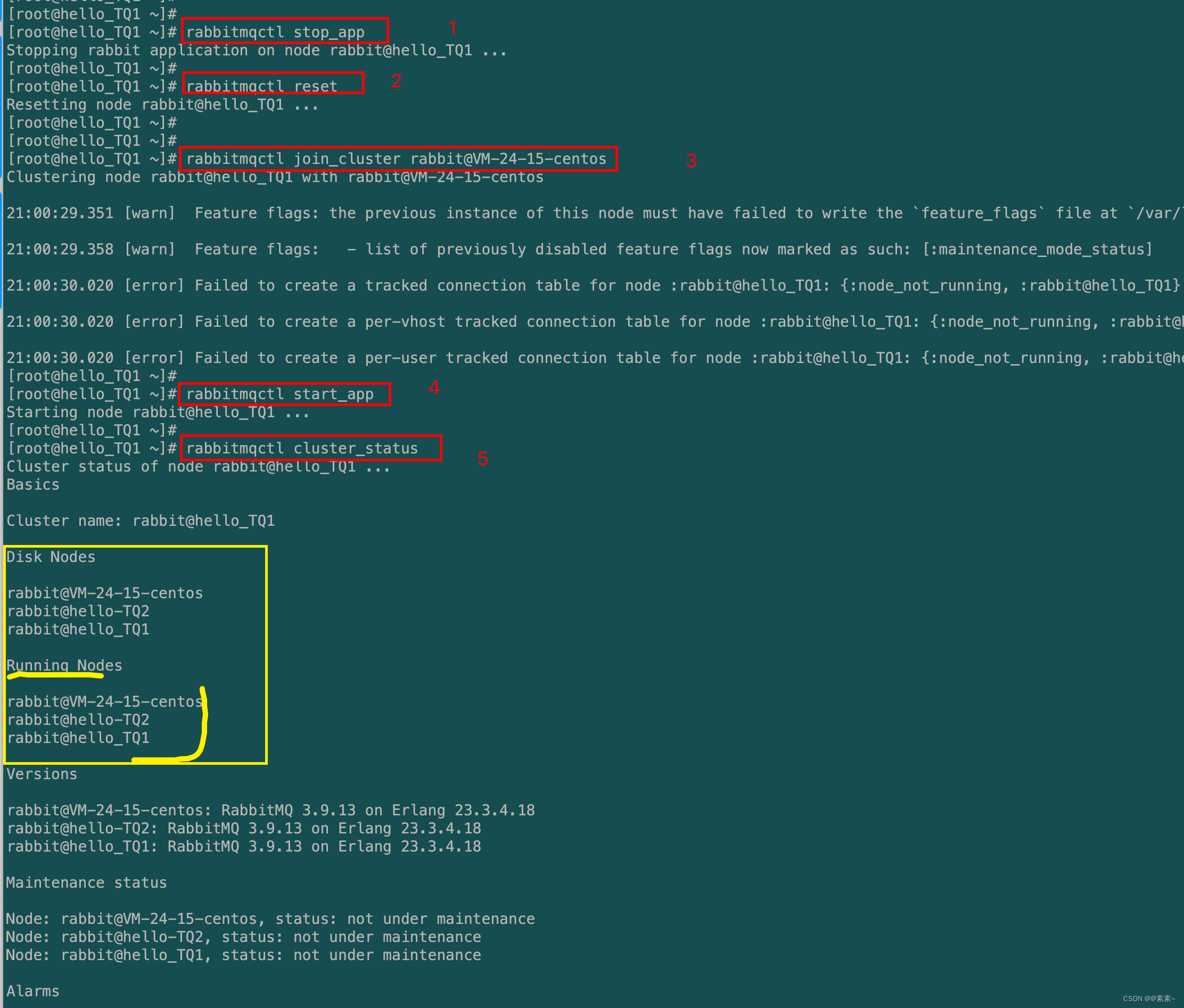
rabbit@hello-TQ2和rabbit@hello_TQ1,加入node1节点的集群,比如rabbit@VM-24-15-centos。在此之前,必须重置两个新加入的成员。- 分别在要加入的两个机上上,执行下面的操作命令:
rabbitmqctl stop_app # 1.关闭RabbitMQ服务 rabbitmqctl reset # 2.重置节点 # 3.节点加入, 在一个node加入cluster之前,必须先停止该node的rabbitmq应用,即先执行stop_app rabbitmqctl join_cluster rabbit@VM-24-15-centos rabbitmqctl start_app # 4.启动服务 - 注意:
- abbitmqctl stop 会将Erlang虚拟机关闭;
- rabbitmqctl stop_app 只关闭rabbitMQ服务
- rabbitmqctl start_app 只启动应用服务
- 分别在要加入的两个机上上,执行下面的操作命令:
- 加入节点、重置节点注意:
- 我们首先将
rabbit@hello-TQ2与rabbit@hello_TQ1加入一个集群。为此,我们要在rabbit@hello-TQ2与rabbit@hello_TQ1上停止 RabbitMQ 应用程序并加入rabbit@VM-24-15-centos(node1节点) 群集,然后重新启动 node2、node3的RabbitMQ 应用程序。 - 请注意,节点必须重置后才能加入现有群集。重置节点会删除该节点上以前存在的所有资源和数据。这意味着,节点不能在成为群集成员的同时保留其现有数据。如果需要这样做,可以使用蓝/绿部署策略或备份和还原。
- 我们首先将
- 操作如下:
3.3.5.2 遇到的问题
3.3.5.2.1 问题1:
- 问题如下:
unable to connect to epmd (port 4369) on VM-24-15-centos: nxdomain (non-existing domain)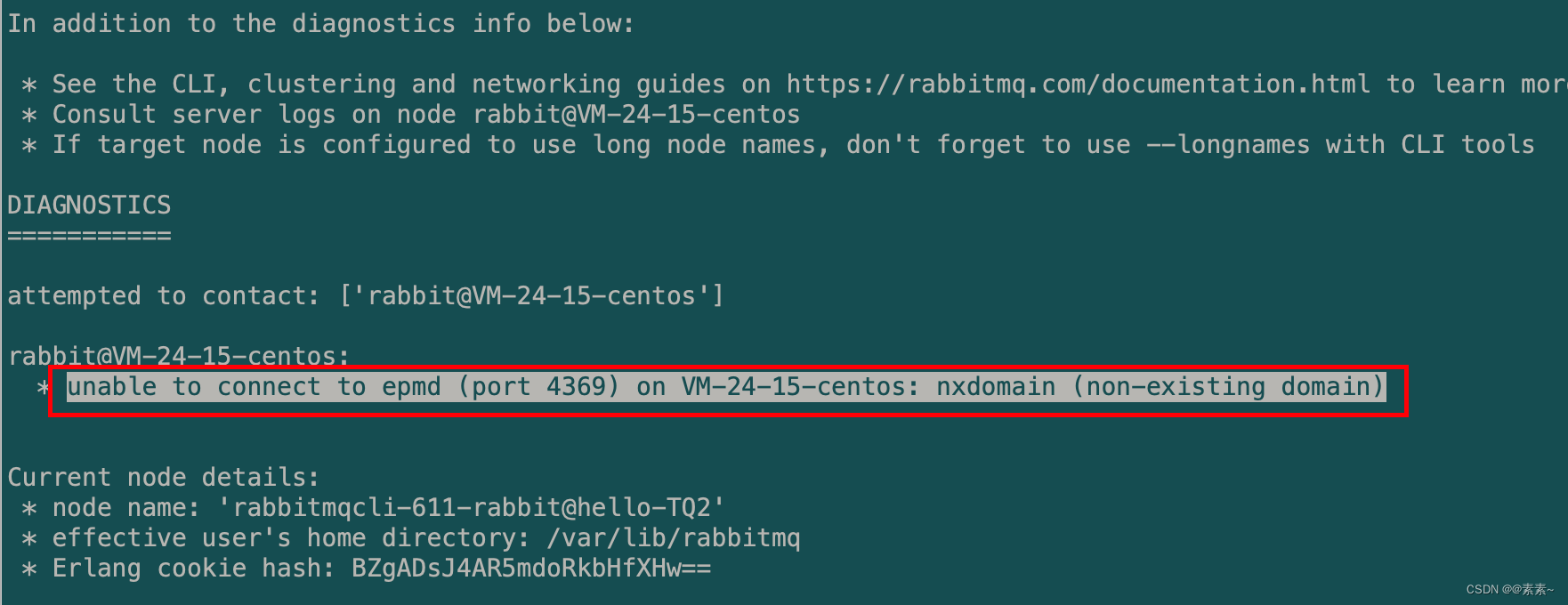
- 解决问题,修改/etc/hosts,让集群节点间需能互相访问,故每个集群节点的hosts文件应包含集群内所有节点的信息以保证互相解析。如果按上面步骤操作应该不会报这个错,所以此处不做过多解释,详细见3.3.2节。
3.3.5.2.1 问题2——移除节点之后重新加入的问题:
- 问题描述:第一次加没问题,移除再次加入直接报错,在执行
rabbitmqctl reset命令时报错,错误如下:Error: {:cannot_start_mnesia, {{:shutdown, {:failed_to_start_child, :mnesia_kernel_sup, :killed}}, {:mnesia_app, :start, [:normal, []]}}}
- 解决问题:
- 第一:先解决上面的问题,解决方法就是删除存储的数据,如下:
cd /var/lib/rabbitmq/mnesia/rabbit@hello_TQ1 rm -rf ./* cd /var/lib/rabbitmq rm -rf erl_crash.dump rm -rf MnesiaCore*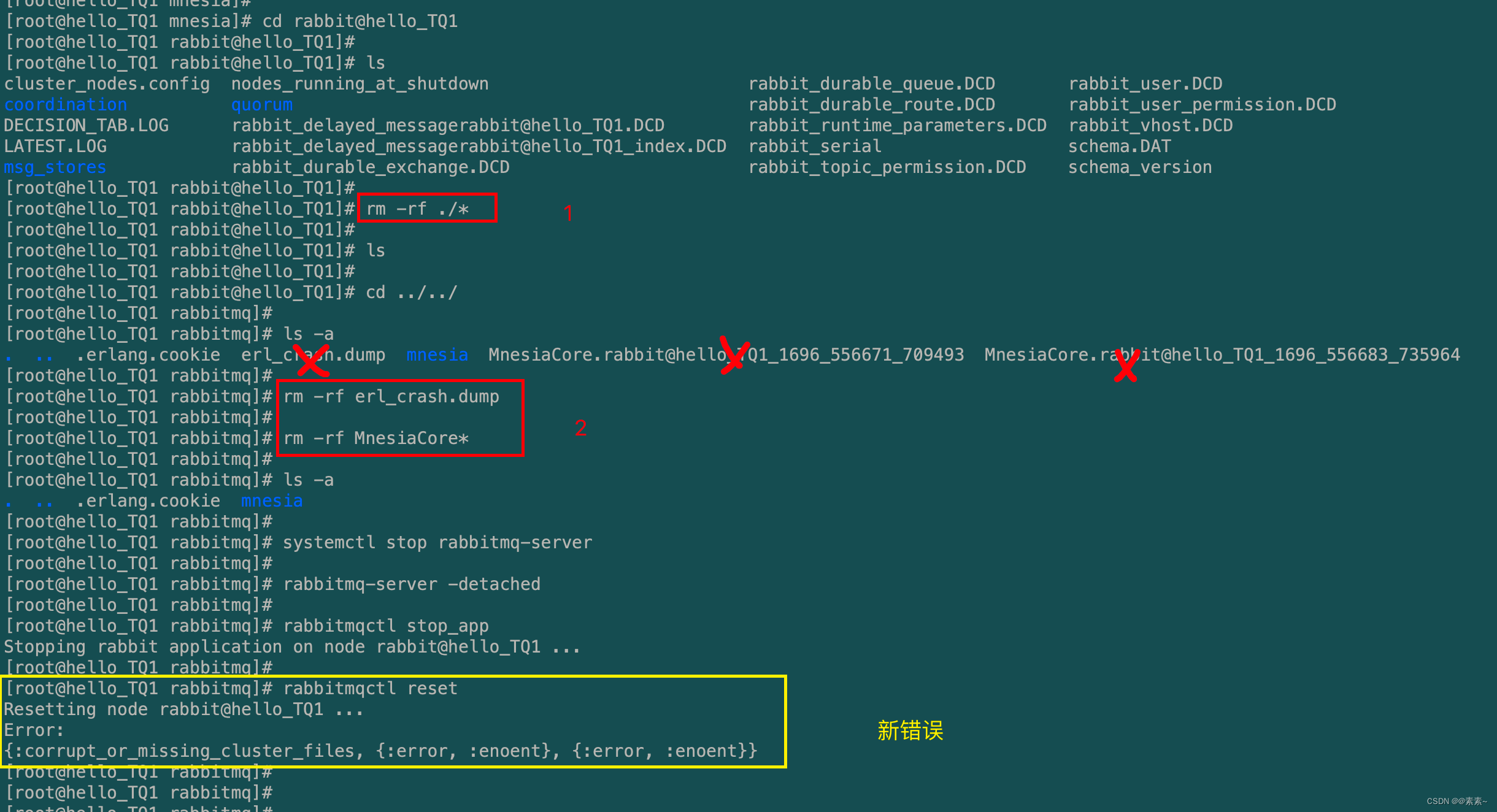
- 第二:解决之后,换了新错误,如下:
Error: {:corrupt_or_missing_cluster_files, {:error, :enoent}, {:error, :enoent}}- 解决问题,rest之前执行一下命令rabbitmqctl cluster_status,一连串的操作如下(上面那个应该也可以按这个解决,不用手动rm-rf,不知道没尝试,但是感觉可以):
rabbitmq-server -detached rabbitmqctl start_app # 先启 rabbitmqctl cluster_status rabbitmqctl stop_app # 再停 rabbitmqctl reset # 重置 rabbitmqctl join_cluster rabbit@VM-24-15-centos rabbitmqctl start_app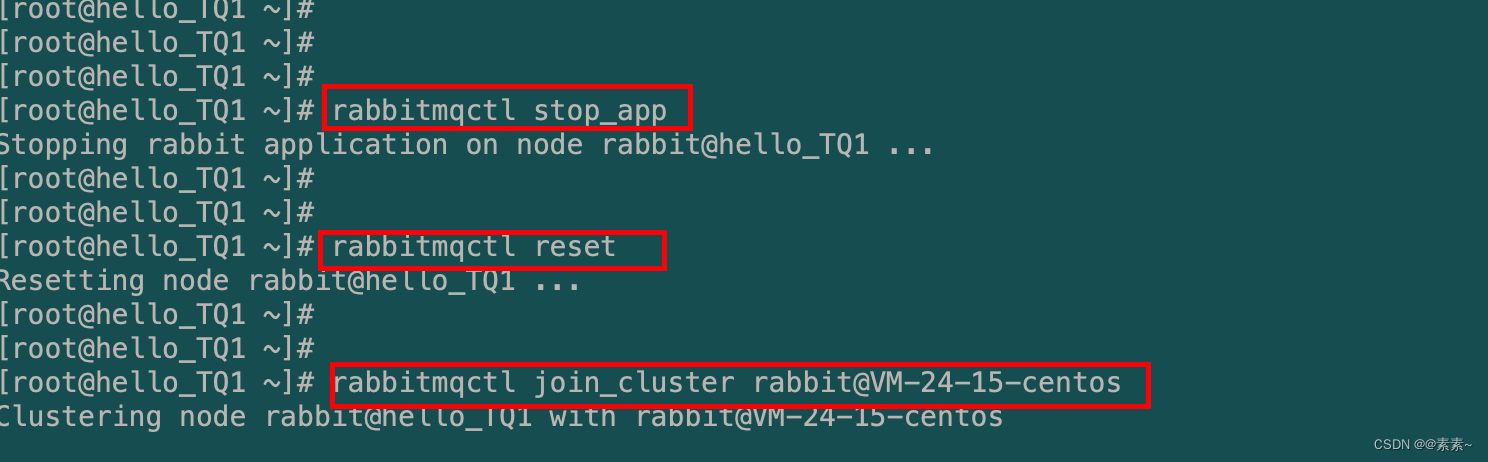
- 解决问题,rest之前执行一下命令rabbitmqctl cluster_status,一连串的操作如下(上面那个应该也可以按这个解决,不用手动rm-rf,不知道没尝试,但是感觉可以):
- 第一:先解决上面的问题,解决方法就是删除存储的数据,如下:
3.3.6 查看集群状态(命令查看)
- 通过在任一节点上运行
rabbitmqctl cluster_status命令,我们可以看到这两个节点已加入集群中:rabbitmqctl cluster_status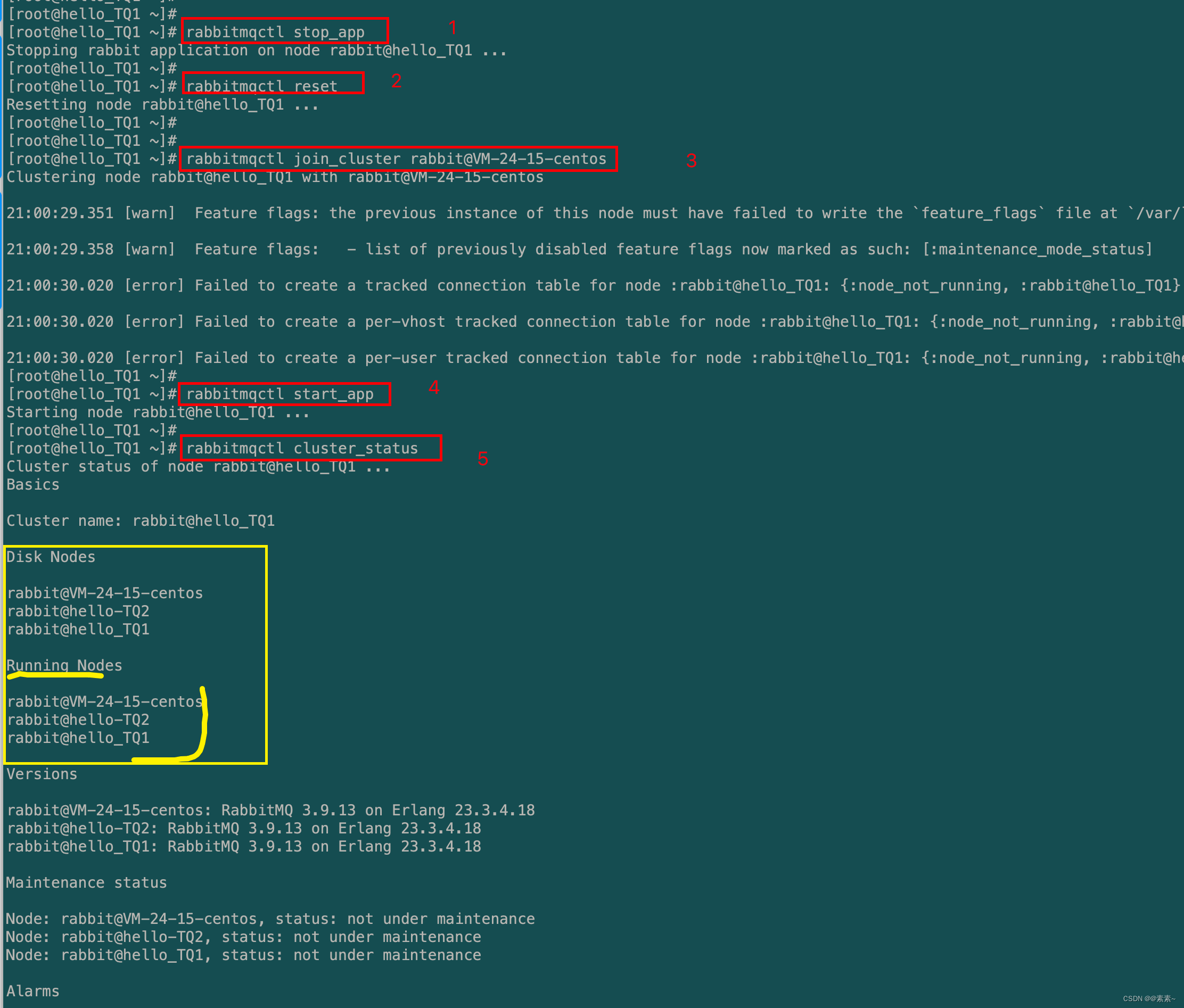
3.3.7 查看集群状态(UI界面查看)
- 如下:
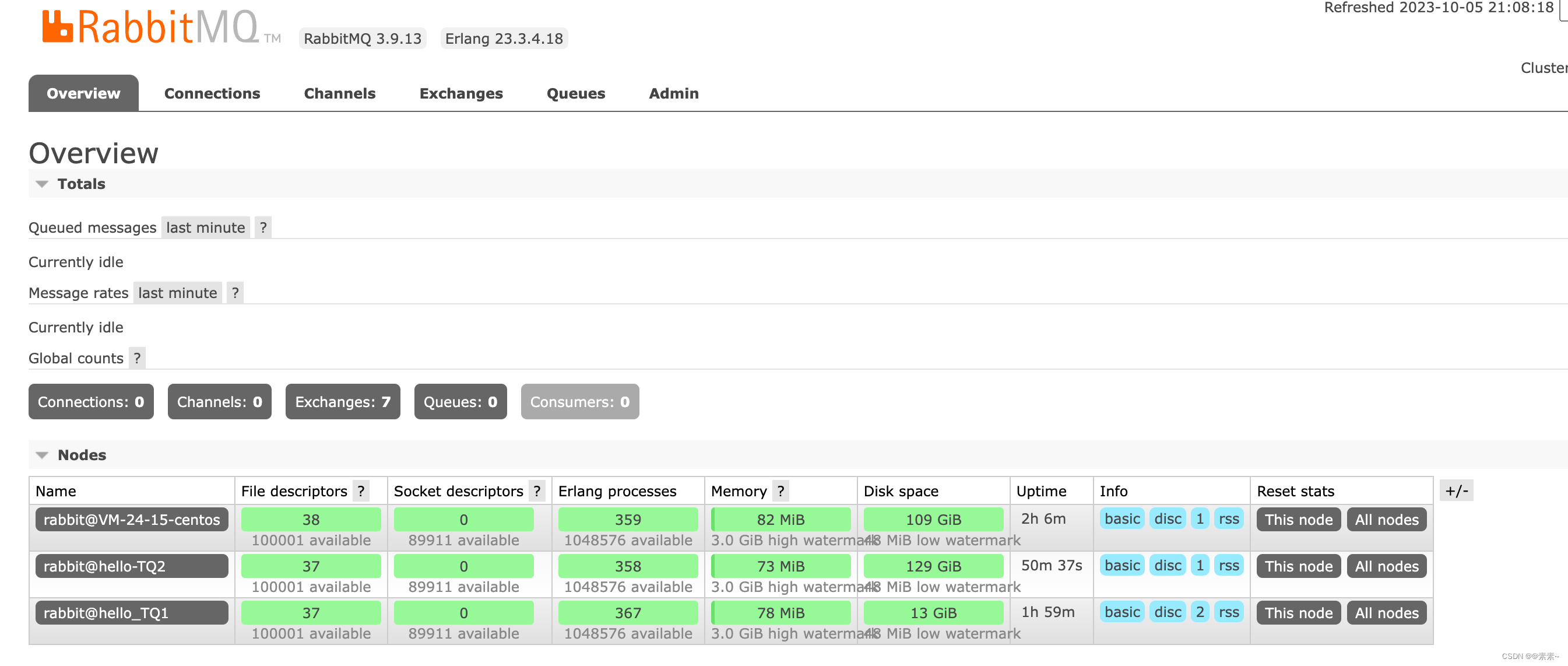
3.4 为集群创建用户
- 如下,在任一台机器上创建即可,创建之后,3个IP都可以登录
rabbitmqctl add_user mqAdmin2 123456 rabbitmqctl set_user_tags mqAdmin2 administrator rabbitmqctl set_permissions -p "/" mqAdmin2 ".*" ".*" ".*"
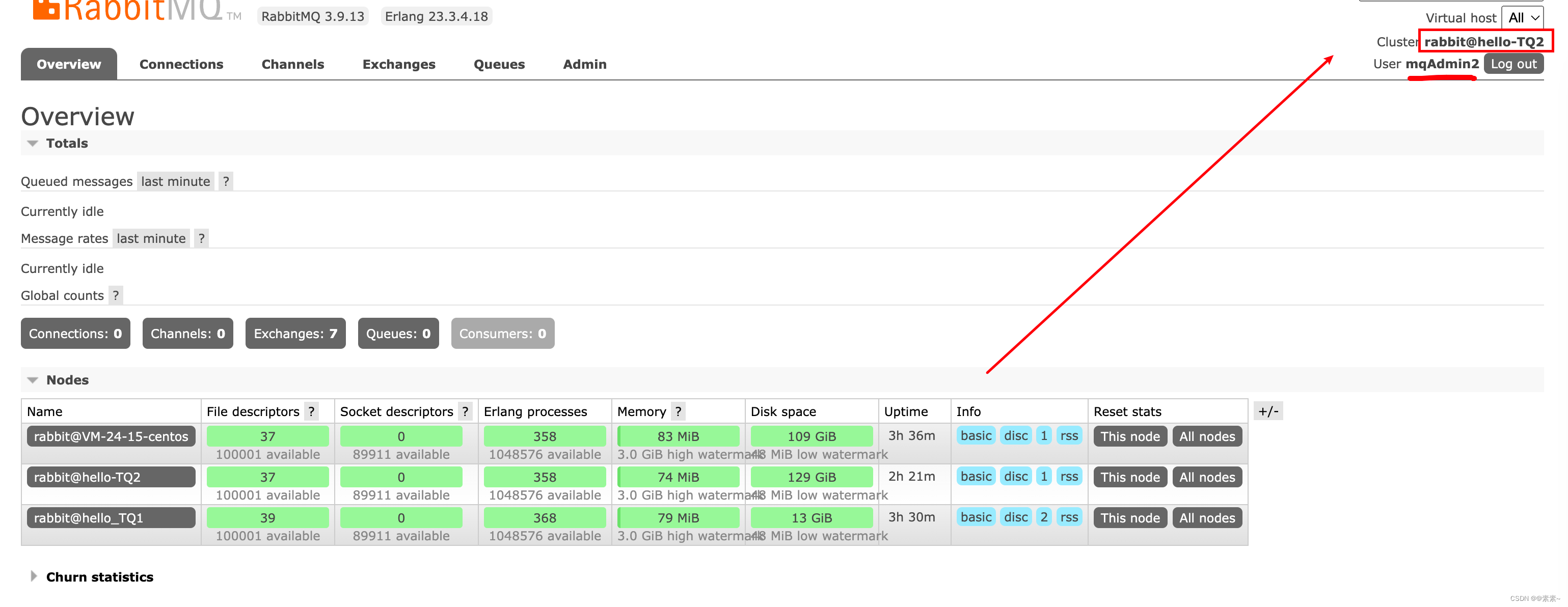
3.5 集群——简单实用
3.5.1 查看是否启用了自动集群发现机制
- rabbitmq集群发现机制:
- 如果集群中默认配置中启用了RabbitMQ的自动集群发现机制。那么在一个节点上创建Exchange或Queue时,它会自动地在整个集群中被发现。
- 当您在一个节点上创建Exchange或Queue时,该节点会将其信息广播到整个集群中,其他节点会收到这个广播消息并自动地创建相应的Exchange或Queue。这种方式可以使得集群中的Exchange和Queue自动地分布到所有节点上,从而提高系统的可用性和可伸缩性。
- 另外前提:我这里的版本是
RabbitMQ 3.9.13 Erlang 23.3.4.18,没有找到默认的rabbitmq.conf文件 或rabbitmq.conf.d文件。- 一般情况下,这两个文件在
/etc/rabbitmq目录下,如果有这个配置文件的,可以查看配置文件里的cluster_formation.peer_discovery_backend行的配置,如果该行的值为rabbit_peer_discovery_classic_config,则表示启用了自动集群发现机制。如果该行的值为其他任何值,则表示未启用自动集群发现机制。 - 如果没有配置文件的,也可通过
rabbitmqctl environment命令查看配置,如下:rabbitmqctl environment | grep peer_discovery_backend
- 一般情况下,这两个文件在
3.5.2 自动集群发现机制(简单演示)
- 如下:在node1上和node3上分别创建一个队列,其他节点上都能发现:

- 并且可以消费,消费一次,在node2上消费之后,其他节点就不会再有此已消费的消息。
3.6 解除集群节点
- 如果想解除node3(rabbit@hello_TQ1):
- 首先,在node3机器上做如下操作,命令如下:
rabbitmqctl stop_app # 关闭rabbitMQ服务 - 然后,在node1上做忘记node3节点的操作,如下:
操作此命令之前,一定要先关闭被忘记的节点的服务,否则,如下错误:rabbitmqctl forget_cluster_node rabbit@hello_TQ1

- 首先,在node3机器上做如下操作,命令如下:
- 根据提示,可知,上面两步操作可以都在node1上完成,直接先stop,再forget,如下:
rabbitmqctl -n rabbit@hello-TQ2 stop_app rabbitmqctl forget_cluster_node rabbit@hello-TQ2
4. 镜像队列
4.1 普通模式集群存在的问题
4.1.1 演示问题——不能备份
- 上面集群虽然可以启动自动集群发现机制,但是存在的问题是,如果创建队列(发送消息)的rabbitmq服务宕机了,消息就丢失了,比如上面node3节点上创建了队列发送了消息,其他node可以发现,但是如下现在node3宕机了,再看下效果:
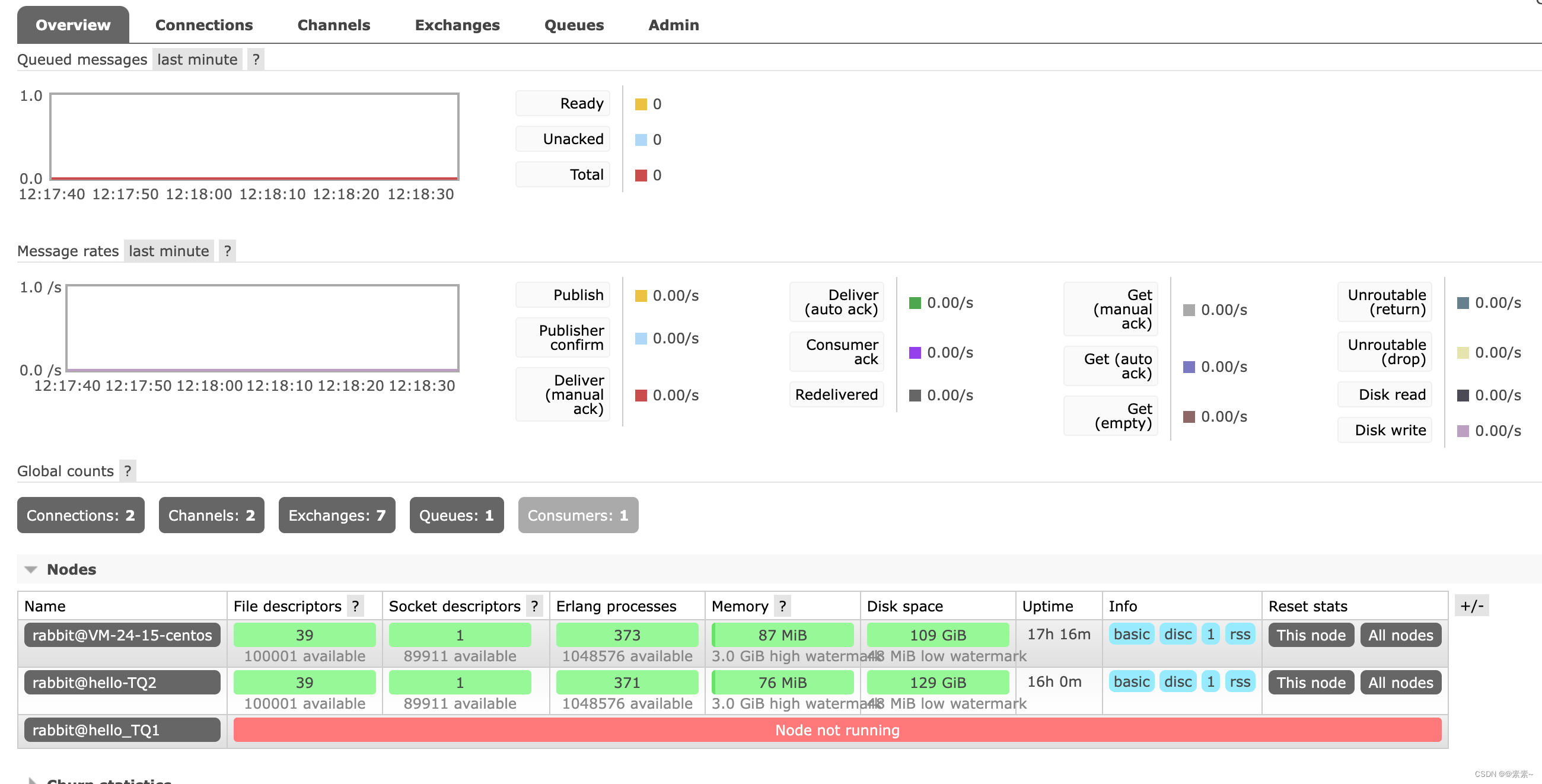
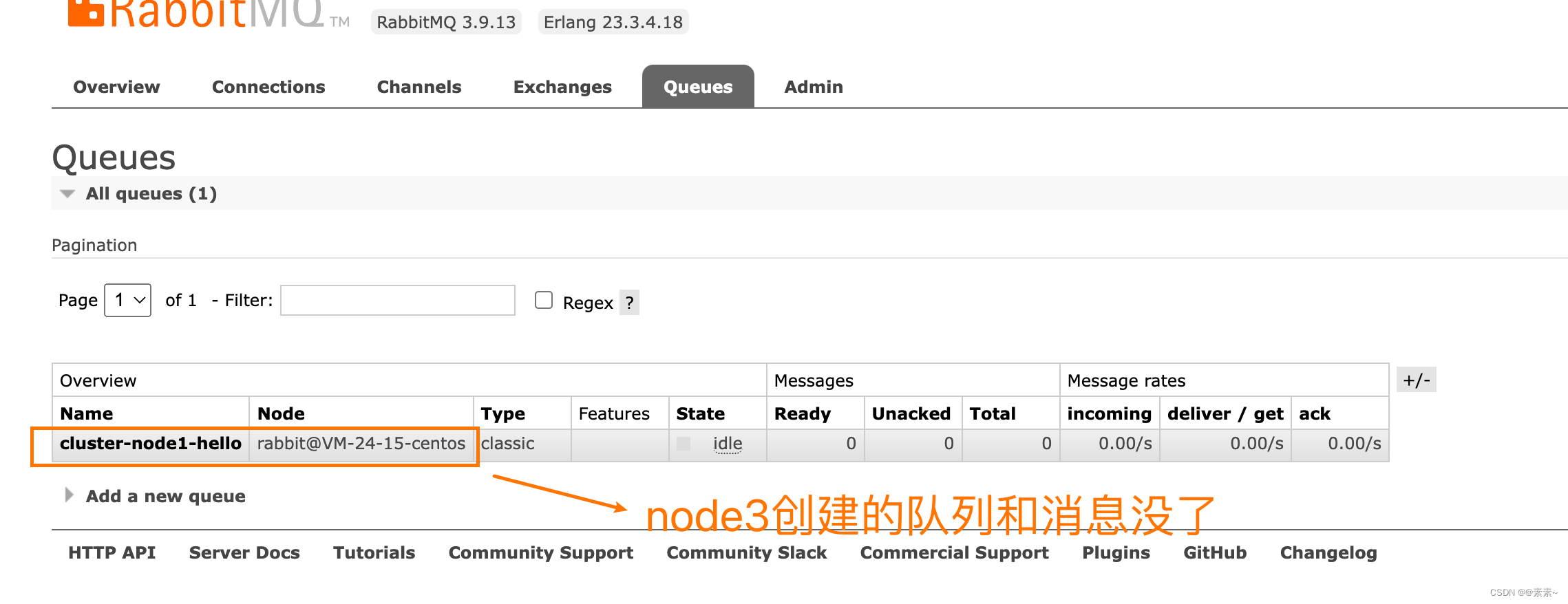
- 所以问题是:只能被发现,但是没有备份!
4.1.2 引入镜像队列
- RabbitMQ的自动集群发现机制可以帮助集群中的Exchange和Queue自动地分布到所有节点上,从而提高系统的可用性和可伸缩性。然而,这种机制并不能完全保证消息的高可用性。如果某个节点出现故障,该节点上的Exchange和Queue可能会丢失或不可用,从而导致消息丢失或无法传递。为了解决这个问题,RabbitMQ提供了镜像队列(Mirrored Queue)的功能。
4.2 配置镜像队列
4.2.1 命令式配置策略
4.2.1.1 指定复制系数配置策略
- 如果你的集群有很多节点,那么此时复制的性能开销就比较大,此时需要选择合适的复制系数。通常可以遵循过半写原则,即对于一个节点数为 n 的集群,只需要同步到 n/2+1 个节点上即可。此时需要同时修改镜像策略为
exactly,并指定复制系数 ha-params。 - 例如:下面是一个策略,其中名称以“two.”开头的队列(注意是:two.开头,别忘了".")将镜像到群集中的任意两个节点,并自动同步。操作命令如下:
rabbitmqctl set_policy ha-two "^two\." \ '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
- 使用Java代码声明一个队列,测试看效果如下:


- 使用Java代码声明一个队列,测试看效果如下:
- 注意:set_policy 后面跟的是策略名称,是可以修改的,如下我用
report-two当策略名称:rabbitmqctl set_policy report-two "^report\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
4.2.1.2 配置镜像到群集中的所有节点
- 以下示例声明一个策略,该策略与名称
以“susu.”开头的队列匹配,并配置镜像到群集中的所有节点。- 操作命令如下:
rabbitmqctl set_policy ha-all "^susu\." '{"ha-mode":"all"}'
- 使用Java代码声明一个队列,测试看效果如下:

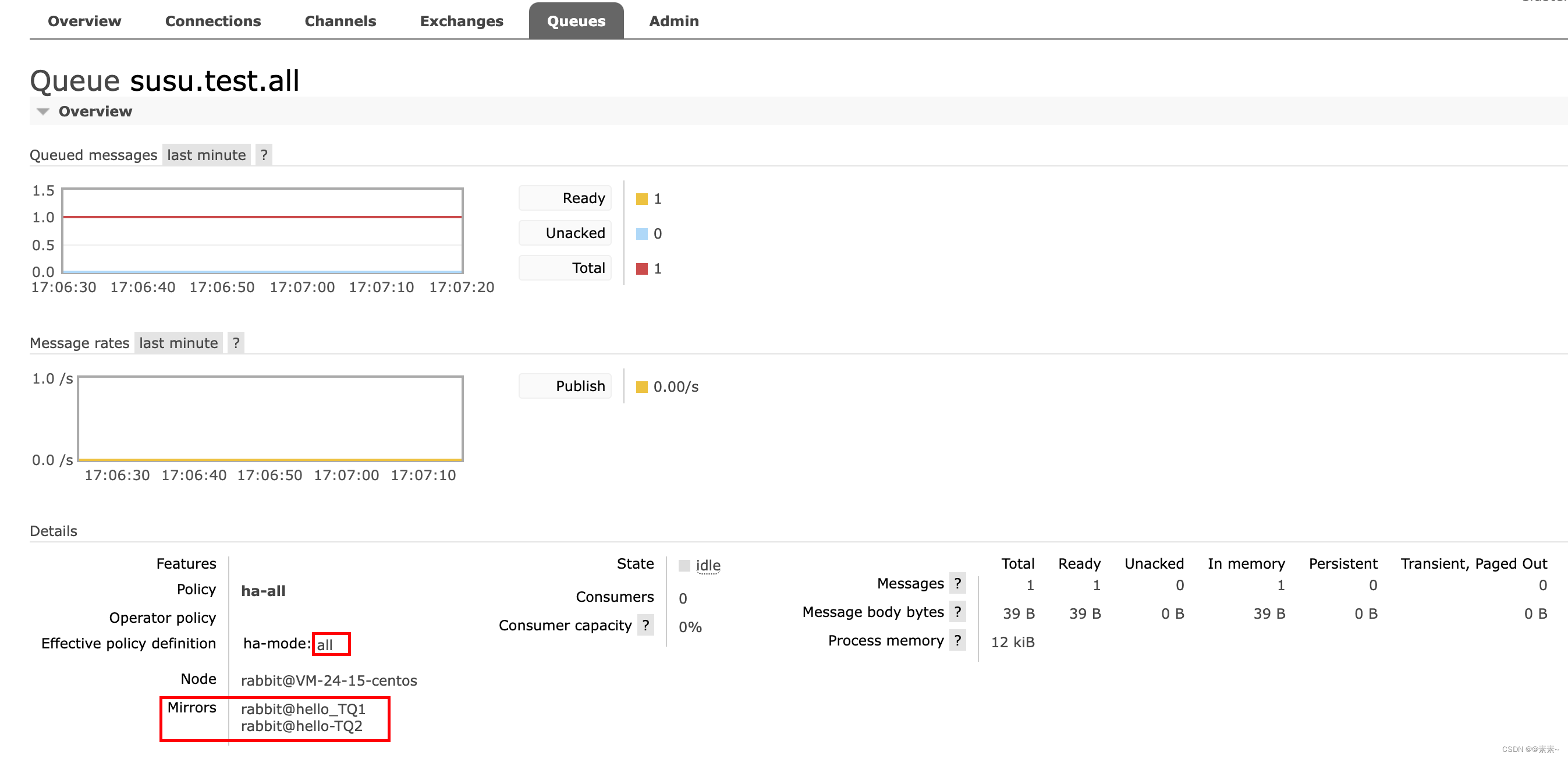
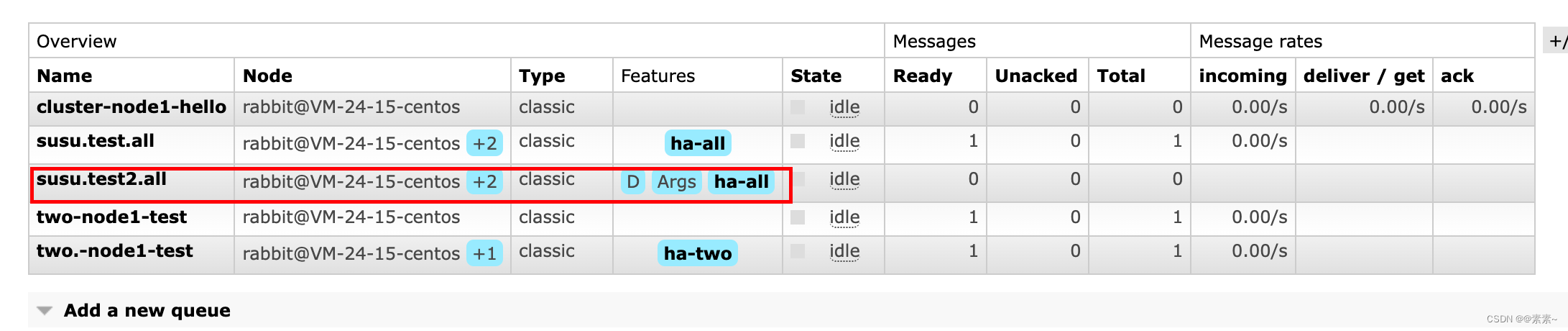
- 当然,在web页面上创建也是一样的效果:
- 操作命令如下:
- 需要注意的是:镜像到所有节点很少是必需的,这会导致不必要的资源浪费。
4.2.1.3 镜像到群集中的特定节点
- 如下配置的一种策略,其中名称
以“beijing.”开头的队列将镜像到群集中的特定节点(即:指定的节点),配置命令如下:rabbitmqctl set_policy ha-nodes "^beijing\." '{"ha-mode":"nodes","ha-params":["rabbit@VM-24-15-centos","rabbit@hello-TQ2"]}'


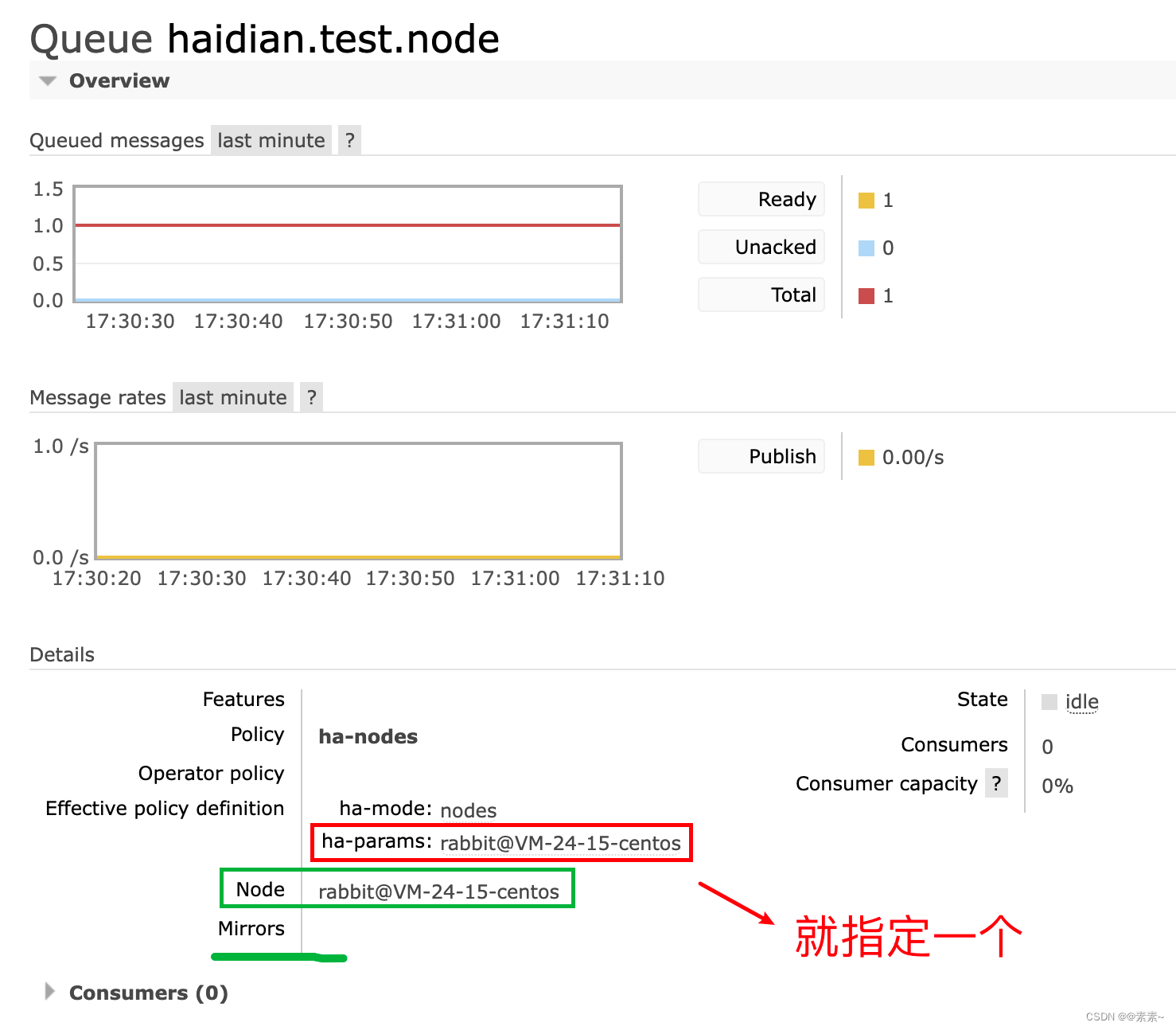
- 当然这种方式的你也可以指定一个节点,如下:
rabbitmqctl set_policy ha-nodes "^haidian\." '{"ha-mode":"nodes","ha-params":["rabbit@VM-24-15-centos"]}'
4.2.2 UI界面操作
- 对于上面的例子在UI界面上如何操作实现,拿第一个例子来说,指定复制系数配置策略,直接看官网怎么说吧,按照步骤来就行了:

其他不多说了,更多请去官网:
https://www.rabbitmq.com/ha.html.
4.2.3 小知识——ha
- 上面命令中有“ha-all“、“ha-mode“、“ha-params“等,这里的
ha指的是:high available(高可用)
4.2.4 参考官网
- 参考官网:
https://www.rabbitmq.com/ha.html.
![2023年中国资产数字化监控运维管理系统行业分析:产品应用领域不断拓展[图]](https://img-blog.csdnimg.cn/img_convert/aa2f42e3284959588c941a252329acd8.png)
![练[WUSTCTF2020]朴实无华](https://img-blog.csdnimg.cn/img_convert/ea8396cd7dcfbbfef4b8f91abdedc8db.png)






![2023年中国短租公寓主要类型、品牌及行业市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/5f5ccd00497e6f2dd94c63847720a4f7.png)