编者按:IDP开启Embedding系列专栏,详细介绍Embedding的发展史、主要技术和应用。
本文是《Embedding技术与应用系列》的第二篇,重点介绍 神经网络的发展历程及其技术架构,剖析了嵌入技术与这些神经网络(Transformer、BERT和GPT等)的关系。
正如OpenAI去年年底推出的ChatGPT在对话领域的重要地位,嵌入技术正在成为人工智能进步的重要基石。本文作者认为,嵌入技术与生成式方法以及基于人类反馈的强化学习相结合,将支持人工智能在自然语言理解和内容生成方面取得更大突破。
通过介绍神经网络技术发展历程中的关键点,作者全面梳理了嵌入技术同神经网络共同演变的脉络,为读者呈现了嵌入技术在神经网络发展过程中所起到的作用,值得我们深入学习和思考。相信随着相关技术的不断进步,嵌入技术必将在推动AI语言能力的持续进步。
以下是译文,enjoy!
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
作者 | Vicki Boykis
编译 | 岳扬
Word2Vec是最早采用嵌入(embedding)概念生成固定特征词汇(fixed feature vocabular)的神经网络架构之一。然而,神经网络在自然语言建模(natural language modeling)方面变得愈加流行,这主要归功于几个关键要素。
首先,在20世纪80年代,研究人员在使用反向传播算法(backpropagation)进行神经网络训练方面取得了一定的进展。 反向传播算法是一种通过计算损失函数(loss function)相对于神经网络权重的梯度,利用微积分中的链式法则(the chain rule)来学习收敛的方法[1]。这种机制使模型能够理解何时达到loss值的全局最小值(global minimum),并通过梯度下降(gradient descent)为模型参数找到正确的权重(correct weights),从而训练模型。早期的方法中(如感知机学习规则(perceptron learning rule)),也尝试过这样做,但有一定的限制,如仅适用于简单的模型架构、收敛时间长以及遭遇梯度消失(vanishing gradients),这使得有效地更新模型的权重十分困难。
这些进步推动了第一类多层神经网络-前馈神经网络(feed-forward neural networks)的出现。1998年,一篇论文使用反向传播算法在多层感知机(multilayer perceptrons)上成功完成了识别手写数字图像的任务[2],展示了开发者和研究人员真正可以应用的实际用例。使用这个MNIST数据集现在是深度学习中经典的“Hello World”入门案例之一。
其次,在21世纪初,出现的PB级数据增长使我们能够从互联网上采集到大量多模态输入数据,进而出现了一些大型数据集。 这导致研究人员能够进行大量实验来证明神经网络在大量级数据上仍然能够正常工作。例如,斯坦福大学的研究人员推出了ImageNet,他们想创建一个神经网络输入数据的黄金标准数据集来提高模型性能。FeiFei Li组织了一支由学生以及Amazon Turk的众包工作者组成的团队,标记了从互联网上抓取的320万张图像,并根据WordNet(一个20世纪70年代出现的分类学)将其按类别进行组织和分类[3]。
研究人员看到了标准数据集的优势。 2015年,Alex Krizhevsky与现在在OpenAI工作的Ilya Sutskever合作,向ImageNet竞赛提交了一份名为AlexNet的作品。它是一个性能优于很多其他方法的卷积神经网络。
AlexNet有两个特别之处。第一处是它有八层堆叠的权重层和偏置层(eight stacked layers of weights and biases),这在当时是极不寻常的。如今,12层的神经网络(如BERT和其他transformers)都是完全正常的,但在当时,神经网络超过两层就是变革性的。第二处是AlexNet在GPU上运行,这在当时是一个新的架构概念,因为当时GPU主要用于游戏的图形渲染。另外,Ilya Sutskever现在是GPT系列模型背后的主要研究人员之一,GPT系列模型是当前生成式人工智能浪潮的基础。
神经网络结构(如循环神经网络(RNN)和后来的长短期记忆网络(LSTM))作为生成词汇表征(representations of vocabularies)的方法开始流行起来。 这些神经网络结构也成为了处理文本数据的方法,用于自然语言处理、计算机视觉等各种机器学习任务。神经网络是对传统机器学习模型的扩展,但它们具有一些独特的特征。在传统的机器学习方法中,只有一组或一层可学习的参数以及一个模型。如果输入的数据没有复杂的相互作用(interactions),传统机器学习模型可以相当容易地学习特征空间(feature space)并进行准确的预测。
然而,传统机器学习模型带来的问题是,当我们开始处理非常大的、潜在的(implicit)特征空间(比如存在于文本、音频或视频中),我们会无法推导出具体的特征。如果我们人工创建这些特征,这些特征将会不明显。通过将神经元堆叠在一起(译者注:这是构建神经网络的一种方法,通过堆叠神经元,多个层可以相互连接,从而构建出具有更强表达能力的、更复杂的深度神经网络模型),每个神经元代表模型的某一个方面,神经网络可以提取这些隐层表征(latent representations,译者注:在机器学习和深度学习中,数据通常会被转换为一个向量或者矩阵的形式。这个转换过程叫做“表征学习”。其中,将输入数据转换为一组隐式的表征,又被称为空间中的“隐式表征”或“隐式变量”)。神经网络非常善于学习数据的表征(representation),神经网络的每一层都会将前一层学到的表示转换成更高层次的表示,直到我们获得清晰的数据图像[4]。
01 深度学习架构
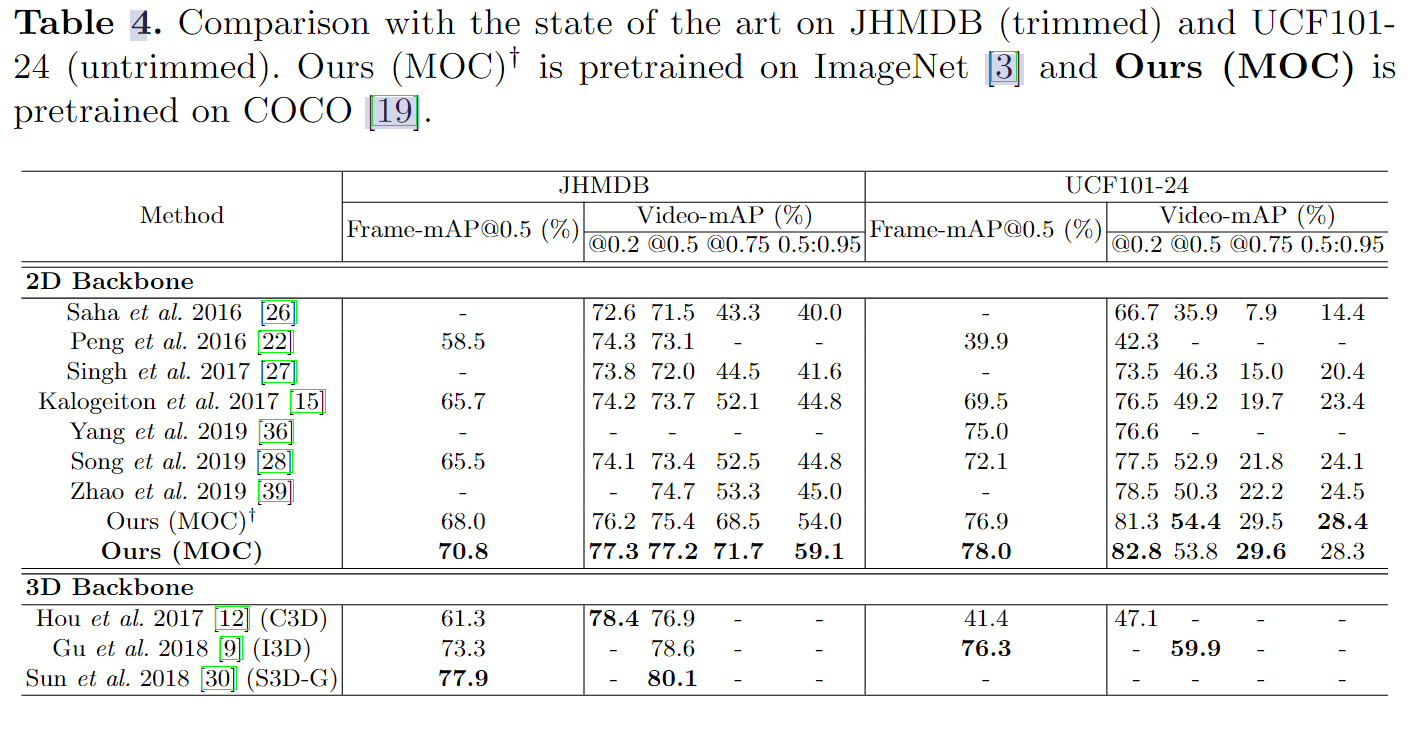
我们已经前面已经提到了神经网络Word2Vec,这个神经网络试图去理解文本中单词之间的关系,而这些单词本身无法告知我们。在这个领域,有以下几种主流的神经网络架构:
- 前馈网络: 从固定长度的输入中提取含义。其输出结果不会反馈给模型进行迭代。
- 卷积神经网络(CNNs): 其主要用于图像处理,拥有一个由滤波器组成的卷积层,滤波器在图像上不断移动来检查特征表示(feature representations),然后通过进行点积与滤波器相乘来输出特定的特征。
- 循环神经网络(RNNs): 它们接受一连串的词语项(items),并产生一个概括该句子的向量。
RNN和CNN主要用于特征提取(feature extraction),一般不代表整个模型构建流程,但在这之后将被送入前馈模型中,然后再完成分类、摘要等工作。
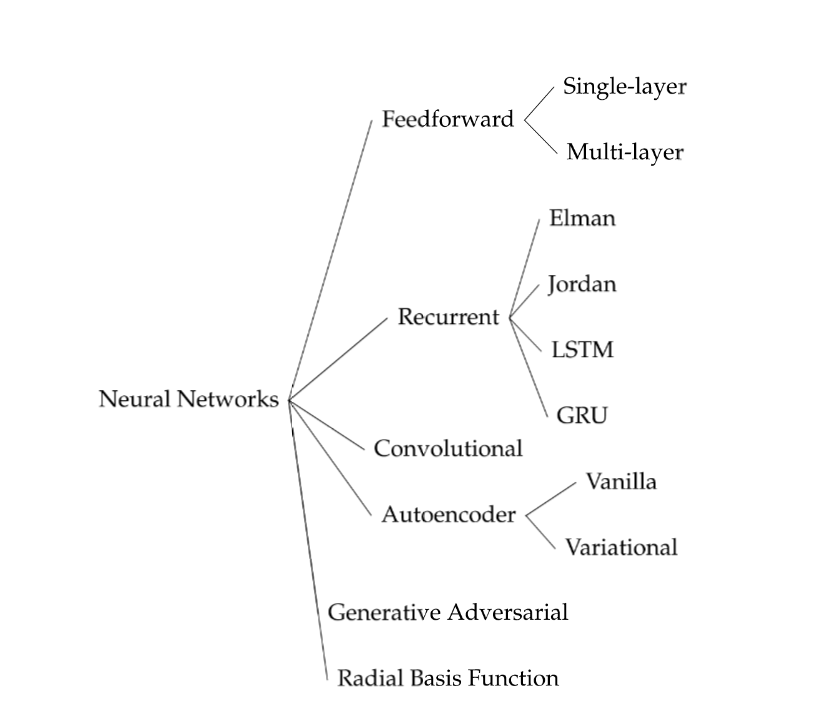
图1 神经网络的种类
由于某些原因,神经网络的构建和管理都变得非常复杂。首先,这个过程需要大量的干净、标注清晰的数据来进行优化。其次,这个流程需要特殊GPU架构来进行处理,并且它们有自己的元数据管理(metadata management)和网络延迟注意事项(latency considerations)。最后,在神经网络本身,我们需要使用大量的训练数据对模型对象(the model object)进行处理,以使其收敛。我们需要用于运算的特征矩阵数量以及必须在模型生命周期内保留于内存中的数据量一直在不断累积,这就需要大量的性能调优(performance tuning)。
这些特性使得开发和运行神经网络的成本高得令人望而却步,直到最近的15年左右才实现突破。 首先,随着实体计算服务和云计算服务的规模不断扩大,市场上的存储空间呈指数级增长,这意味着我们现在有能力存储大量训练数据,而互联网数据的爆炸也为谷歌等公司提供了大量的训练数据。其次,GPU的使用也得到了普及,GPU是一种支持并行计算的硬件——适用于容易将任务分离成可以并行执行的任务,例如单词数量计算。在神经网络中,我们通常可以以任何给定的并行数量的方式并行计算,包括在单个神经元的层面上。
尽管GPU最初是用于处理计算机图形的,但在21世纪初 [5] ,研究人员发现了将其用于通用计算的潜力,Nvidia通过引入CUDA(即GPU之上的API层)入场“押宝”GPU用于通用计算。反过来又推动了主流高级深度学习框架(如PyTorch和Tensorflow)的出现和发展 。
现在神经网络可以被大规模地训练和实验。与我们之前介绍的方法相比,当我们计算TF-IDF时,我们需要循环遍历每个单词,在整个数据集上按顺序执行计算,以达到与其他单词成比例的分数,其时间复杂度将为O(ND) [6]。
然而,使用神经网络,我们可以将模型训练分布在不同的GPU上,这个过程被称为模型并行(model parallelism),或者计算batches——将训练数据的大小送入模型中,在训练循环中与其他数据一起并行更新超参数(hyperparameters),并在每个minibatch结束时进行更新,这被称为数据并行 [7]。
02 Transformers
Word2Vec是一种前馈网络(feed-forward network),其模型权重和信息仅从编码层(the encoding state)流向隐藏嵌入层(译者注:the hidden embedding layer,是Word2Vec模型中的一个隐藏层,它的作用是将输入的单词转换为一个向量表征,也称为嵌入向量。),再流向输出概率层(译者注:the output probability layer,是Word2Vec模型中的最后一层,它的作用是将隐藏层的嵌入向量映射为每个单词的概率分布。)。第二层和第三层之间没有反馈,这意味着每一层都对其后各层的状态一无所知。因此,它无法提供比上下文窗口大小更长的推理建议。但是,对于那些只需要使用单一、静态词汇的机器学习问题,这种模型非常有效。
然而,对于需要结合语境理解单词的长篇文章,Word2Vec就表现不佳了。 举个例子,假如在一次对话中,我们说了这样一句话:“我读了Langston Hughes的那句话,我喜欢它,但并没有真正读过他后来的作品。”我们可以理解,“它”指的是那句话,需要结合前一句的语境,而“他”指的是两句前提到的“Langston Hughes”。
另外,Word2Vec无法处理词汇表之外的单词,即模型尚未训练过的,需要泛化的单词。 这意味着,如果用户搜索一个新产生的热门词汇,或者我们想要推荐一个在模型训练之后才产生的内容,用户将无法从该模型的结果中看到任何相关内容[8],除非经常重新训练模型。
Word2Vec 面临的另一个问题是多义词导致的语境崩溃 —— 同一词语可能含有多种不同的含义:例如,如果在同一句子中有 “jail cell” 和 “cell phone” ,Word2Vec可能无法区分这两个词在不同语境下的不同含义。因此,基于深度学习的 NLP 的大部分工作都是为了保留和理解上下文,以便通过模型传播并提取语义。
为了克服Word2Vec的这些限制条件,人们提出了多种不同的方法,有研究人员尝试使用循环神经网络(RNN)。 RNN基于传统的前馈网络,不同之处在于模型的各层会向前层提供反馈。这使得模型可以记住句子中单词周围的语境,从而更好地理解多义词在此处的含义。
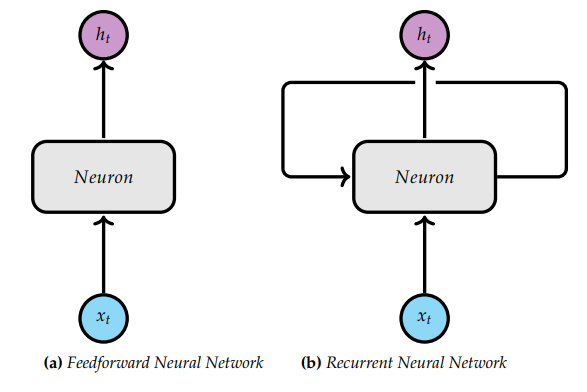
图2 前馈神经网络和循环神经网络架构图
传统的RNN存在这样一种问题,在反向传播过程中,权重必须传递到上一层神经元,因此会出现梯度消失的问题。 当我们连续求导,使得反向传播过程中链式法则(chain rule)中使用的偏导数趋近于零时,就会出现这种情况。一旦趋近于零,神经网络就会认为它已经达到了局部最优,并在收敛前停止训练。
为了解决这个问题,出现了一种非常流行的RNN变体,即长短期记忆网络(LSTM) ,该网络最初由Schmidhuber开发,后来在语音识别(text applications speech recognition)和图像描述(image captioning)[9]等领域得到广泛应用。相比之前的模型每次只能输入一个向量,RNN可以使用门控循环单元(GRU)处理向量序列,这使得 LSTM 可以控制输入分析的信息量。虽然 LSTM 的效果相当不错,但它们也有一定的局限性。由于其架构比较复杂,无法进行并行训练,因此训练时间更长,计算成本更高。
2.1 Encoders/Decoders and Attention 编码器/解码器架构和注意力机制
与之前的 RNN 和 Word2Vec 相比,有两个概念使研究人员能够克服在更大的上下文窗口中记忆长向量所带来的计算昂贵问题:编码器/解码器架构和注意力机制。
编码器/解码器架构是一种由两个神经网络组成的神经网络架构,编码器从数据中获取输入向量(input vectors)并创建固定长度的嵌入,另一个解码器(也是一个神经网络)将编码后的嵌入(embeddings encoded)作为输入,并生成一组静态输出,如文本翻译或进行文本摘要。在这两类层之间的是注意力机制,这是一种通过不断执行加权矩阵乘法来保持整个输入状态的方法,这种乘法可以突出词汇表中特定术语之间的相关性。我们可以将注意力(attention)看作一个非常庞大且复杂的哈希表,它可以跟踪文本中的单词,以及这些单词如何映射到输入和输出中的不同表述。
图3 编码器/解码器架构图

图4 典型的编码器/解码器结构,来自《the Annotated Transformer》[10]
2017年发布的《Attention is All You Need》[11]将这两个概念结合到了一个单一的神经网络架构中。这篇论文立刻获得了巨大成功,如今Transformer已成为自然语言处理任务中使用的标准模型之一。
基于原始模型的成功,Transformer 架构的大量变体相继发布。2018年发布了 GPT 和 BERT ,2019 年发布了 BERT 的更小更紧凑版本 Distilbert,2020 年发布了 GPT-3。
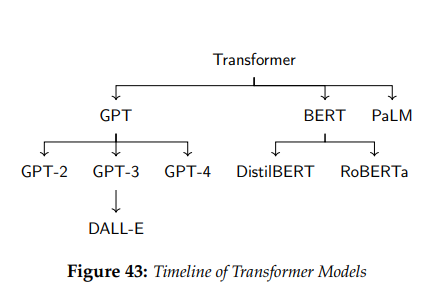
图5 Transformer模型大事记
Transformer 架构本身并不新鲜,但其包含了我们到目前为止讨论过的所有概念:向量(vectors)、编码(encodings)和哈希映射(hash maps)。
Transformer 模型的目标是获取一段多模态内容,并通过在输入语料中创建单词组的多个视图(即多个上下文窗口)来学习其中的潜在关系。在Transformer论文中,自注意力机制是以缩放点积注意力(scaled dot-product attention)的形式实现的,它通过六层编码器层和六层解码器层多次创建数据的不同上下文窗口。输出的是特定机器学习任务的结果,例如翻译句子或总结段落,而倒数第二层是模型的嵌入,我们可以将其用于下游任务。
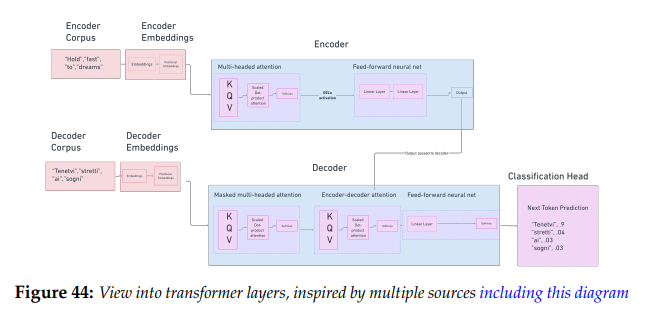
图6 基于多个来源(包括这张图[12])的启发,提供这张Transformer的层视图
论文中所描述的Transformer模型以文本语料库作为输入。我们首先通过分词(tokenizing)将文本转换为token嵌入,并将每一个单词或子单词映射为一个索引。这与 Word2Vec 的流程相同:我们只需将每个单词分配给矩阵中的一个元素即可。然而,仅凭这些并不能帮助我们理解上下文,因此,在此基础上,我们还要借助正弦函数或余弦函数来学习位置嵌入(positional embeddings),将词汇表中其他所有单词的位置映射并压缩到矩阵中。这一过程的最终输出是位置向量(positional vector)或单词编码(word encoding)。
接下来,这些位置向量将并行传递给模型。在Transformer论文中,模型由六层编码层和六层解码层组成。从编码器层开始介绍,该层由两个子层组成:自注意力层和前馈神经网络。自注意力层是关键部分,它通过缩放点积注意力(scaled dot-product attention)来学习每个术语与其他术语之间的关系。我们可以将自注意力看作是一个可微分的查找表(as a differentiable lookup table),或者是一个包含术语及其位置的大型查找字典(as a large lookup dictionary that contains both the terms and their positions),每个术语与其他术语之间的关系权重都是从前几层获得的。
缩放点积注意力涉及三个矩阵的计算:键矩阵(key)、查询矩阵(query)和值矩阵(value)。这些矩阵最初都是前几层输出的相同值。在模型的第一次学习时,它们被随机初始化并通过梯度下降在每一步都进行调整。对于每个嵌入(embedding),我们都会根据这些学习到的注意力权重生成一个加权平均值(weighted average value)。我们计算查询矩阵(query)和键矩阵(key)之间的点积,最后通过 softmax 对权重进行归一化处理。多头注意力机制(Multi-head attention)指的是并行执行多次缩放点积注意力的计算,并将结果串联成一个向量。
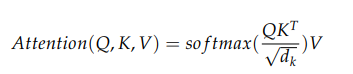
缩放点积注意力(以及编码器的所有层)的优点在于,它可以并行处理语料库中的所有tokens,不需要像 Word2Vec 那样等待一个token处理完成才能处理下一个token,因此无论语料词汇表有多大,输入步骤的数量都是一样的。
解码器部分与编码器略有不同。首先便是输入数据集不同:在Transformer论文中,它(译者注:此处应当指解码器的输入数据集)使用是目标语言的数据集。例如,如果我们想要将英文翻译成意大利语,就需要在意大利语语料库上进行训练。否则,我们执行的所有操作都相同:创建索引嵌入(indexed embeddings),然后将其转换为位置嵌入(positional embeddings)。再然后,我们将目标文本的位置嵌入送入到一个包含三个部分的层中:带有掩码的多头注意力机制、多头注意力机制和前馈神经网络。带掩码的多头自注意力机制与编码器中的自注意力机制基本相同,不过多了一部分:由于解码器的输入词汇是我们需要的 “答案”,即翻译后的文本,因此在这一步中引入的掩码矩阵(mask matrix)起到了过滤器的作用,可以防止注意力头(attention head)查看未来的tokens。
来自带有掩码的多头注意力层(the masked multi-head self attention layer)的输出被传递到编码器-解码器-注意力部分(encoder-decoder attention portion),该部分接受来自最初六个编码器层的最终输入作为键矩阵(key)和值矩阵(value),并将前一个解码器层的输入作为查询矩阵(query),然后执行缩放点积(scaled dot-product)。最后,将每个输出馈送到前馈层(feed forward layer),生成最终的嵌入。
获得每个token的隐藏层状态(hidden state)后,就可以添加任务头(task head)了。对于我们正在处理的任务,即翻译任务,任务头的作用是预测下一个单词应该是什么。在这一过程的每个步骤中,解码器都会查看之前的步骤,并根据这些步骤生成一个完整的句子[13]。最后,我们就能得到预测的单词,就像在Word2Vec中一样。
Transformer之所以具有革命性意义,原因有很多,因为其解决了人们一直在努力解决的几个问题:
- 并行化(Parallelization) - 模型中的每一步都可以并行处理,这意味着我们不需要等待知道一个单词的位置嵌入(positional embedding)后才能处理另一个单词。因为每个嵌入查找矩阵(embedding lookup matrix)都将注意力集中在一个特定的单词上,并带有一个与该单词相关的所有其他单词的查找表,每个单词的每个矩阵都包含整个输入文本的上下文窗口。
- 梯度消失(Vanishing gradients) - 以往的模型(如RNN)可能会出现梯度消失或梯度爆炸的问题,这意味着模型在完全训练好之前就达到了局部最小值,从而使得捕捉长期依赖问题(long-term dependencies)变得具有挑战性。Transformer允许序列中任意两个位置之间的直接连接,从而缓解了这一问题,使信息在前向和反向传播过程中都能更有效地流动。
- 自注意力机制 - 注意力机制允许我们学习整个文本的上下文,而不仅仅是一个2或3个单词的滑动上下文窗口。这使我们能够学习不同上下文中的不同单词,并更准确地预测答案。
03 BERT
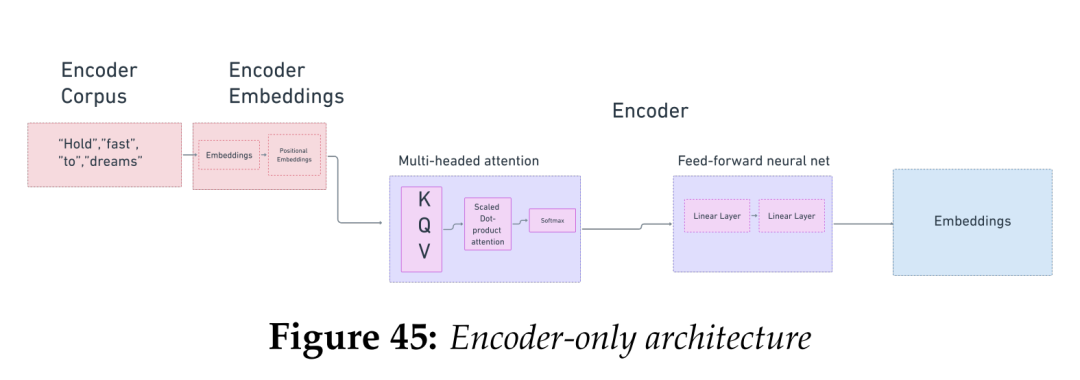
图7 Encoder-only架构
在《Attention is All you Need》获得巨大成功之后,各种各样的Transformer架构应运而生,这种架构的研究和实现在深度学习领域呈现爆炸式增长。下一个被认为是重大进步的Transformer架构是Google于2018年发布的BERT。BERT 是 Bi-Directional Encoder 的缩写,发布于 2018 年[14],其基于Google的一篇论文,是解决常见的自然语言处理任务(如情感分析、问答和文本摘要)的一种方法。BERT是一种Transformer模型,也基于注意力机制,但其架构仅包括编码器部分。BERT最突出的应用是在谷歌搜索中,使得Google搜索能够更准确地理解用户的查询意图,从而提供更有用的搜索结果。在2019年Google发布的一篇博客文章中,强调了已将BERT添加到搜索排名算法中,Google特别讨论了将语境(亦常译作“上下文”)添加到查询中以替代基于关键字的方法的原因。
BERT是一种掩码语言模型(masked language model)。我们在实现 Word2Vec 时,就是通过删除单词和建立上下文窗口来实现掩码的。当我们使用Word2Vec创建表示(representations)时,我们只关注向前移动的滑动窗口。BERT中的“B”代表双向,这说明它通过缩放点积注意力(scaled dot-product attention)双向关注单词。BERT有12个Transformer层。它首先使用WordPiece算法将单词分割为子单词,并将其转换为token。训练 BERT 的目的是让它能够根据上下文预测token。
BERT的输出是单词及其上下文的隐层表示(latent representations) —— 一组嵌入。BERT本质上是一个大规模并行的Word2Vec,可以记住更长的上下文窗口。 BERT十分灵活性,可以用于多种任务,从语言翻译到文本摘要,再到搜索引擎的自动填充(autocomplete)。由于它没有解码器组件,因此无法生成文本,这就为 GPT 模型接替 BERT 的工作铺平了道路。
04 GPT
在BERT开发的同时,OpenAI也在开发另一种Transformer架构——GPT系列。GPT与BERT的不同之处在于,其不仅能对嵌入文本进行编码,也能对其进行解码,因此可以用于概率推理(probabilistic inference)。
最初的GPT模型是基于Book Corpus的数据训练完成的,是一个12层、12头的Transformer,只有解码器部分。后续版本在此基础上不断进行改进,试图提高上下文理解能力。最大的突破出现在GPT-4中,它是通过基于人类反馈的强化学习(reinforcement learning from Human Feedback)进行训练的,这一训练特性使它能够从文本中做出推理,令其结果感觉上更接近人类所写的内容。
现在,我们已经到达了使用嵌入技术的最前沿。随着生成式方法(generative methods)和基于人类反馈的强化学习方法(Reinforcement Learning with Human Feedback)的兴起,例如OpenAI的ChatGPT以及新兴的开源模型Llama、Alpaca等,本文中所述的任何内容在发表时都已经过时了。
Embedding*技术在生产环境中的应用效果到底如何?下一期,我们将分享Embedding技术的多个应用案例,敬请期待。
END
参考资料
[1]David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors. nature, 323(6088):533–536, 1986.
[2]Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998
[3]Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bern-stein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115:211–252, 2015.
[4]Yann LeCun, Yoshua Bengio, Geoffrey Hinton, et al. Deep learning. nature, 521 (7553), 436-444. Google Scholar Google Scholar Cross Ref Cross Ref, page 25, 2015.
[5]Bogdan Oancea, Tudorel Andrei, and Raluca Mariana Dragoescu. Gpgpu computing. arXiv preprint arXiv:1408.6923, 2014.
[6]Yingnan Cong, Yao-ban Chan, and Mark A Ragan. A novel alignment-free method for detection of lateral genetic transfer based on tf-idf. Scientifi reports, 6(1):1–13, 2016.
[7]Christopher J Shallue, Jaehoon Lee, Joseph Antognini, Jascha Sohl-Dickstein, Roy Frostig, and George E Dahl. Measuring the effects of data parallelism on neural network training. arXiv preprint arXiv:1811.03600, 2018.
[8]Giovanni Di Gennaro, Amedeo Buonanno, and Francesco AN Palmieri. Considerations about learning word2vec. The Journal of Supercomputing, pages 1–16, 2021.
[9]Andrej Karpathy. The unreasonable effectiveness of recurrent neural networks, May 2015. URL https://karpathy.github.io/2015/05/21/rnn-effectiveness/.
[10]http://nlp.seas.harvard.edu/2018/04/03/attention.html
[11]Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
[12]https://lilianweng.github.io/posts/2018-06-24-attention/
[13]Alexander M Rush. The annotated transformer. In Proceedings of workshop for NLP open source software (NLP-OSS), pages 52–60, 2018.
[14]Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://vickiboykis.com/what_are_embeddings/index.html
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~




![[计算机入门] Windows附件程序介绍(轻松使用)](https://img-blog.csdnimg.cn/8167752197ea464795d584a2028690aa.png)