NoSQL数据库原理与应用综合项目——Neo4j篇
文章目录
- NoSQL数据库原理与应用综合项目——Neo4j篇
- 0、 写在前面
- 1、本地数据或HDFS数据导入到Neo4j
- 2、Neo4j数据库表操作
- 2.1 使用Python连接Neo4j
- 2.2 查询数据
- 2.3 插入数据
- 2.4 修改数据
- 2.5 删除数据
- 3、Windows远程连接Neo4j(Linux)
- 4、数据及源代码
- 5、总结

0、 写在前面
- Windos版本:
Windows10 - Linux版本:
Ubuntu Kylin 16.04 - JDK版本:
Java8 - Hadoop版本:
Hadoop-2.7.1 - HBase版本:
HBase-1.1.5 - Zookeepr版本:使用HBase自带的ZK
- Redis版本:
Redis-3.2.7 - MongoDB版本:
MongoDB-3.2.7 - Neo4j版本:
Neo4j-3.5.12 Community - IDE:
IDEA 2020.2.3 - IDE:
Pycharm 2021.1.3
节点与节点的关系
- author-[own]-name
- name-[has]-dicount
- name-[belongto]-type
分别代表:
- 作者拥有(own)书籍;
- 书籍具有(has)折扣;
- 书籍属于(belongto)某种类型
1、本地数据或HDFS数据导入到Neo4j
注:选取前200条数据
- 代码:
为了更好地展示节点与节点之间的关系,特意将每条数据拆分为两个节点存储。前5个字段作为标签books1的节点,后5个字段作为标签books2的另一节点。
USING PERIODIC COMMIT 200 LOAD CSV FROM 'file:///tb_books.csv' AS line
merge (b1:books1{id:line[0],type:line[1],name:line[2],author:line[3],
price:line[4]})
merge (b2:books2{id:line[0],discount:line[5],pub_time:line[6], pricing:line[7],
publisher:line[8],crawler_time:line[9]})
批量数据导入Neo4j可以参考以下链接:
http://t.csdn.cn/ORTtv
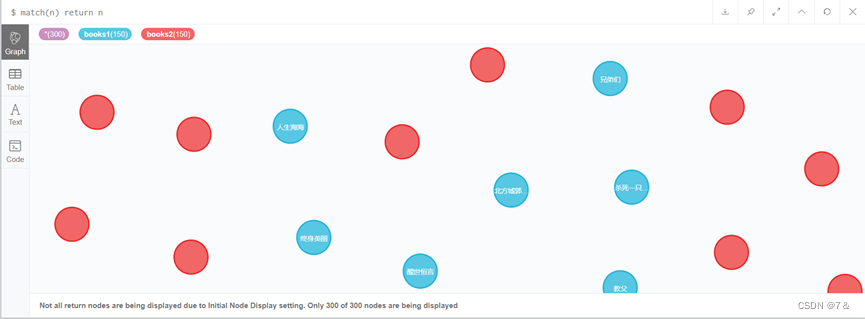
- 运行成功图示:
顺利插入200条数据,一共400个节点
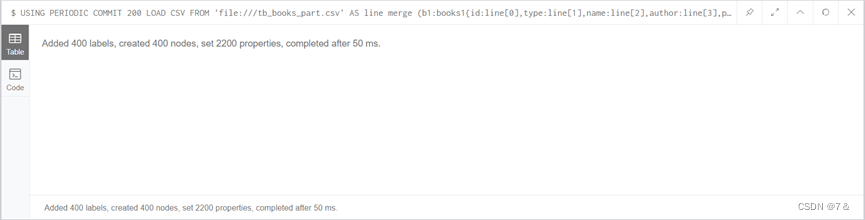
- 结果图:
可以看到book1和books2标签拥有相同量的数据
2、Neo4j数据库表操作
2.1 使用Python连接Neo4j
- 代码:
连接Neo4j数据库输入地址、用户名、密码
url = 'bolt://10.125.0.15:7687'
usr = 'neo4j'
key = '123456'
graph = Graph(url, auth=(usr, key))
matcher = NodeMatcher(graph) # 创建节点匹配器
2.2 查询数据
- 根据ID查找节点
将参数label和ID传入queryById()
# 1. 查找节点id/根据id查找节点
def queryById(label, ID) :
print('所有的节点类型为:', graph.schema.node_labels) # 查看节点类型
res = list(matcher.match(label, id = ID))
print(res)

- 按照属性排序查找Top5节点
将参数label和fieldName传入querySortingByField(),其中使用辅助函数来限制条件
def querySortingByField(label, fieldName) :
pre = list(matcher.match(label))
if pre.__eq__(list()):
print('The label what you query is not exists!')
else :
res = querySortingByFieldHelper(label, fieldName)
if res is not None :
print(res)
辅助函数querySortingByFieldHelper()
def querySortingByFieldHelper(label, fieldName) :
flag = True
if fieldName.__eq__('id'):
res = list(matcher.match(label).order_by('_.id').limit(5))
elif fieldName.__eq__('type'):
res = list(matcher.match(label).order_by('_.type').limit(5))
elif fieldName.__eq__('name'):
res = list(matcher.match(label).order_by('_.name').limit(5))
elif fieldName.__eq__('author'):
res = list(matcher.match(label).order_by('_.author').limit(5))
elif fieldName.__eq__('price'):
res = list(matcher.match(label).order_by('_.price').limit(5))
elif fieldName.__eq__('discount'):
res = list(matcher.match(label).order_by('_.discount').limit(5))
elif fieldName.__eq__('pub_time'):
res = list(matcher.match(label).order_by('_.pub_time').limit(5))
elif fieldName.__eq__('pricing'):
res = list(matcher.match(label).order_by('_.pricing').limit(5))
elif fieldName.__eq__('publisher'):
res = list(matcher.match(label).order_by('_.publisher').limit(5))
elif fieldName.__eq__('crawler_time'):
res = list(matcher.match(label).order_by('_.crawler_time').limit(5))
else:
flag = False
if flag :
return res
else :
print('不存在这个属性!')

- 查找关系
要查询的关系名rsName作为参数传入queryRelationship()
# TODO 查关系,找到所有关系
def queryRelationship(rsName) :
all_r_types = list(graph.schema.relationship_types)
all = list(graph.match(nodes=None, r_type=None, limit=None))
flag = True
if rsName.__eq__('own') :
print('你所查询的关系【' + rsName + '】结果为:')
one = list(graph.match(nodes=None, r_type = 'own'))
elif rsName.__eq__('has') :
print('你所查询的关系【' + rsName + '】结果为:')
one = list(graph.match(nodes=None, r_type = 'has'))
elif rsName.__eq__('belongto') :
print('你所查询的关系【' + rsName + '】结果为:')
one = list(graph.match(nodes=None, r_type = 'belongto'))
else :
flag = False
print('你所查询的关系【' + rsName + '】不存在!')
if flag :
print(one)

2.3 插入数据
- 新增节点
要插入的节点信息以数组的形式作为参数传入addNode()
Note:新增的数据依旧是拆分为2部分,创建两个节点
## TODO 增加节点
def addNode(arr) :
# TODO 创建节点
node1 = Node(arr[10], id = arr[0], type = arr[1], name = arr[2],
author = arr[3], price = arr[4])
node2 = Node(arr[10], id = arr[0], discount=arr[5],pub_time=arr[6], pricing=arr[7],
publisher=arr[8],crawler_time=arr[9])
graph.create(node1)
graph.create(node2)
print('Add node successfully!')

- 为节点增加关系
要插入的节点信息以数组的形式作为参数传入addNode()
Note:此处为节点间新增关系,关系名称设置为节点的ID号+“_”+关系名(own、has、belongto)
## TODO 增加关系
def addRelationShip(label1, label2, ID) :
# TODO 创建关系(已有节点)
matchList1 = list(matcher.match(label1, id = ID))
matchList2 = list(matcher.match(label2, id = ID))
rLabel1 = matchList1[0]['id'] + "_own"
fromNode1 = Node(rLabel1, author = matchList1[0]['author'])
toNode1 = Node(rLabel1, name = matchList1[0]['name'])
own_relation = Relationship(fromNode1, "own", toNode1)
rLabel2 = matchList1[0]['id'] + "_has"
fromNode2 = Node(rLabel2, name=matchList1[0]['name'])
if label2.__contains__('insert') :
toNode2 = Node(rLabel2, discount=matchList2[1]['discount'])
else :
toNode2 = Node(rLabel2, discount=matchList2[0]['discount'])
has_relation = Relationship(fromNode2, "has", toNode2)
rLabel3 = matchList1[0]['id'] + "_belongto"
fromNode3 = Node(rLabel3, name=matchList1[0]['name'])
toNode3 = Node(rLabel3, type=matchList1[0]['type'])
belongto_relation = Relationship(fromNode3, "belongto", toNode3)
# 将创建关系传递到图上
total_rs = own_relation | has_relation | belongto_relation
graph.create(total_rs)
print("Add relation{own,has,belongto} successfully!")

2.4 修改数据
- 修改指定属性name值
要修改的条件label, ID, fieldName, newValue作为参数传入updateFieldVal()
Note:此处使用CQL语句来实现修改属性值,graph.run(uCQL)执行修改操作
def updateFieldVal(label, ID, fieldName, newValue):
# TODO 修改属性值
uCQL = 'match(b:' + label + ') where b.id = ' + "\'" + ID + "\'" + ' set b.' + fieldName + '=' + \
"\'" + newValue + "\'" + ' return b'
print(uCQL)
try :
graph.run(uCQL)
print('update sucessfully!')
except Exception :
print('Happen Exception!')


2.5 删除数据
- 根据ID删除一个节点
要删除的条件label,id值作为参数传入deleteOneNodeById()
# 2. 根据ID删除一个节点(不能删除含有关系的节点)
def deleteOneNodeById(label, fieldValue) :
node = matcher.match(label).where(id = fieldValue).first() # 先匹配,叫fieldValue的第一个结点
graph.delete(node)
print('标签为' + label + ', id为' + fieldValue + '的一个节点成功删除!')

- 删除指定关系
要删除的条件label和rsName作为参数传入deleteRelationship()
Note:此处也是使用CQL语句实现的,graph.run(deleteCQL1)执行删除关系的操作
# 3. 删除关系
def deleteRelationship(label, rsName) :
deleteCQL1 = 'match(n:' + "`" + label + "`" + ')-[r:' + rsName + ']-() delete r'
print(deleteCQL1)
try :
graph.run(deleteCQL1)
print('delete label[' + label + '],' + 'relationship[' + rsName + '] successufully!')
except Exception:
print('Happen Exception')
删除前数据:

删除后数据:

3、Windows远程连接Neo4j(Linux)
Neo4j的相关配置文件需要提前设置正确,最主要的就是ip地址,同时要注意防火墙是否关闭。
4、数据及源代码
-
Github
-
Gitee
5、总结
由于数据量有1万多条,将数据一次性全部导入Neo4j速度较慢,所以只是抽取200条数据进行导入,加速导入的速度。
结束!