参考视频:https://www.youtube.com/watch?v=m9fH9OWn8YM
YOLO官方网站:GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
在本地的pycharm上面建立一个项目

使用scp把代码传递到远程服务器
scp -r /Users/xxx/PycharmProjects/Yolov8-second/* xxx@xxx:/home/ps/Code/Python/YoloV8
有个问题是:如果我们直接这样传过去,那我们这个地方是空的

如果不是空的,我们直接给原来的删掉,这个时候,pycharm会自动提示让你添加一个python解释题,然后添加即可。
如果不这样做的话,好多package都会报红
使用romote development进行远程开发
什么是远程开发?就是把远程服务器上面的项目,给直接拿到本地的pycharm上面进行开发,这样可以使用pycharm的debug等各种方便。

输入一下服务器的账号密码,选中要远程开发的项目文件夹

安装Yolov8
如果需要不修改Yolov8的源代码,直接pip install安装即可,参考官方网站安装即可
在main.py中写入如下代码
from ultralytics import YOLO
# Create a new YOLO model from scratch
# model = YOLO('yolov8n.yaml')
# Load a pretrained YOLO model (recommended for training)
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
results = model.train(data="config.yaml", epochs=500) # train the modelmodel = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
这个是我们直接使用一个yolo官方训练好的模型,在此基础上继续训练,这样效果会比较好
results = model.train(data="config.yaml", epochs=500) # train the model
这个是用我们自己的config.yaml,里面有数据集,自己训练一个模型,这个模型,可以按照自己的想法,只识别指定的几种物体,用一定量的数据集
path: /Users/roy/PycharmProjects/YoloV8/clean_data
train: images/train
val: images/val
names:
0: Person
1: CoffeeCup
2: Book
3: ComputerMousepath必须使用绝对路径,train和val也必须使用我上面的格式,names也必须按照上面的格式,一个空格都不能错位,names就是我只识别这四个物体,这个地方的Person,CoffeeCup,Book,这些单词都是我们下载的数据集中的数据
下载数据集
先在项目根目录下面创建一个datasets文件夹,创建一个raw_data文件夹,然后再根目录下来再创建一个download_raw_dataset.py
import fiftyone.zoo
classes = ["Coffee cup", "Book", "Computer mouse", "Person"]
for i in range(len(classes)):
item = classes[i]
print(item)
dataset = fiftyone.zoo.load_zoo_dataset(
"open-images-v7",
splits=["train", "val", "test"],
label_types=["detections"],
classes=[item],
max_samples=1000,
dataset_dir="./datasets/raw_data",
)
for i in range(len(classes)):
item = classes[i]
print(item)
dataset = fiftyone.zoo.load_zoo_dataset(
"open-images-v7",
splits=["val"],
label_types=["detections"],
classes=[item],
max_samples=100,
dataset_dir="./datasets/raw_data",
)
这是下载完成之后的数据集的结构

_path结尾的变量,可以直接使用鼠标定位到文件夹的位置
数据清洗
在datasets文件下面,创建一个clean_data文件夹,里面存储清洗后,可以让Yolov8使用的数据
detections.csv不是干净的数据,我们需要在创建一个clean.csv文件
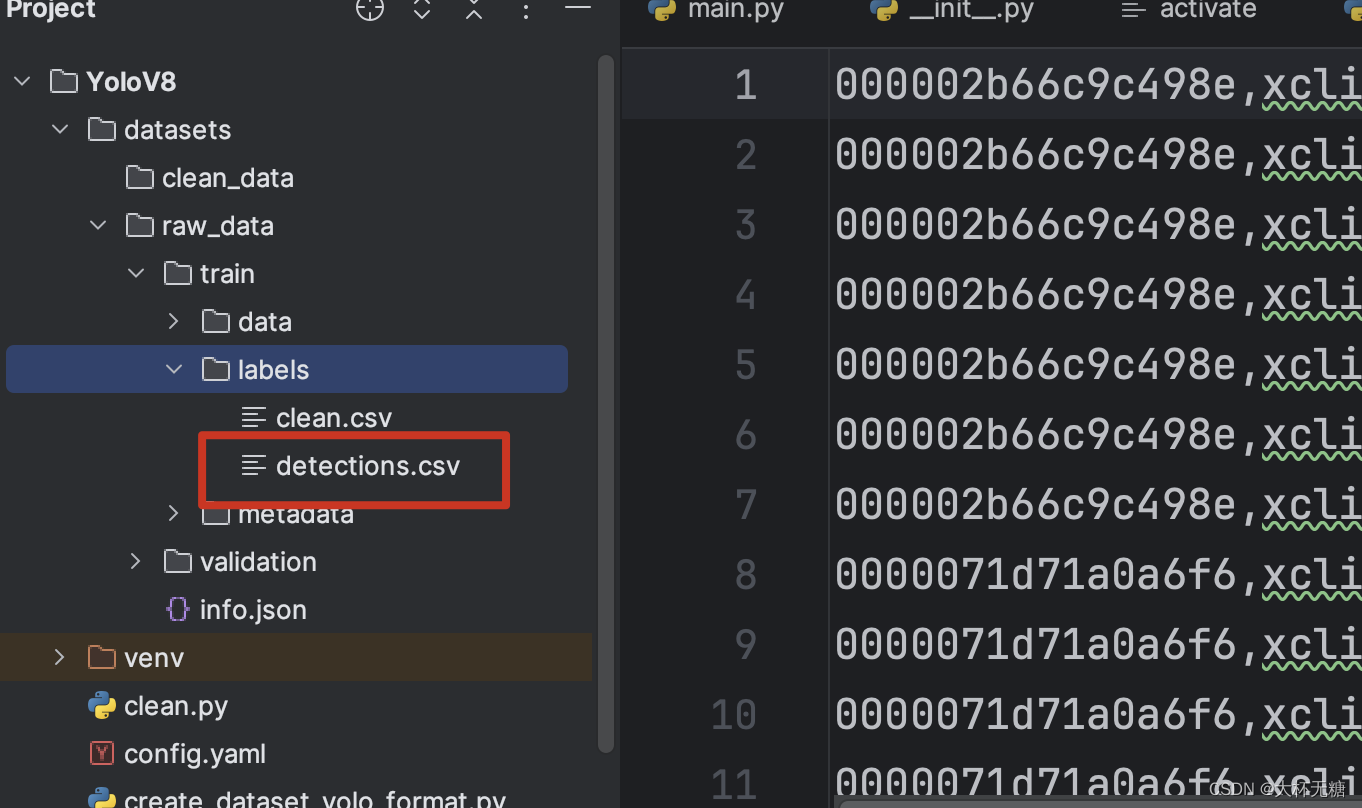
在根目录下面创建一个clean.py
import csv
from tqdm import tqdm
import os
# csv_file_path = os.path.join('.', 'datasets', 'raw_data', 'train', 'labels', 'detections.csv')
csv_file_path = './datasets/raw_data/train/labels/detections.csv'
# 图像文件夹路径
# images_file_path = os.path.join('.', 'train', "data")
images_file_path = './datasets/raw_data/train/data'
images_name = os.listdir(images_file_path)
images_name = [x.split(".")[0] for x in images_name]
# 类别
LabelName = ['/m/01g317', '/m/02p5f1q', '/m/0bt_c3', '/m/020lf']
# 保存标注文件路径
# data_annotation_csv = os.path.join('.', 'train', 'labels', 'clean.csv')
data_annotation_csv_path = './datasets/raw_data/train/labels/clean.csv'
with open(csv_file_path, 'r', encoding='utf-8') as f:
with open(data_annotation_csv_path, "w", encoding='utf-8') as ff:
csv_f = csv.reader(f)
bar = tqdm(csv_f)
for row in bar:
if row[0] in images_name and row[2] in LabelName:
for index in range(len(row)):
ff.write(row[index])
if (index != (len(row) - 1)):
ff.write(",")
ff.write("\n")
现在clean.csv就是干净的数据,我们还需要再进行一步操作,创建Yolo需要的格式
在根目录下面创建文件create_dataset_yolo_format.py
import os
import shutil
DATA_OUT_DIR = os.path.abspath(os.path.join('datasets/clean_data'))
for set_ in ['train', 'val', 'test']:
for dir_ in [os.path.join(DATA_OUT_DIR, set_),
os.path.join(DATA_OUT_DIR, set_, 'imgs'),
os.path.join(DATA_OUT_DIR, set_, 'labels')]:
if os.path.exists(dir_):
shutil.rmtree(dir_)
os.makedirs(dir_, exist_ok=True)
LabelName = ['/m/01g317', '/m/02p5f1q', '/m/0bt_c3', '/m/020lf']
# 使用enumerate函数创建键值对,键是元素,值是索引
alpaca_id_dict = {alpaca_id: index for index, alpaca_id in enumerate(LabelName)}
print(alpaca_id_dict)
train_bboxes_filename = os.path.join('datasets/raw_data/train/labels', 'clean.csv')
# validation_bboxes_filename = os.path.join('datasets/raw_data/validation/labels', 'clean.csv')
# test_bboxes_filename = os.path.join('datasets/raw_data/test/labels', 'clean.csv')
# for j, filename in enumerate([train_bboxes_filename, validation_bboxes_filename, test_bboxes_filename]):
for j, filename in enumerate([train_bboxes_filename]):
set_ = ['train', 'val', 'test'][j]
print(filename)
with open(filename, 'r') as f:
line = f.readline()
while len(line) != 0:
id, _, class_name, _, x1, x2, y1, y2, _, _, _, _, _ = line.split(',')[:13]
if class_name in LabelName:
if not os.path.exists(os.path.join(DATA_OUT_DIR, set_, 'imgs', '{}.jpg'.format(id))):
shutil.copy(os.path.join("datasets/raw_data", set_, "data", '{}.jpg'.format(id)),
os.path.join(DATA_OUT_DIR, set_, 'imgs', '{}.jpg'.format(id)))
with open(os.path.join(DATA_OUT_DIR, set_, 'labels', '{}.txt'.format(id)), 'a') as f_ann:
# class_id, xc, yx, w, h
x1, x2, y1, y2 = [float(j) for j in [x1, x2, y1, y2]]
xc = (x1 + x2) / 2
yc = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
f_ann.write('{} {} {} {} {}\n'.format(alpaca_id_dict[class_name], xc, yc, w, h))
print(alpaca_id_dict[class_name])
f_ann.close()
line = f.readline()
执行之后,数据清洗工作就完成了
下来就是开始训练了,执行main方法,训练500轮(epoch),然后模型会保存在根目录下面的runs