1.简介
组织机构:Meta(Facebook)
代码仓:GitHub - facebookresearch/llama: Inference code for LLaMA models
模型:llama-2-7b、llama-2-7b-chat
下载:使用download.sh下载
硬件环境:Jetson AGX Orin
2.代码和模型下载
cd /home1/zhanghui
git clone https://github.com/facebookresearch/llama
打开LIama2模型官网:GitHub - facebookresearch/llama: Inference code for LLaMA models

点击 request a new download link
再想想办法:
填好信息(记住不能选择China),点击Accept

你会在邮箱里面收到一封邮件:

这个先放到一边,待用。
cd /home1/zhanghui
cd llama
./download.sh
在提示下输入邮箱提供的URL和模型类型(先选择7B吧),系统会开始下载模型文件:
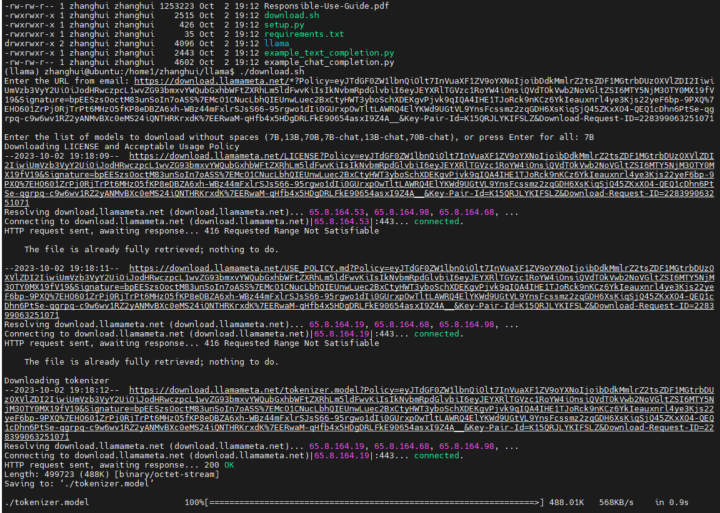
耐心等待,文件会下载到 当前目录和 ./llama-2-7b目录下:
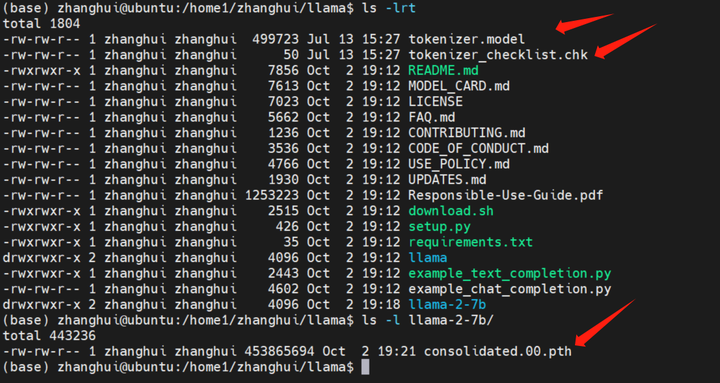

这个下载代码写得不错。它卡住了会重试,还能断点续传。不愧是大公司的作品。

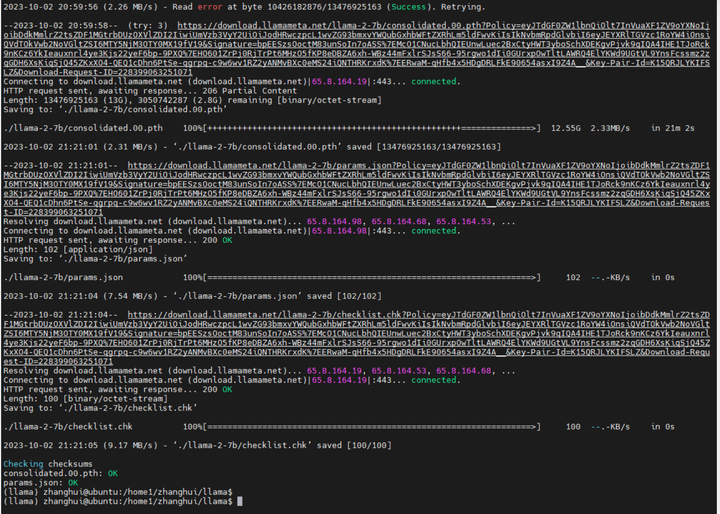

下载完毕。
3.安装依赖
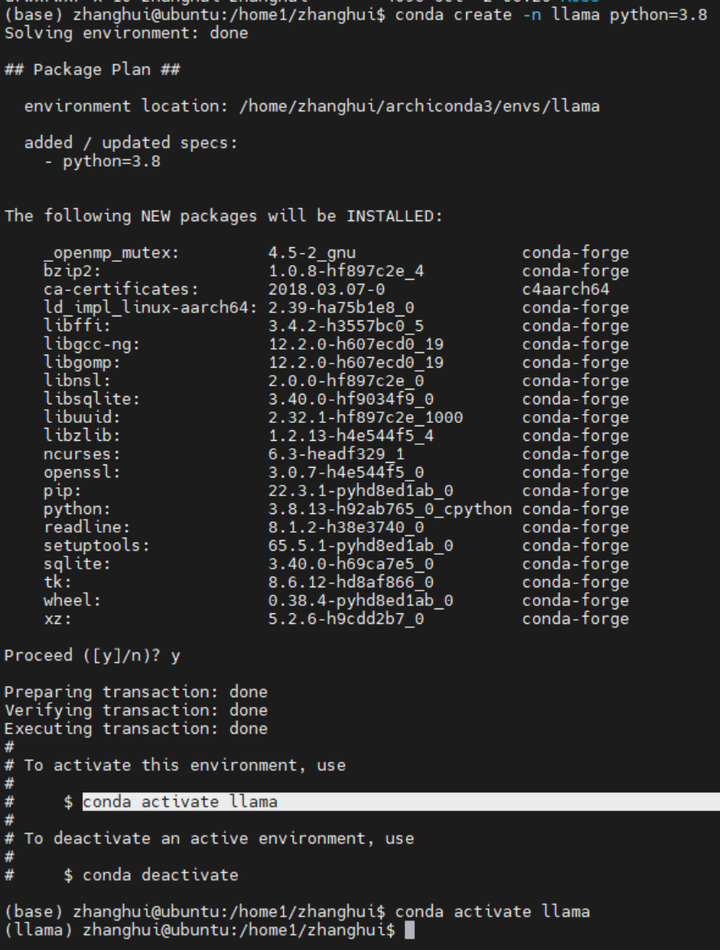
打开终端,创建llama conda环境。
conda create -n llama python=3.8
conda activate llama
cd /home1/zhanghui
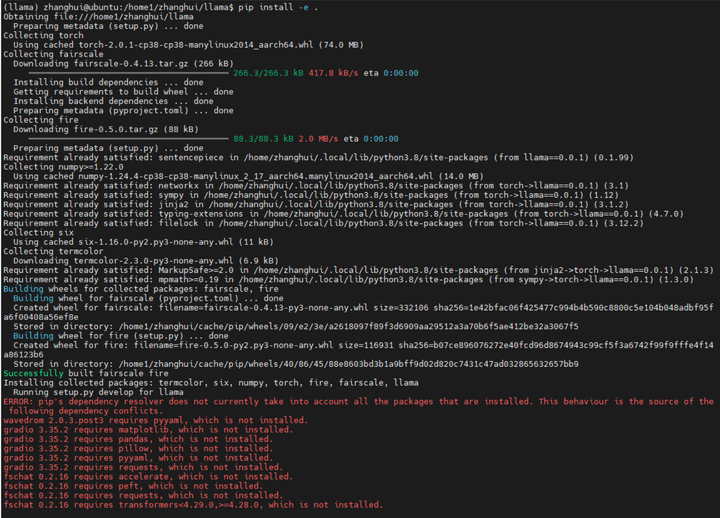
安装:
pip install -e .

注意一开始它打算装torch 2.0,而这个我们后面需要将其换成jetson专用版。

cd ..
pip install ./torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl

cd llama
torchrun --nproc_per_node 1 example_text_completion.py --ckpt_dir llama-2-7b/ --tokenizer_path tokenizer.model --max_seq_len 128 --max_batch_size 4
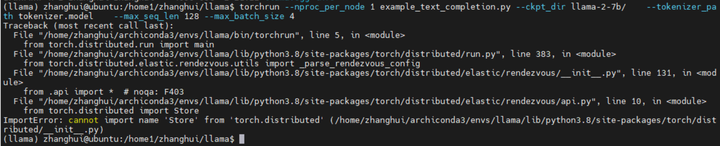
查看 https://forums.developer.nvidia.com/t/importerror-cannot-import-name-store-from-torch-distributed/262235

这个貌似要让用户源码编译后自制jetson安装包。感觉难度比较大。
换成torch2.1试试呢?
pip install torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
cd llama
torchrun --nproc_per_node 1 example_text_completion.py --ckpt_dir llama-2-7b/ --tokenizer_path tokenizer.model --max_seq_len 128 --max_batch_size 4
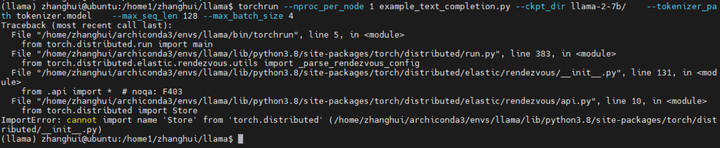
结果好像是一样的。
那么在Jetson AGX Orin上怎么编译torch呢?
打开 https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048
找到 Build from source:
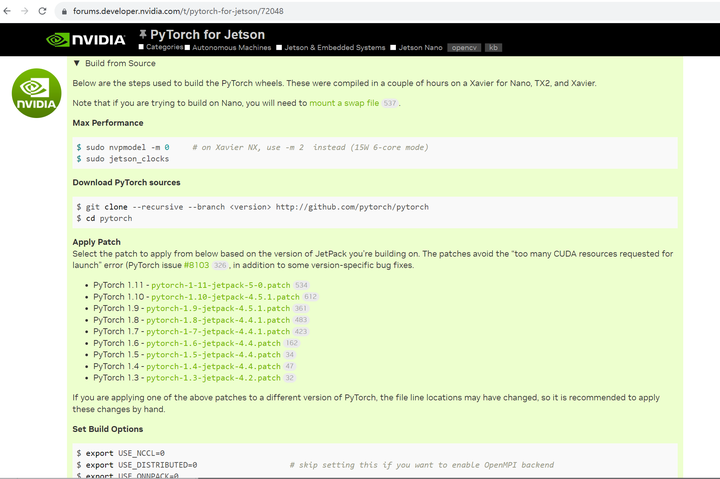

这是一个”危险“的工作。。
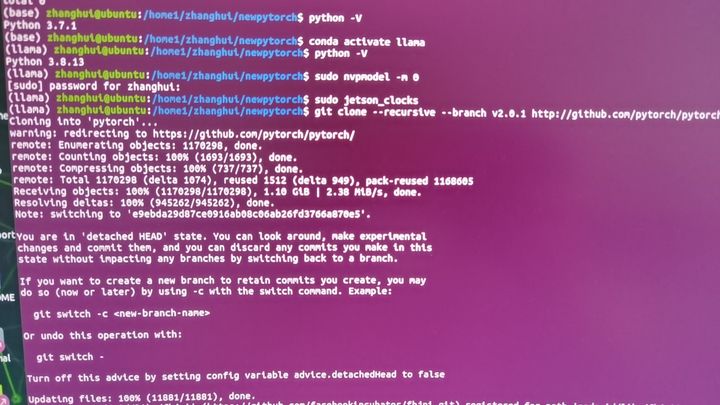
cd /home1/zhanghui
mkdir newpytorch
cd newpytorch
conda activate llama
sudo nvpmodel -m 0
sudo jetson_clocks
git clone --recursive --branch v2.0.1 http://github.com/pytorch/pytorch
export USE_NCCL=0
export USE_DISTRIBUTED=1 # skip setting this if you want to enable OpenMPI backend
export USE_QNNPACK=0
export USE_PYTORCH_QNNPACK=0
export TORCH_CUDA_ARCH_LIST="7.2;8.7"
export PYTORCH_BUILD_VERSION=2.0.1
export PYTORCH_BUILD_NUMBER=1

cd pytorch
pip install -r requirements.txt
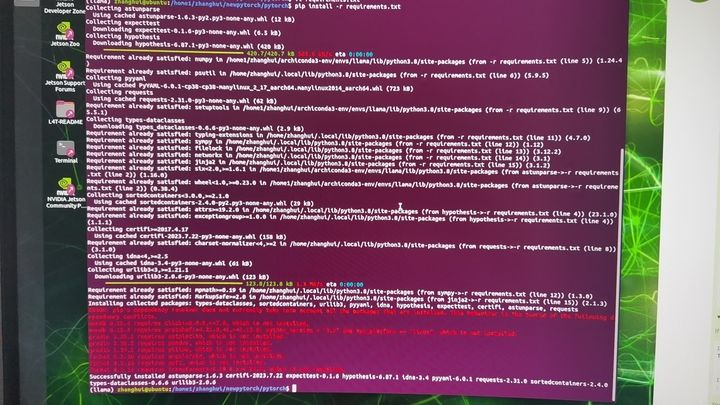
pip install scikit-build
pip install ninja

python3 setup.py bdist_wheel

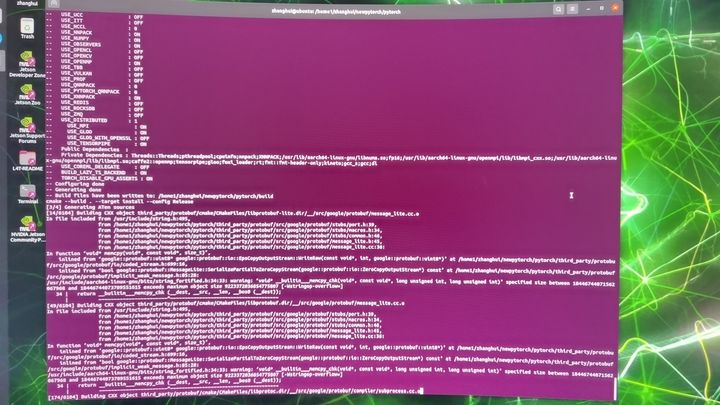

耐心等待wheel制作完成。。。
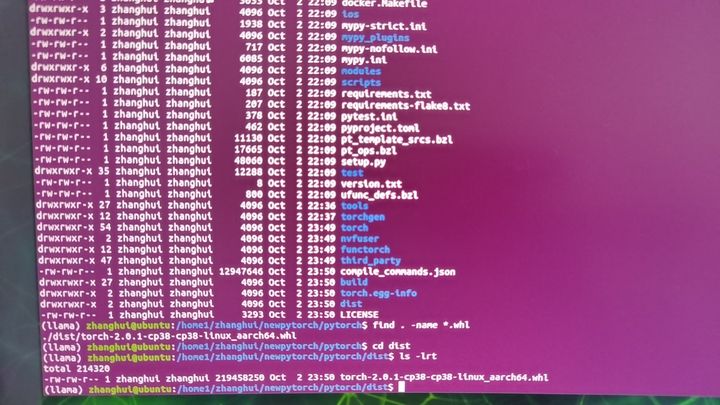
编译成功,编译好的whl文件在dist目录下:

我们来安装:
cd dist
pip install ./torch-2.0.1-cp38-cp38-linux_aarch64.whl

cd /home1/zhanghui
cd llama
torchrun --nproc_per_node 1 example_text_completion.py --ckpt_dir llama-2-7b/ --tokenizer_path tokenizer.model --max_seq_len 128 --max_batch_size 4
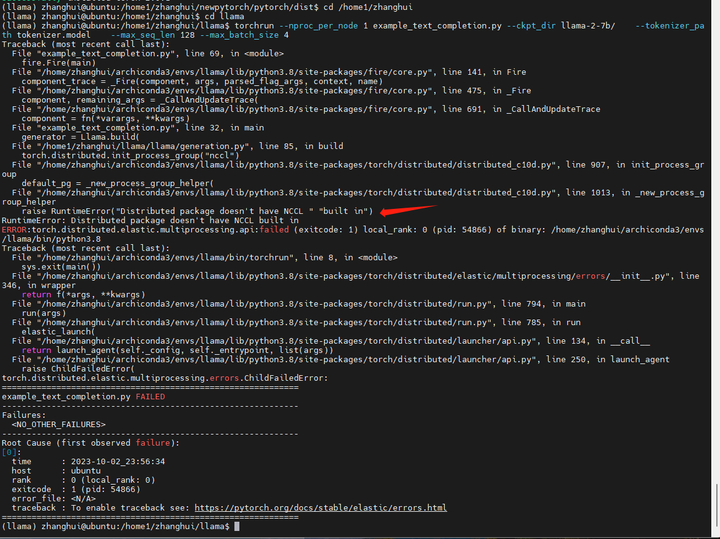
回头看:
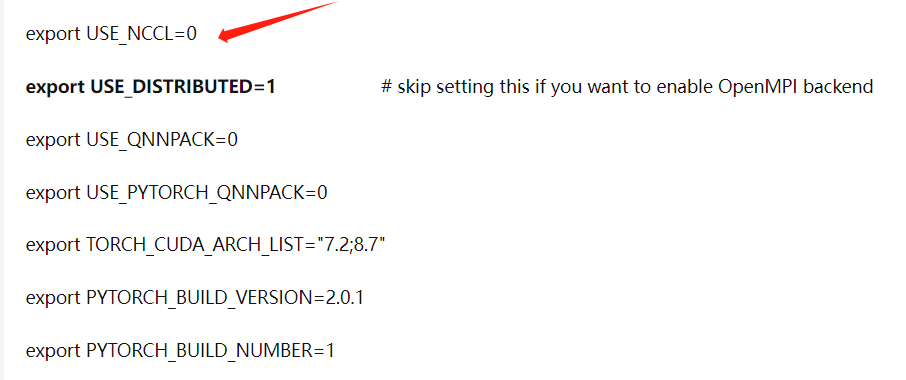
唉,原来还有一个参数没改:
export USE_NCCL=0
(不知道其他两个参数要不要改。。。)
备份一下,清除build目录,重新编译。
cd /home1/zhanghui
cd newpytorch/pytorch
cd build
rm -rf *
cd ..
export USE_NCCL=1
export USE_DISTRIBUTED=1 # skip setting this if you want to enable OpenMPI backend
export USE_QNNPACK=0
export USE_PYTORCH_QNNPACK=0
export TORCH_CUDA_ARCH_LIST="7.2;8.7"
export PYTORCH_BUILD_VERSION=2.0.1
export PYTORCH_BUILD_NUMBER=1
python3 setup.py bdist_wheel

仍然耐心等待编译成功。


cd dist
pip install ./torch-2.0.1-cp38-cp38-linux_aarch64.whl --force-reinstall

4.部署验证
cd /home1/zhanghui
cd llama
torchrun --nproc_per_node 1 example_text_completion.py --ckpt_dir llama-2-7b/ --tokenizer_path tokenizer.model --max_seq_len 128 --max_batch_size 4

运行结果如下:
(llama) zhanghui@ubuntu:/home1/zhanghui/newpytorch/pytorch/dist$ cd /home1/zhanghui
(llama) zhanghui@ubuntu:/home1/zhanghui$ cd llama
(llama) zhanghui@ubuntu:/home1/zhanghui/llama$ torchrun --nproc_per_node 1 example_text_completion.py --ckpt_dir llama-2-7b/ --tokenizer_path tokenizer.model --max_seq_len 128 --max_batch_size 4
> initializing model parallel with size 1
> initializing ddp with size 1
> initializing pipeline with size 1
Loaded in 30.33 seconds
I believe the meaning of life is
> to love.
I believe the meaning of life is to love. We were created to love and be loved. We were created to love God and to love our neighbor as ourselves. We were created to love our spouse, our children, our family, our friends, our community, and our world.
We
==================================
Simply put, the theory of relativity states that
> 1) the laws of physics are the same for all non-accelerating observers, and 2) the speed of light is the same for all observers, regardless of their relative motion or their gravitational potential.
The first statement is the most important. It is the basis for the second.
==================================
A brief message congratulating the team on the launch:
Hi everyone,
I just
> wanted to let you know that the team is pleased to announce the launch of the new site. We hope that you like the new design and that it makes it easier to find the information that you are looking for. Please take a few minutes to let us know what you think by taking our quick survey.
==================================
Translate English to French:
sea otter => loutre de mer
peppermint => menthe poivrée
plush girafe => girafe peluche
cheese =>
> fromage
grilled cheese => sandwich au fromage
giraffe => girafe
candy cane => canne à sucre
candy => sucre
peppermint candy => sucre à la menthe poivrée
pe
==================================
(llama) zhanghui@ubuntu:/home1/zhanghui/llama$example_text_completion.py 是在做一个文本补全的任务。
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
import fire
from llama import Llama
from typing import List
def main(
ckpt_dir: str,
tokenizer_path: str,
temperature: float = 0.6,
top_p: float = 0.9,
max_seq_len: int = 128,
max_gen_len: int = 64,
max_batch_size: int = 4,
):
"""
Entry point of the program for generating text using a pretrained model.
Args:
ckpt_dir (str): The directory containing checkpoint files for the pretrained model.
tokenizer_path (str): The path to the tokenizer model used for text encoding/decoding.
temperature (float, optional): The temperature value for controlling randomness in generation.
Defaults to 0.6.
top_p (float, optional): The top-p sampling parameter for controlling diversity in generation.
Defaults to 0.9.
max_seq_len (int, optional): The maximum sequence length for input prompts. Defaults to 128.
max_gen_len (int, optional): The maximum length of generated sequences. Defaults to 64.
max_batch_size (int, optional): The maximum batch size for generating sequences. Defaults to 4.
"""
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
prompts: List[str] = [
# For these prompts, the expected answer is the natural continuation of the prompt
"I believe the meaning of life is",
"Simply put, the theory of relativity states that ",
"""A brief message congratulating the team on the launch:
Hi everyone,
I just """,
# Few shot prompt (providing a few examples before asking model to complete more);
"""Translate English to French:
sea otter => loutre de mer
peppermint => menthe poivrée
plush girafe => girafe peluche
cheese =>""",
]
results = generator.text_completion(
prompts,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)
for prompt, result in zip(prompts, results):
print(prompt)
print(f"> {result['generation']}")
print("\n==================================\n")
if __name__ == "__main__":
fire.Fire(main)其中,prompt列表如下:
# For these prompts, the expected answer is the natural continuation of the prompt
"I believe the meaning of life is",
"Simply put, the theory of relativity states that ",
"""A brief message congratulating the team on the launch:
Hi everyone,
I just """,
运行的结果如下:
I believe the meaning of life is to love. We were created to love and be loved. We were created to love God and to love our neighbor as ourselves. We were created to love our spouse, our children, our family, our friends, our community, and our world. We
Simply put, the theory of relativity states that > 1) the laws of physics are the same for all non-accelerating observers, and 2) the speed of light is the same for all observers, regardless of their relative motion or their gravitational potential. The first statement is the most important. It is the basis for the second.
Hi everyone, I just > wanted to let you know that the team is pleased to announce the launch of the new site. We hope that you like the new design and that it makes it easier to find the information that you are looking for. Please take a few minutes to let us know what you think by taking our quick survey.
第一段似乎没补齐。后面两段好像还行。
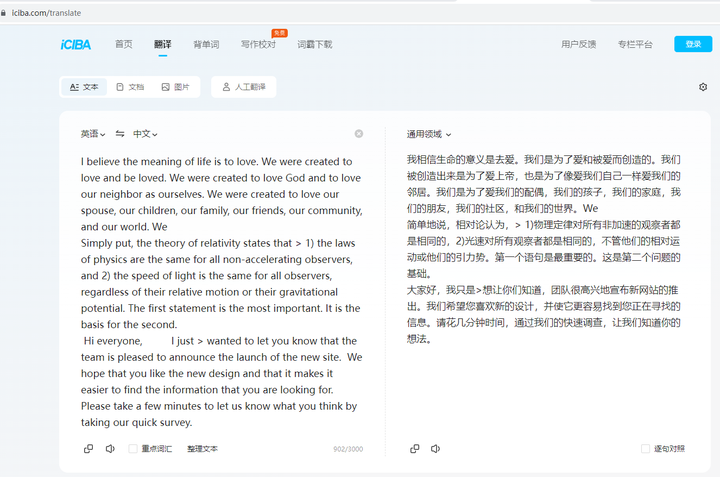
我们来改改prompt
example_text_completion_1.py
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
import fire
from llama import Llama
from typing import List
def main(
ckpt_dir: str,
tokenizer_path: str,
temperature: float = 0.6,
top_p: float = 0.9,
max_seq_len: int = 128,
max_gen_len: int = 64,
max_batch_size: int = 4,
):
"""
Entry point of the program for generating text using a pretrained model.
Args:
ckpt_dir (str): The directory containing checkpoint files for the pretrained model.
tokenizer_path (str): The path to the tokenizer model used for text encoding/decoding.
temperature (float, optional): The temperature value for controlling randomness in generation.
Defaults to 0.6.
top_p (float, optional): The top-p sampling parameter for controlling diversity in generation.
Defaults to 0.9.
max_seq_len (int, optional): The maximum sequence length for input prompts. Defaults to 128.
max_gen_len (int, optional): The maximum length of generated sequences. Defaults to 64.
max_batch_size (int, optional): The maximum batch size for generating sequences. Defaults to 4.
"""
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
prompts: List[str] = [
# For these prompts, the expected answer is the natural continuation of the prompt
"Hello, I am Zhanghui, Now I want to tell you something about me ",
]
results = generator.text_completion(
prompts,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)
for prompt, result in zip(prompts, results):
print(prompt)
print(f"> {result['generation']}")
print("\n==================================\n")
if __name__ == "__main__":
fire.Fire(main)torchrun --nproc_per_node 1 example_text_completion_1.py --ckpt_dir llama-2-7b/ --tokenizer_path tokenizer.model --max_seq_len 128 --max_batch_size 4
运行结果如下:
(llama) zhanghui@ubuntu:/home1/zhanghui/llama$ torchrun --nproc_per_node 1 example_text_completion_1.py --ckpt_dir llama-2-7b/ --tokenizer_path tokenizer.model --max_seq_len 128 --max_batch_size 4
> initializing model parallel with size 1
> initializing ddp with size 1
> initializing pipeline with size 1
Loaded in 20.56 seconds
Hello, I am Zhanghui, Now I want to tell you something about me
> 🙂
I am a Chinese girl. I like music, art, photography, travel, nature and etc. I love learning new things and I am always open to new ideas. I am a very positive person and I like to laugh. I am an open-minded person and I like to
==================================
(llama) zhanghui@ubuntu:/home1/zhanghui/llama$LOL,你对我了解的太多了。居然查出了我的本质。。。
附:
Jetson Orin适配的pytorch 2.0.1的安装包已经放到网盘,请大家自行获取:
链接: 百度网盘 请输入提取码
提取码: 9snu
(全文完,谢谢阅读)