1.简介
组织机构:阿里
代码仓:https://github.com/QwenLM/Qwen
模型:Qwen/Qwen-7B-Chat-Int4
下载:http://huggingface.co/Qwen/Qwen-7B-Chat-Int4
modelscope下载:https://modelscope.cn/models/qwen/Qwen-7B-Chat-Int4/summary
硬件环境:Jetson AGX Orin
2.代码和模型下载
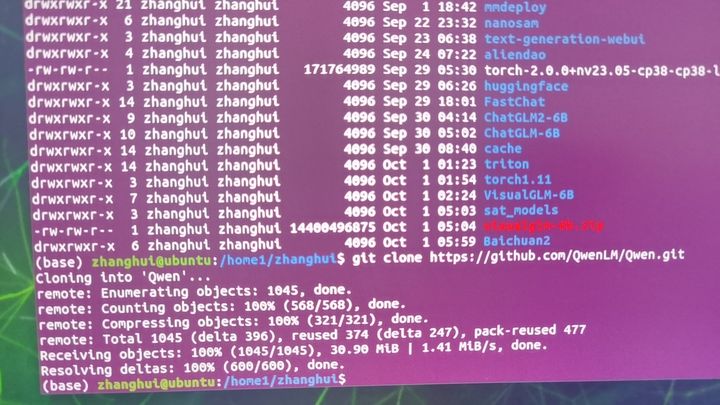
cd /home1/zhanghui
git clone https://github.com/QwenLM/Qwen
cd Qwen
在这个目录下创建模型目录:

打开 http://huggingface.co/Qwen/Qwen-7B-Chat-Int4 下载模型:

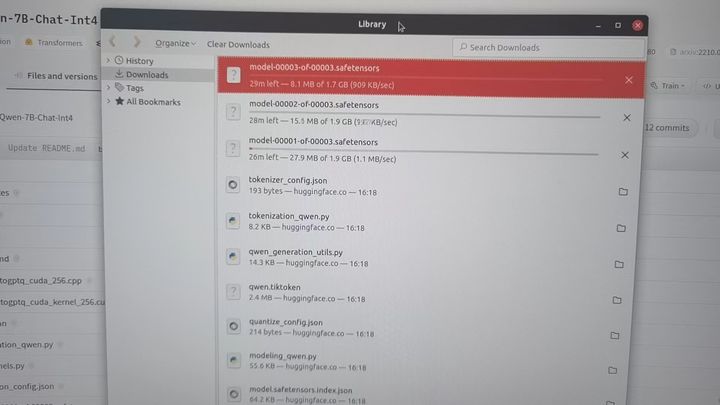
下载好的模型保存到了 ~/Downloads目录:

将其挪到 /home1/zhanghui/Qwen/Qwen/Qwen-7B-Chat-Int4 目录:

3.安装依赖
由于Orin上的pytorch只能选Python 3.8的版本,所以:
conda create -n model38 python=3.8
conda activate model38
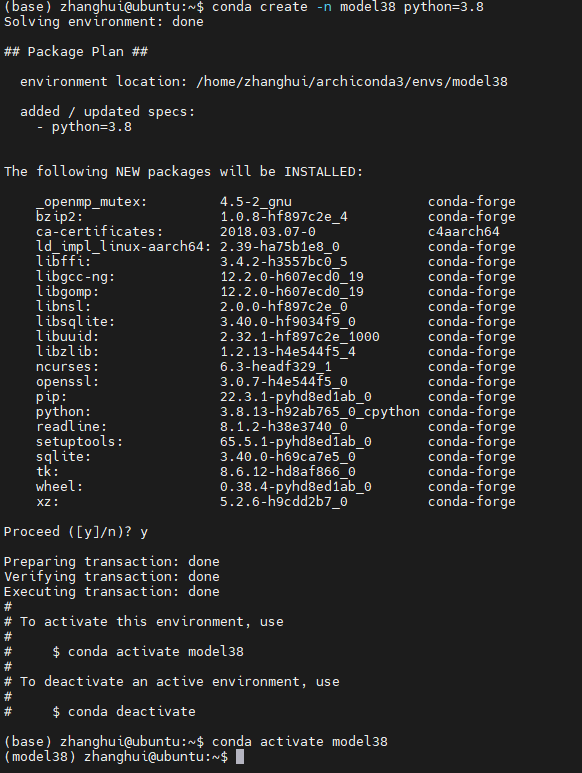
cd /home1/zhanghui/
安装pytorch 2.0
pip install ./torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
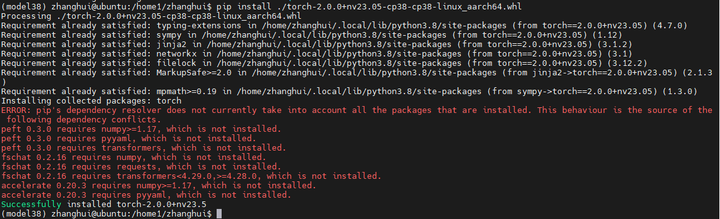
安装依赖包:
cd Qwen
pip install -r requirements.txt


安装量化依赖:
pip install auto-gptq optimum

安装其他依赖:
pip install transformers_stream_generator tiktoken

好像不需要装了。已经有了。
安装flash-attention库
cd ..
git clone https://github.com/Dao-AILab/flash-attention -b v1.0.8
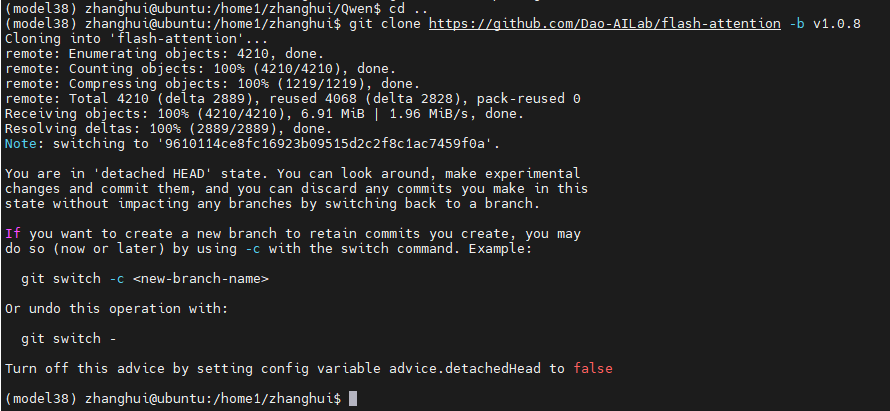
cd flash-attention
pip install .

编译的时间有点慢,要耐心等待。如果不放心,可以另开一个终端看看它是不是还在编译:
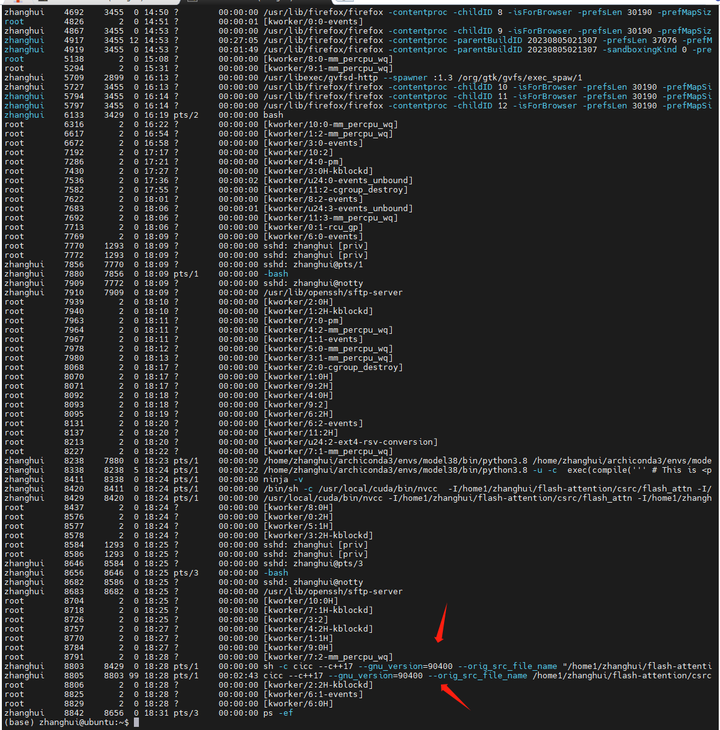
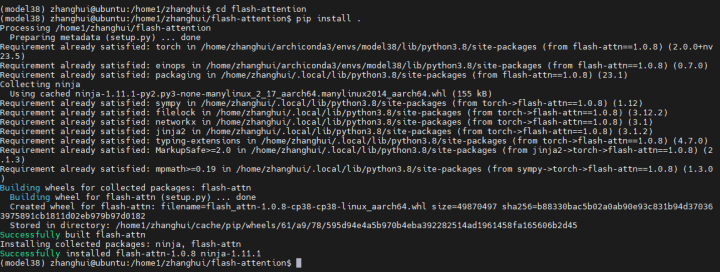
编译完毕。
pip install chardet cchardet
4.部署验证
cd /home1/zhanghui
cd Qwen
修改cli_demo.py
DEFAULT_CKPT_PATH = './Qwen/Qwen-7B-Chat-Int4'
以及去掉清屏
# Copyright (c) Alibaba Cloud.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
"""A simple command-line interactive chat demo."""
import argparse
import os
import platform
import shutil
from copy import deepcopy
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
from transformers.trainer_utils import set_seed
#DEFAULT_CKPT_PATH = 'Qwen/Qwen-7B-Chat'
DEFAULT_CKPT_PATH = './Qwen/Qwen-7B-Chat-Int4'
_WELCOME_MSG = '''\
Welcome to use Qwen-Chat model, type text to start chat, type :h to show command help.
(欢迎使用 Qwen-Chat 模型,输入内容即可进行对话,:h 显示命令帮助。)
Note: This demo is governed by the original license of Qwen.
We strongly advise users not to knowingly generate or allow others to knowingly generate harmful content, including hate speech, violence, pornography, deception, etc.
(注:本演示受Qwen的许可协议限制。我们强烈建议,用户不应传播及不应允许他人传播以下内容,包括但不限于仇恨言论、暴力、色情、欺诈相关的有害信息。)
'''
_HELP_MSG = '''\
Commands:
:help / :h Show this help message 显示帮助信息
:exit / :quit / :q Exit the demo 退出Demo
:clear / :cl Clear screen 清屏
:clear-his / :clh Clear history 清除对话历史
:history / :his Show history 显示对话历史
:seed Show current random seed 显示当前随机种子
:seed <N> Set random seed to <N> 设置随机种子
:conf Show current generation config 显示生成配置
:conf <key>=<value> Change generation config 修改生成配置
:reset-conf Reset generation config 重置生成配置
'''
def _load_model_tokenizer(args):
tokenizer = AutoTokenizer.from_pretrained(
args.checkpoint_path, trust_remote_code=True, resume_download=True,
)
if args.cpu_only:
device_map = "cpu"
else:
device_map = "auto"
model = AutoModelForCausalLM.from_pretrained(
args.checkpoint_path,
device_map=device_map,
trust_remote_code=True,
resume_download=True,
).eval()
config = GenerationConfig.from_pretrained(
args.checkpoint_path, trust_remote_code=True, resume_download=True,
)
return model, tokenizer, config
def _clear_screen():
if platform.system() == "Windows":
os.system("cls")
else:
os.system("clear")
def _print_history(history):
terminal_width = shutil.get_terminal_size()[0]
print(f'History ({len(history)})'.center(terminal_width, '='))
for index, (query, response) in enumerate(history):
print(f'User[{index}]: {query}')
print(f'QWen[{index}]: {response}')
print('=' * terminal_width)
def _get_input() -> str:
while True:
try:
message = input('User> ').strip()
except UnicodeDecodeError:
print('[ERROR] Encoding error in input')
continue
except KeyboardInterrupt:
exit(1)
if message:
return message
print('[ERROR] Query is empty')
def main():
parser = argparse.ArgumentParser(
description='QWen-Chat command-line interactive chat demo.')
parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH,
help="Checkpoint name or path, default to %(default)r")
parser.add_argument("-s", "--seed", type=int, default=1234, help="Random seed")
parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only")
args = parser.parse_args()
history, response = [], ''
model, tokenizer, config = _load_model_tokenizer(args)
orig_gen_config = deepcopy(model.generation_config)
#_clear_screen()
print(_WELCOME_MSG)
seed = args.seed
while True:
query = _get_input()
# Process commands.
if query.startswith(':'):
command_words = query[1:].strip().split()
if not command_words:
command = ''
else:
command = command_words[0]
if command in ['exit', 'quit', 'q']:
break
elif command in ['clear', 'cl']:
_clear_screen()
print(_WELCOME_MSG)
continue
elif command in ['clear-history', 'clh']:
print(f'[INFO] All {len(history)} history cleared')
history.clear()
continue
elif command in ['help', 'h']:
print(_HELP_MSG)
continue
elif command in ['history', 'his']:
_print_history(history)
continue
elif command in ['seed']:
if len(command_words) == 1:
print(f'[INFO] Current random seed: {seed}')
continue
else:
new_seed_s = command_words[1]
try:
new_seed = int(new_seed_s)
except ValueError:
print(f'[WARNING] Fail to change random seed: {new_seed_s!r} is not a valid number')
else:
print(f'[INFO] Random seed changed to {new_seed}')
seed = new_seed
continue
elif command in ['conf']:
if len(command_words) == 1:
print(model.generation_config)
else:
for key_value_pairs_str in command_words[1:]:
eq_idx = key_value_pairs_str.find('=')
if eq_idx == -1:
print('[WARNING] format: <key>=<value>')
continue
conf_key, conf_value_str = key_value_pairs_str[:eq_idx], key_value_pairs_str[eq_idx + 1:]
try:
conf_value = eval(conf_value_str)
except Exception as e:
print(e)
continue
else:
print(f'[INFO] Change config: model.generation_config.{conf_key} = {conf_value}')
setattr(model.generation_config, conf_key, conf_value)
continue
elif command in ['reset-conf']:
print('[INFO] Reset generation config')
model.generation_config = deepcopy(orig_gen_config)
print(model.generation_config)
continue
else:
# As normal query.
pass
# Run chat.
set_seed(seed)
try:
for response in model.chat_stream(tokenizer, query, history=history, generation_config=config):
pass
# print(f"\nUser: {query}")
print(f"\nQwen-Chat: {response}")
# _clear_screen()
# print(f"\nUser: {query}")
# print(f"\nQwen-Chat: {response}")
except KeyboardInterrupt:
print('[WARNING] Generation interrupted')
continue
history.append((query, response))
if __name__ == "__main__":
main()
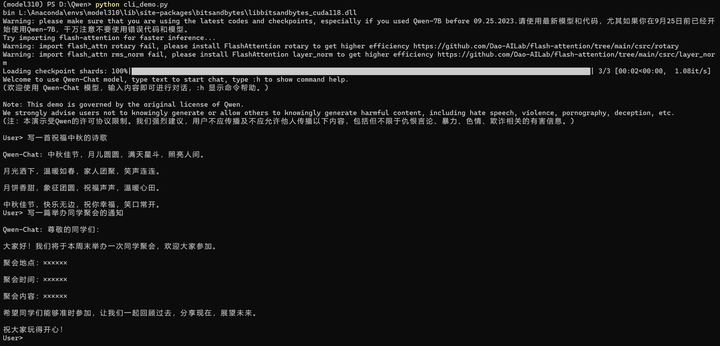
运行 python cli_demo.py

看来如果不装modelscope的话,可能会少不少其他的包。
pip install modelscope

再来:python cli_demo.py
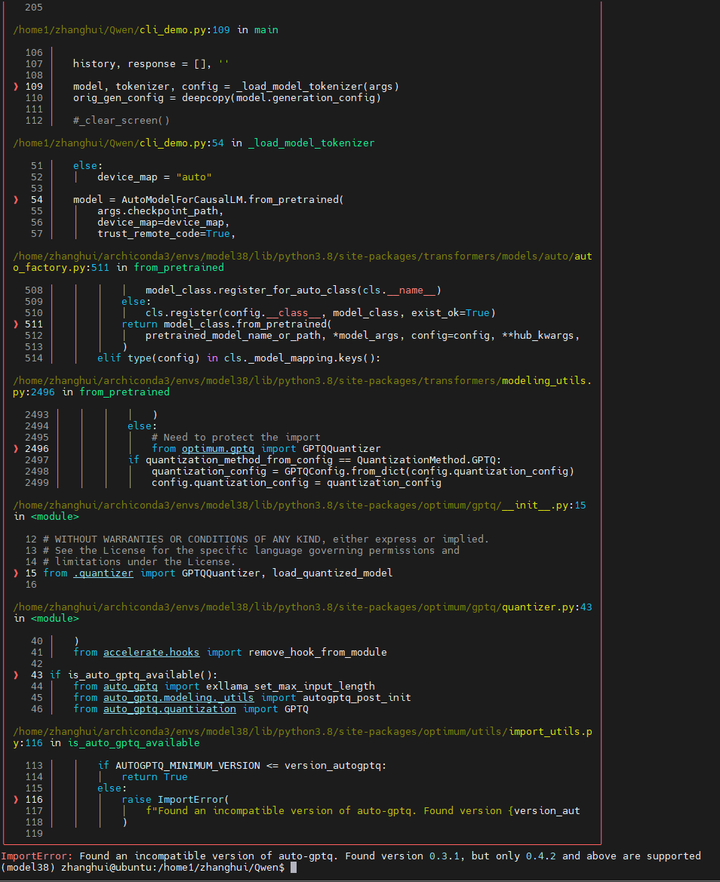
怎么?auto-gptq没有aarch64的版本?
pip install auto-gptq==0.4.2

那就只好源码编译了。
打开AutoGPTQ官网:https://github.com/PanQiWei/AutoGPTQ
请注意不是AutoGPT:https://github.com/Significant-Gravitas/AutoGPT
而是AutoGPTQ。AutoGPTQ用于量化,而AutoGPT是自动聊天机器人。
cd ..
git clone https://github.com/PanQiWei/AutoGPTQ.git -b v0.4.2
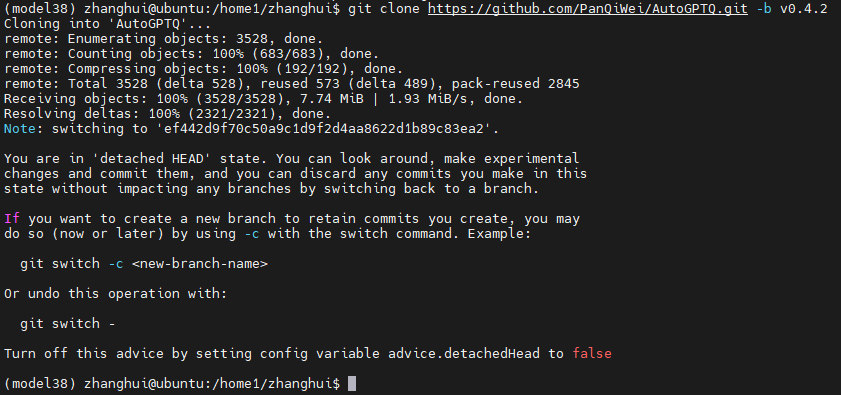
cd AutoGPTQ
pip install -v .

耐心等待编译结束:

cd ../Qwen
再来:python cli_demo.py
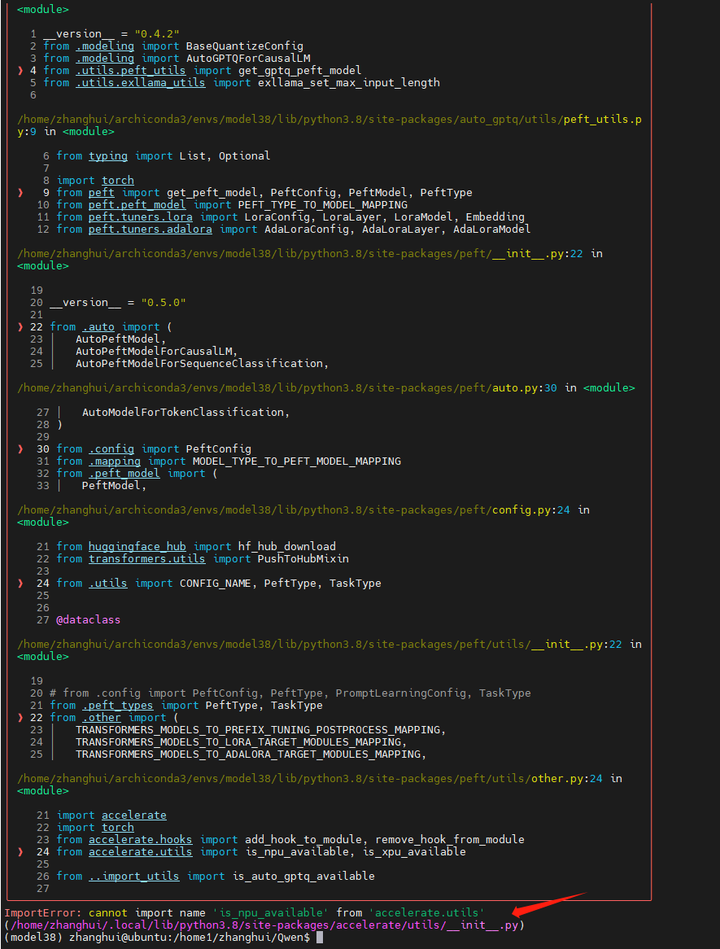
参考:本地免费GPT4?Llama 2开源大模型,一键部署且无需硬件要求教程-CSDN博客
修改 /home/zhanghui/archiconda3/envs/model38/lib/python3.8/site-packages/peft/utils/other.py
将 is_npu_available改为is_tpu_available
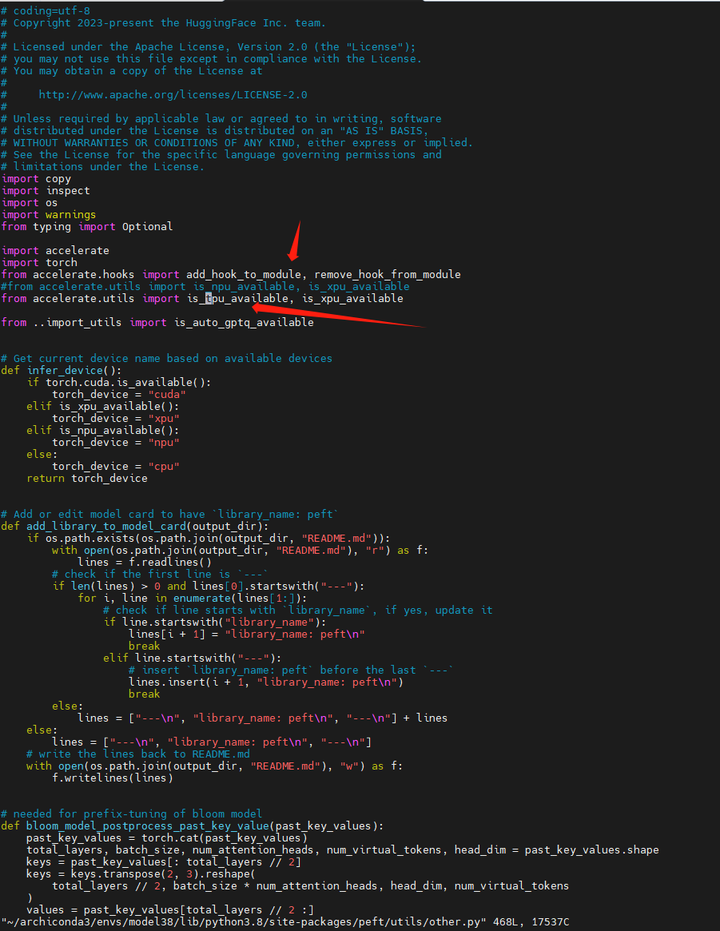
再来:python cli_demo.py
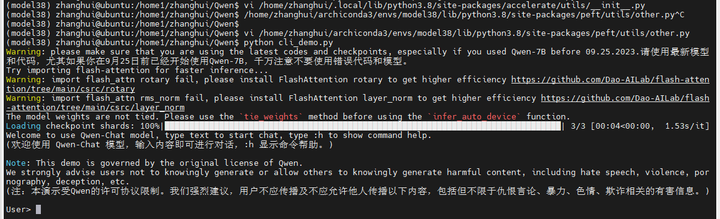
终于可以运行了?
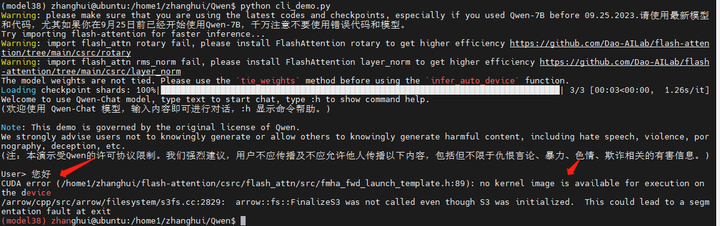
好像并不可以。
查看下torch的版本:
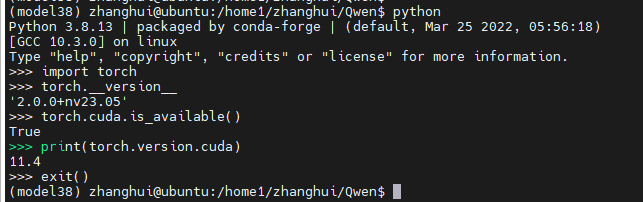
用modelscope的方式运行下试试呢?
vi Qwen-7B-Chat-Int4.py
from modelscope import AutoTokenizer, AutoModelForCausalLM, snapshot_download
model_dir = snapshot_download("qwen/Qwen-7B-Chat-Int4", revision = 'v1.1.3' )
# Note: The default behavior now has injection attack prevention off.
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
trust_remote_code=True
).eval()
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
# 你好!很高兴为你提供帮助。并执行:python Qwen-7B-Chat-Int4.py
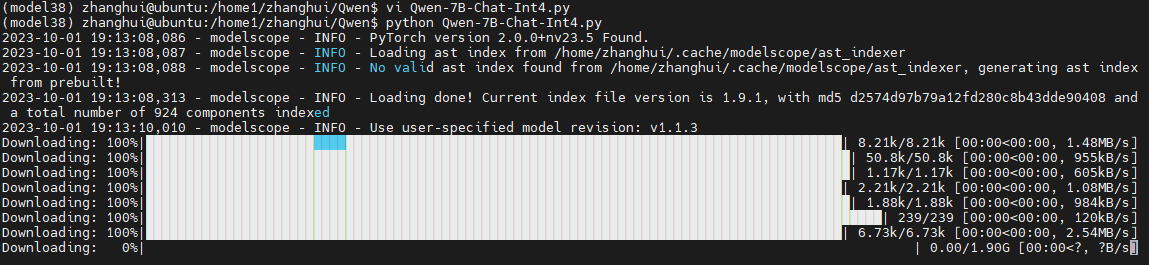
它会将模型下载到 ~/.cache/modelscope/hub/qwen/Qwen-7B-Chat-Int4 目录:(其实下次可以把这个目录下的文件准备好)
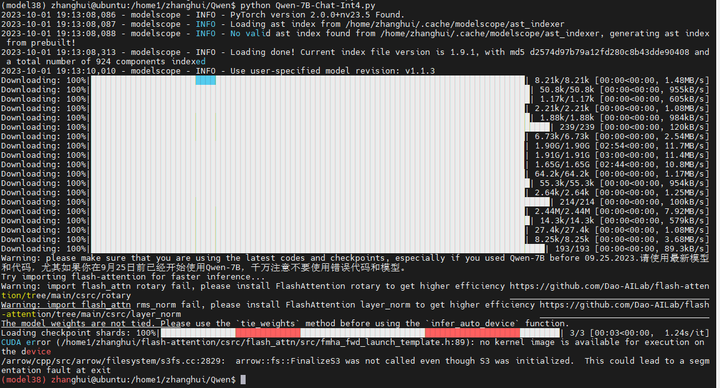
这个直接就报错了。错误跟cli_demo.py一模一样。
将 ~/archiconda3/envs/model38/lib/python3.8/site-packages/peft/utils/other.py 文件改回来:
from accelerate.utils import is_npu_available, is_xpu_available
#from accelerate.utils import is_tpu_available, is_xpu_available查看 https://blog.51cto.com/u_9453611/7671814
可能是peft包的问题,重新装一下:
pip uninstall peft

pip install peft@git+https://github.com/huggingface/peft.git
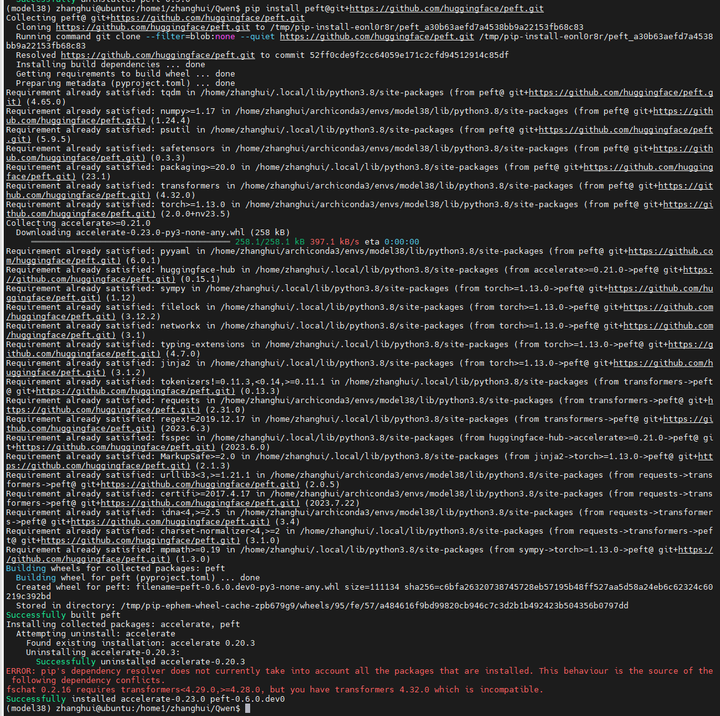
再来:python Qwen-7B-Chat-Int4.py

(model38) zhanghui@ubuntu:/home1/zhanghui/Qwen$ python Qwen-7B-Chat-Int4.py
2023-10-01 19:55:46,315 - modelscope - INFO - PyTorch version 2.0.0+nv23.5 Found.
2023-10-01 19:55:46,316 - modelscope - INFO - Loading ast index from /home/zhanghui/.cache/modelscope/ast_indexer
2023-10-01 19:55:46,365 - modelscope - INFO - Loading done! Current index file version is 1.9.1, with md5 d2574d97b79a12fd280c8b43dde90408 and a total number of 924 components indexed
2023-10-01 19:55:47,331 - modelscope - INFO - Use user-specified model revision: v1.1.3
Warning: please make sure that you are using the latest codes and checkpoints, especially if you used Qwen-7B before 09.25.2023.请使用最新模型和代码,尤其如果你在9月25日前已经开始使用Qwen-7B,千万注意不要使用错误代码和模型。
Try importing flash-attention for faster inference...
Warning: import flash_attn rotary fail, please install FlashAttention rotary to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/rotary
Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████| 3/3 [00:03<00:00, 1.11s/it]
CUDA error (/home1/zhanghui/flash-attention/csrc/flash_attn/src/fmha_fwd_launch_template.h:89): no kernel image is available for execution on the device
/arrow/cpp/src/arrow/filesystem/s3fs.cc:2829: arrow::fs::FinalizeS3 was not called even though S3 was initialized. This could lead to a segmentation fault at exit
(model38) zhanghui@ubuntu:/home1/zhanghui/Qwen$要不然垂死挣扎一次,重新源码编译一下flash attention
pip uninstall flash-attn

安装最新版flash-attn试试:
cd /home1/zhanghui
mkdir new
cd new
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
pip install flash-attn --no-build-isolation

python setup.py install
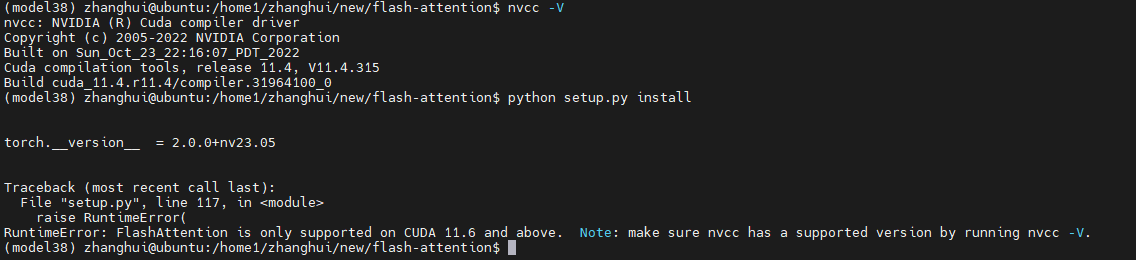
当前的nvcc是11.4版本,而最新版flash-attn需要11.6以上版本。
所以是不是装一个cuda 11.6?经验告诉我,这不是一个好的选择,没准会把orin给搞崩溃。
那么退而求其次,我们看看 flash-attention有么有支持11.4版本的:https://github.com/Dao-AILab/flash-attention/tree/v2.1.0
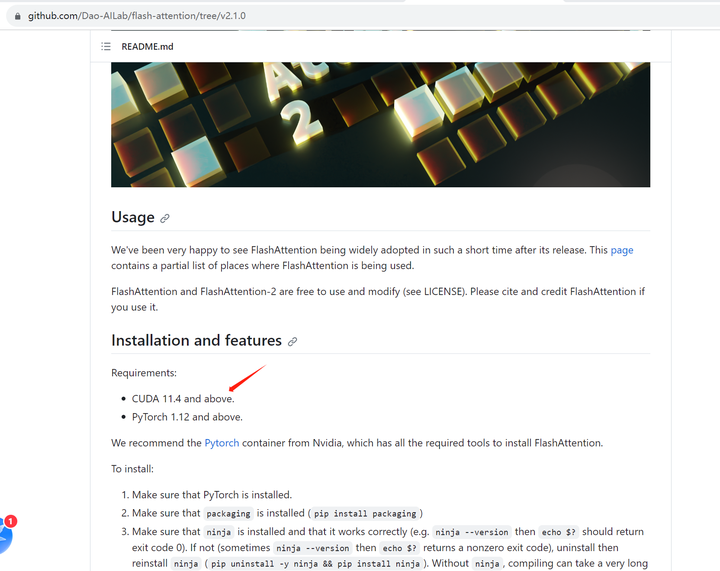
巧的是 v2.1.1 是CUDA 11.4版本,而v2.1.2是CUDA11.6版本。
cd /home1/zhanghui
pip uninstall flash-attn
mkdir new2
cd new2
git clone https://github.com/Dao-AILab/flash-attention -b v2.1.0

cd flash-attention
python setup.py install
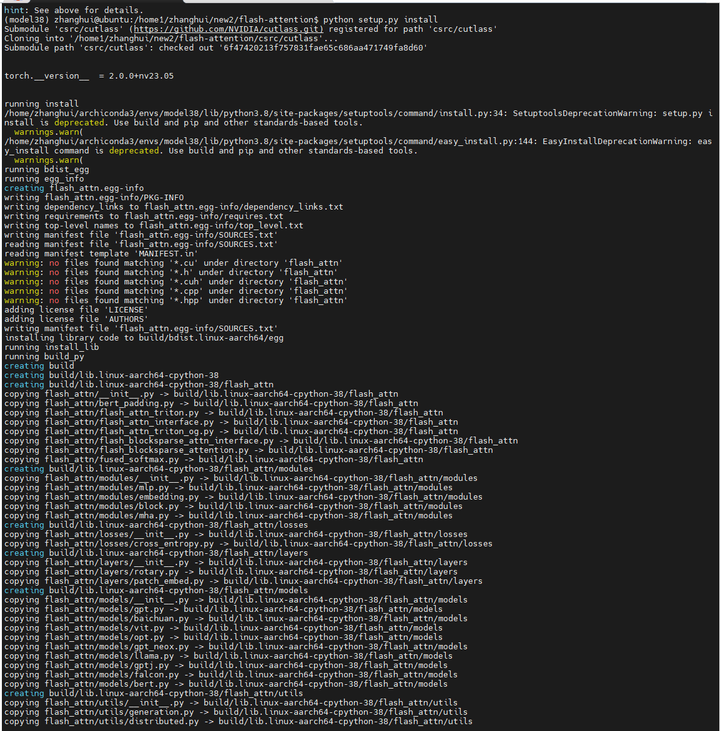
然后好像orin又死了。

重启Orin后,试试单进程编译:
export MAX_JOBS=1
export FLASH_ATTENTION_FORCE_SINGLE_THREAD=True
python setup.py install
耐心等待吧。
这回应该不会让CPU占满的。
但是一直看不出来。可能是并发太低了。这样其实也受不了。
还是换成 2.1.1的版本吧!
cd /home1/zhanghui
cd new2
mv flash-attention flash-attention-2.1.0
git clone https://github.com/Dao-AILab/flash-attention -b v2.1.1
cd flash-attention
export MAX_JOBS=4
python setup.py install
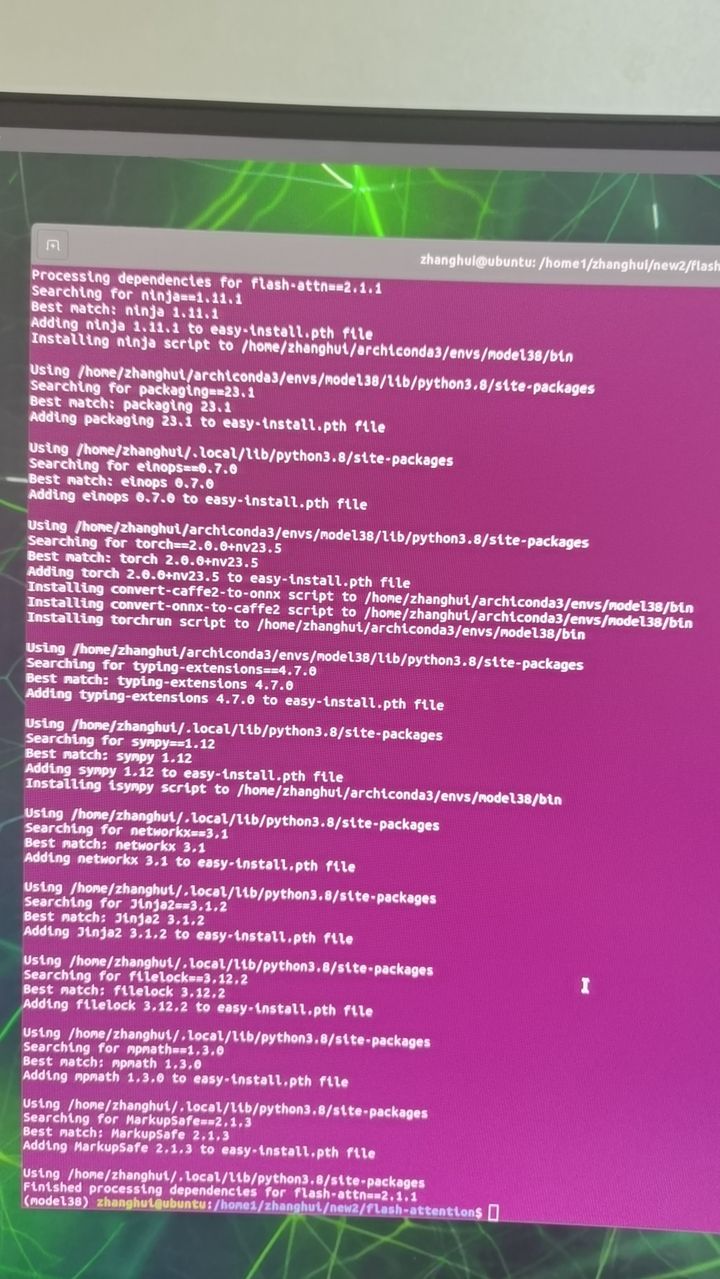
编译成功。
再试试:
cd /home1/zhanghui
cd Qwen
python Qwen-7B-Chat-Int4.py
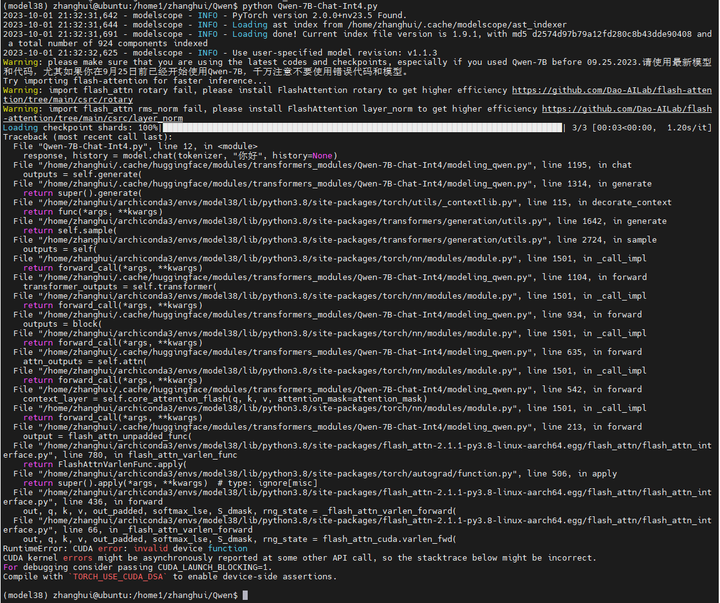
报错如下:
(model38) zhanghui@ubuntu:/home1/zhanghui/Qwen$ python Qwen-7B-Chat-Int4.py
2023-10-01 21:32:31,642 - modelscope - INFO - PyTorch version 2.0.0+nv23.5 Found.
2023-10-01 21:32:31,644 - modelscope - INFO - Loading ast index from /home/zhanghui/.cache/modelscope/ast_indexer
2023-10-01 21:32:31,691 - modelscope - INFO - Loading done! Current index file version is 1.9.1, with md5 d2574d97b79a12fd280c8b43dde90408 and a total number of 924 components indexed
2023-10-01 21:32:32,625 - modelscope - INFO - Use user-specified model revision: v1.1.3
Warning: please make sure that you are using the latest codes and checkpoints, especially if you used Qwen-7B before 09.25.2023.请使用最新模型和代码,尤其如果你在9月25日前已经开始使用Qwen-7B,千万注意不要使用错误代码和模型。
Try importing flash-attention for faster inference...
Warning: import flash_attn rotary fail, please install FlashAttention rotary to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/rotary
Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████| 3/3 [00:03<00:00, 1.20s/it]
Traceback (most recent call last):
File "Qwen-7B-Chat-Int4.py", line 12, in <module>
response, history = model.chat(tokenizer, "你好", history=None)
File "/home/zhanghui/.cache/huggingface/modules/transformers_modules/Qwen-7B-Chat-Int4/modeling_qwen.py", line 1195, in chat
outputs = self.generate(
File "/home/zhanghui/.cache/huggingface/modules/transformers_modules/Qwen-7B-Chat-Int4/modeling_qwen.py", line 1314, in generate
return super().generate(
File "/home/zhanghui/archiconda3/envs/model38/lib/python3.8/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/home/zhanghui/archiconda3/envs/model38/lib/python3.8/site-packages/transformers/generation/utils.py", line 1642, in generate
return self.sample(
File "/home/zhanghui/archiconda3/envs/model38/lib/python3.8/site-packages/transformers/generation/utils.py", line 2724, in sample
outputs = self(
File "/home/zhanghui/archiconda3/envs/model38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/zhanghui/.cache/huggingface/modules/transformers_modules/Qwen-7B-Chat-Int4/modeling_qwen.py", line 1104, in forward
transformer_outputs = self.transformer(
File "/home/zhanghui/archiconda3/envs/model38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/zhanghui/.cache/huggingface/modules/transformers_modules/Qwen-7B-Chat-Int4/modeling_qwen.py", line 934, in forward
outputs = block(
File "/home/zhanghui/archiconda3/envs/model38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/zhanghui/.cache/huggingface/modules/transformers_modules/Qwen-7B-Chat-Int4/modeling_qwen.py", line 635, in forward
attn_outputs = self.attn(
File "/home/zhanghui/archiconda3/envs/model38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/zhanghui/.cache/huggingface/modules/transformers_modules/Qwen-7B-Chat-Int4/modeling_qwen.py", line 542, in forward
context_layer = self.core_attention_flash(q, k, v, attention_mask=attention_mask)
File "/home/zhanghui/archiconda3/envs/model38/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/zhanghui/.cache/huggingface/modules/transformers_modules/Qwen-7B-Chat-Int4/modeling_qwen.py", line 213, in forward
output = flash_attn_unpadded_func(
File "/home/zhanghui/archiconda3/envs/model38/lib/python3.8/site-packages/flash_attn-2.1.1-py3.8-linux-aarch64.egg/flash_attn/flash_attn_interface.py", line 780, in flash_attn_varlen_func
return FlashAttnVarlenFunc.apply(
File "/home/zhanghui/archiconda3/envs/model38/lib/python3.8/site-packages/torch/autograd/function.py", line 506, in apply
return super().apply(*args, **kwargs) # type: ignore[misc]
File "/home/zhanghui/archiconda3/envs/model38/lib/python3.8/site-packages/flash_attn-2.1.1-py3.8-linux-aarch64.egg/flash_attn/flash_attn_interface.py", line 436, in forward
out, q, k, v, out_padded, softmax_lse, S_dmask, rng_state = _flash_attn_varlen_forward(
File "/home/zhanghui/archiconda3/envs/model38/lib/python3.8/site-packages/flash_attn-2.1.1-py3.8-linux-aarch64.egg/flash_attn/flash_attn_interface.py", line 66, in _flash_attn_varlen_forward
out, q, k, v, out_padded, softmax_lse, S_dmask, rng_state = flash_attn_cuda.varlen_fwd(
RuntimeError: CUDA error: invalid device function
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.这个问题搜了一下,在网上看到过很多次,大概率是什么软件版本不匹配的原因。这样就比较尴尬了。
比如安装torch 2.1的jetson版本试试:
pip install ./torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl

python Qwen-7B-Chat-Int4.py
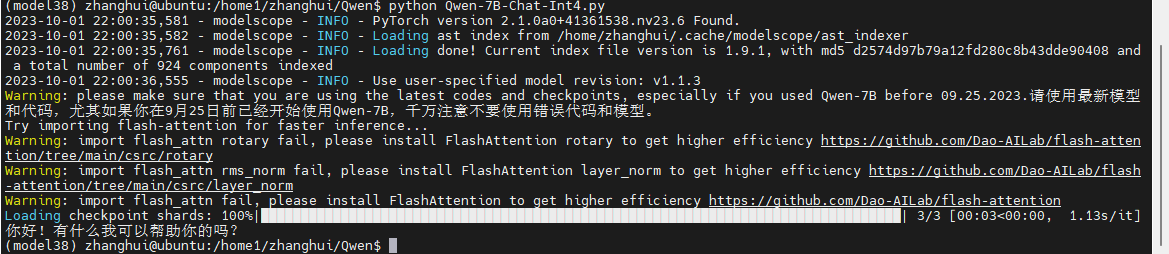
咦?
怎么好像是成功的样子。。。
python cli_demo.py

没想到到最后居然能成功。真的是国庆一喜了!
最后列一下pip的版本:
(model38) zhanghui@ubuntu:~$ pip list
Package Version Editable project location
----------------------------- ----------------------- -------------------------------
absl-py 2.0.0
accelerate 0.23.0
addict 2.4.0
aiofiles 23.1.0
aiohttp 3.8.4
aiosignal 1.3.1
aliyun-python-sdk-core 2.14.0
aliyun-python-sdk-kms 2.16.2
altair 5.0.1
anyio 3.7.0
appdirs 1.4.4
async-timeout 4.0.2
attrs 23.1.0
auto-gptq 0.4.2+cu114
cachetools 5.3.1
cchardet 2.1.7
certifi 2023.7.22
cffi 1.16.0
chardet 5.2.0
charset-normalizer 3.1.0
click 8.1.7
coloredlogs 15.0.1
contourpy 1.1.1
crcmod 1.7
cryptography 41.0.4
cycler 0.12.0
datasets 2.13.0
diffusers 0.21.4
dill 0.3.6
docker-pycreds 0.4.0
einops 0.7.0
exceptiongroup 1.1.1
fastapi 0.99.0
ffmpy 0.3.0
filelock 3.12.2
flash-attn 2.1.1
fonttools 4.43.0
frozenlist 1.3.3
fschat 0.2.16
fsspec 2023.6.0
gast 0.5.4
gitdb 4.0.10
GitPython 3.1.31
google-auth 2.23.2
google-auth-oauthlib 1.0.0
gradio 3.35.2
gradio_client 0.2.7
grpcio 1.59.0
h11 0.14.0
httpcore 0.17.2
httpx 0.24.1
huggingface-hub 0.15.1
humanfriendly 10.0
idna 3.4
importlib-metadata 6.8.0
importlib-resources 5.12.0
jieba 0.42.1
Jinja2 3.1.2
jmespath 0.10.0
joblib 1.3.2
jsonschema 4.17.3
kiwisolver 1.4.5
linkify-it-py 2.0.2
loralib 0.1.2
Markdown 3.4.4
markdown-it-py 2.2.0
markdown2 2.4.9
MarkupSafe 2.1.3
matplotlib 3.7.3
mdit-py-plugins 0.3.3
mdurl 0.1.2
modelscope 1.9.1
mpmath 1.3.0
ms-swift 1.1.0
multidict 6.0.4
multiprocess 0.70.14
nanosam 0.0 /home1/zhanghui/nanosam/nanosam
networkx 3.1
nh3 0.2.13
ninja 1.11.1
nltk 3.8.1
numpy 1.24.4
oauthlib 3.2.2
optimum 1.13.2
orjson 3.9.1
oss2 2.18.2
packaging 23.1
pandas 2.0.3
pathtools 0.1.2
peft 0.6.0.dev0
Pillow 10.0.1
pip 22.3.1
pkgutil_resolve_name 1.3.10
platformdirs 3.10.0
prompt-toolkit 3.0.38
protobuf 4.24.3
psutil 5.9.5
pyarrow 13.0.0
pyasn1 0.5.0
pyasn1-modules 0.3.0
pycparser 2.21
pycryptodome 3.19.0
pydantic 1.10.10
pydub 0.25.1
Pygments 2.15.1
pyparsing 3.1.1
pyrsistent 0.19.3
python-dateutil 2.8.2
python-multipart 0.0.6
pytz 2023.3.post1
PyYAML 6.0.1
regex 2023.6.3
requests 2.31.0
requests-oauthlib 1.3.1
rich 13.4.2
rouge 1.0.1
rsa 4.9
safetensors 0.3.3
scipy 1.10.1
semantic-version 2.10.0
sentencepiece 0.1.99
sentry-sdk 1.26.0
setproctitle 1.3.2
setuptools 65.5.1
shortuuid 1.0.11
simplejson 3.19.1
six 1.16.0
smmap 5.0.0
sniffio 1.3.0
sortedcontainers 2.4.0
starlette 0.27.0
svgwrite 1.4.3
sympy 1.12
tensorboard 2.14.0
tensorboard-data-server 0.7.1
tiktoken 0.4.0
tokenizers 0.13.3
tomli 2.0.1
toolz 0.12.0
torch 2.1.0a0+41361538.nv23.6
tqdm 4.65.0
transformers 4.32.0
transformers-stream-generator 0.0.4
typing_extensions 4.7.0
tzdata 2023.3
uc-micro-py 1.0.2
urllib3 2.0.5
uvicorn 0.22.0
wandb 0.15.4
wavedrom 2.0.3.post3
wcwidth 0.2.6
websockets 11.0.3
Werkzeug 3.0.0
wheel 0.38.4
xxhash 3.3.0
yapf 0.40.2
yarl 1.9.2
zipp 3.15.0
(model38) zhanghui@ubuntu:~$
(全文完,谢谢阅读)