文章目录
- 1. SE (Squeeze-and-Excitation)
- 2. CBAM (Convolutional Block Attention Module)
- 3. ECA (Efficient Channel Attention)
- 4. CA (Coordinate Attention)
1. SE (Squeeze-and-Excitation)
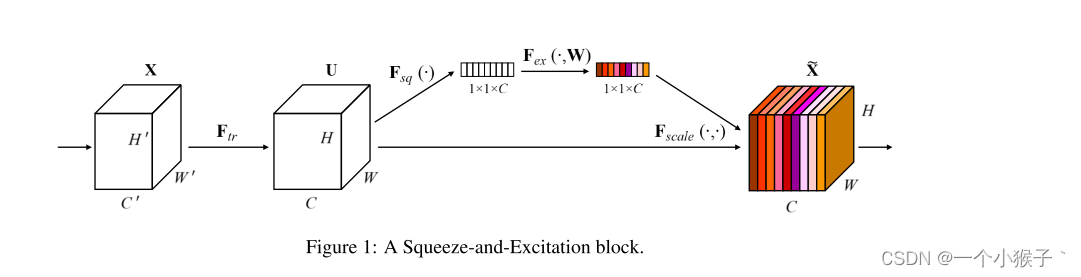
SENet是通道注意力机制的典型实现
对于SENet而言,其重点是获得输入进来的特征层,每一个通道的权值。利用SENet,我们可以让网络关注它最需要关注的通道。
实现方式:
1、对输入的特征层进行全局平局池化
2、然后进行两次全连接,第一次全连接输出的通道数会少一些,第二次全连接输出的通道数和输入的特征层相同
3、在完成两次全连接之后,会使用一次sigmoid将值固定在[0,1]之间,此时我们获得了输入特征层每一个通道的权值
4、将获得的权值与输入特征层相乘
优点:
简单有效:SE注意力机制提出简单,易于实现,同时在各种视觉任务中证明了其有效性。
参数少:相较于其他注意力机制,SE模块的参数量相对较少,因此在性能和计算开销之间取得了平衡。
缺点:
计算相对复杂:虽然参数少,但在网络中引入SE模块可能增加计算的复杂性,特别是在大规模网络中。
代码
import torch
from torch import nn
class senet(nn.Module):
def __init__(self, channel, ration=16):
super(senet, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // ration, bias=False),
nn.ReLU(),
nn.Linear(channel // ration, channel, bias=False),
nn.Sigmoid(),
)
def forward(self, x):
b, c, h, w = x.size()
# b, c ,h, w --> b, c, 1, 1
avg = self.avg_pool(x).view([b,c])
fc = self.fc(avg).view([b, c, 1, 1])
return x * fc
2. CBAM (Convolutional Block Attention Module)
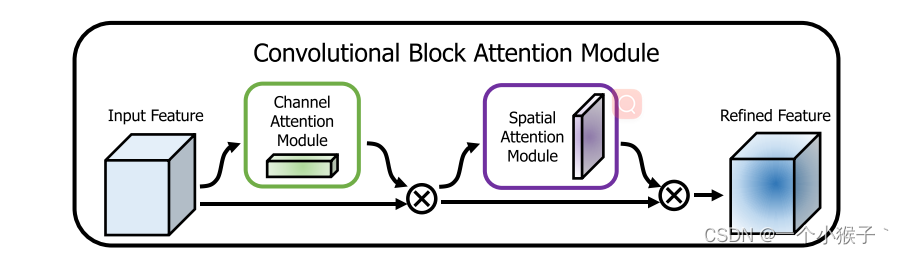
CBAM将通道注意力机制和空间注意力机制进行一个结合,相比于SENet只关注通道的注意力机制可以取得更好的效果。其实现示意图如下所示,CBAM会对输入进来的特征层,分别进行通道注意力机制的处理和空间注意力机制的处理。
实现方式:
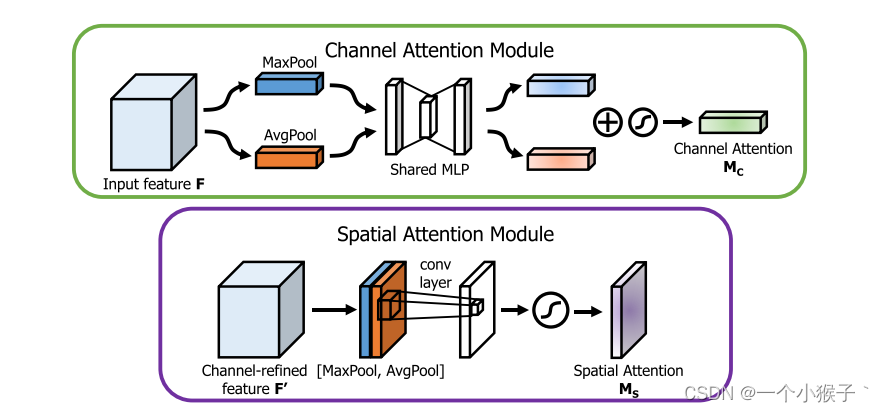
图像的上半部分为通道注意力机制,通道注意力机制的实现可以分为两个部分,我们会对输入进来的单个特征层,分别进行全局平均池化和全局最大池化。之后对平均池化和最大池化的结果,利用共享的全连接层进行处理,我们会对处理后的两个结果进行相加,然后取一个sigmoid,此时我们获得了输入特征层每一个通道的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
图像的下半部分为空间注意力机制,我们会对输入进来的特征层,在每一个特征点的通道上取最大值和平均值。之后将这两个结果进行一个堆叠,利用一次通道数为1的卷积调整通道数,然后取一个sigmoid,此时我们获得了输入特征层每一个特征点的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
优点:
结合了卷积和注意力机制,可以从空间和通道两个方面上对图像进行关注。
缺点:
需要更多的计算资源,计算复杂度更高。
代码
import torch
from torch import nn
#通道注意力
class channel_attention(nn.Module):
def __init__(self, channel, ration=16):
super(channel_attention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel//ration, bias=False),
nn.ReLU(),
nn.Linear(channel//ration, channel, bias=False),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.size()
avg_pool = self.avg_pool(x).view([b, c])
max_pool = self.max_pool(x).view([b, c])
avg_fc = self.fc(avg_pool)
max_fc = self.fc(max_pool)
out = self.sigmoid(max_fc+avg_fc).view([b, c, 1, 1])
return x * out
#空间注意力
class spatial_attention(nn.Module):
def __init__(self, kernel_size=7):
super(spatial_attention, self).__init__()
self.conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=kernel_size, stride=1,
padding=kernel_size // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.size()
#通道的最大池化
max_pool = torch.max(x, dim=1, keepdim=True).values
avg_pool = torch.mean(x, dim=1, keepdim=True)
pool_out = torch.cat([max_pool, avg_pool], dim=1)
conv = self.conv(pool_out)
out = self.sigmoid(conv)
return out * x
#将通道注意力和空间注意力进行融合
class CBAM(nn.Module):
def __init__(self, channel, ration=16, kernel_size=7):
super(CBAM, self).__init__()
self.channel_attention = channel_attention(channel, ration)
self.spatial_attention = spatial_attention(kernel_size)
def forward(self, x):
out = self.channel_attention(x)
out = self.spatial_attention(out)
return out
model = CBAM(512)
print(model)
inputs = torch.ones([2,512,26,26])
out = model(inputs)
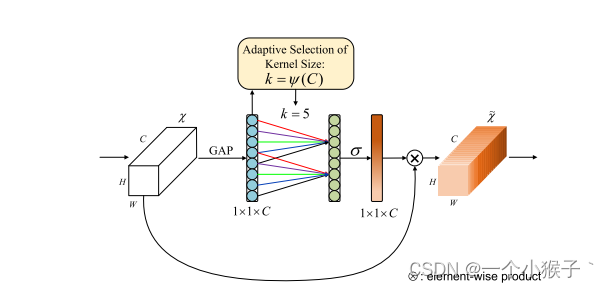
3. ECA (Efficient Channel Attention)
CANet可以看作是SENet的改进版。
ECANet的作者认为SENet对通道注意力机制的预测带来了副作用,捕获所有通道的依赖关系是低效并且是不必要的。
在ECANet的论文中,作者认为卷积具有良好的跨通道信息获取能力。
ECA模块去除了原来SE模块中的全连接层,直接在全局平均池化之后的特征上通过一个1D卷积进行学习。
既然使用到了1D卷积,那么1D卷积的卷积核大小的选择就变得非常重要了,1D卷积的卷积核大小会影响注意力机制每个权重的计算要考虑的通道数量。用更专业的名词就是跨通道交互的覆盖率。
优点:
计算效率高:ECA模块采用了一维卷积的方式,相较于二维卷积,在保持性能的前提下降低了计算复杂度。
缺点:
空间信息未利用:ECA主要关注通道信息,相对忽略了空间信息,这可能在某些任务中不是最优的选择。
代码
import torch
from torch import nn
import math
class eca_block(nn.Module):
def __init__(self, channel, gamma=2, b=1):
super(eca_block, self).__init__()
kernel_size = int(abs((math.log(channel,2)+ b)/gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size+1
padding = kernel_size//2
self.avg_pool =nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.size()
#变成序列的形式
avg = self.avg_pool(x).view([b, 1, c])
out = self.conv(avg)
out = self.sigmoid(out).view([b, c, 1, 1])
return out * x
model = eca_block(512)
print(model)
inputs = torch.ones([2,512,26,26])
outputs = model(inputs)
4. CA (Coordinate Attention)
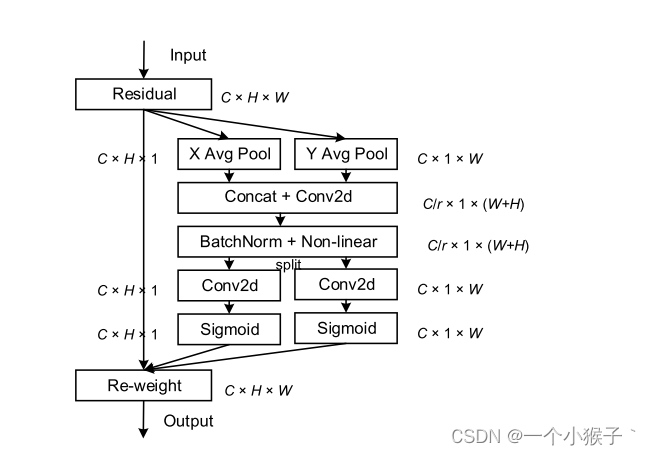
该文章的作者认为现有的注意力机制(如CBAM、SE)在求取通道注意力的时候,通道的处理一般是采用全局最大池化/平均池化,这样会损失掉物体的空间信息。作者期望在引入通道注意力机制的同时,引入空间注意力机制,作者提出的注意力机制将位置信息嵌入到了通道注意力中。
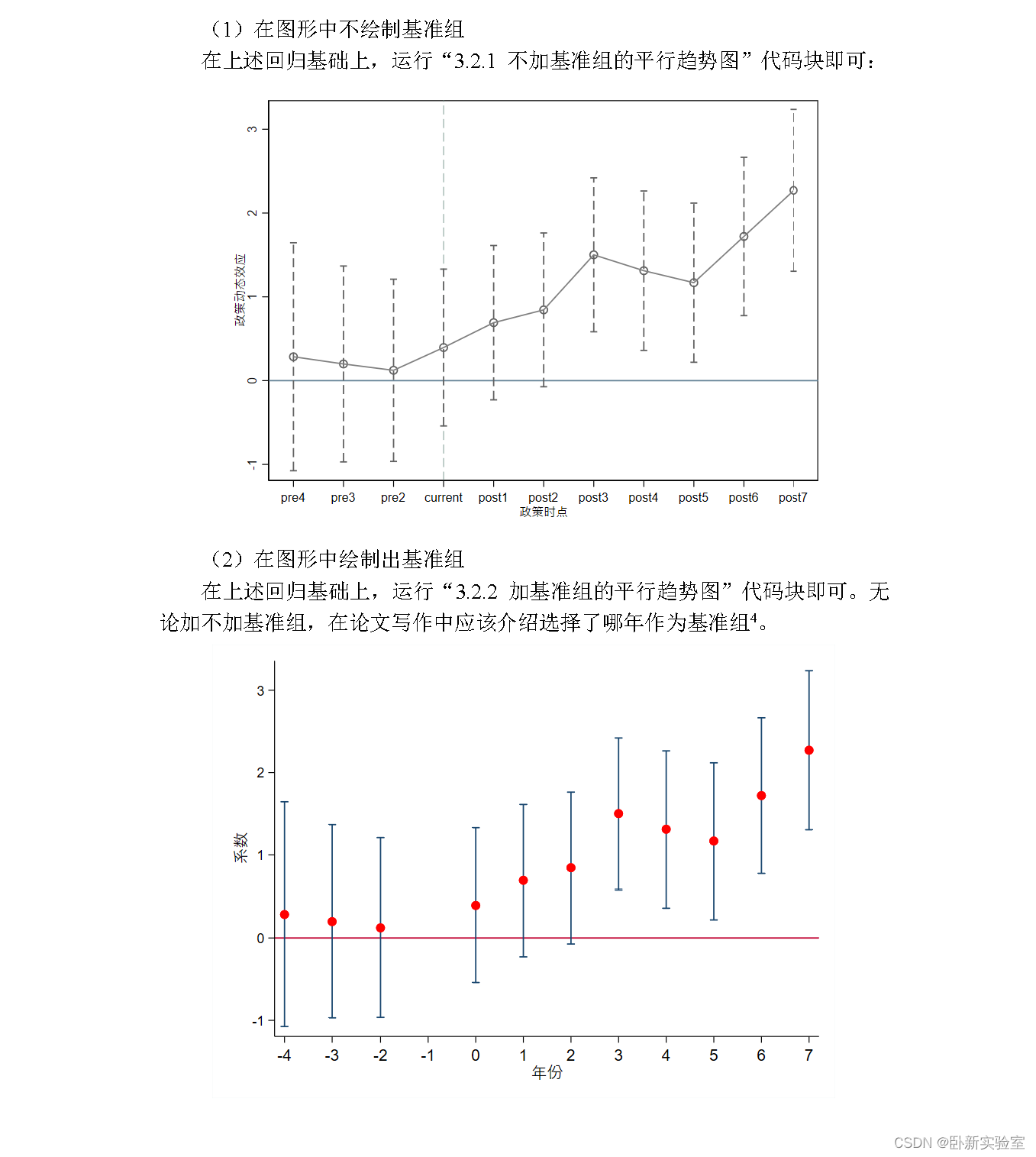
CA注意力的实现如图所示,可以认为分为两个并行阶段:
将输入特征图分别在为宽度和高度两个方向分别进行全局平均池化,分别获得在宽度和高度两个方向的特征图。假设输入进来的特征层的形状为[C, H, W],在经过宽方向的平均池化后,获得的特征层shape为[C, H, 1],此时我们将特征映射到了高维度上;在经过高方向的平均池化后,获得的特征层shape为[C, 1, W],此时我们将特征映射到了宽维度上。
然后将两个并行阶段合并,将宽和高转置到同一个维度,然后进行堆叠,将宽高特征合并在一起,此时我们获得的特征层为:[C, 1, H+W],利用卷积+标准化+激活函数获得特征。
之后再次分开为两个并行阶段,再将宽高分开成为:[C, 1, H]和[C, 1, W],之后进行转置。获得两个特征层[C, H, 1]和[C, 1, W]。
然后利用1x1卷积调整通道数后取sigmoid获得宽高维度上的注意力情况。乘上原有的特征就是CA注意力机制
优点:
准确性高:CA注意力机制能够准确地捕捉不同通道之间的关系,提高了特征表达的准确性。
通用性强:CA注意力机制可以适用于各种不同的网络结构和任务。
缺点:
计算复杂度高:CA模块的计算复杂度较高,特别是在大规模网络中,可能会增加显著的计算开销。
代码
import torch
from torch import nn
class CA_Block(nn.Module):
def __init__(self, channel, reduction=16):
super(CA_Block, self).__init__()
self.conv_1x1 = nn.Conv2d(channel, channel//reduction, kernel_size=1, stride=1, bias=False)
self.relu = nn.ReLU()
self.bn = nn.BatchNorm2d(channel//reduction)
self.F_h = nn.Conv2d(in_channels=channel//reduction, out_channels=channel, kernel_size=1, stride=1, bias=False)
self.F_w = nn.Conv2d(in_channels=channel//reduction, out_channels=channel, kernel_size=1, stride=1, bias=False)
self.sigmoid_h = nn.Sigmoid()
self.sigmoid_w = nn.Sigmoid()
def forward(self, x):
#b,c,h,w
_, _, h, w = x.size()
#(b, c, h, w) --> (b, c, h, 1) --> (b, c, 1, h)
x_h = torch.mean(x, dim=3, keepdim=True).permute(0, 1, 3, 2)
#(b, c, h, w) --> (b, c, 1, w)
x_w = torch.mean(x, dim=2, keepdim=True)
#(b, c, 1, w) cat (b, c, 1, h) ---> (b, c, 1, h+w)
#(b, c, 1, h+w) ---> (b, c/r, 1, h+w)
x_cat_conv_relu = self.relu(self.bn(self.conv_1x1(torch.cat((x_h,x_w), 3))))
#(b, c/r, 1, h+w) ---> (b, c/r, 1, h) 、 (b, c/r, 1, w)
x_cat_conv_split_h, x_cat_conv_split_w = x_cat_conv_relu.split([h,w], 3)
#(b, c/r, 1, h) ---> (b, c, h, 1)
s_h = self.sigmoid_h(self.F_h(x_cat_conv_split_h.permute(0, 1, 3, 2)))
#(b, c/r, 1, w) ---> (b, c, 1, w)
s_w = self.sigmoid_w(self.F_w(x_cat_conv_split_w))
#s_h往宽方向进行扩展, s_w往高方向进行扩展
out = (s_h.expand_as(x) * s_w.expand_as(x)) * x
return out
model = CA_Block(512)
print(model)
inputs = torch.ones([2,512,26,26])
model(inputs)





![[JAVAee]SpringBoot-AOP](https://img-blog.csdnimg.cn/90425924543a410786d19347fcb5ae6c.png)