Shuffle的设计
为什么需要Shuffle?
Shuffle的本质是基于磁盘划分来解决分布式大数据量的全局分组、全局排序、重新分区【增大】 等问题
因为单台机器的资源处理不了分布式大数据量全局分区/排序/分组
所以需要通过Shuffle对每一台机器的数据构建一个Task来做分区的标记(通过Hash或Ranger分区器)这样所有的数据被标记后就可以根据标记进入指定分区,实现全局分区/分组/排序功能
举例说明
假设有一个HDFS文件,分成三个Block块,每台机器上有一个Block
node1-Block1:(a,1)(c,9)(c,6)(d,3)
node2-Block2:(b,4)(a,8)(d,2)
node3-Block3:(b,7)(d,5)
需求:在分布式大数据量计算过程中,需要对所有数据进行全局分组 / 全局排序 / 重新分配
全局分组:相同单词的放在一组
- node1-Block1:(a, [1,8])(c, [9,6])
- node2-Block2:(b, [4,7])
- node3-Block3:(d, [3,2,5])
全局排序:按照整体value降序排序
- node1-Block1:(c,9)(a,8)(b,7)(c,6)
- node2-Block2:(d,5)(b,4)(d,3)
- node3-Block3:(d,2)(a,1)
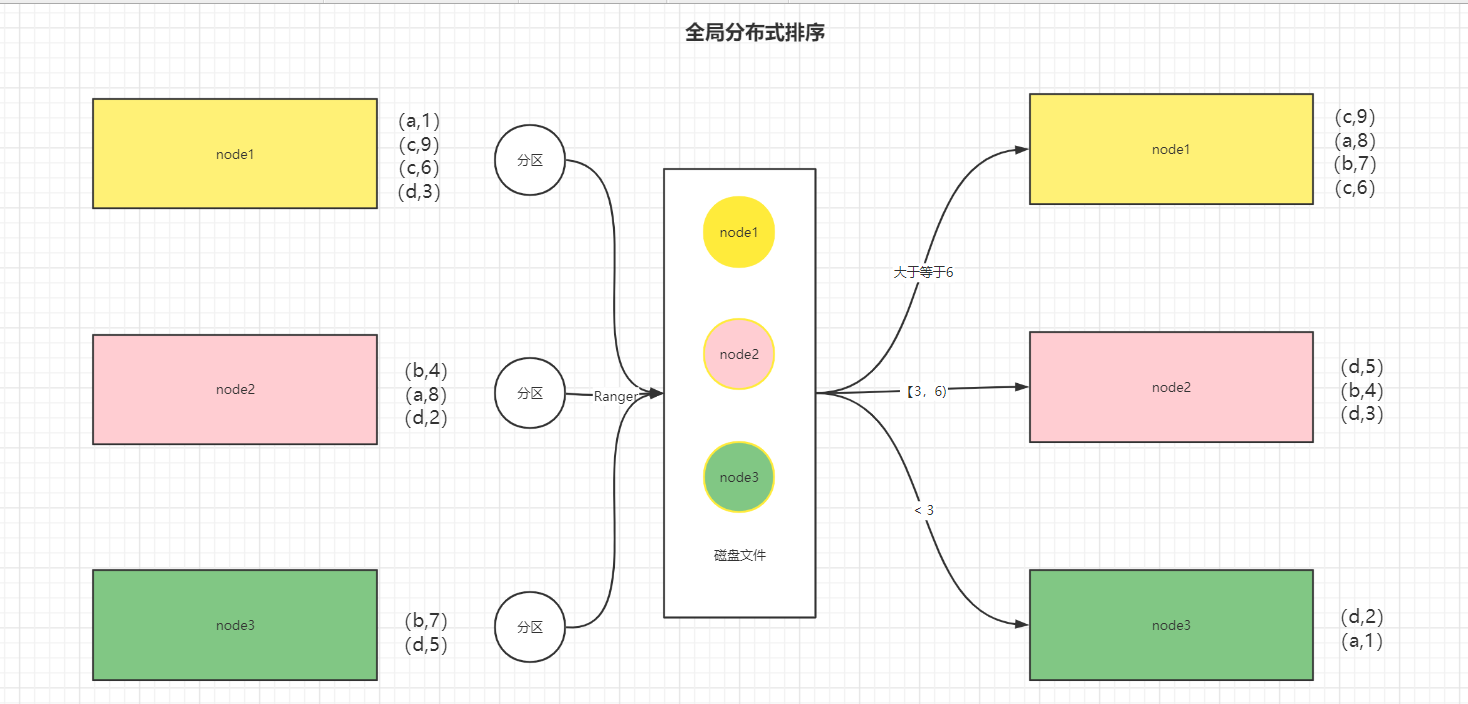
重新分区:数据分配不均衡,希望更加均衡
- node1-Block1:(a,1)(a,8)(d,3)
- node2-Block2:(b,4)(b,7)(d,2)
- node3-Block3:(c,9)(c,6)(d,5)
以上需求,可以在一台机器的内存中实现吗?
答案:不能
因为将多台机器的数据合并到一台机器上,可能会由于数据量过大导致一台机器内存被撑爆
MR的Shuffle过程
阶段:Map端Shuffle、Reduce端Shuffle
功能:分区、排序、分组
目标:Shuffle最终目的是为了做分组,Shuffle=>分组、Reduce=>聚合
问题:MR的Shuffle设计目的是为了做分组,为什么要经过排序,而且是三次排序?
- 第三次排序:为了加快分组的效率
- 第二次排序:为了加快第三次排序的速度,基于有序的合并可以更快
- 第一次排序:为了加快第二次排序的速度
过程:
- Input:负责读取数据,对数据进行切片,将数据转换成KV => K1V1
- Map:负责数据一对一的处理,得到KV => K2V2
- Shuffle:分区、排序、分组
-
Map端Shuffle
- 分区Partition:调用分区器给每条K2V2打上标签,标记这条数据未来会被哪个Reduce进行处理
- 溢写Spill:所有分区好的数据会进入一个内存区域【环形缓冲区100M】,达到阈值80%,会被锁定,做排序,然后溢写
- 排序规则:相同分区的数据放在一起,每个分区内部按照Key升序排序
- 排序算法:快排【小数据量】
- 发生位置:内存
- 溢写:将排序好的数据写入磁盘变成一个有序的小文件
- 合并Merge:每个MapTask会将自己生成的所有小文件整体合并为一个有序的大文件,合并过程中会进行排序
- 排序规则:相同分区的数据放在一起,每个分区内部按照Key升序排序
- 排序算法:归并【基于数据索引的大数据排序算法】
- 发生位置:磁盘
- 产出:每个MapTask最终产生两个文件:1-数据文件,2-索引文件【每个分区的数据在文件的什么位置】
-
Reduce端Shuffle
- 拉取Pull:每个Reduce到每个MapTask的结果文件中读取属于自己那部分数据
- 一个Reduce拿到了多份数据
- 合并Merge:每个Reduce将拉取到的所有数据进行合并,并且排序
- 排序规则:内部按照Key升序排序
- 排序算法:归并【基于数据索引的大数据排序算法】
- 分组Group:按照Key进行分组,将相同K2的V2放入一个列表中
- 拉取Pull:每个Reduce到每个MapTask的结果文件中读取属于自己那部分数据
-
- Reduce:负责对所有Map产生的数据进行聚合
- Output:负责将上一步的结果进行输出