最近看到网上有些文章在讨论JAVA中普通文件IO读/写的时候经过了几次数据拷贝,如果从系统调用开始分析,以读取文件为例,数据的读取过程如下(以缓存I/O为例):
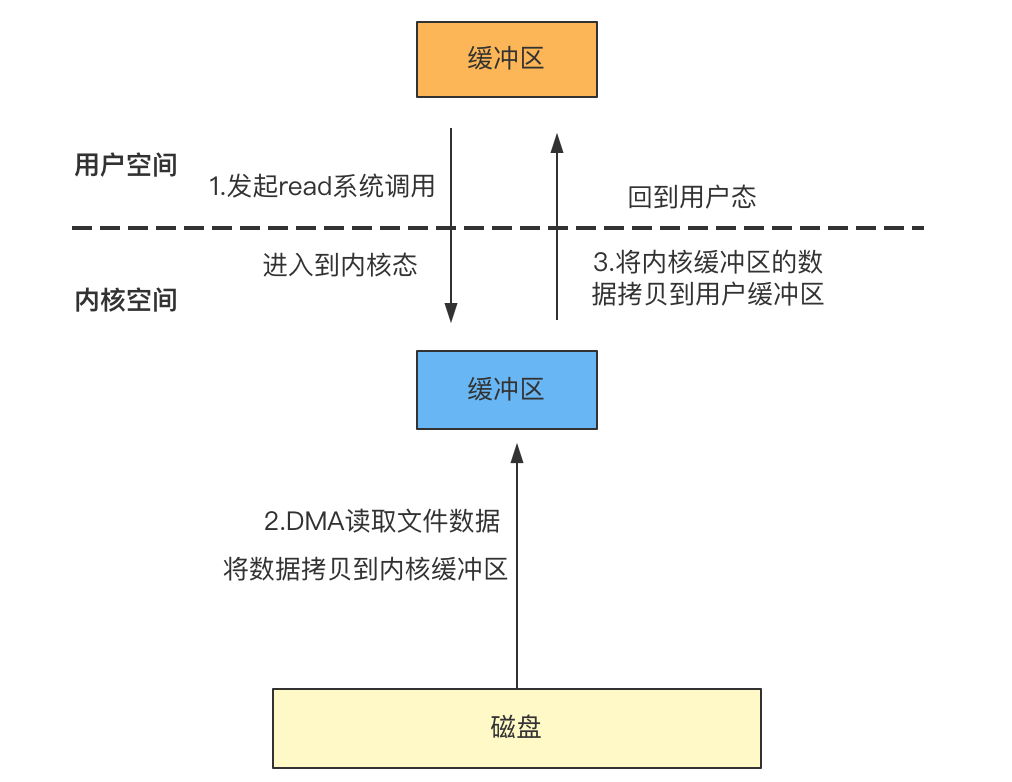
- 应用程序调用read函数发起系统调用,此时由用户空间切换到内核空间;
- 内核通过DMA从磁盘拷贝数据到内核缓冲区;
- 将内核缓冲区的数据拷贝到用户空间的缓冲区,回到用户空间;
整个读取过程发生了两次数据拷贝,一次是DMA将磁盘上的文件数据拷贝到内核缓冲区,一次是将内核缓冲区的数据拷贝到用户缓冲区。
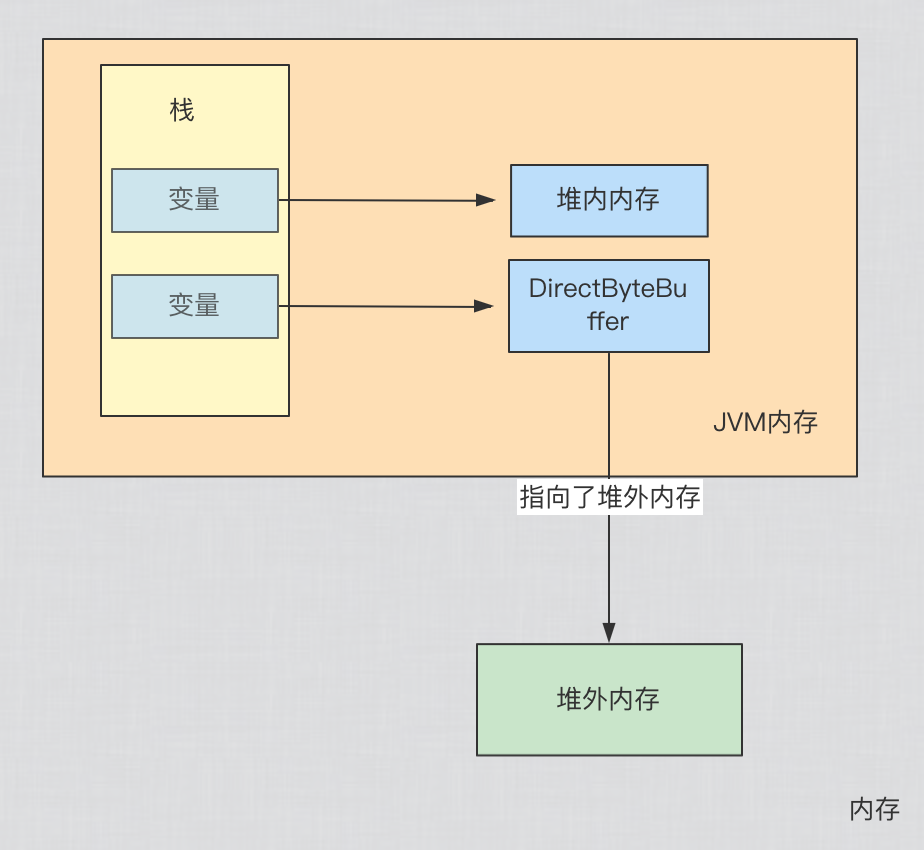
在JAVA中,JVM划分了堆内存,平时创建的对象基本都在堆中,不过也可以通过NIO包下的ByteBuffer申请堆外内存DirectByteBuffer:
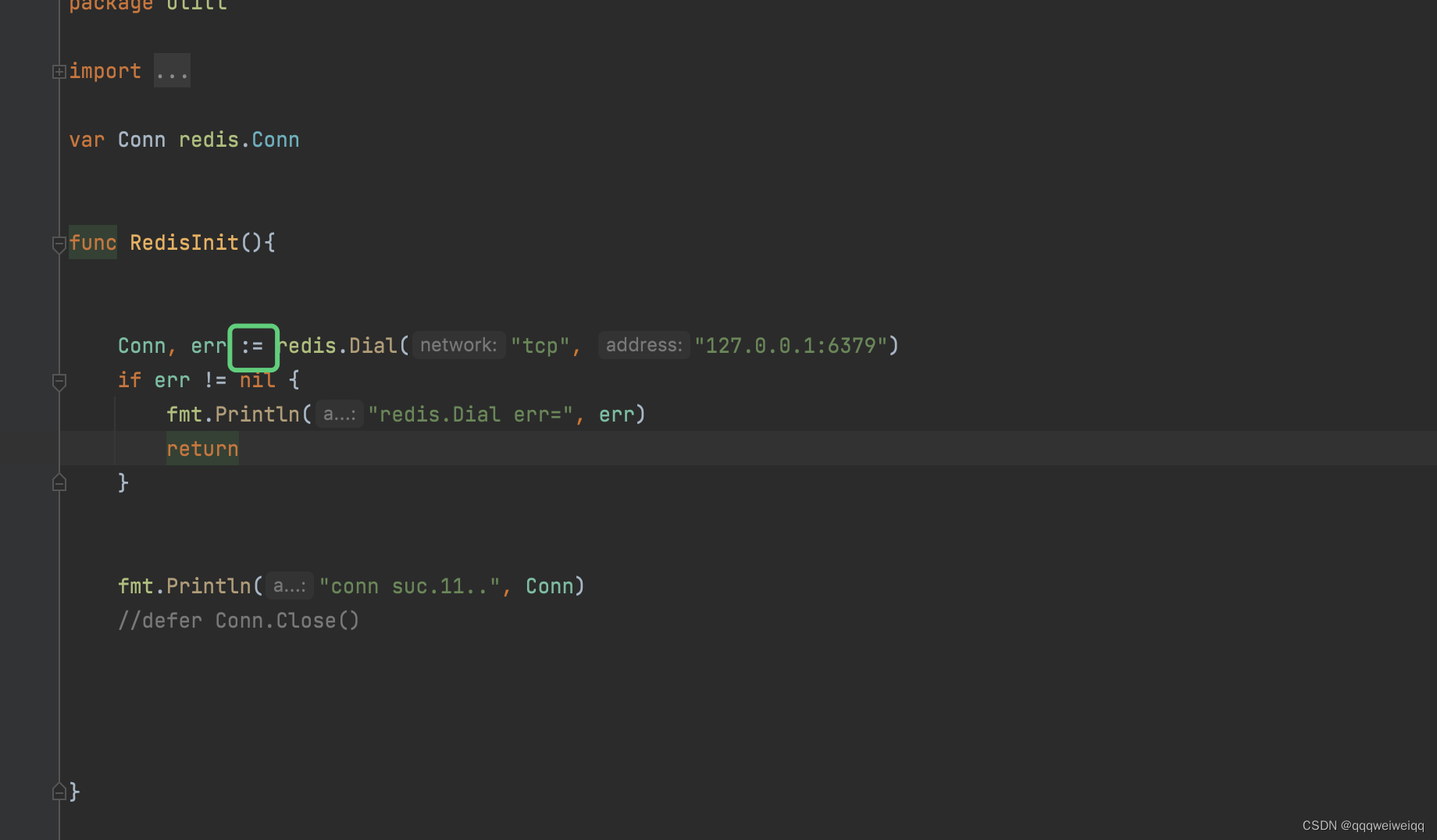
ByteBuffer.allocateDirect(size);
无论是普通IO或者是NIO,在进行文件读写的时候一般都会创建一个buffer作为数据的缓冲区,读写相关方法底层是通过调用native函数(JNI调用)来实现的,在进行读写时将buffer传递给JNI。
JNI一般使用C/C++代码实现,JNI底层调用C函数库时,要求buffer所在内存地址上的内容不能失效,但是JVM在进行垃圾回收的时候有可能对对象进行移动,导致地址发生变化,所以通过NIO进行文件读取的时候,从源码中可以明显看到对buffer的对象类型进行了判断,如果buffer是DirectByteBuffer类型,使用的是堆外内存,直接使用即可,反之则认为使用的是堆内内存,此时需要先申请一块堆外内存作为堆外内存buffer,然后进行系统调用,进行数据读取,读取完毕后将堆外内存buffer的内容再拷回JVM堆内内存buffer中,这里一般是没有疑问的。
比较有疑问的点是在普通IO中,读写文件传入的是字节数组byte[],一种说法是数组一般分配的是连续的内存空间,即使内存地址发生了变化,根据数组的首地址依旧可以找到整个数组的内存,所以使用普通IO进行文件读写的时候,不需要重新分配堆外内存,直接使用堆内的字节数组即可,为了探究普通IO到底有没有重新申请堆外内存,接下来我们去看下源码。
普通IO
首先来看一下使用普通IO进行文件读取的例子,创建一个文件输入流和字节数组,通过输入流读取文件到字节数组中,这里的字节数组占用的是JVM的堆内内存:
// 创建输入流
try (InputStream is = new FileInputStream("/document/123.txt")) {
// 创建字节数组(堆内内存)
byte[] bytes = new byte[1024];
int len = 0;
// 通过read方法读取数据到bytes数组
while ((len = is.read(bytes)) != -1){
String content = new String(bytes, 0, len);
System.out.print(content);
}
is.read(bytes);
} catch (Exception e) {
e.printStackTrace();
}
由于输入流使用的FileInputStream,所以读取文件会进入到FileInputStream中的read方法,可以看到里面又调用了readBytes方法,readBytes是一个native方法,里面传入了三个参数,分别为存放数据的字节数组、读取文件的起始位置和读取数据的长度:
public class FileInputStream extends InputStream {
/**
* 读取数据
*/
public int read(byte b[]) throws IOException {
return readBytes(b, 0, b.length);
}
/**
* 读取字节数据
* @param b 数据读取后放入的字节数组
* @param off 读取起始位置
* @param len 读取数据的长度
* @exception IOException If an I/O error has occurred.
*/
private native int readBytes(byte b[], int off, int len) throws IOException;
}
接下来就需要去readBytes中看下到底有没有使用传入的堆内内存进行数据拷贝,由于readBytes是native方法,所以需要借助openjdk源码来查看具体的实现过程。
openjdk源码下载地址:http://hg.openjdk.java.net/
这里以openjdk1.8为例,看一下readBytes的实现过程。
readBytes方法在源码解压后的src\share\native\java\io\io_util.h文件中,它的处理逻辑如下:
- 创建一个字符数组
stackBuf(堆外内存),大小为BUF_SIZE,从BUF_SIZE的定义中可以看出大小为8192字节 - 对读取数据长度进行判断,如果大于8192,则根据长度重新分配一块内存(堆外内存)作为数据缓冲区赋给
buf变量,如果小于就使用预先分配的字符数组stackBuf赋给buf变量 - 调用
IO_Read函数读取数据到buf变量中,IO_Read函数中进行了系统调用,通过DMA从磁盘读取数据到内核缓冲区 - 调用
SetByteArrayRegion将buf数据拷贝到bytes数组中
从readBytes的处理逻辑来看,并没有直接使用传入的字节数组(堆内内存)进行数据拷贝,而是重新分配了内存,这里分配的是堆外内存,然后进行系统调用从磁盘读取数据到内核缓冲区,再将内核缓冲区的数据拷贝到这里分配的堆外内存中,最后调用SetByteArrayRegion将堆外内存的数据拷贝到堆内内存字节数组中。
/* 最大buffer大小
*/
#define BUF_SIZE 8192
// bytes对应传入的字节数组(堆内内存),off对应起始位置,len对应读取数据的长度
jint
readBytes(JNIEnv *env, jobject this, jbyteArray bytes,
jint off, jint len, jfieldreadBytesID fid)
{
jint nread;
// 创建一个字符数组,大小为BUF_SIZE,这里分配的是堆外内存
char stackBuf[BUF_SIZE];
// 数据缓冲区
char *buf = NULL;
FD fd;
// 校验bytes是否为空
if (IS_NULL(bytes)) {
JNU_ThrowNullPointerException(env, NULL);
return -1;
}
// 校验是否越界
if (outOfBounds(env, off, len, bytes)) {
JNU_ThrowByName(env, "java/lang/IndexOutOfBoundsException", NULL);
return -1;
}
if (len == 0) { // 如果读取数据长度为0直接返回
return 0;
} else if (len > BUF_SIZE) { // 如果读取长度大于BUF_SIZE
buf = malloc(len); // 分配内存(堆外内存)
if (buf == NULL) {
JNU_ThrowOutOfMemoryError(env, NULL);
return 0;
}
} else {
// 使用预先分配的数组
buf = stackBuf;
}
fd = GET_FD(this, fid);
if (fd == -1) {
JNU_ThrowIOException(env, "Stream Closed");
nread = -1;
} else {
// 数据读取
nread = IO_Read(fd, buf, len);
if (nread > 0) {
// 将数据拷贝到堆内内存bytes中
(*env)->SetByteArrayRegion(env, bytes, off, nread, (jbyte *)buf);
} else if (nread == -1) {
JNU_ThrowIOExceptionWithLastError(env, "Read error");
} else { /* EOF */
nread = -1;
}
}
if (buf != stackBuf) {
free(buf);
}
return nread;
}
由于操作系统不同,系统调用的方法也不同,这里以UNIX为例,看下IO_Read函数的具体实现。
IO_Read函数的定义在解压后的src\solaris\native\java\io\io_util_md.h文件中,可以看到IO_Read指向的是handleRead方法:
#define IO_Read handleRead
在handleRead在src\solaris\native\java\io\io_util_md.c中实现,可以看到里面进行了系统调用,通过read函数读取数据:
ssize_t
handleRead(FD fd, void *buf, jint len)
{
ssize_t result;
// 进行系统调用,通过read函数读取数据
RESTARTABLE(read(fd, buf, len), result);
return result;
}
普通IO数据读取流程总结
- 发起JNI调用,创建堆外缓冲区;
- JNI中发起read系统调用,此时需要由用户空间切换到内核空间;
- 进入到内核空间,DMA读取文件数据到内核缓冲区;
- 将内核缓冲区的数据拷贝到用户缓冲区,切换回用户空间;
- 将堆外缓冲区的数据拷贝到JVM堆内缓冲区中;
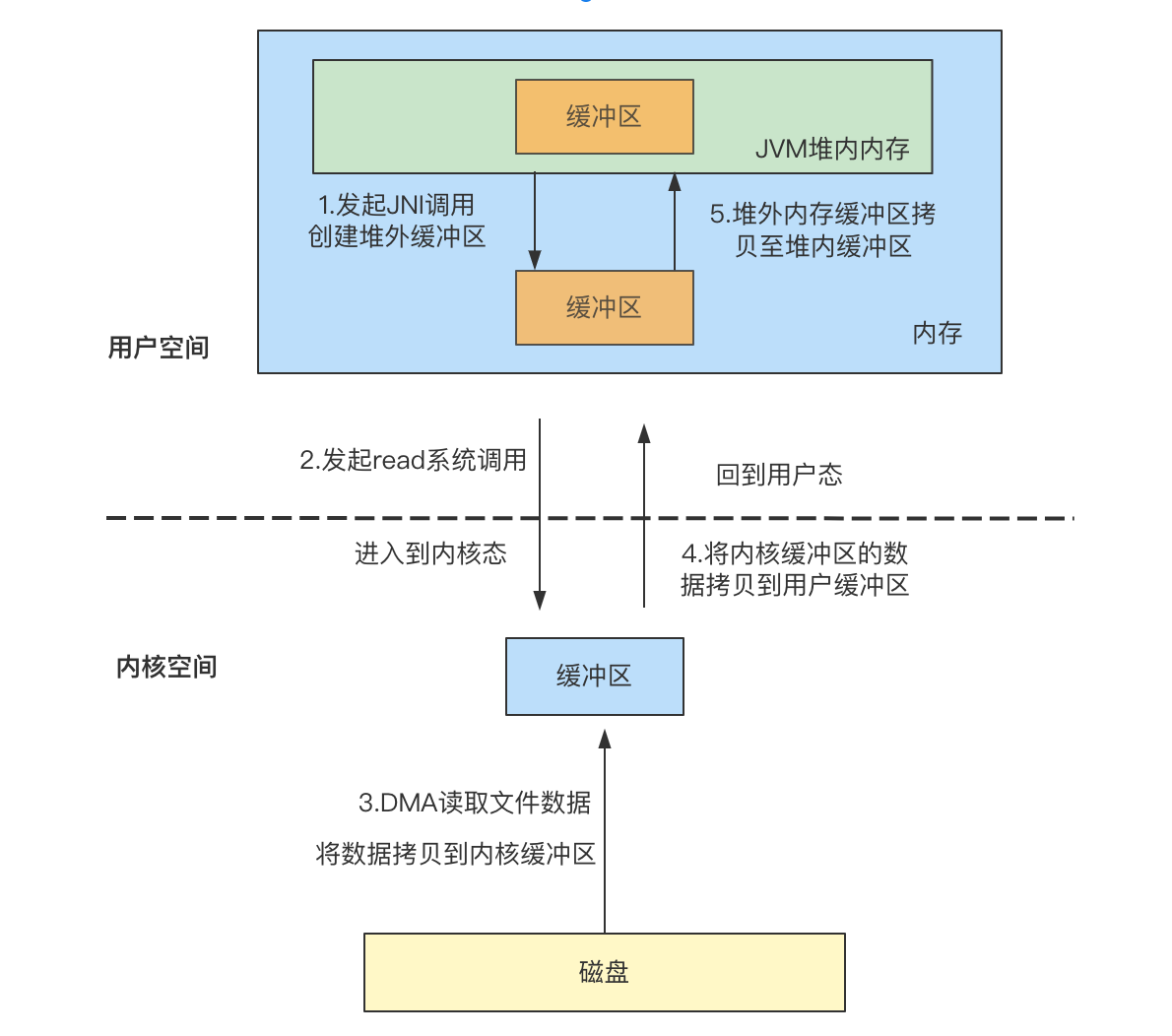
普通IO文件读取过程中并没有因为使用字节数组而减少一次拷贝,读取过程中数据发生了三次拷贝,分别是从DMA读取数据到内核缓冲区、从内核缓冲区拷贝到用户空间的堆外缓冲区和从堆外缓冲区拷贝到JVM堆内缓冲区。
文件写入的逻辑与读取类似,具体可以通过源码查看。
NIO
接下来再来看下NIO读取文件的过程。
使用NIO的FileChannel读取文件的例子:
try (FileInputStream fileInputStream = new FileInputStream("/document/123.txt")) {
// 获取文件对应的channel
FileChannel channel = fileInputStream.getChannel();
// 分配buffer
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 将数据读取到buffer
channel.read(buffer);
} catch (Exception e) {
e.printStackTrace();
}
接下来进入到FileChannelImpl的read方法中,由于jdk中没有sun包下面的源码,IDEA只能通过反编译查看源码,有些参数会是var1、var2…这样的变量名,不便于阅读,所以还可以借助openjdk中的源码来查看实现,当然也可以从网上下载sun包的源码,放入jdk的源码包中。
FileChannelImpl在src/share/classes/sun/nio/ch/FileChannelImpl.java中,里面又是通过IOUtil的read方法读取数据放入buffer中的:
public class FileChannelImpl extends FileChannel {
public int read(ByteBuffer dst) throws IOException {
ensureOpen();
if (!readable)
throw new NonReadableChannelException();
synchronized (positionLock) {
int n = 0;
int ti = -1;
try {
begin();
ti = threads.add();
if (!isOpen())
return 0;
do {
// 通过IOUtil的read方法读取数据,fd为文件描述符,dst为传入的buffer
n = IOUtil.read(fd, dst, -1, nd);
} while ((n == IOStatus.INTERRUPTED) && isOpen());
return IOStatus.normalize(n);
} finally {
threads.remove(ti);
end(n > 0);
assert IOStatus.check(n);
}
}
}
}
IOUtil在src/share/classes/sun/nio/ch/IOUtil.java中,可以看到首先对传入的buffer类型进行了判断:
- 如果是
DirectBuffer,直接调用readIntoNativeBuffer读取数据即可; - 如果不是
DirectBuffer,表示占用的堆内内存,此时需要Util的getTemporaryDirectBuffer申请一块堆外内存,然后调用readIntoNativeBuffer读取数据;
public class IOUtil {
static int read(FileDescriptor fd, ByteBuffer dst, long position,
NativeDispatcher nd)
throws IOException
{
if (dst.isReadOnly())
throw new IllegalArgumentException("Read-only buffer");
// 如果目标buffer是DirectBuffer
if (dst instanceof DirectBuffer)
return readIntoNativeBuffer(fd, dst, position, nd); // 直接读取数据
// 重新分配一块native buffer,也就是堆外内存
ByteBuffer bb = Util.getTemporaryDirectBuffer(dst.remaining());
try {
// 读取数据
int n = readIntoNativeBuffer(fd, bb, position, nd);
bb.flip();
if (n > 0)
dst.put(bb);
return n;
} finally {
Util.offerFirstTemporaryDirectBuffer(bb);
}
}
}
Util在src/share/classes/sun/nio/ch/Util.java中。
在Util中,使用了ThreadLocal缓存了每个线程申请的内存buffer,在调用
getTemporaryDirectBuffer方法获取内存时,首先会根据大小从ThreadLocal中获取是否有满足条件的buffer,如果有直接返回即可,如果大小不够则重新申请,可以看到申请的是堆外内存:
public class Util {
// Per-thread cache of temporary direct buffers
private static ThreadLocal<BufferCache> bufferCache =
new ThreadLocal<BufferCache>()
{
@Override
protected BufferCache initialValue() {
// 初始化,创建一个BufferCache
return new BufferCache();
}
};
/**
* Returns a temporary buffer of at least the given size
*/
public static ByteBuffer getTemporaryDirectBuffer(int size) {
// 先从缓存中获取
BufferCache cache = bufferCache.get();
ByteBuffer buf = cache.get(size);
// 如果获取不为空
if (buf != null) {
return buf;
} else {
// 如果没有合适的buffer则重新申请
if (!cache.isEmpty()) {
buf = cache.removeFirst();
free(buf);
}
// 申请堆外内存
return ByteBuffer.allocateDirect(size);
}
}
}
ByteBuffer的allocateDirect方法返回的是DirectByteBuffer:
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer>
public static ByteBuffer allocateDirect(int capacity) {
// 创建DirectByteBuffer
return new DirectByteBuffer(capacity);
}
}
参考
Java NIO direct buffer的优势在哪儿?
JAVA IO专题一:java InputStream和OutputStream读取文件并通过socket发送,到底涉及几次拷贝



![[React] Zustand状态管理库](https://img-blog.csdnimg.cn/199d8d74875d4e598f33a97e0c20312d.png)