摘要
SPD-Conv是一种新的构建块,用于替代现有的CNN体系结构中的步长卷积和池化层。它由一个空间到深度(SPD)层和一个非步长卷积(Conv)层组成。
空间到深度(SPD)层的作用是将输入特征图的每个空间维度降低到通道维度,同时保留通道内的信息。这可以通过将输入特征图的每个像素或特征映射到一个通道来实现。在这个过程中,空间维度的大小会减小,而通道维度的大小会增加。
非步长卷积(Conv)层是一种标准的卷积操作,它在SPD层之后进行。与步长卷积不同,非步长卷积不会在特征图上移动,而是对每个像素或特征映射进行卷积操作。这有助于减少在SPD层中可能出现的过度下采样问题,并保留更多的细粒度信息。
SPD-Conv的组合方式是将SPD层和Conv层串联起来。具体来说,输入特征图首先通过SPD层进行转换,然后输出结果再通过Conv层进行卷积操作。这种组合方式可以在不丢失信息的情况下减少空间维度的尺寸,同时保留通道内的信息,有助于提高CNN对低分辨率图像和小型物体的检测性能。
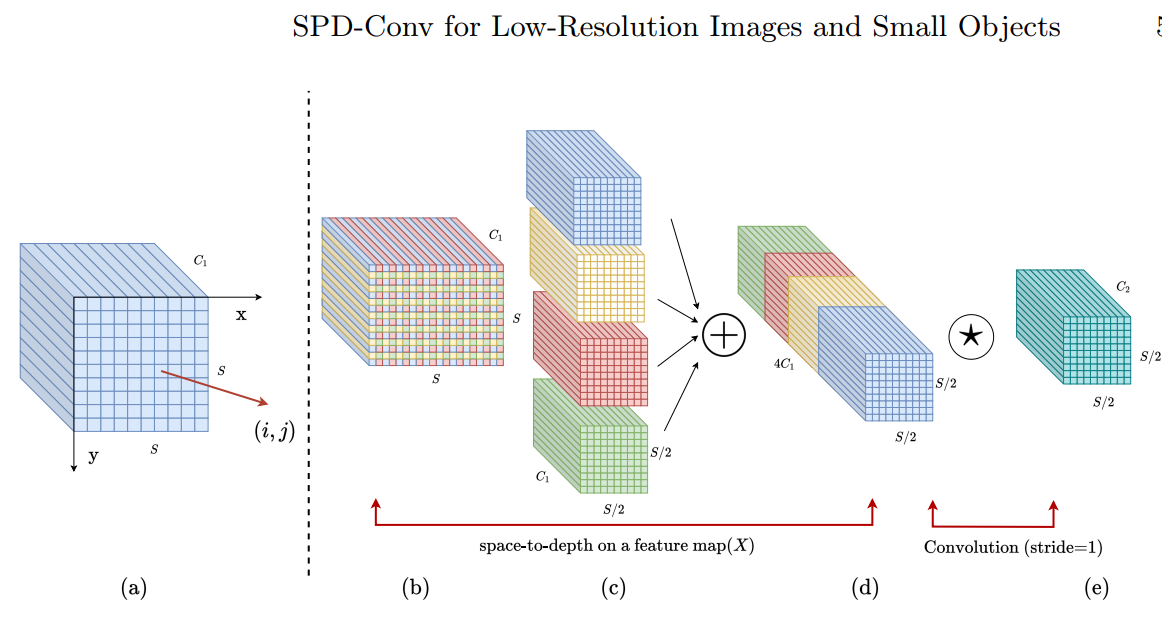
总结起来,SPD-Conv是一种新的构建块,旨在解决现有CNN体系结构中步长卷积和池化层的问题。它由一个空间到深度(SPD)层和一个非步长卷积(Conv)层组成,能够提高模型对低分辨率图像和小型物体的检测性能,并降低对“良好质量”输入的依赖。
优势
将SPD-Conv应用于YOLO v5和ResNet创建的新CNN架构有以下优势&#x





](https://img-blog.csdnimg.cn/34f25434e13641d3a138f929d859c0fc.png)