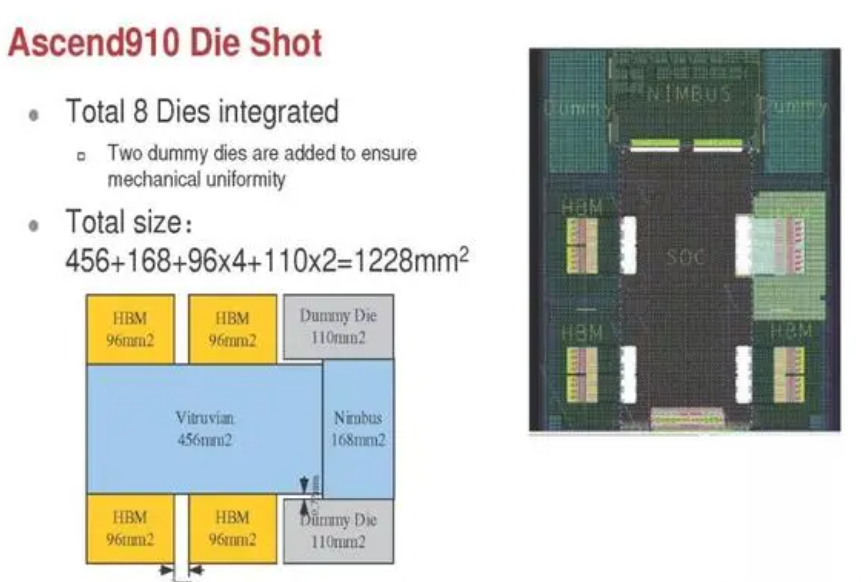
VR渲染的独特和最明显的方面之一是需要生成两个视图,左右眼睛各一个。我们需要这两个视图来为观众创建立体3D效果。
Multi Camera

传统上,VR应用程序必须绘制两次几何体--一次是左眼,一次是右眼。这基本上使非VR应用程序所需的处理翻了一番。
要显示每只眼睛的视图,最简单的方法是运行两次渲染循环。每个眼睛都将配置并经历自己的渲染循环迭代。最后,我们将有两个图像,我们可以发送到显示设备。底层实现使用两个Unity相机,每只眼睛一个,它们经历生成立体图像的过程。

虽然这种方法肯定有效,但多摄像头依赖于暴力,在CPU和GPU方面效率最低。CPU必须完全迭代两次渲染循环,GPU可能无法使用两次被拉到眼睛上的对象的缓存。
Multi Pass

Multi Pass是优化XR渲染循环的方法之一。核心思想是提取渲染循环中与视图无关的部分。这意味着,任何不明确依赖XR视图的工作都不必每只眼睛完成。
此优化最明显的的优化方向之一是阴影渲染。阴影并不明确独立于相机查看器的位置。Unity实际上通过两个步骤实现阴影:创建级联阴影贴图,然后将阴影分配给屏幕空间。对于Multi-Pass,我们可以创建一组级联阴影贴图,然后为屏幕创建两个阴影贴图,因为屏幕空间的阴影贴图取决于查看器的位置。由于我们的阴影生成的体系结构,屏幕空间的阴影贴图受益于局部性,因为阴影贴图生成循环耦合相对紧密。这可以与剩余的渲染工作流进行比较,后者需要在渲染循环上完成迭代,然后返回到类似的阶段(例如,眼睛特定的不透明过程被剩余的渲染循环阶段分开)。
另一个可以在两只眼睛之间分裂的步骤一开始可能并不明显:我们可以在两只眼睛之间做一次扑杀。在我们的第一个实现中,我们使用截头剔除来生成两个对象列表,每只眼睛一个。然而,我们可以创造一个均匀的扑杀脸,在我们的两只眼睛之间分开。这意味着每只眼睛都比单眼剔除截头要多一些,但我们已经考虑了单次排序的好处,以超过一些额外的顶点着色器、剪裁和筛选的成本。
Multi Pass比多摄像头节省了一些很好的费用,但还有更多的事情要做。
Multi Camera与Multi Pass虽然在性能上差了一些,但有一个好处就是在于不会对shader进行侵入式修改。
Single Pass
Single Pass渲染意味着我们对整个渲染循环进行渲染一次,能够提高性能。
要进行这两个绘制,我们需要确保我们有所有的常量数据和索引绑定。
渲染引擎怎样draw呢?在Multi Pass中,每个眼睛都有自己的渲染目标,但对于Single Pass,我们不能这样做,因为为连续的绘制调用切换渲染目标的成本也是极大的。一种优化思路是使用渲染目标数组,但我们必须从大多数平台上的几何着色器导出数组索引,这在GPU上可能很昂贵,对于现有着色器来说也是侵入性的。
当前的解决方案是使用双宽渲染目标,并在绘制调用之间切换视口,以便每只眼睛都可以渲染到双宽渲染目标的一半。更改视口成本也高昂,但比更改渲染目标更低复杂,也比使用几何着色器更低侵入性。还有使用视口数组的相关选项,但它们与渲染目标数组存在相同的问题,因为索引只能从几何着色器导出。还有另一种使用动态剪裁的技术,我们在这里就不讨论了。
现在,我们有了一个解决方案,可以开始连续两次draw,以看到两只眼睛,但是需要硬件上支持。使用Single-Pass,我们不希望在恒定缓冲区绑定之间不必要地切换。相反,我们将两只眼睛的视觉矩阵和投影矩阵联系在一起,并使用StereoEyeIndex索引它们。
另一个细节:要最大限度地减少Viewport和unity_StereoEyeIndex状态更改,我们可以更改眼睛绘制模式。我们可以画左、右、右、左等,而不是画左、右、左、右等。使用节奏。这允许我们将状态更新的数量与交替节奏相比减少一半。
性能这并不完全是Multi Pass的两倍。对剔除和阴影进行了优化,而且我们仍在通过眼睛发送绘制和切换视口,这导致了一些CPU和GPU成本。
在OpenGL中,使用glTexImage3DMultisample赋值双宽度纹理数组
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE_ARRAY, framebufferDesc.m_nRenderTextureId);
glTexImage3DMultisample(GL_TEXTURE_2D_MULTISAMPLE_ARRAY, 4, GL_RGBA8, nWidth, nHeight, 2, GL_FALSE);我们来看看OpenGL的具体实现方式:
struct FramebufferDescSPS
{
GLuint m_nDepthBufferId;
GLuint m_nRenderTextureId;
GLuint m_nRenderFramebufferId;
GLuint m_nCombinedFramebufferId[2]; // framebuffer where we will render each layer separately
GLuint m_nReadFramebufferId; // needed to bind the texture layers for the blit
GLuint m_nResolveTextureId[2];
GLuint m_nResolveFramebufferId[2];
};
bool CreateFrameBufferSPS( int nWidth, int nHeight, FramebufferDescSPS &framebufferDesc )
{
glGenFramebuffers(1, &framebufferDesc.m_nRenderFramebufferId );
glBindFramebuffer(GL_FRAMEBUFFER, framebufferDesc.m_nRenderFramebufferId);
glGenTextures(1, &framebufferDesc.m_nDepthBufferId);
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE_ARRAY, framebufferDesc.m_nDepthBufferId);
glTexImage3DMultisample(GL_TEXTURE_2D_MULTISAMPLE_ARRAY, 4, GL_DEPTH_COMPONENT24, nWidth, nHeight, 2, GL_FALSE);
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE_ARRAY, 0);
glGenTextures(1, &framebufferDesc.m_nRenderTextureId);
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE_ARRAY, framebufferDesc.m_nRenderTextureId);
glTexImage3DMultisample(GL_TEXTURE_2D_MULTISAMPLE_ARRAY, 4, GL_RGBA8, nWidth, nHeight, 2, GL_FALSE);
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE_ARRAY, 0);
// check FBO status
GLenum status = glCheckFramebufferStatus(GL_FRAMEBUFFER);
if (status != GL_FRAMEBUFFER_COMPLETE)
{
return false;
}
glBindFramebuffer( GL_FRAMEBUFFER, 0 );
return true;
}
shader中需要加入扩展,#extension GL_NV_viewport_array2: require
#extension GL_NV_stereo_view_rendering: require
我们传入的时候需要传入左右眼的MVP
m_unSceneProgramIDSPS = CompileGLShader(
"Scene",
// Vertex Shader
"#version 410\n"
"#extension GL_ARB_shading_language_include : enable\n"
"#extension GL_NV_viewport_array2: require\n"
"#extension GL_NV_stereo_view_rendering: require\n"
"layout(secondary_view_offset=1) out highp int gl_Layer;\n"
"uniform mat4 matrixEyeLeft;\n"
"uniform mat4 matrixEyeRight;\n"
"layout(location = 0) in vec4 position;\n"
"layout(location = 1) in vec2 v2UVcoordsIn;\n"
"layout(location = 2) in vec3 v3NormalIn;\n"
"out vec2 v2UVcoords;\n"
"void main()\n"
"{\n"
" v2UVcoords = v2UVcoordsIn;\n"
" gl_Position = matrixEyeLeft * position;\n"
" gl_SecondaryPositionNV = matrixEyeRight * position;\n"
" gl_Layer = 0;\n"
"}\n",
// Fragment Shader
"#version 410 core\n"
"uniform sampler2D mytexture;\n"
"uniform bool combinedMode;\n"
"in vec2 v2UVcoords;\n"
"out vec4 outputColor;\n"
"void main()\n"
"{\n"
" outputColor = texture(mytexture, v2UVcoords);\n"
" if (combinedMode) {\n"
" outputColor *= vec4(1.0f, 0.5f, 0.5f, 1.0f);\n"
" }\n"
"}\n"
);
Single Pass Instanced
之前,我们提到了使用渲染目标数组的可能性。渲染目标数组是立体渲染的自然解决方案。眼睛纹理共享格式和大小,并限定它们在渲染目标数组中使用。但是使用几何着色器导出数组切片是一个很大的缺点。我们真正想要的是能够从顶点着色器导出渲染目标数组索引,以更容易集成和更好的性能。
从顶点着色器导出渲染目标数组索引的能力实际上存在于某些GPU和API中,并且变得越来越普遍。在DX11上,此功能作为功能选项VPAndRTArrayIndexFromAnyShaderFeingRasterizer提供。
现在我们可以确定我们将在渲染目标数组的哪个切片上渲染,我们如何选择切片?我们使用现有的单通双宽基础架构。我们可以使用unity_StereoEyeIndex填充着色器中的SV_RenderTargetArrayIndex语义。在API端,我们不再需要切换视口,因为同一视口可以用于渲染目标数组的两个切片。我们已经将矩阵配置为可从顶点着色器索引。
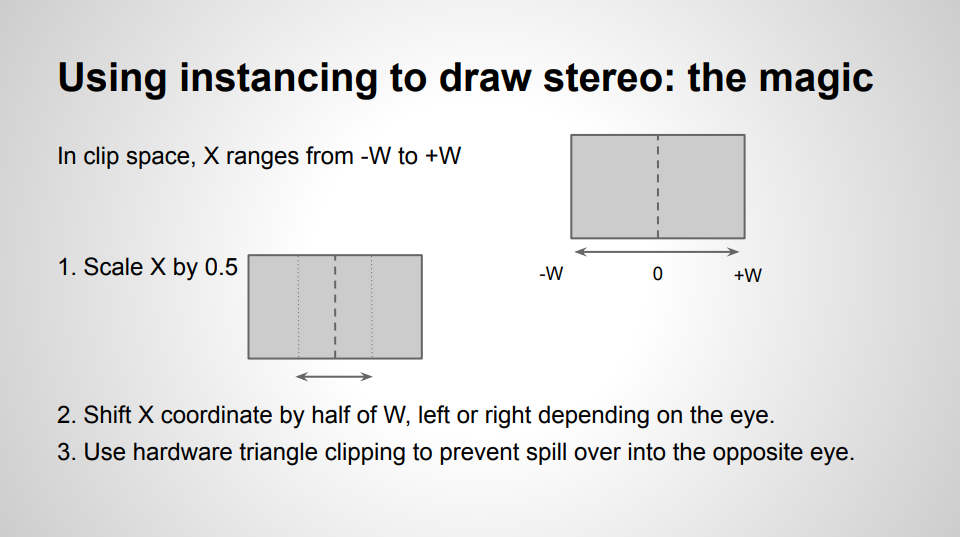
虽然我们仍然可以使用现有的技术,输出两个绘制并在每次绘制之前切换恒定缓冲区中的unity_StereoEyeIndex值,但有一种有效的技术。我们可以使用GPU实例发送单个绘制调用,并允许GPU通过两只眼睛倍增我们的绘制。我们可以将现有的draw实例数量翻一番。然后,我们可以解码顶点着色器中的实例ID,以确定我们要渲染到哪个眼睛。
使用此技术的最大影响是,我们将在API端生成的绘制调用数量减少了一半,节省了部分CPU时间。此外,GPU本身能够更有效地处理绘制,即使生成了相同的工作量,因为它不需要处理两个单个绘制调用。我们还通过不必在绘制之间更改视口来最大限度地减少状态更新,就像我们使用传统的单通道技术所做的那样。
GPU Instance的具体使用方法可以参考LearnOpenGL - Instancing
我们看看咋使用GPU Instance实现Single Pass Instanced




Multi View
虚拟现实应用程序需要从不同的视角渲染所有场景两次,以创造深度的错觉。通过简单地使用不同的视图和透视矩阵渲染所有内容两次来执行此操作并不是最佳的,因为它需要多次设置一个基本相同的绘制调用。GL_OVR_multiview 扩展通过允许一个绘制调用渲染到数组纹理的多个纹理层来解决这个问题,从而消除了设置多个绘制调用的开销。然后,为附着的数组纹理中的每个纹理层调用一次顶点和片段着色器,并可以访问变量g_ViewID_OVR,该变量可用于为每个图层选择视图相关输入。使用此机制,可以使用视图和投影矩阵数组而不是单个矩阵,着色器可以使用g_ViewID_OVR为每个图层选择正确的矩阵,允许一个绘制调用从多个眼睛位置渲染,而开销很少。
Multi-View是某些OpenGL/OpenGL ES实现的扩展,其中驱动程序本身在两只眼睛上多路复用单个绘制调用。驱动程序不显式实例化绘制调用并将实例解码为着色器中的眼睛索引,而是负责复制绘制并在着色器中创建数组索引(通过g_ViewID)。
有一个与立体实例不同的底层实现细节:驱动程序本身确定渲染目标,而不是显式选择要光栅化的渲染目标数组层的顶点着色器。g_ViewID用于计算视图相关状态,而不是选择渲染目标。在使用中,它对开发人员来说并不起什么作用,但它是一个有趣的细节。
我们看看Multi View在OpenGL ES的实现方法:
1、设置多视图帧缓冲区对象
在使用扩展之前,应检查它是否可用,这可以使用以下代码完成,该代码查找GL_OVR_multiview 扩展。如果需要,类似的代码可用于检查GL_OVR_multiview2 或GL_OVR_multiview_multisampled_render_to_texture 扩展。
const GLubyte* extensions = GL_CHECK(glGetString(GL_EXTENSIONS));
char * found_extension = strstr ((const char*)extensions, "GL_OVR_multiview");
if (NULL == found_extension)
{
LOGI("OpenGL ES 3.0 implementation does not support GL_OVR_multiview extension.\n");
exit(EXIT_FAILURE);
}但是,即使支持扩展,也可能在GL标头中无法使用gFramebufferTextureMultiviewOVR函数。如果是这种情况,可以使用eglGetProc访问函数,如以下代码所示。
typedef void (*PFNGLFRAMEBUFFERTEXTUREMULTIVIEWOVR)(GLenum, GLenum, GLuint, GLint, GLint, GLsizei);
PFNGLFRAMEBUFFERTEXTUREMULTIVIEWOVR glFramebufferTextureMultiviewOVR;
glFramebufferTextureMultiviewOVR =
(PFNGLFRAMEBUFFERTEXTUREMULTIVIEWOVR)eglGetProcAddress ("glFramebufferTextureMultiviewOVR");
if (!glFramebufferTextureMultiviewOVR)
{
LOGI("Can not get proc address for glFramebufferTextureMultiviewOVR.\n");
exit(EXIT_FAILURE);
}如果此调用成功,则可以将gFramebufferTextureMultiviewOVR用作普通的gl函数。
下面的代码设置了一个帧缓冲区对象,以便渲染到多视图。颜色附着和深度附着都是具有2层的数组纹理,并且在此帧缓冲区对象上使用的每个绘制调用都将渲染到这两个层。重要的是,所有附件的层数必须相同,否则帧缓冲区将不完整。帧缓冲区对象必须绑定到GL_Draw_FRAMEBFER,否则gFramebufferTextureMultiviewOVR调用将给出一个无效操作错误。为帧缓冲区对象设置的视图数与绘制时当前着色器程序中声明的视图数匹配也很重要,否则绘制调用将给出无效操作错误。下一节将展示如何创建可用于多视图渲染的着色器程序。
bool setupFBO(int width, int height)
{
// Create array texture
GL_CHECK(glGenTextures(1, &frameBufferTextureId));
GL_CHECK(glBindTexture(GL_TEXTURE_2D_ARRAY, frameBufferTextureId));
GL_CHECK(glTexParameteri(GL_TEXTURE_2D_ARRAY, GL_TEXTURE_MIN_FILTER, GL_LINEAR));
GL_CHECK(glTexParameteri(GL_TEXTURE_2D_ARRAY, GL_TEXTURE_MAG_FILTER, GL_LINEAR));
GL_CHECK(glTexStorage3D(GL_TEXTURE_2D_ARRAY, 1, GL_RGBA8, width, height, 2));
/* Initialize FBO. */
GL_CHECK(glGenFramebuffers(1, &frameBufferObjectId));
/* Bind our framebuffer for rendering. */
GL_CHECK(glBindFramebuffer(GL_DRAW_FRAMEBUFFER, frameBufferObjectId));
/* Attach texture to the framebuffer. */
GL_CHECK(glFramebufferTextureMultiviewOVR(GL_DRAW_FRAMEBUFFER, GL_COLOR_ATTACHMENT0,
frameBufferTextureId, 0, 0, 2));
/* Create array depth texture */
GL_CHECK(glGenTextures(1, &frameBufferDepthTextureId));
GL_CHECK(glBindTexture(GL_TEXTURE_2D_ARRAY, frameBufferDepthTextureId));
GL_CHECK(glTexStorage3D(GL_TEXTURE_2D_ARRAY, 1, GL_DEPTH_COMPONENT24, width, height, 2));
/* Attach depth texture to the framebuffer. */
GL_CHECK(glFramebufferTextureMultiviewOVR(GL_DRAW_FRAMEBUFFER, GL_DEPTH_ATTACHMENT,
frameBufferDepthTextureId, 0, 0, 2));
/* Check FBO is OK. */
GLenum result = GL_CHECK(glCheckFramebufferStatus(GL_DRAW_FRAMEBUFFER));
if (result != GL_FRAMEBUFFER_COMPLETE)
{
LOGE("Framebuffer incomplete at %s:%i\n", __FILE__, __LINE__);
/* Unbind framebuffer. */
GL_CHECK(glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0));
return false;
}
return true;
}2、在着色器中使用多视图渲染到多个图层
以下代码显示了用于多视图渲染的着色器。只有顶点着色器包含多视图特定的代码。它启用GL_OVR_multiview扩展,并将布局中的num_views变量设置为2。此数量需要与使用gFramebufferTextureMultiviewOVR附加到帧缓冲区的视图数量相同。着色器采用视图投影矩阵数组(视图和投影矩阵相乘),而不是仅采用一个,并通过使用g_ViewID_OVR索引来选择要使用的矩阵,该索引给出了要渲染到的当前纹理层的索引。这允许我们为不同的图层拥有不同的相机位置和投影,使我们可以在VR应用程序中从两个眼睛位置进行渲染,只需一次绘制调用。在这种情况下,只有一个模型矩阵,因为模型不会为不同的层移动。在这种情况下,只有g_Position受g_ViewID_OVR值的影响,这意味着此着色器只需要GL_OVR_multiview扩展,而不需要GL_OVR_multiview2扩展。为了也根据g_ViewID_OVR(或其他顶点输出)更改法线,需要GL_OVR_multiview2。
#version 300 es
#extension GL_OVR_multiview : enable
layout(num_views = 2) in;
in vec3 vertexPosition;
in vec3 vertexNormal;
uniform mat4 modelViewProjection[2];
uniform mat4 model;
out vec3 v_normal;
void main()
{
gl_Position = modelViewProjection[gl_ViewID_OVR] * vec4(vertexPosition, 1.0);
v_normal = (model * vec4(vertexNormal, 0.0f)).xyz;
}
#version 300 es
precision mediump float;
in vec3 v_normal;
out vec4 f_color;
vec3 light(vec3 n, vec3 l, vec3 c)
{
float ndotl = max(dot(n, l), 0.0);
return ndotl * c;
}
void main()
{
vec3 albedo = vec3(0.95, 0.84, 0.62);
vec3 n = normalize(v_normal);
f_color.rgb = vec3(0.0);
f_color.rgb += light(n, normalize(vec3(1.0)), vec3(1.0));
f_color.rgb += light(n, normalize(vec3(-1.0, -1.0, 0.0)), vec3(0.2, 0.23, 0.35));
f_color.a = 1.0;
}该程序可以以与任何其他程序相同的方式设置。viewProjection矩阵必须设置为矩阵数组均匀,如下代码所示。在这个例子中,投影矩阵是相同的,但对于VR,通常会为每只眼睛使用不同的投影矩阵。本教程后面的示例将渲染到2个以上的层,并将在每个层使用不同的透视矩阵,这就是这里有多个透视矩阵的原因。在这种情况下,相机位置在x方向上设置为-1.5和1.5,两者都位于场景的中心。
/* M_PI_2 rad = 90 degrees. */
projectionMatrix[0] = Matrix::matrixPerspective(M_PI_2, (float)width / (float)height, 0.1f, 100.0f);
projectionMatrix[1] = Matrix::matrixPerspective(M_PI_2, (float)width / (float)height, 0.1f, 100.0f);
/* Setting up model view matrices for each of the */
Vec3f leftCameraPos = {-1.5f, 0.0f, 4.0f};
Vec3f rightCameraPos = {1.5f, 0.0f, 4.0f};
Vec3f lookAt = {0.0f, 0.0f, -4.0f};
Vec3f upVec = {0.0f, 1.0f, 0.0f};
viewMatrix[0] = Matrix::matrixCameraLookAt(leftCameraPos, lookAt, upVec);
viewMatrix[1] = Matrix::matrixCameraLookAt(rightCameraPos, lookAt, upVec);
modelViewProjectionMatrix[0] = projectionMatrix[0] * viewMatrix[0] * modelMatrix;
modelViewProjectionMatrix[1] = projectionMatrix[1] * viewMatrix[1] * modelMatrix;
multiviewModelViewProjectionLocation = GL_CHECK(glGetUniformLocation(multiviewProgram, "modelViewProjection"));
multiviewModelLocation = GL_CHECK(glGetUniformLocation(multiviewProgram, "model"));
/* Upload matrices. */
GL_CHECK(glUniformMatrix4fv(multiviewModelViewProjectionLocation, 2, GL_FALSE, modelViewProjectionMatrix[0].getAsArray()));
GL_CHECK(glUniformMatrix4fv(multiviewModelLocation, 1, GL_FALSE, modelMatrix.getAsArray()));在绑定多视图帧缓冲区对象时,使用此程序渲染的任何内容都将从不同的视角渲染到两个纹理层,而不必执行多次绘制调用。在将VR场景渲染为每只眼睛的单独层之后,现在需要将结果渲染到屏幕上。通过绑定纹理并将其作为2D数组纹理渲染,可以轻松完成此操作。对于VR应用程序,可以设置两个视口,对于每个视口,相关纹理图层将渲染到屏幕上。这可以是将纹理简单地斑点到屏幕上,也可以在显示纹理之前对纹理执行过滤或其他后处理操作。由于纹理是数组,纹理采样操作需要vec3纹理坐标,其中最后一个坐标索引到数组中。为了使每个绘制调用选择不同的图层,可以提供具有图层索引的统一,如以下片段着色器中所示。
#version 300 es
precision mediump float;
precision mediump int;
precision mediump sampler2DArray;
in vec2 vTexCoord;
out vec4 fragColor;
uniform sampler2DArray tex;
uniform int layerIndex;
void main()
{
fragColor = texture(tex, vec3(vTexCoord, layerIndex));
}性能分析
Single Pass和Single Pass Instance代表了与Multi Pass相比的有着显著CPU优势。这是因为切换到Single Pass已经节省了大部分CPU开销。
Single Pass Instance减少了绘制调用的数量,但与场景图的处理相比,这些成本相当低。
考虑到大多数现代图形驱动程序都是多线程的,绘制调用的输出可以在调度CPU线程上相当快地完成。
参考文献:
https://github.com/ikapoura/single-pass-stereo-with-openvr
Single Pass Stereo: is it worth it? – Learning by creating
VRWorks - Single Pass Stereo | NVIDIA Developer
LearnOpenGL - Instancing
Calculating Stereo Pairs
VRWorks - Multi-View Rendering (MVR) | NVIDIA Developer
https://gitea.yiem.net/QianMo/Real-Time-Rendering-4th-Bibliography-Collection/raw/branch/main/Chapter%201-24/[1891]%20[SDVR%202015]%20High%20Performance%20Stereo%20Rendering%20for%20VR.pdf
Turing Multi-View Rendering in VRWorks | NVIDIA Technical Blog