1. Hibench
官网
HiBench is a big data benchmark suite that helps evaluate different big data frameworks in terms of speed, throughput and system resource utilizations. It contains a set of Hadoop, Spark and streaming workloads, including Sort, WordCount, TeraSort, Repartition, Sleep, SQL, PageRank, Nutch indexing, Bayes, Kmeans, NWeight and enhanced DFSIO, etc. It also contains several streaming workloads for Spark Streaming, Flink, Storm and Gearpump.
1.1 workloads
There are totally 29 workloads in HiBench. The workloads are divided into 6 categories which are micro, ml(machine learning), sql, graph, websearch and streaming.
1.2 install maven
首先需要安装maven,并配好环境安装教程
mkdir repo
cd conf
vim settings.xml
修改仓库地址
<localRepository>/opt/module/maven/apache-maven-3.8.6/repo</localRepository>
阿里云镜像文件中已经有了,注释掉其他mirror
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
1.3 bulid
下载zip文件,上传解压后的文件 不要使用7.11 会出现版本问题
参照文档中的,构建HiBench项目,我使用的是全部安装:
#ALL
mvn -Dspark=3.1 -Dscala=2.12 clean package
#SPARK
mvn -Psparkbench -Dspark=3.1 -Dscala=2.12 clean package
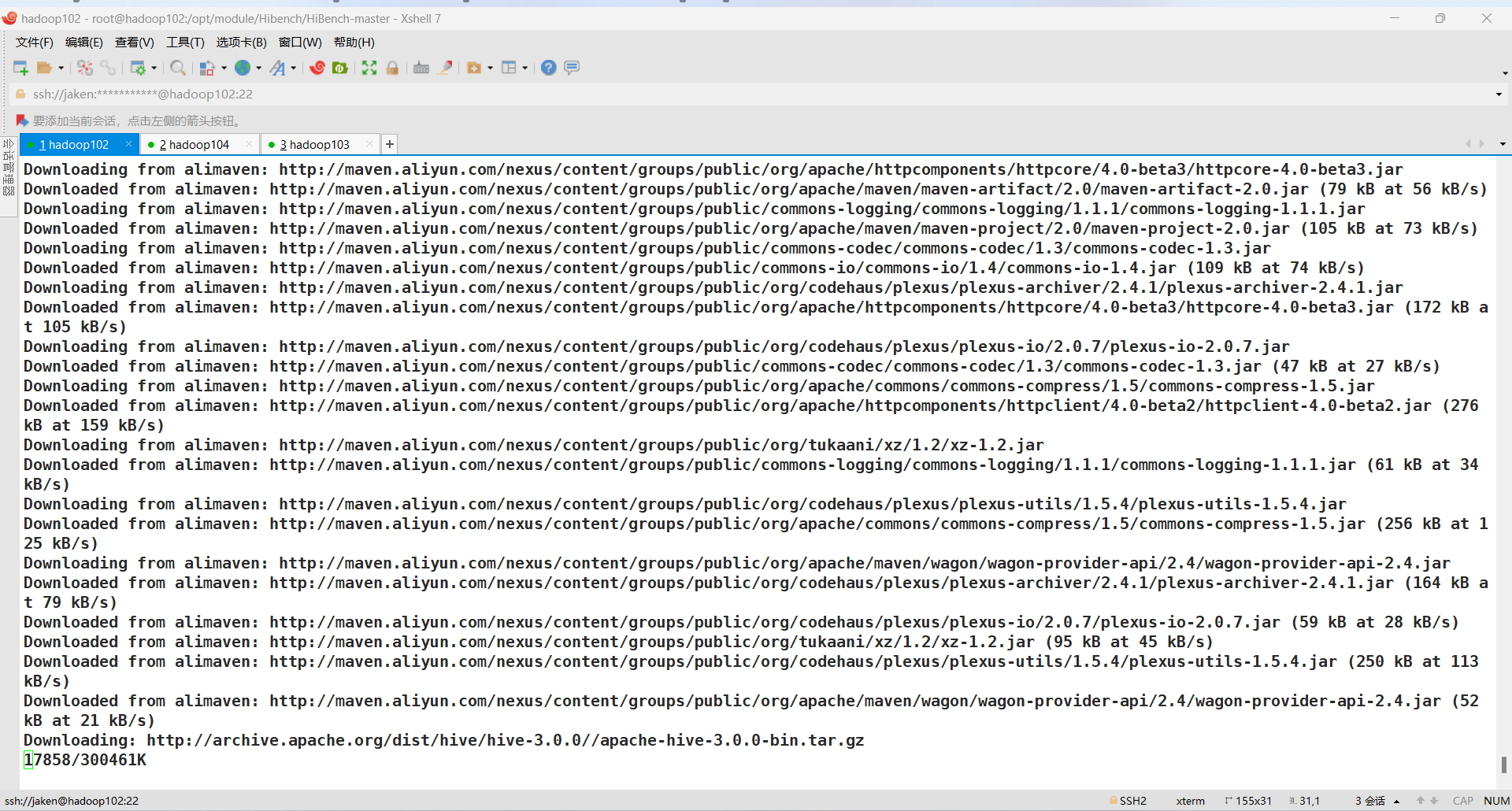
如果出现以下错误:
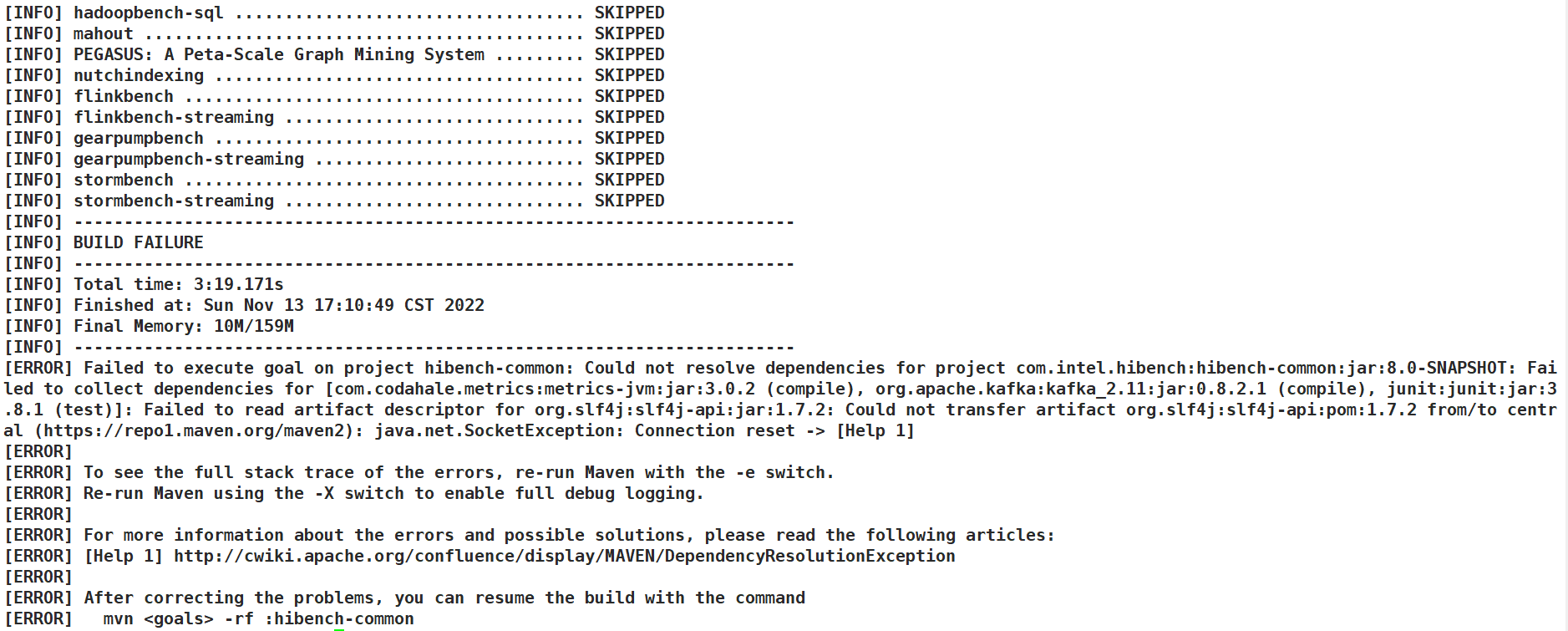
原因是maven没有安装好,没有设置好镜像以及安装仓库,详情见安装教程
build成功
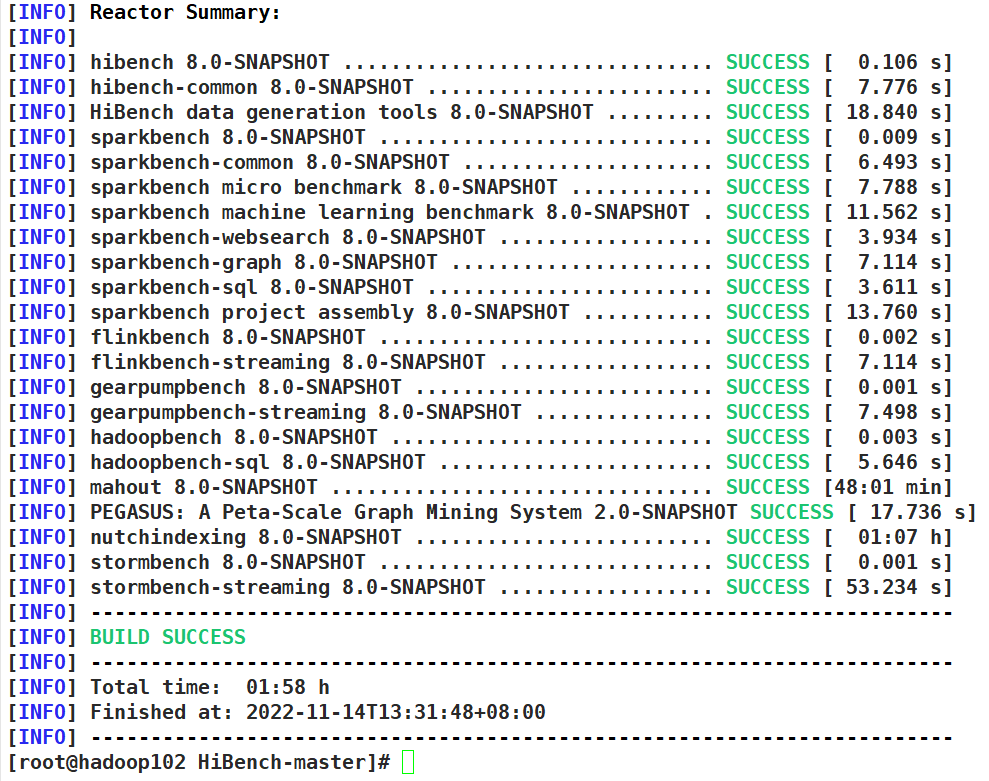
第二次
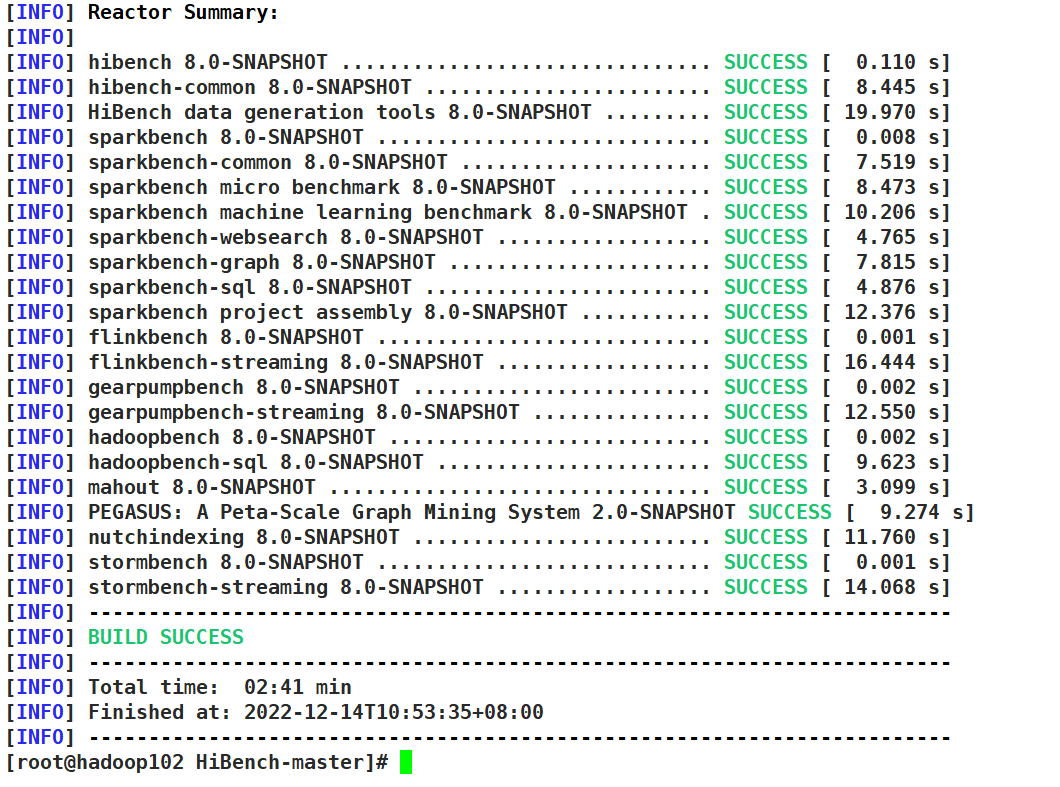
1.4 configure
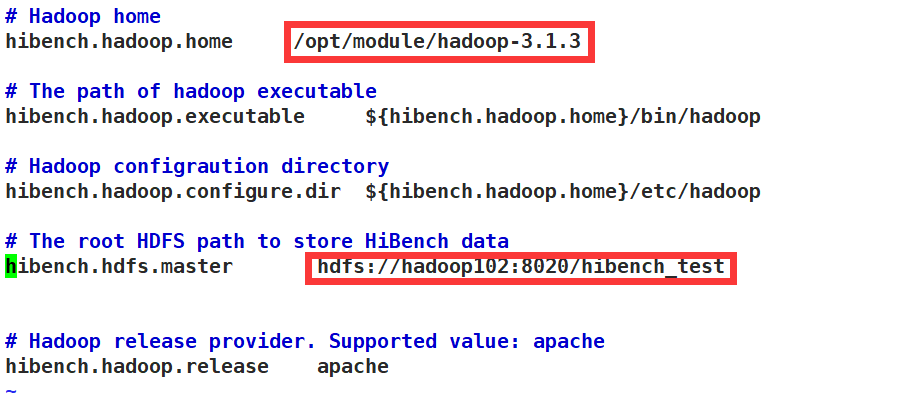
hadoop.conf
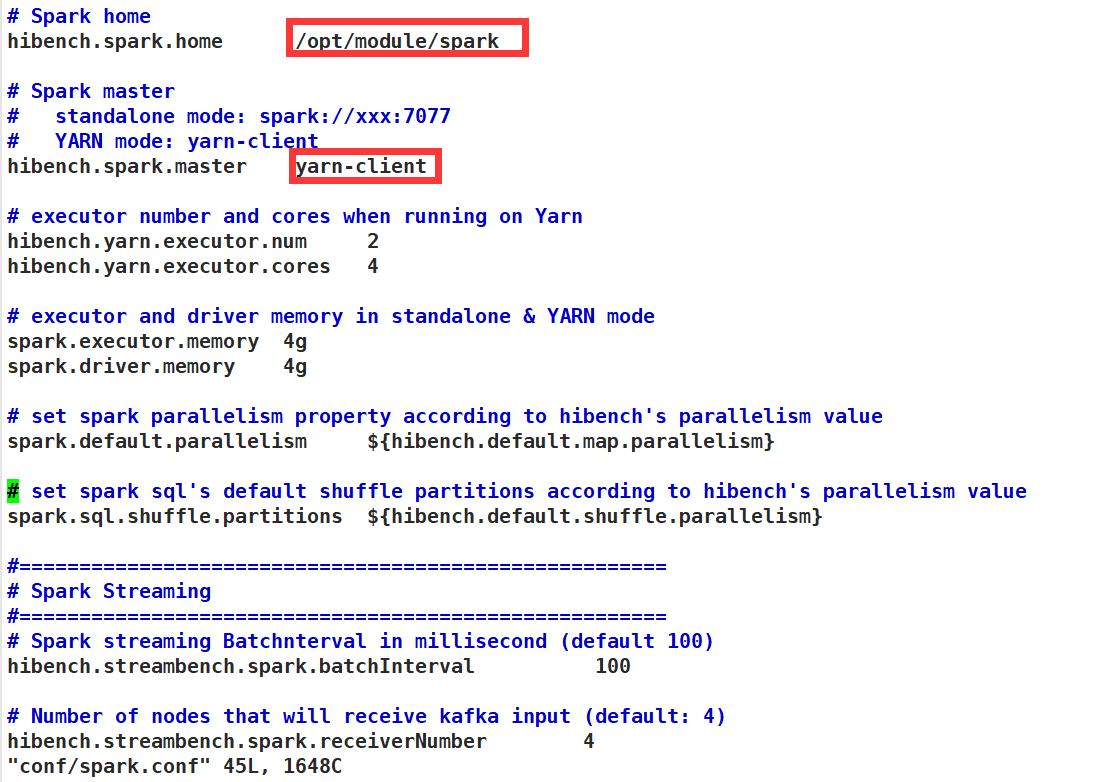
spark.conf
Input data size

if you chose a real large data size ,you may find the errors:
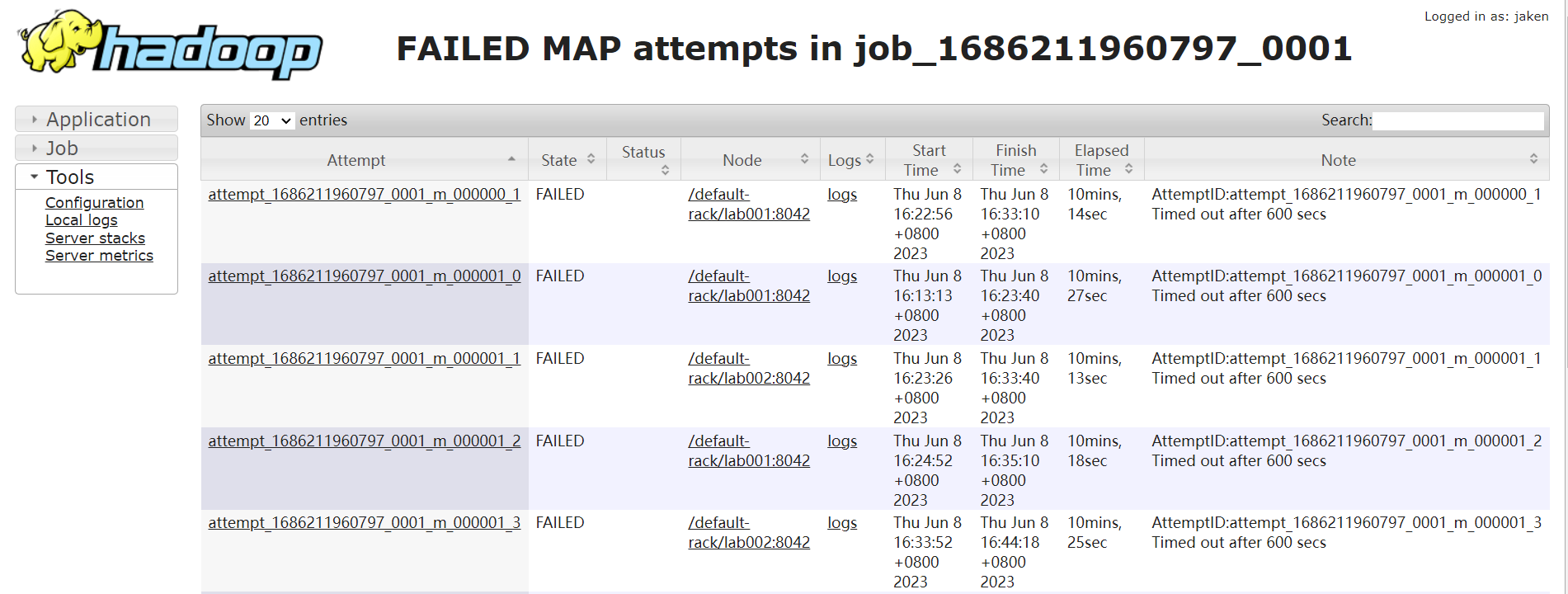

you need to modify the mapred-site.xml, and add the context:
<property>
<name>mapred.task.timeout</name>
<value>800000</value>
<final>true</final>
</property>
cluster mode
vim /opt/module/hibench/HiBench-master/HiBench-master/bin/functions/workload_functions.sh
# 修改run_spark_job 方法

1.5 hadoop example
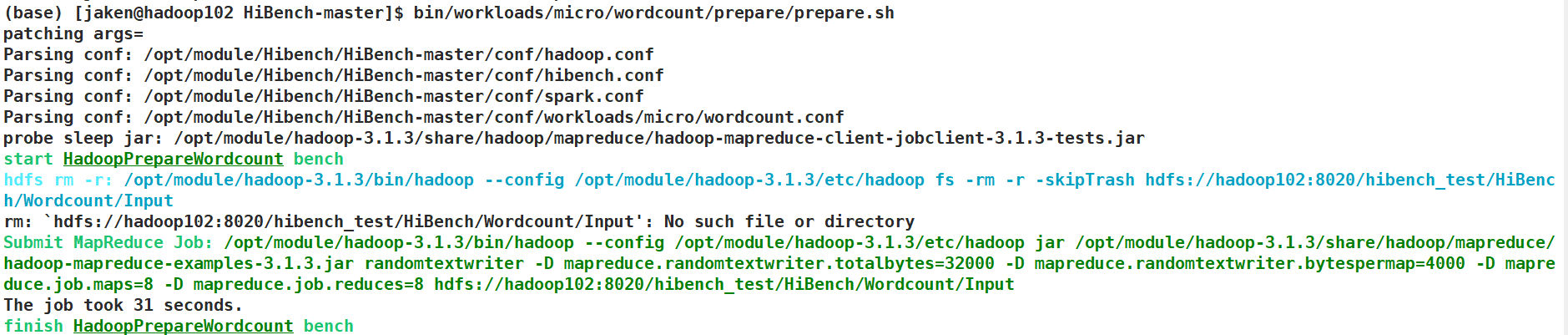
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/wordcount/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/wordcount/hadoop/run.sh
官网地址
运行成功
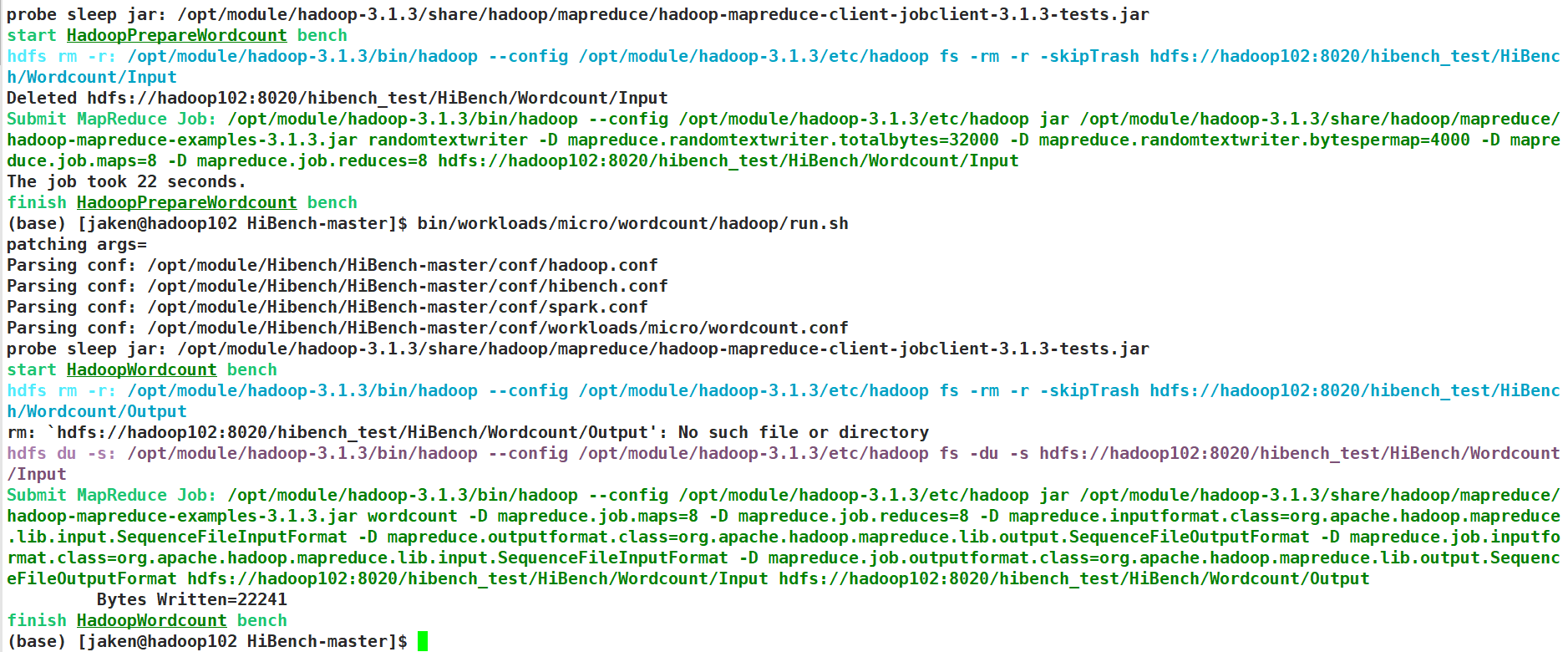

更详细的介绍
/opt/module/Hibench/HiBench-master/report/wordcount/hadoop
1.6 spark example
准备输入数据
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/wordcount/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/terasort/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/sort/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/kmeans/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/bayes/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/lr/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/websearch/pagerank/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/graph/nweight/prepare/prepare.sh
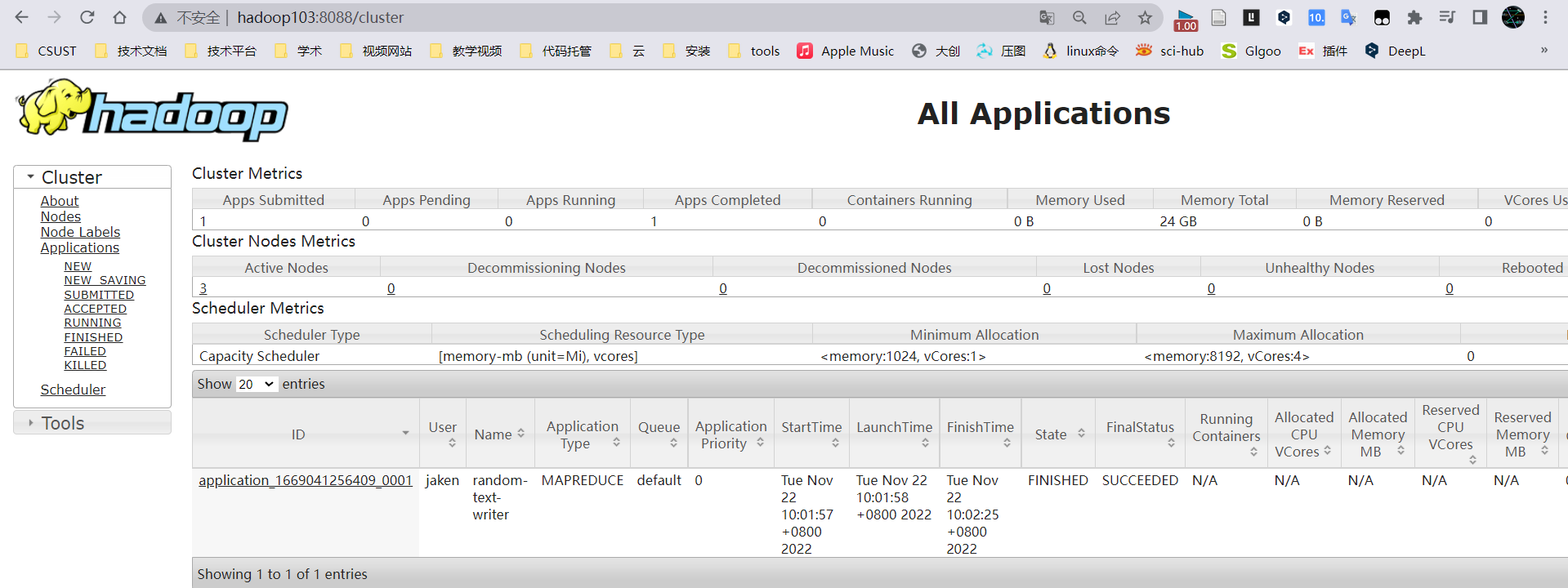
控制台输出
yarn
进入HDFS查看准备的输入数据
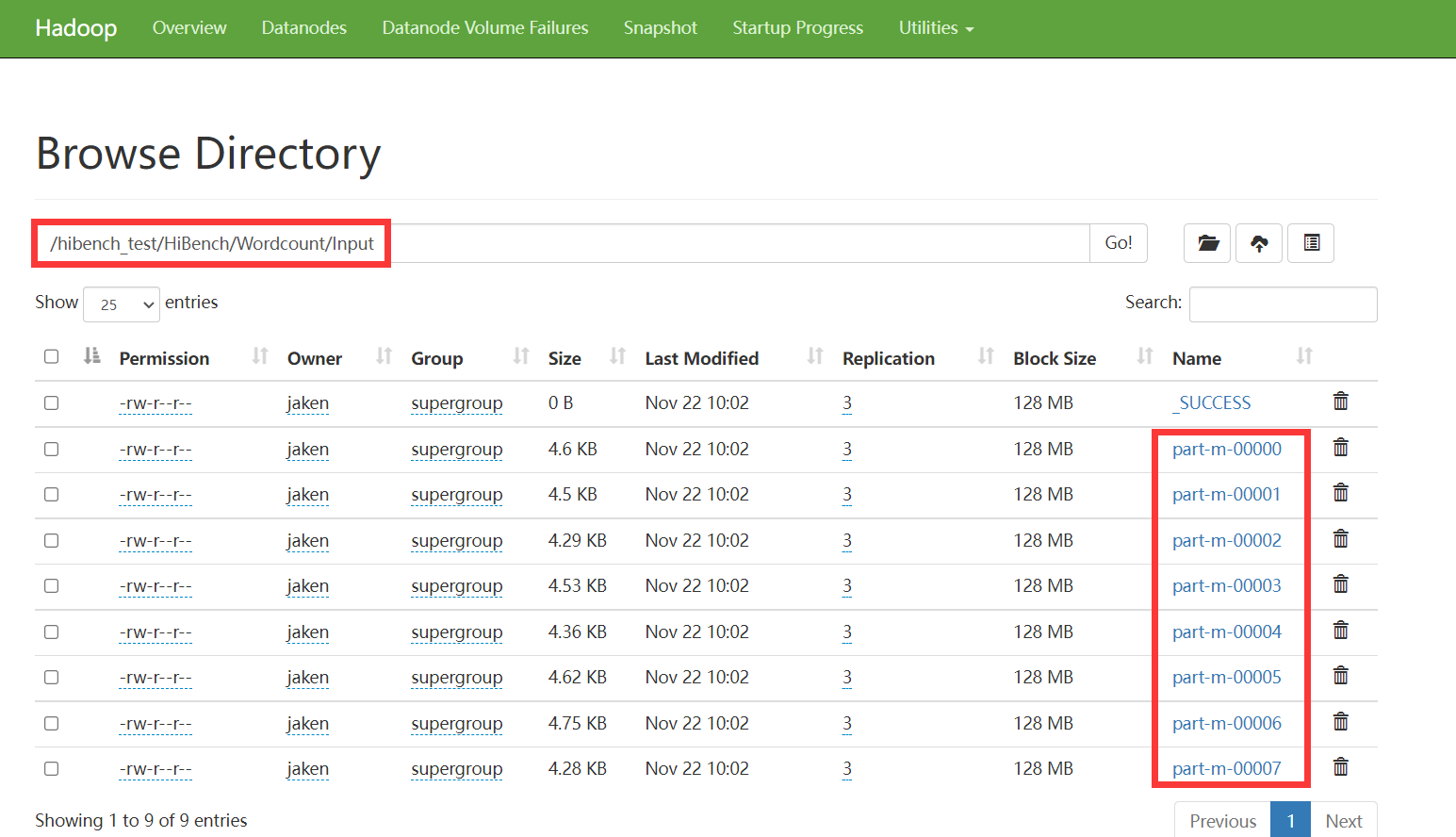
准备命令
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/wordcount/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/terasort/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/sort/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/kmeans/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/bayes/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/lr/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/websearch/pagerank/prepare/prepare.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/graph/nweight/prepare/prepare.sh
注意jar文件夹中不要包含其他备用的jar包
运行命令
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/wordcount/spark/run.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/terasort/spark/run.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/sort/spark/run.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/kmeans/spark/run.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/bayes/spark/run.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/lr/spark/run.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/websearch/pagerank/spark/run.sh
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/graph/nweight/spark/run.sh

成功!
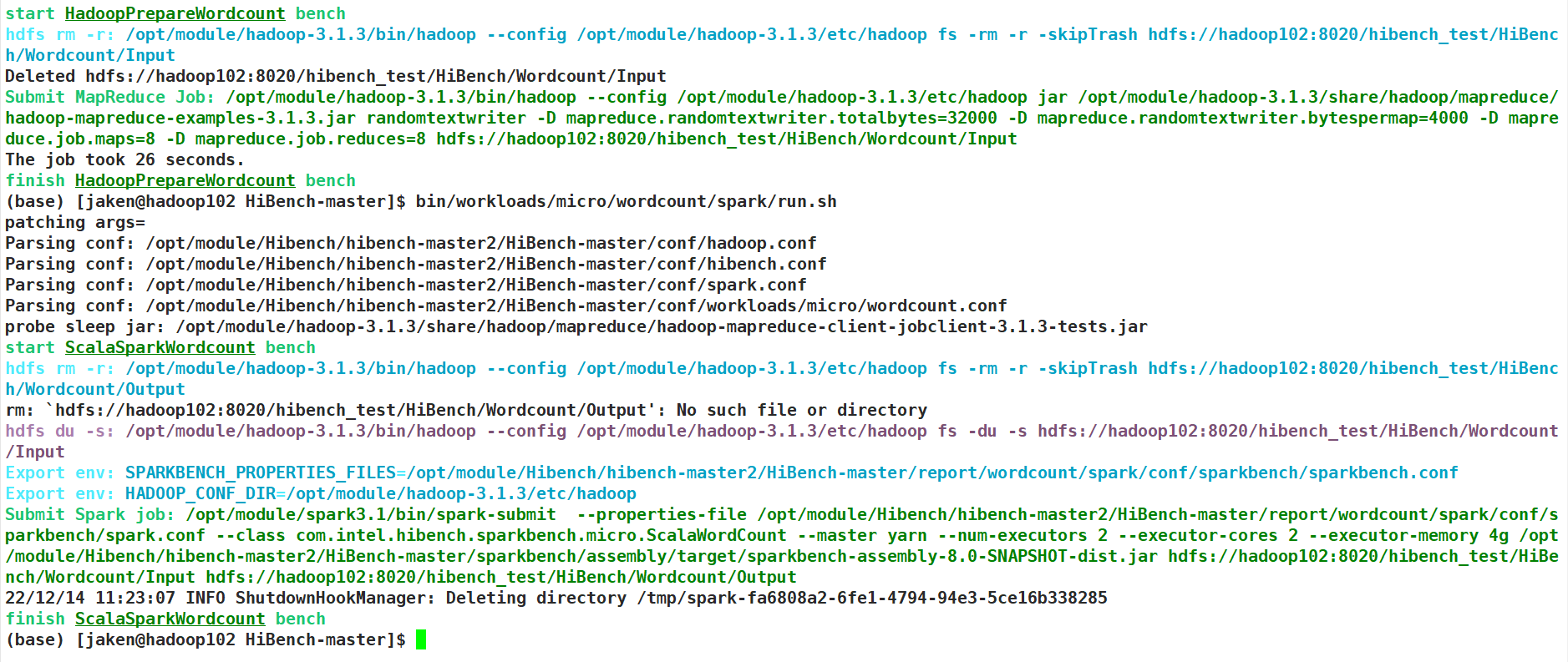
结果
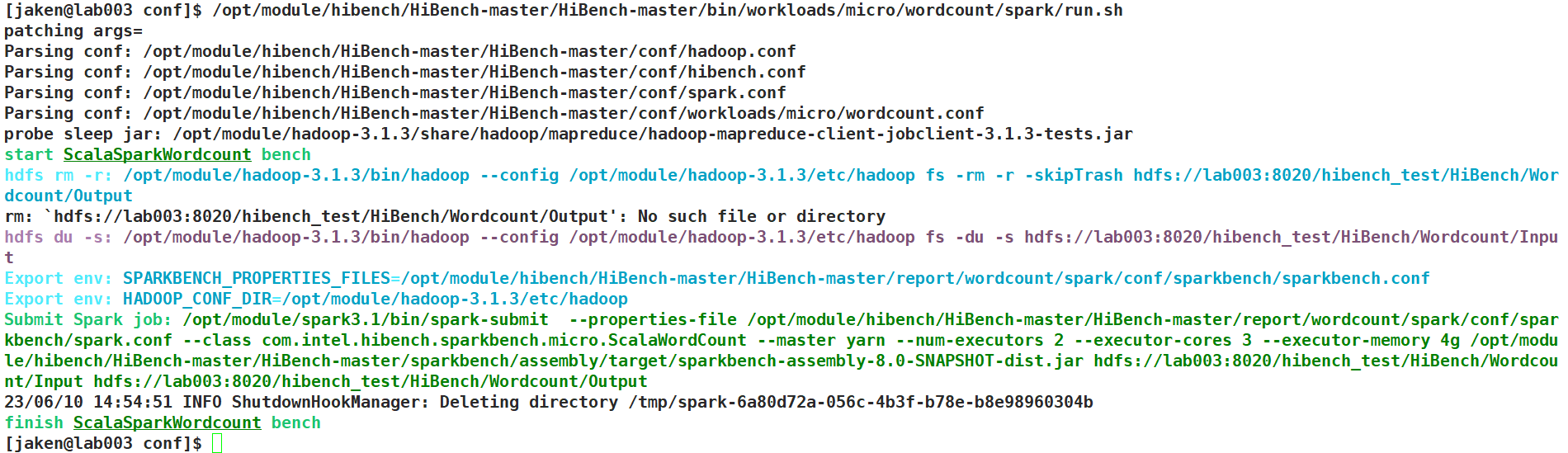
trouble
网络配置问题
所有任务在yarn上都用的是内网IP
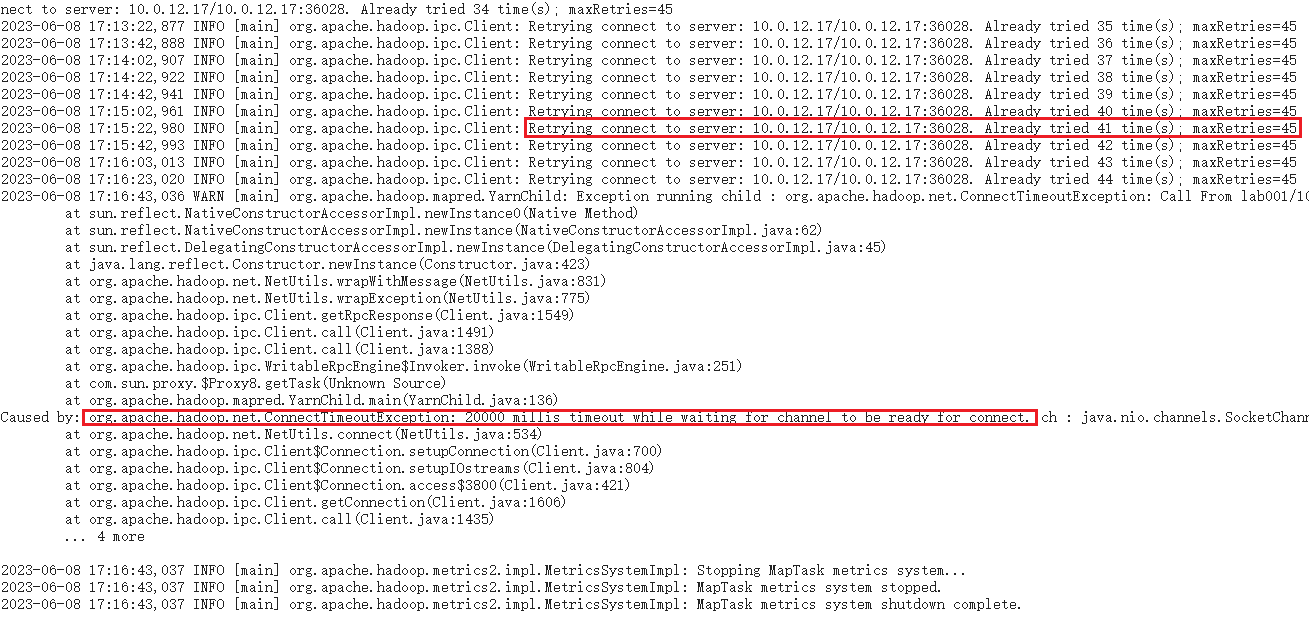
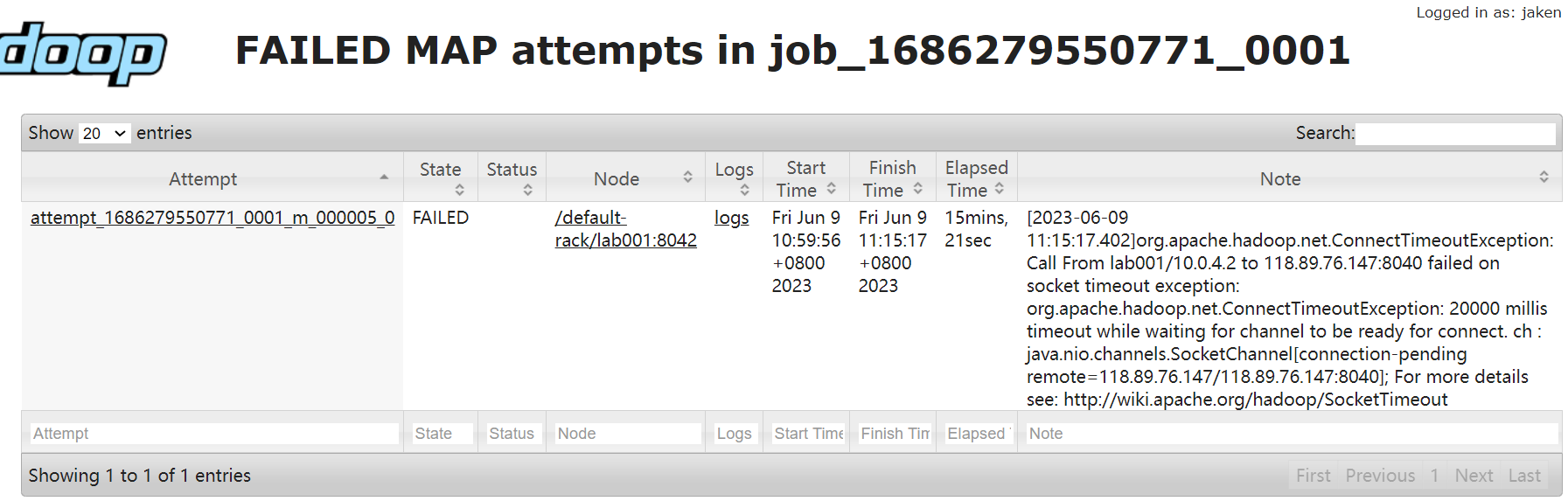
Permission denied
# 进入bin目录
chmod -R +x ./bin/
multi-job

Parsing conf: /opt/module/hibench/HiBench-master/HiBench-master/conf/hibench.conf
Parsing conf: /opt/module/hibench/HiBench-master/HiBench-master/conf/spark.conf
Parsing conf: /opt/module/hibench/HiBench-master/HiBench-master/conf/workloads/websearch/pagerank.conf
probe sleep jar: /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar
ERROR, execute cmd: '( /opt/module/hadoop-3.1.3/bin/yarn node -list 2> /dev/null | grep RUNNING )' timedout.
STDOUT:
STDERR:
Please check!
Traceback (most recent call last):
File "/opt/module/hibench/HiBench-master/HiBench-master/bin/functions/load_config.py", line 685, in <module>
load_config(conf_root, workload_configFile, workload_folder, patching_config)
File "/opt/module/hibench/HiBench-master/HiBench-master/bin/functions/load_config.py", line 217, in load_config
generate_optional_value()
File "/opt/module/hibench/HiBench-master/HiBench-master/bin/functions/load_config.py", line 613, in generate_optional_value
probe_masters_slaves_hostnames()
File "/opt/module/hibench/HiBench-master/HiBench-master/bin/functions/load_config.py", line 549, in probe_masters_slaves_hostnames
probe_masters_slaves_by_Yarn()
File "/opt/module/hibench/HiBench-master/HiBench-master/bin/functions/load_config.py", line 500, in probe_masters_slaves_by_Yarn
assert 0, "Get workers from yarn-site.xml page failed, reason:%s\nplease set `hibench.masters.hostnames` and `hibench.slaves.hostnames` manually" % e
AssertionError: Get workers from yarn-site.xml page failed, reason:( /opt/module/hadoop-3.1.3/bin/yarn node -list 2> /dev/null | grep RUNNING ) executed timedout for 5 seconds
please set `hibench.masters.hostnames` and `hibench.slaves.hostnames` manually
start ScalaSparkPagerank bench
/opt/module/hibench/HiBench-master/HiBench-master/bin/functions/workload_functions.sh: line 38: .: filename argument required
.: usage: . filename [arguments]
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/websearch/pagerank/spark/run.sh: line 26: OUTPUT_HDFS: unbound variable
原因可能是系统负载过高导致的响应迟钝
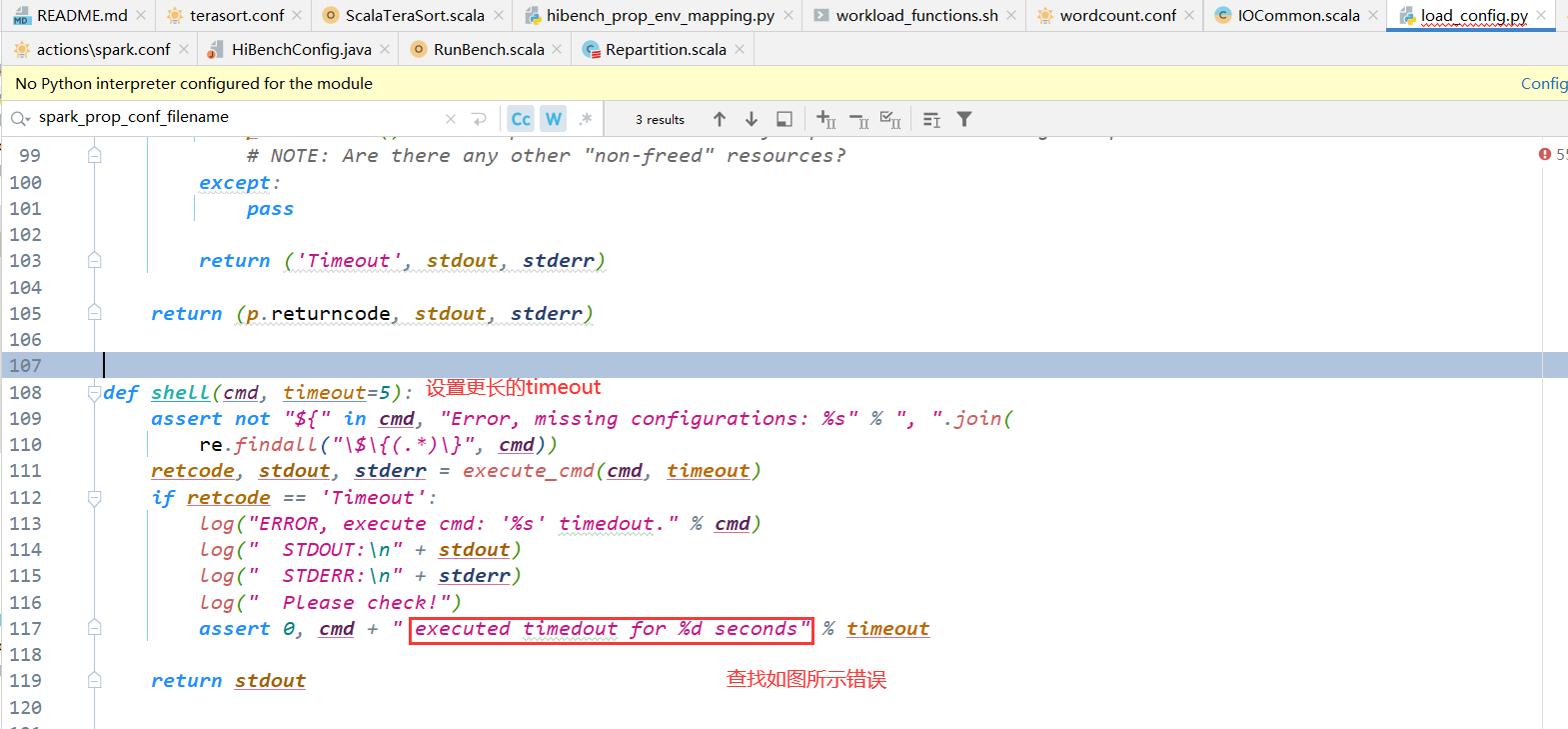
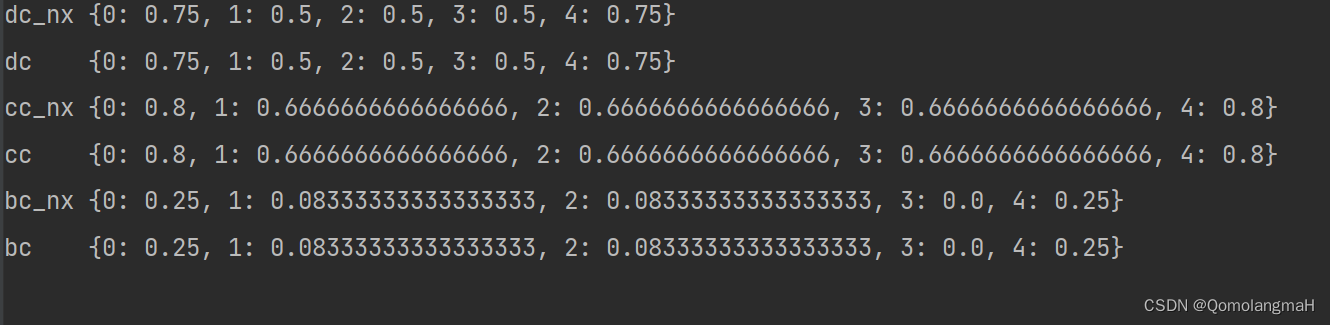
2.records
parallelism = 18
有input的stage的任务数是由数据数据的大小决定的,spark.default.parallelism决定的是shuffle后的stage的任务数
LR
内存不够
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1692258304054&to=1692264023063&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230817154625-0003&var-groupbyInterval=1s

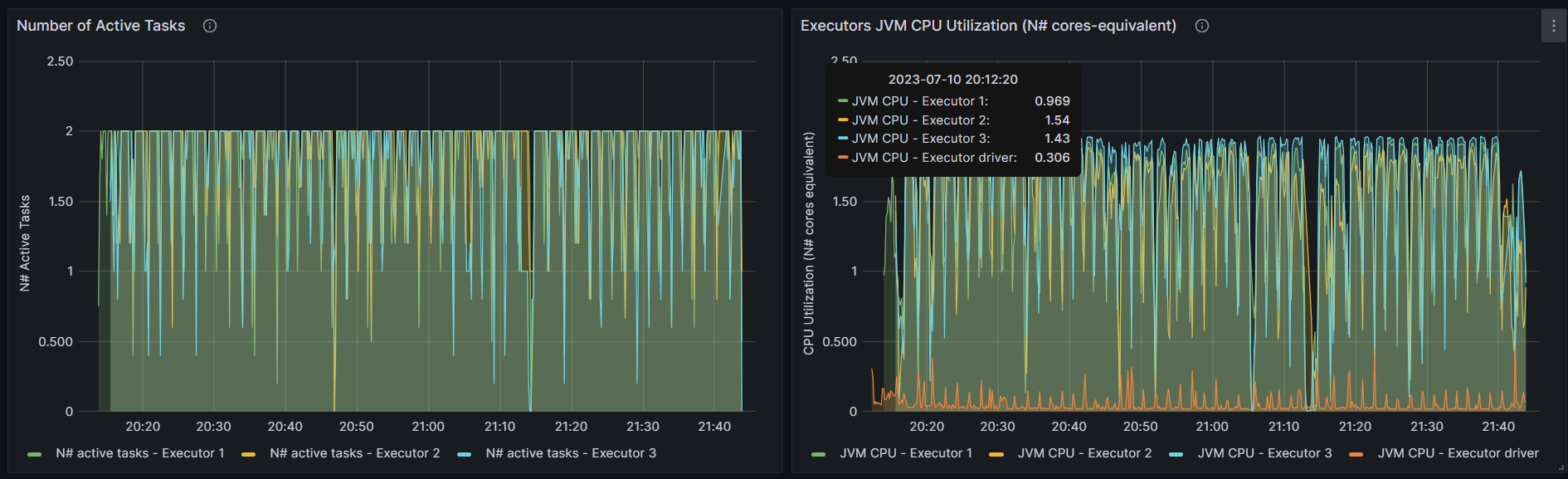
http://192.168.10.102:18080/history/app-20230817154625-0003/stages/
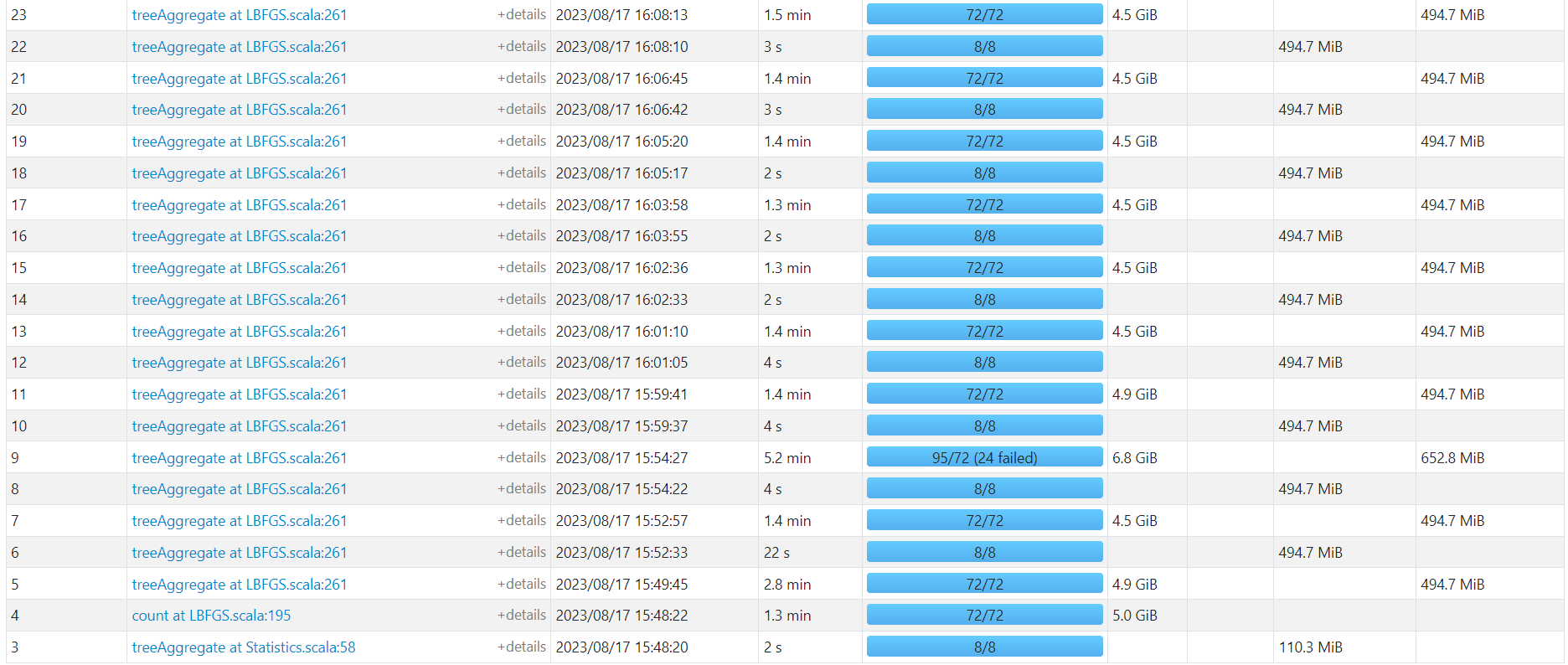

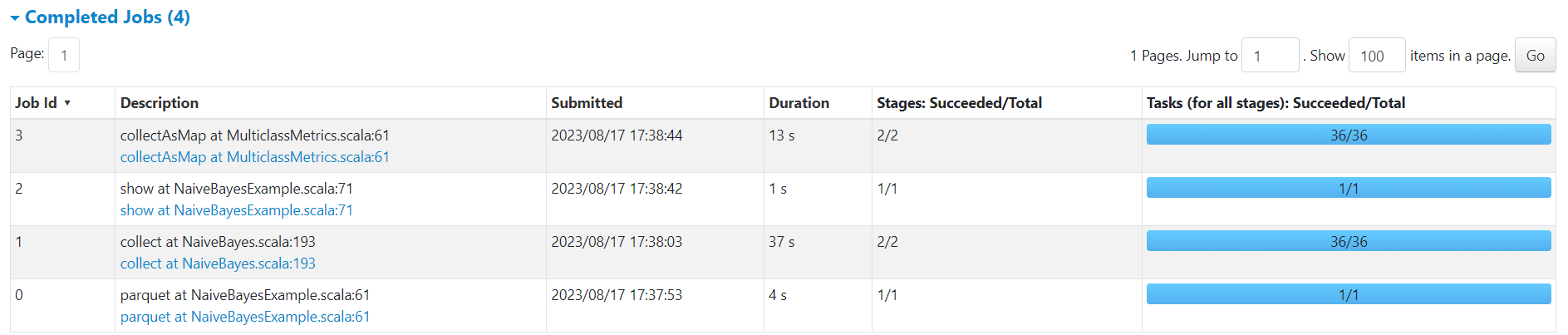
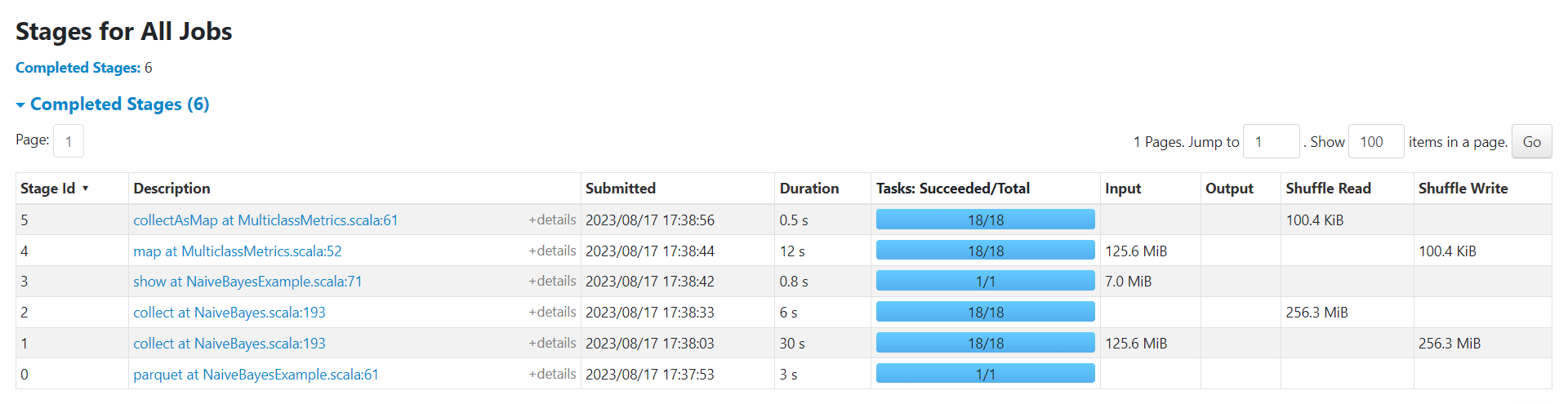
Bayes
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1692265076383&to=1692265140060&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230817173746-0004&var-groupbyInterval=1s
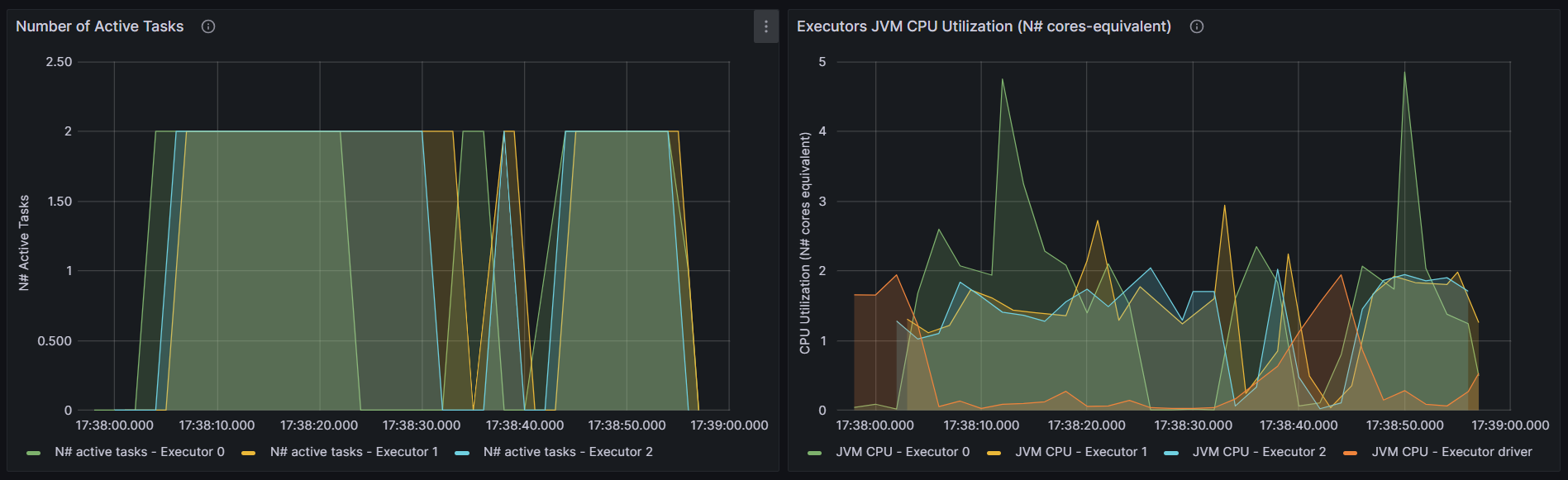
http://192.168.10.102:18080/history/app-20230817173746-0004/jobs/

NWeightGraphX


ScalaPageRank
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1692277885573&to=1692278062264&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230817211121-0012&var-groupbyInterval=1s
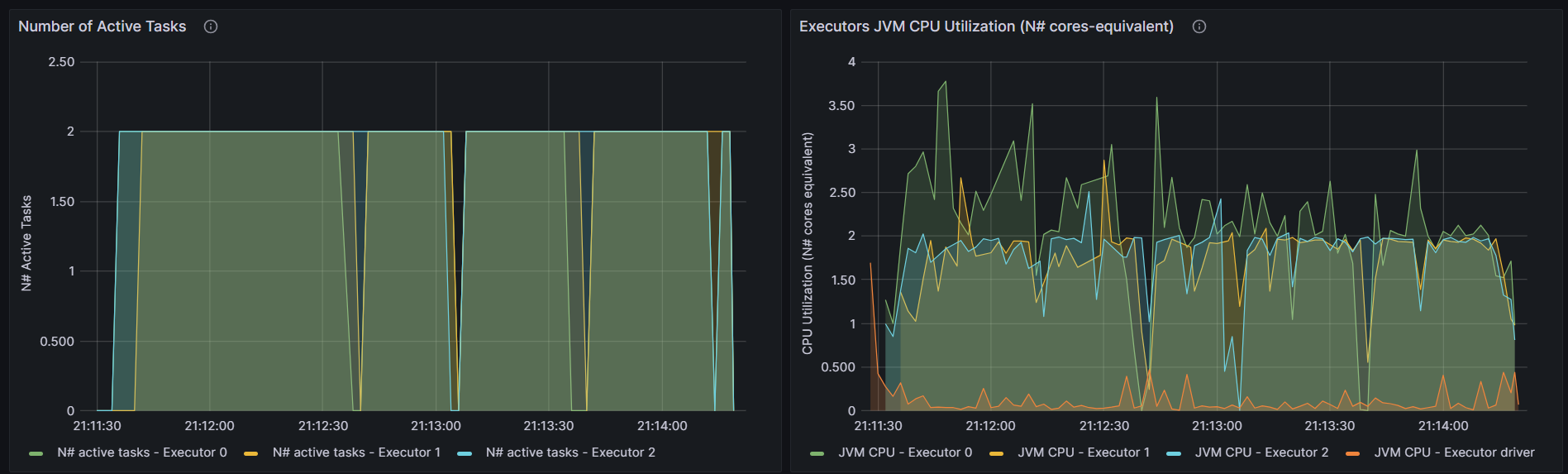
http://192.168.10.102:18080/history/app-20230817211121-0012/stages/

distinct
flatMap
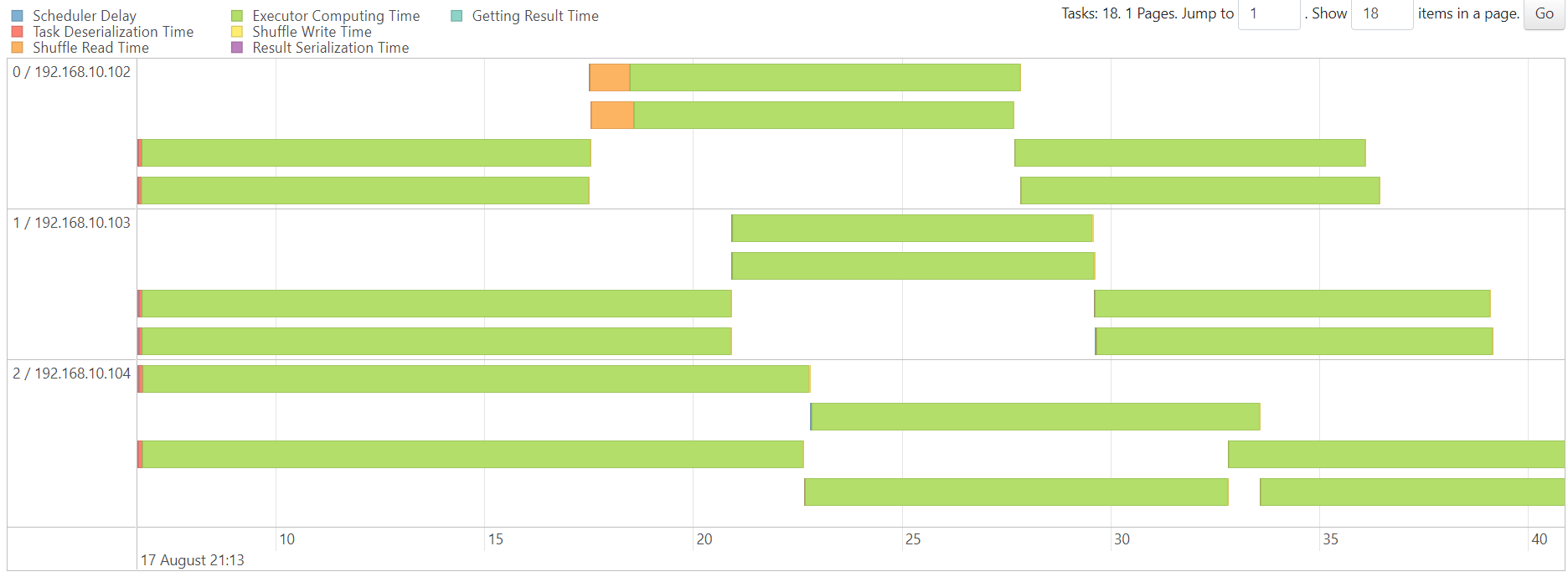
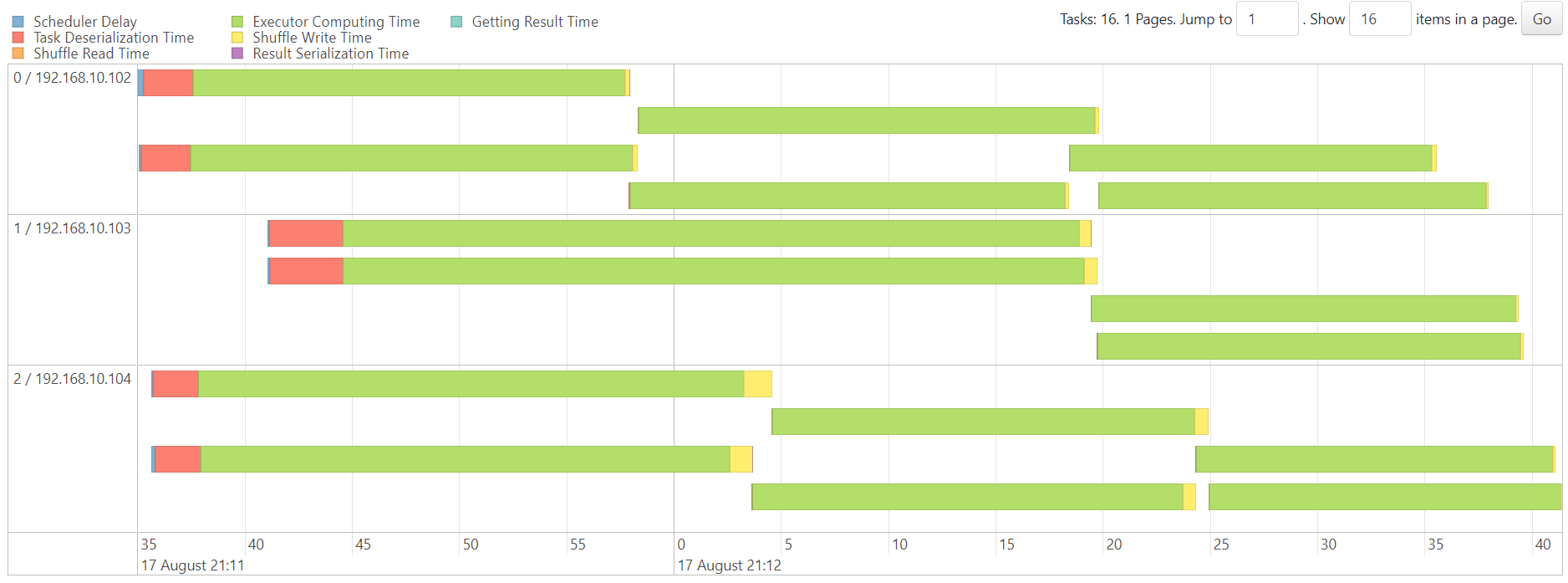
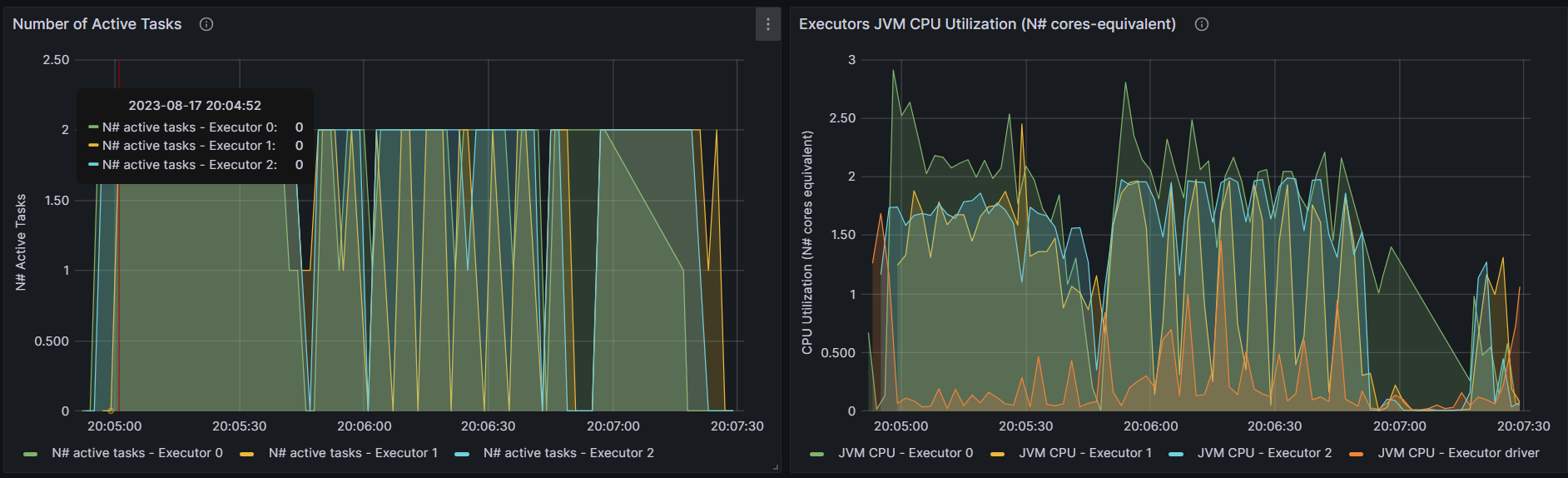
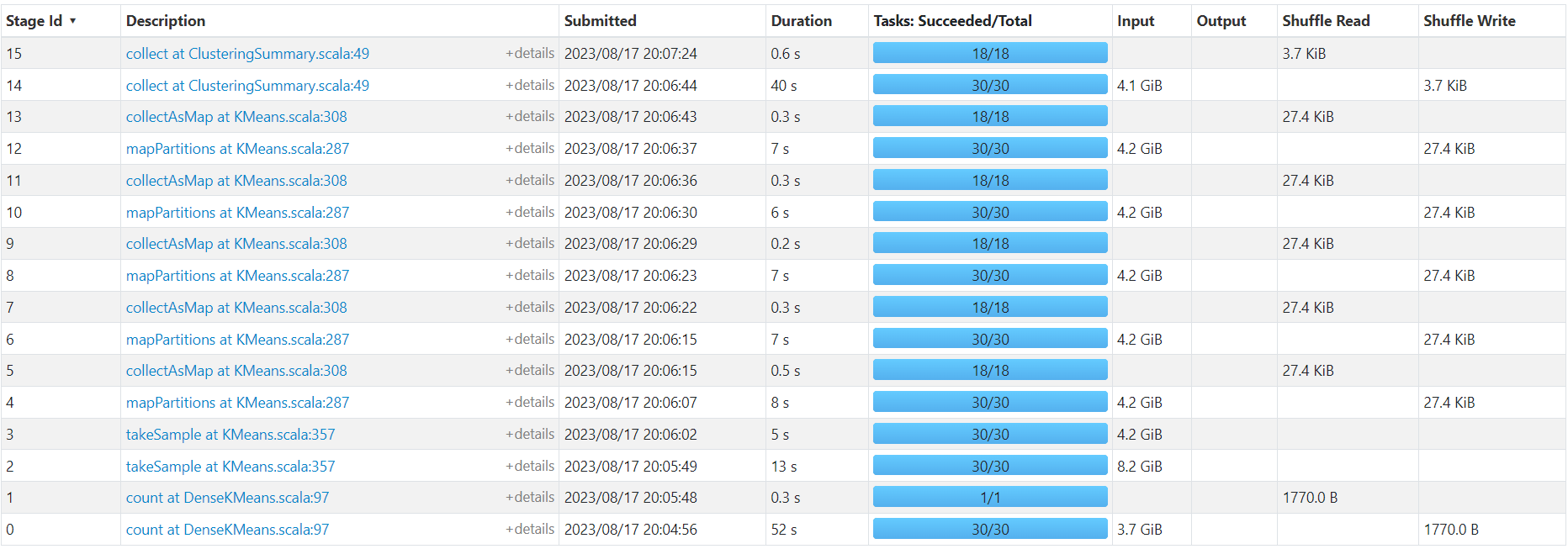
DenseKMeans
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1692273890319&to=1692274051643&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230817200442-0009&var-groupbyInterval=1s
http://192.168.10.102:18080/history/app-20230817200442-0009/stages/

map
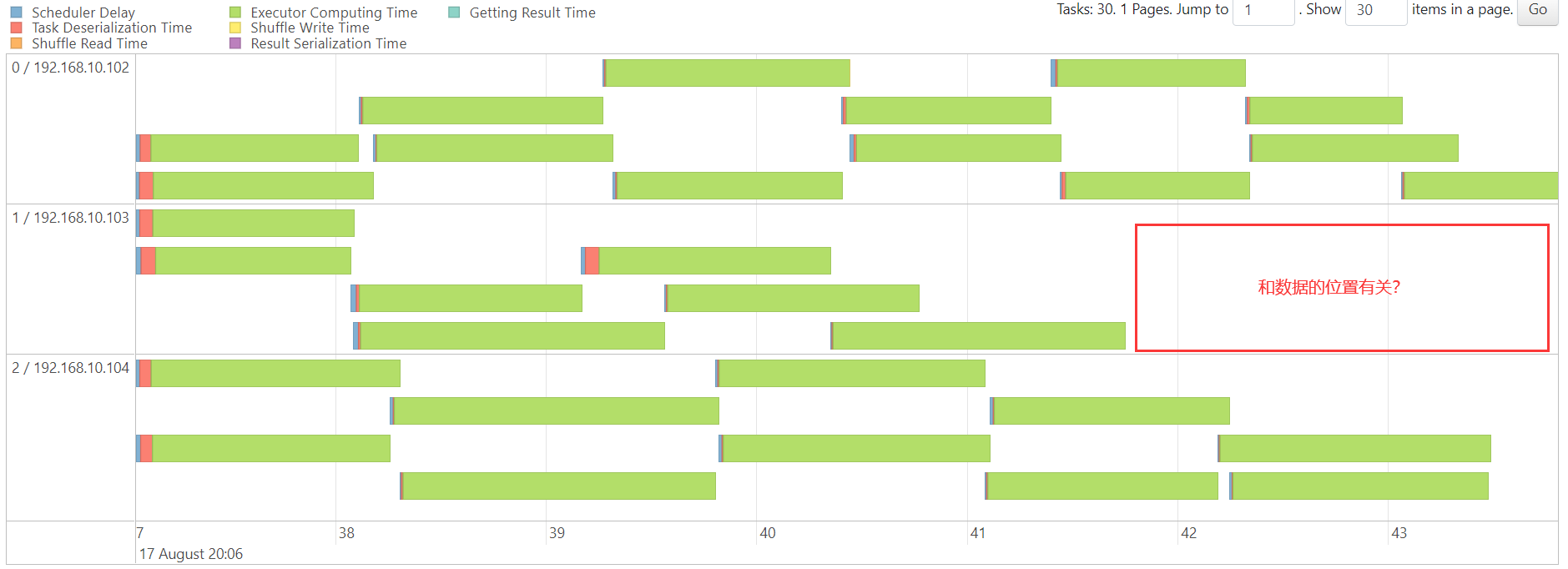
collect
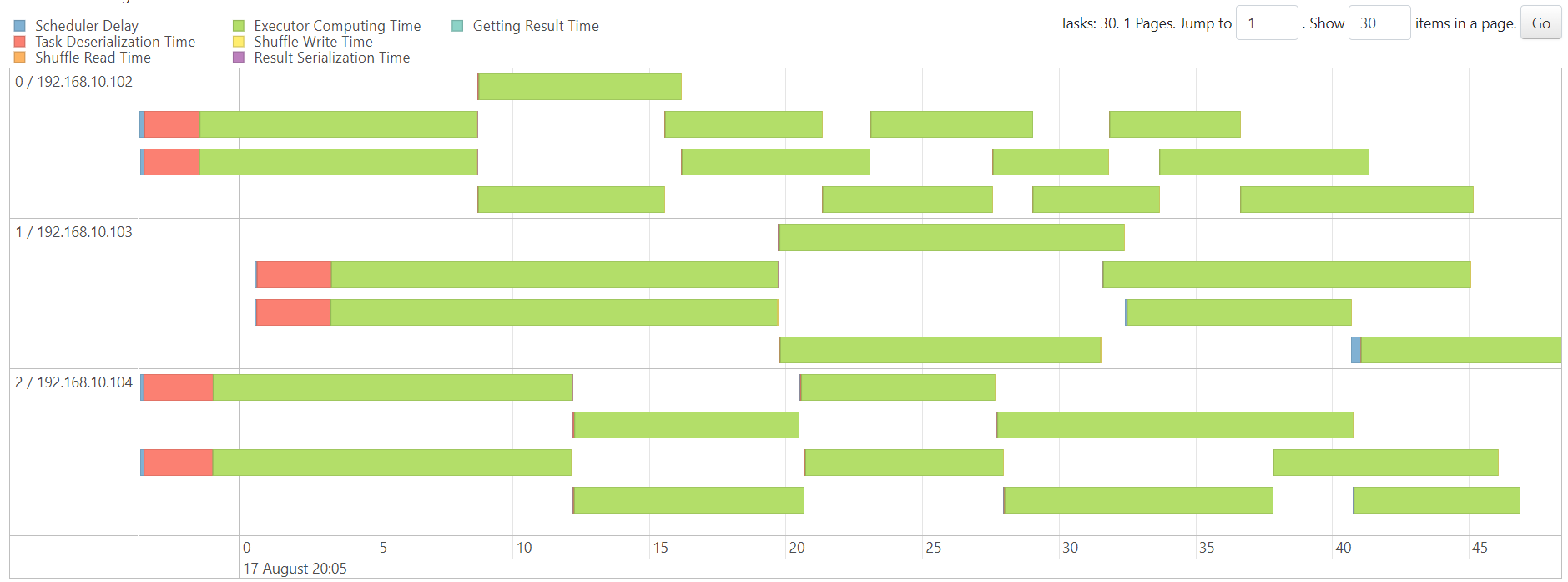
sort
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1692276453862&to=1692276644236&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230817204743-0011&var-groupbyInterval=1s
http://192.168.10.102:18080/history/app-20230817204743-0011/stages/

map
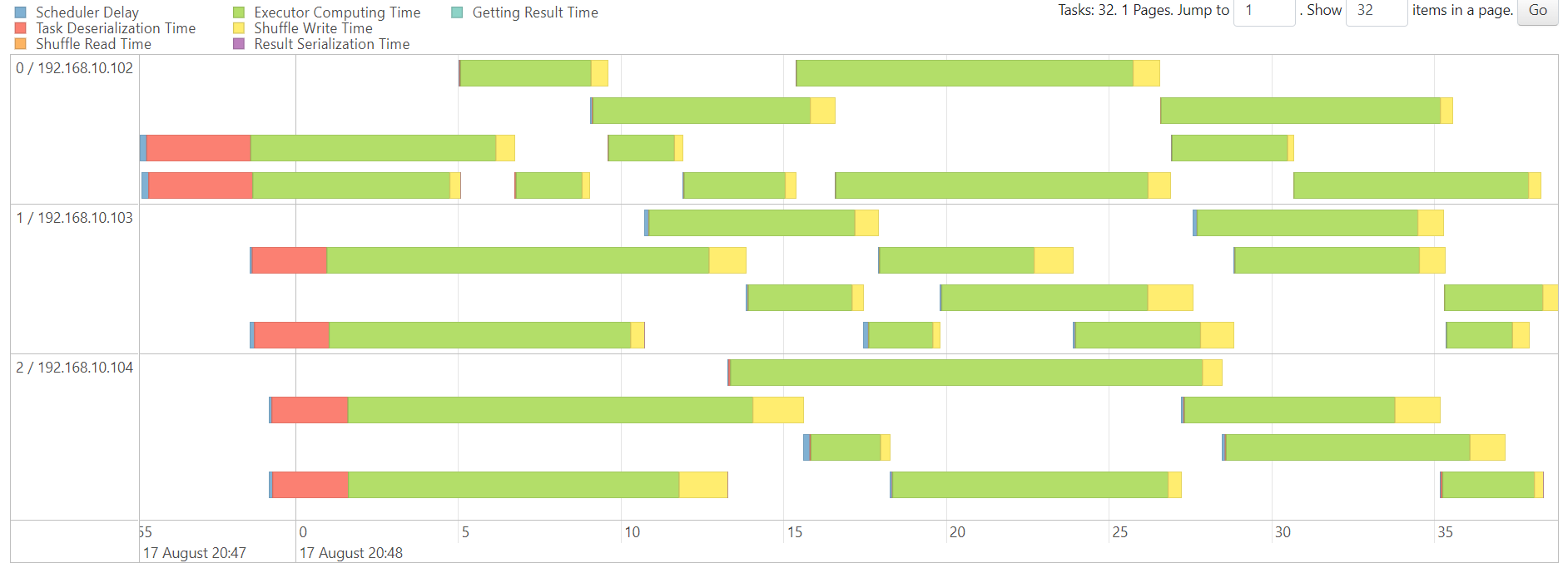
reduce
TeraSort
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1692275803257&to=1692276079162&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230817203719-0010&var-groupbyInterval=1s

http://192.168.10.102:18080/history/app-20230817203719-0010/stages/

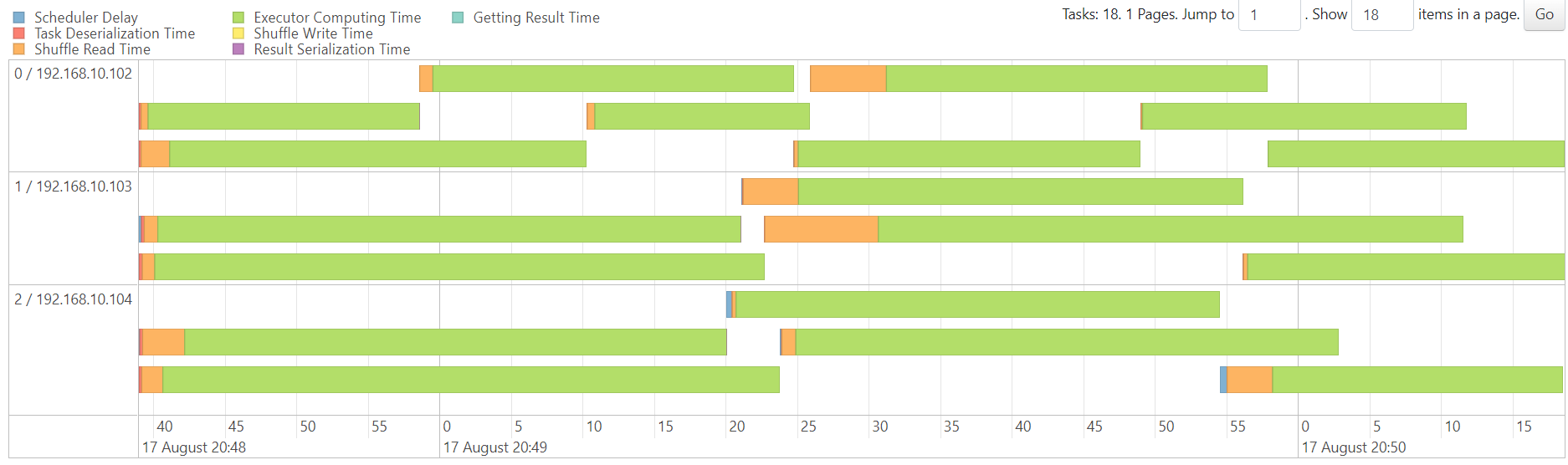
map

reduce
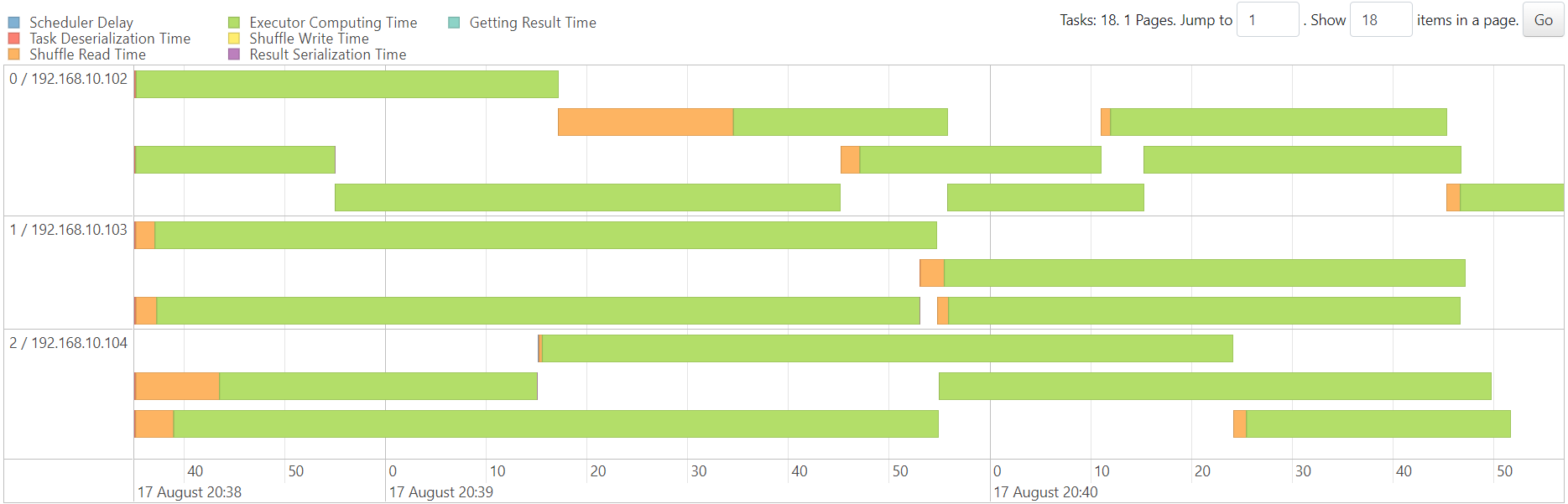
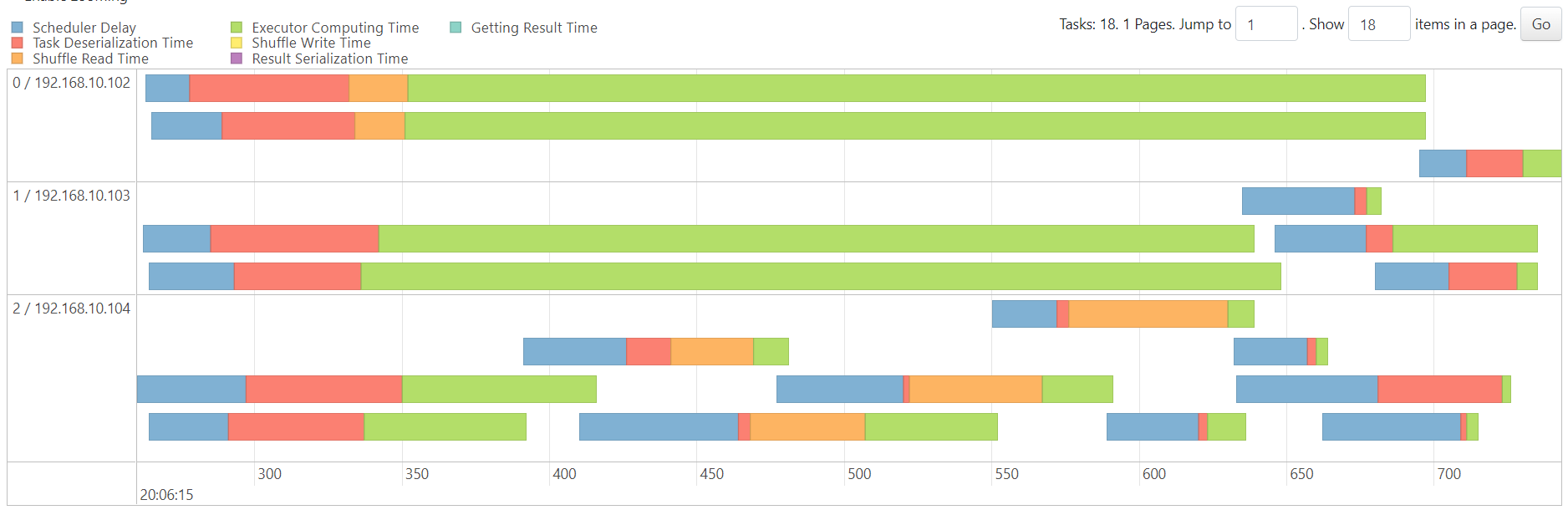
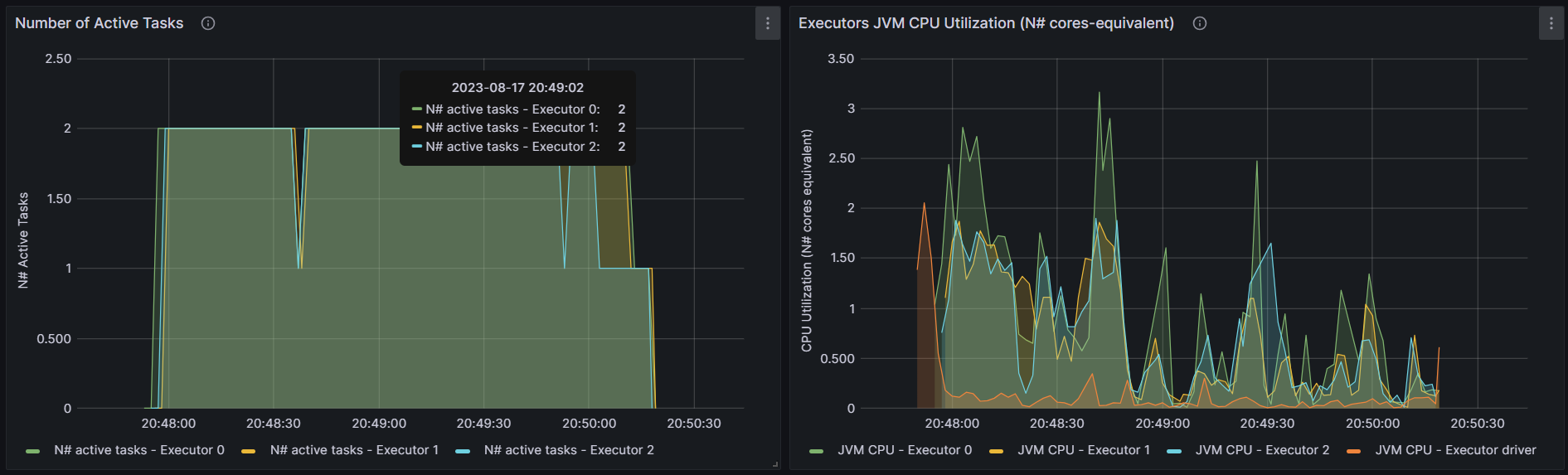
WordCount
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1691983226006&to=1691983545077&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230814112024-0002&var-groupbyInterval=1s
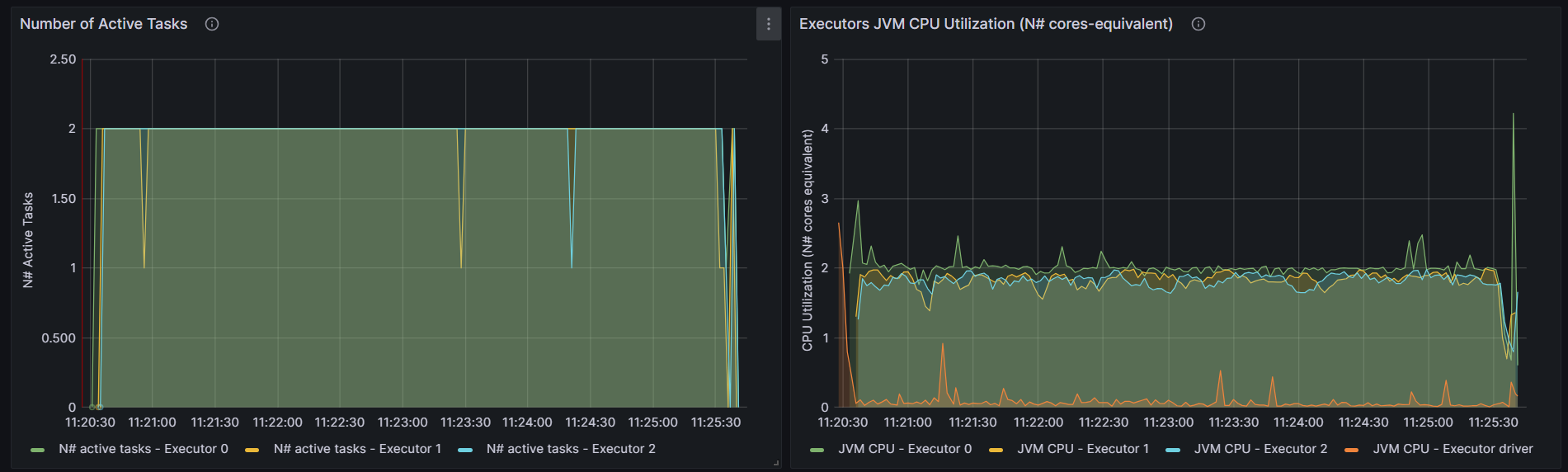
parallelism=20

http://192.168.10.102:18080/history/app-20230814112024-0002/jobs/
map
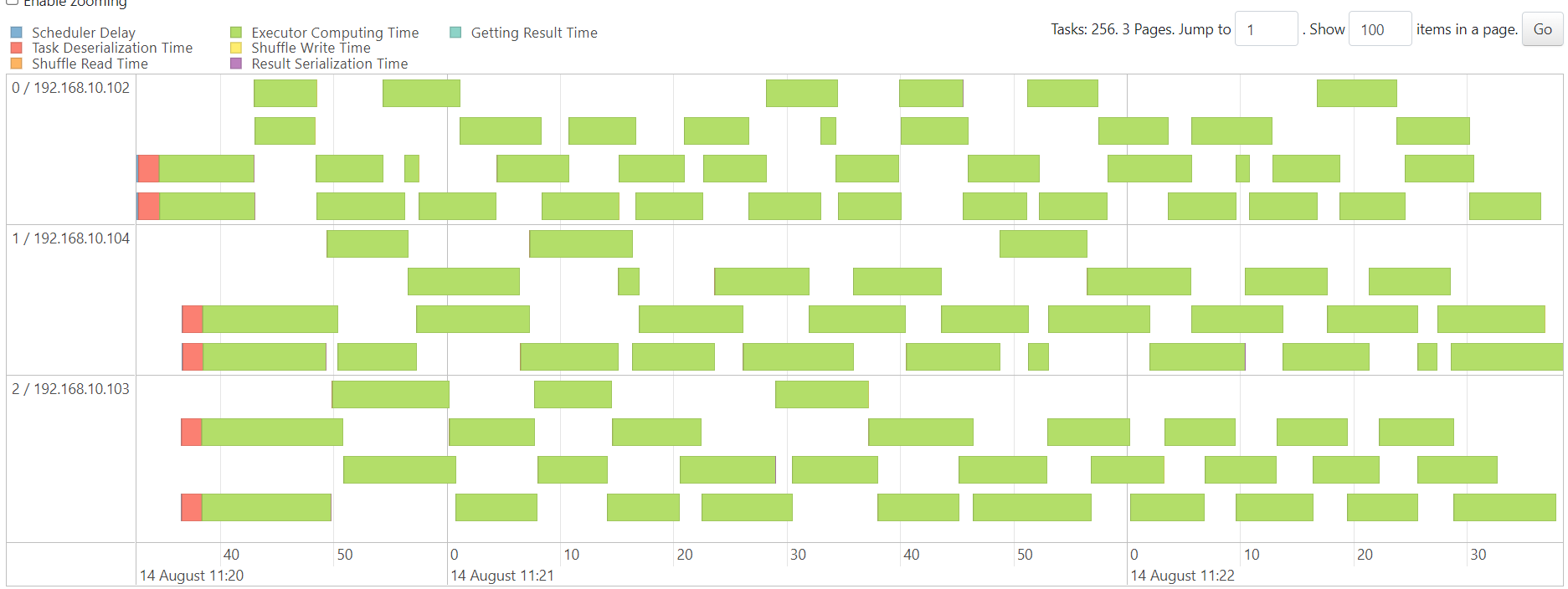
reduce
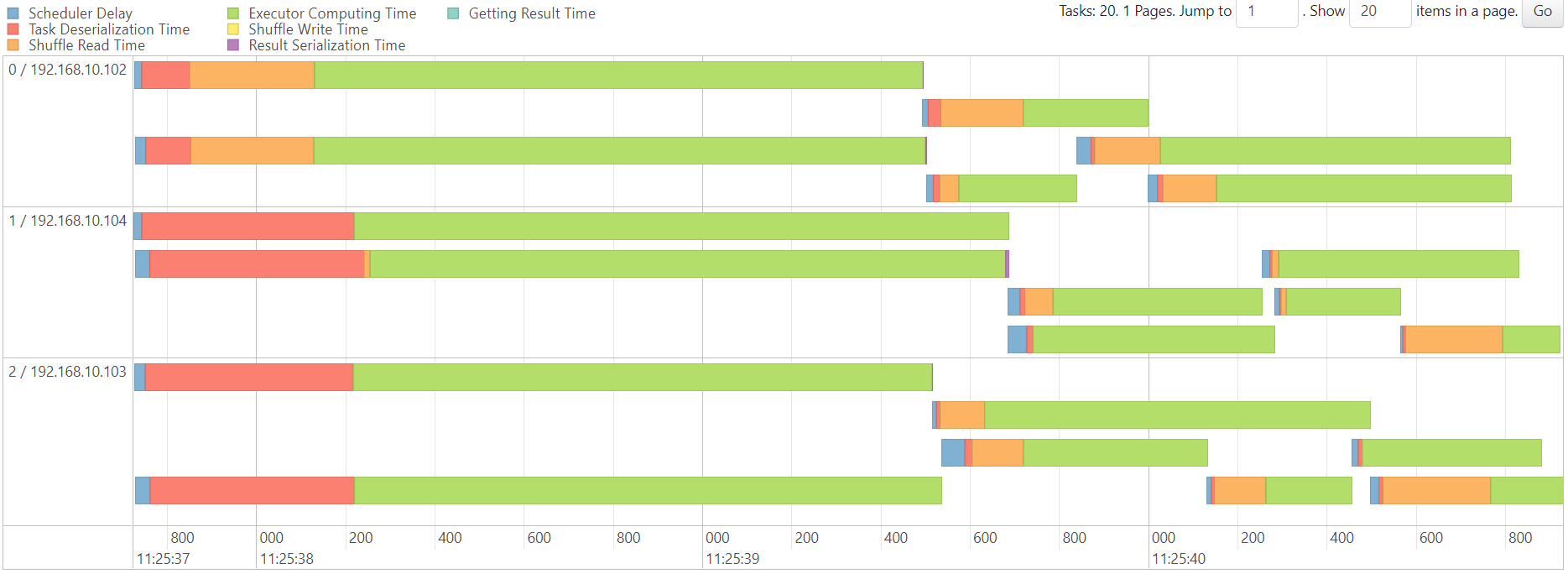
hdfs维护
hadoop fs -rm -r -skipTrash /hibench_test/HiBench/
hadoop dfsadmin -safemode leave
var-ApplicationId=app-20230814112024-0002&var-groupbyInterval=1s
[外链图片转存中…(img-eGnFeoml-1696143711685)]
parallelism=20
[外链图片转存中…(img-tqMq87MT-1696143711685)]
http://192.168.10.102:18080/history/app-20230814112024-0002/jobs/
map
[外链图片转存中…(img-ckoZlP4I-1696143711686)]
reduce
[外链图片转存中…(img-yA8CbUjp-1696143711686)]
hdfs维护
hadoop fs -rm -r -skipTrash /hibench_test/HiBench/
hadoop dfsadmin -safemode leave