目录
内存分区模型
常量 与 变量
常量的定义
#define 与 const 区别
宏与const使用
修改const常量
整数类型
无符号整数
有符号整数
补码
内存分析
浮点数类型
float类型的IEEE编码
double类型的IEEE编码
基本的浮点数指令
数据类型转换分析
浮点数作为返回值
字符与字符串
字符编码
字符串的存储方式
字符串在内存的存储
布尔类型
地址,指针
不同类型指针访问同一内存地址
各类型指针寻址方式
引用
引用类型揭密
引用类型作为函数参数
总结
本节会学习C++的基本数据类型在内存中的存储
内存分区模型
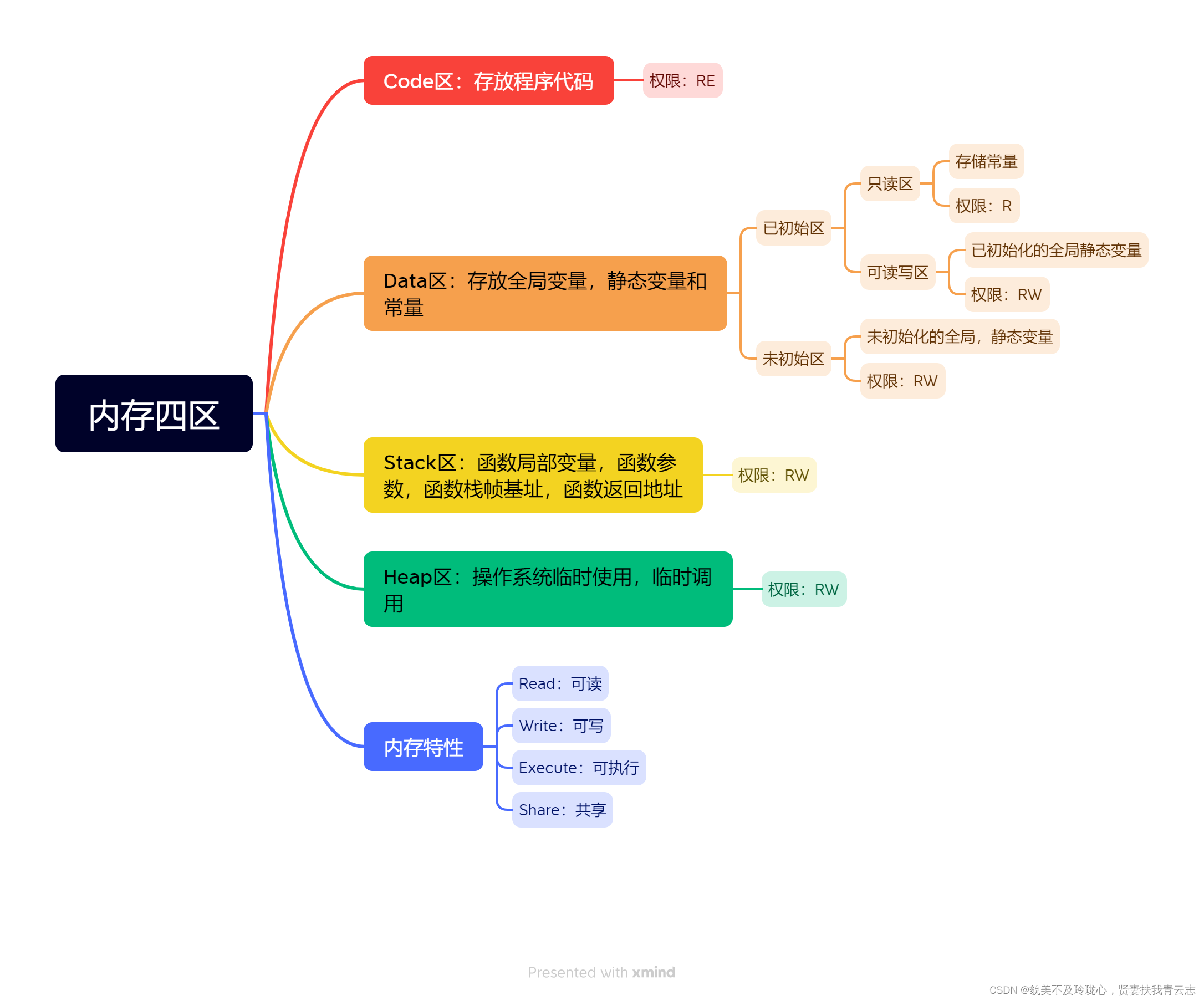
内存分为代码区code、数据区data、栈区stack和堆区heap。
Ø 代码区:通常放可执行代码,有些编译器会把常量也编译进去。
Ø 数据区:分为已初始化数据Inited和未初始化数据Uninit这两部分。
已初始化数据分为两部分,一部分是只读的,一部分是可读可写的。
未初始化数据可读可写。
数据区通常存储全局变量,静态变量,常量。常量通常置于已初始化的只读区(有些编译器也会放在代码区,因为代码区也有只读属性,不能写)。已初始化变量存储在已初始化区0042,未初始化变量存储在未初始化区0043。已初始化区分为可读写区0042c和只读区0042a。
Ø 栈区:存放参数变量,局部变量以及支撑程序返回的保存的返回地址和寄存器环境。
Ø 堆区:运行时临时需要空间,这个时候可以通过库函数或者操作系统接口临时使用紧急调用某些内存空间。操作系统会分配某一段满足要求的空间以提供使用。
编译器规划变量在哪里的时候,不看业务逻辑,只看内存属性,能不能读,能不能写。按照内存属性和内存位置分类
常量 与 变量
常量是一个恒定不变的值,它在内存中也是不可修改的。常量数据在程序运行前就已经存在,它们被编译到可执行文件中,当程序启动后,它们便会被加载进来。这些数据通常都会保存在常量数据区中,该区的属性没有写权限,所以在对常量进行修改时,程序会报错。试图修改常量数据都将引发异常,导致程序崩溃。
常量的定义
在C++中,可以使用宏机制#define来定义常量,也可以使用const将变量定义为一个常量。
- #define定义常量名称,编译器在对其进行编译时,会将代码中的宏名称替换成对应信息。宏的使用可以增加代码的可读性。
- const是为了增加程序的健壮性而存在的。常用字符串处理函数 strcpy 的第二个参数被定义为一个常量,这是为了防止该参数在函数内被修改,对原字符串造成破坏
#define 与 const 区别
#define修饰的符号名称是一个真量数值,而const修饰的栈常量,是一个“假”常量。在实际中,使用const定义的栈变量,最终还是一个变量,只是在编译期间对语法进行了检查,发现代码有对const修饰的变量存在直接修改行为则报错。被const修饰过的栈变量本质上是可以被修改的。我们可以利用指针获取const修饰过的栈变量地址,强制将const属性修饰去掉,就可以修改对应的数据内容。

宏与const使用
测试代码
#include<stdio.h>
#define NUMBER_ONE 1
int main(int argc, char* argv[])
{
const int n = NUMBER_ONE;
printf("const = %d #define = %d \r\n", n, NUMBER_ONE);
return 0;
}观察预处理文件

会自动把宏的地方进行替换
修改const常量
#define修饰的符号名称是一个真量数值,而const修饰的栈常量,是一个“假”常量。在实际中,使用const定义的栈变量,最终还是一个变量,只是在编译期间对语法进行了检查,发现代码有对const修饰的变量存在直接修改行为则报错。
被const修饰过的栈变量本质上是可以被修改的。我们可以利用指针获取const修饰过的栈变量地址,强制将const属性修饰去掉,就可以修改对应的数据内容
测试代码:
#include<stdio.h>
int main(int argc, char* argv[])
{
const int n1 = 5;
int* p = (int*)&n1;
*p = 6;
int n2 = n1;
return 0;
}
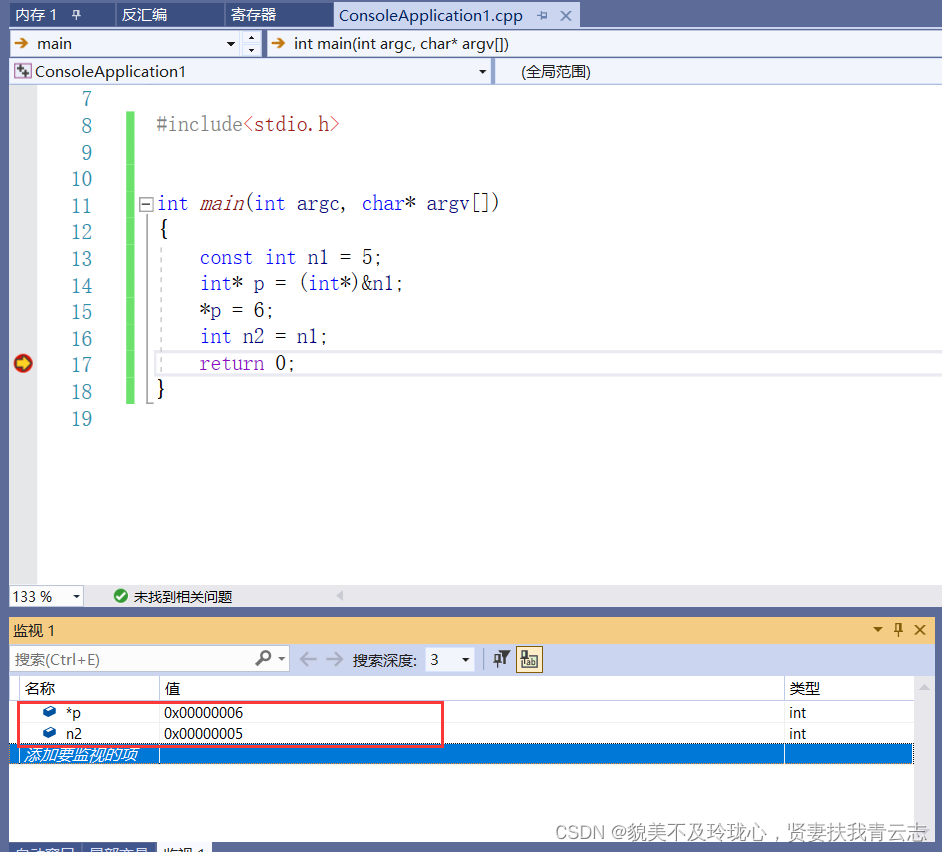
使用指针可以修改const常量的值
为什么n2没被赋值为6,因为这一步发生在编译阶段,直接进行了替换
由于const修饰的变量n1被赋值一个数字常量5,编译器在编译过程中发现n1的初始值是可知的,并且被修饰为const。之后所有使用n1的地方都替换为这个可预知值,故int n2 =n1;对应的汇编代码没有将n1赋值给n2,而是用常量值5代替。
整数类型
C++整型数据分类:

在内存中,整型数据的存储按照有符号,无符号两种方式存储又有所不同
无符号整数
在内存中,无符号整数的所有位都用来表示数值。
大小:变量在内存中占4字节,由8个十六进制数组成
取值范围:0x00000000~0xFFFFFFFF ,如果转换为十进制数,则表示范围为0~4294967295。
当无符号整型不足32位时,用0来填充剩余高位,直到占满4字节内存空间为止。
在内存中存储时,x86架构是使用小端存储的方式,高位放高地址位,地位放低地址位;
有符号整数
有符号整数中最高位,即符号位。最高位为0表示正数,最高位为1表示负数。
有符号整数int在内存中同样占4字节,但由于最高位为符号位,不能用来表示数值,因此有符号整数的取值范围要比无符号整数取值范围少1位,即 0x80000000 ~ 0x7FFFFFFF,如果转换为十进制数,则表示范围为 -2147 483 648 ~ 2147 483 647 。
在有符号整数中,正数的表示区间为0x00000000~0x7FFFFFFF;负数的表示区间为0×80000000~0xFFFFFFFF。
补码
负数在内存中都是以补码形式存放的,补码的规则是用0减去这个数的绝对值,也可以简单地表达为对这个数值取反加1。- 0x3 = 0xFFFFFFFC + 1 = 0xFFFFFFFD ,两者在计算时是等价的。
计算机只会做加法,对负数的计算只能转换为加法
对有符号数求补码:0×80000000~0xFFFFFFFF。 0x80000000的补码还是0x80000000,于是就把它规定为负数的最小值,这就是负数的个数比整数多1的原因。
在内存中看到一个整数类型的数据:最高位大于8就是一个负数,小于8就是一个正数
如何判断一段数据是有符号数还是无符号数?
这就需要查看指令或者已知的函数操作内存地址的方式,根据操作方式或 函数相关定义得出该地址的数据类型。如API调用MessageBoxA,它 有4个参数,查看帮助手册得知,第4个参数为一个无符号整数,从而 可分析出这个传入数值的类型。
内存分析
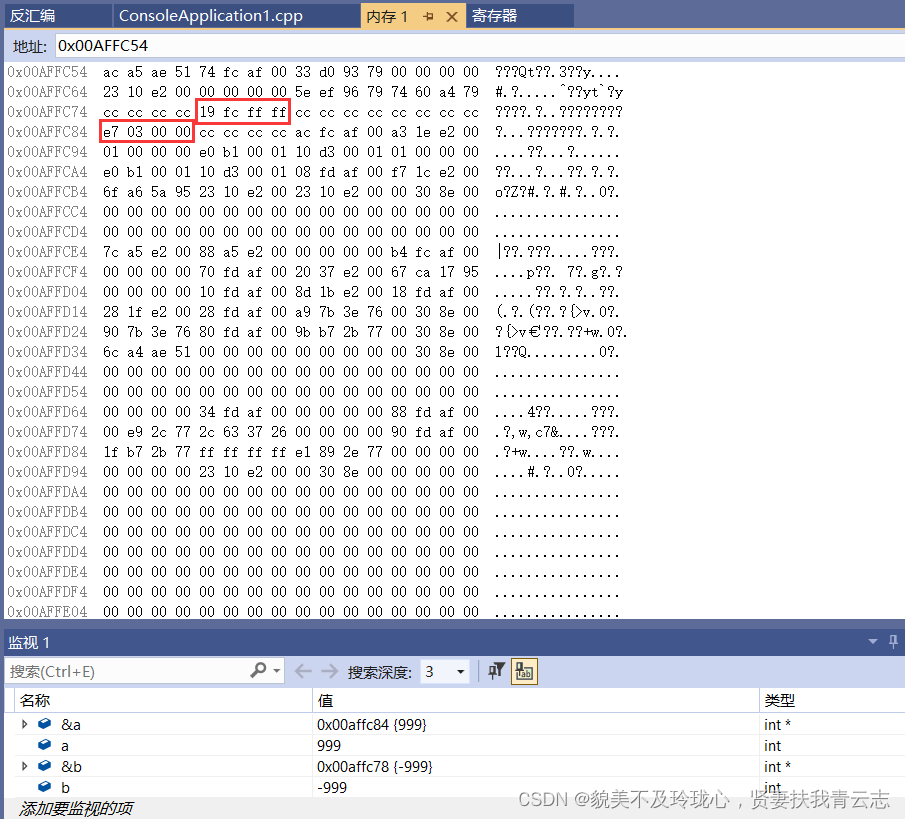
dword ptr: 这是一个修饰符,表示操作数应当被视为双字(32位)。[a]: 这是一个内存引用,指定要操作的内存地址。
rep stos dword ptr es:[edi] 指令解读
- rep:表示要重复执行指定的操作。在这里,它告诉处理器重复执行
stos操作。- stos: 这是一个存储字节或双字的指令。具体的操作取决于指定的操作数大小。
es是附加段寄存器,可以用来存储额外的数据段的基地址;edi是基址寄存器,通常用于存储目标操作数的基地址。es:edi表示以es段寄存器中存储的数据段基地址为起点,加上edi寄存器中存储的偏移量,得到的内存地址作为操作数的地址。例如,如果es寄存器中存储的是数据段的基地址为0x00100000,而edi寄存器中存储的偏移量为0x00000100,那么es:edi将表示内存地址0x00100100。
浮点数类型

这两种数据类型在内存中同样以十六进制方式存储,但与整型类型有所不同。
浮点类型并不是将一个浮点小数直接转换成二进制数保存﹐而是将浮点小数转换成的二进制码重新编码,再进行存储。C/C++的浮点数是有符号的。
- 浮点数先转化为二进制形式
- 移动小数点,高位一位是1,左移为正,右移为负
- 最高位表示小数正负;之后8位(float,+127)或者11位(double,+1023)表示移动的位数;最后一部分表示小数
浮点数强制转换为整数时,不会采用数学上四舍五入的方式,而是舍弃掉小数部分
浮点数的操作不会用到通用寄存器﹐而是会使用浮点协处理器的浮点寄存器﹐专门对浮点数进行运算处理。
float类型的IEEE编码
浮点数:12.25
对应二进制小数:1100.01
小数点向左移动,每移动一次,指数加1:1.10001 小数点移动3次
符号位:0
指数位:3+127(固定的)=130 10000010
尾数位:10001 000000000000000000结果:0 10000010 10001000000000000000000
十六进制表示:0x41440000
解释:
- 为什么小数二进制形式的整数1舍去?
由于尾数位中最高位1是固定值,故忽略不计,只要在转换回十进制数时加1即可。
- 为什么指数位要加127呢?
这是因为指数可能出现负数,十进制数127可表示为二进制数01111111,IEEE编码方式规定 , 当 指 数 小 于 0111111 时 为 一 个 负 数 , 反 之 为 正 数 , 因 此01111111为0。
负小数案例:
浮点数:-0.125
二进制数:-0.001
最高符号位:1
指数为:0.001 -- 1 指数 -3 -3+127 = 124 01111100
尾数:0
1 01111100 00000000000000000000000
16进制:0xBE000000
double类型的IEEE编码
double类型和float类型大同小异,只是double类型表示的范围更大,占用空间更多,是float类型所占空间的两倍。当然,精准度也会更高。
double类型占8字节的内存空间,同样,最高位也用于表示符号,指数位占11位,剩余52位表示位数。
在float类型中,指数位范围用8位表示,加127后用于判断指数符号。在double类型中,由于扩大了精度,因此指数范围使用11位正数表示,加1023后可用于指数符号判断。
double类型的IEEE编码转换过程与float类型一样
基本的浮点数指令
浮点数的操作指令与普通数据类型不同,浮点数操作是通过浮点寄存器实现的,而普通数据类型使用的是通用寄存器,它们分别使用两套不同的指令
通过寄存器,指令就可以区分浮点数和整数
早期的CPU中,浮点数寄存器是通过栈实现的;在使用浮点指令时,都要先利用ST(0)进行运算。当ST(0)中有值时,便会将ST(0)中的数据顺序向下存放到ST(1)中,然后再将数据放入ST(0)。如果再次操作ST(0),则会先将ST(1)中的数据放入ST(2),然后将ST(0)中的数据放入ST(1),最后将新的数据存放到ST(0)。以此类推,在8个浮点寄存器都有值的情况下继续向ST(0)中的存放数据,这时会丢弃ST(7)中的数据信息。
1997年开始,Intel和AMD都引入了媒体指令(MMX),这些指令允许多个操作并行,允许对多个不同的数据并行执行同一操作。之后演变位SSE,再到最新的AVX。
寄存器在MMX中被称为MM寄存器,在SSE中被称为XMM寄存器,在AVX中被称为YMM寄存器。MM寄存器是64位的,XMM是128位的,而YMM是256位的。
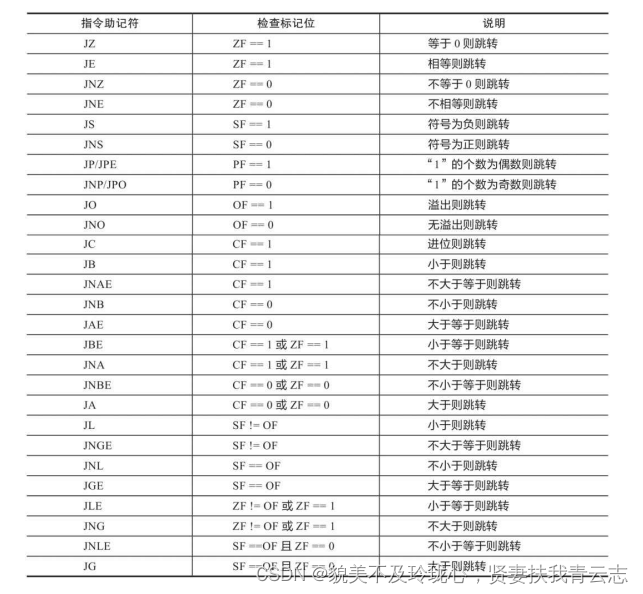
常用SSE浮点数指令表

数据类型转换分析

cvtsi2ss xmm0,dword ptr [argc]cvtsi2ss是一个x86指令,用于将整数转换为单精度浮点数,并将结果存储在 XMM 寄存器中dword ptr [argc]表示从内存中读取一个双字(32位)整数,其地址由argc变量给出。- 整数值被转换为等效的单精度浮点数。
- 转换后的浮点数被保存在 XMM0 寄存器中。
- XMM寄存器都是128位,16字节
movss dword ptr [f],xmm0movss是一个x86指令,用于将 XMM 寄存器中的单精度浮点数值移动到内存中。xmm0寄存器中存储着一个单精度浮点数值。dword ptr [f]表示将这个浮点数值写入到内存地址f指向的4个字节中(即将xmm0的低32位写入到f)。
cvtss2sd xmm0,dword ptr [f]cvtss2sd是一个x86指令,用于将单精度浮点数转换为双精度浮点数,并将结果存储在 XMM 寄存器中。dword ptr [f]表示从内存中读取一个双字(32位)单精度浮点数,其地址由f变量给出。- 单精度浮点数值被转换为等效的双精度浮点数。
- 转换后的双精度浮点数被保存在 XMM0 寄存器中。
movsd mmword ptr [esp],xmm0- 指令
movsd是用于将双精度浮点数(64 位)从 XMM 寄存器存储到内存中的指令。 xmm0寄存器中存储着一个双精度浮点数值。mmword ptr [esp]表示将这个双精度浮点数值写入到内存中,其中[esp]是一个内存地址,mmword ptr指示该地址存储着一个八字(即64位)的数据。
cvttss2si eax,dword ptr [f]cvttss2si是一个 x86 指令,用于将单精度浮点数转换为有符号整数,并将结果存储在通用寄存器中dword ptr [f]表示从内存中读取一个单精度浮点数,其地址由变量f给出。- 将该单精度浮点数执行向零舍入操作(即直接去除小数部分,保留整数部分)以获得一个等效的整数值。
- 将整数值保存在
eax寄存器中。
浮点数作为返回值

fld是 x86 指令集中的一个指令,用于加载浮点数到浮点寄存器中。[string "%f" (0E77BCCh)]表示从内存地址0E77BCCh处读取一个 32 位(4 字节)的浮点数值。- 这个浮点数值被加载到浮点寄存器中,通常是栈上的寄存器 ST(0)。

fstp是 x86 指令中的一个指令,用于将浮点数从浮点寄存器存储到内存中。dword ptr [f]表示将浮点数值写入到内存中,其中[f]是一个内存地址,dword ptr指示该地址存储着一个双字(即32位)的数据。- 将栈上的浮点数值弹出到内存中,并在此过程中将其从浮点寄存器 ST(0) 中清除。
字符与字符串
字符串是由多个字符按照一定排列顺序组成的,在C++中,以'\0'作为字符串结束标记。每个字符都记录在一张表中,它们各自对应一个唯一编号,系统通过这些编号查找到对应的字符并显示。字符表格中的编号便是字符的编码格式。
字符编码
在C++中,字符的编码格式分为两种:ASCII和Unicode。
- Unicode是ASCII的升级编码格式,它弥补了ASCII的不足,也是编码格式的发展趋势。
- ASCII编码在内存中占1字节,由0~255之间的数字组成。每个数字表示一个符号,具体表示方式可查看ASCII表。由于ASCII编码也是由数字组成的,所以可以和整数互相转换,但整数不可超过ASCII的最大表示范围,因为多余部分将被舍弃。
字符串的存储方式
字符串是由一系列按照一定的编码顺序线性排列的字符组成的。在程序中,只要知道字符串的首
地址和结束地址就可以确定字符串的长度和大小。在定义字符串的时候都会先指定好首地址。结束地址确定有两种方法:
- 一种是在首地址的4字节中保存字符串的总长度
- 另一种是在字符串的结尾处使用一个规定好的特殊字符,即结束符
字符串在内存的存储
wchar_t内存中两个字节表示一个字符,char则是一个


布尔类型
地址,指针
在C++中,地址标号使用十六进制表示,取一个变量的地址使用“&”符号,只有变量才存在内存地址,常量没有地址(不包括const定义的伪常量)。
指针的定义使用“TYPE * ”格式,TYPE为数据类型,任何数据类型都可以定义指针。指针本身也是一种数据类型,用于保存各种数据类型在内存中的地址。指针变量同样可以取出地址,所以会出现多级指针。
例如:int* p1 = &n; p1存储的是一个地址,这个地址存储的是值;p1也是变量;
在32位应用程序中,地址是一个由32位二进制数字组成的值,4个字节;
在64位应用程序中,地址是一个由64位二进制数字组成的值。
为了便于查看,转换成十六进制数字显示出来,用于标识内存编号。指针是用于保存这个编号的一种变量类型,它包含在内存中,所以可以取出指针类型变量在内存中的位置——地址。由于指针保存的数据都是地址,所以无论什么类型的指针,32位程序都占据4字节的内存空间,
指针可以根据指针类型对地址对应的数据进行解释。而一个地址值无法单独解释数据,对于0x0135FE04这个地址值,仅凭借它本身无法说明该地址处对应数据的信息。如果是在一个int类型的指针中保存这个地址,就可以将其看作int类型数据的起始地址,向后数4字节到0x0135FE08处,将0x0135FE04~0x0135FE08中的数据按整型存储方式解释;
对比指针地址不同点:

指针与地址共同点:

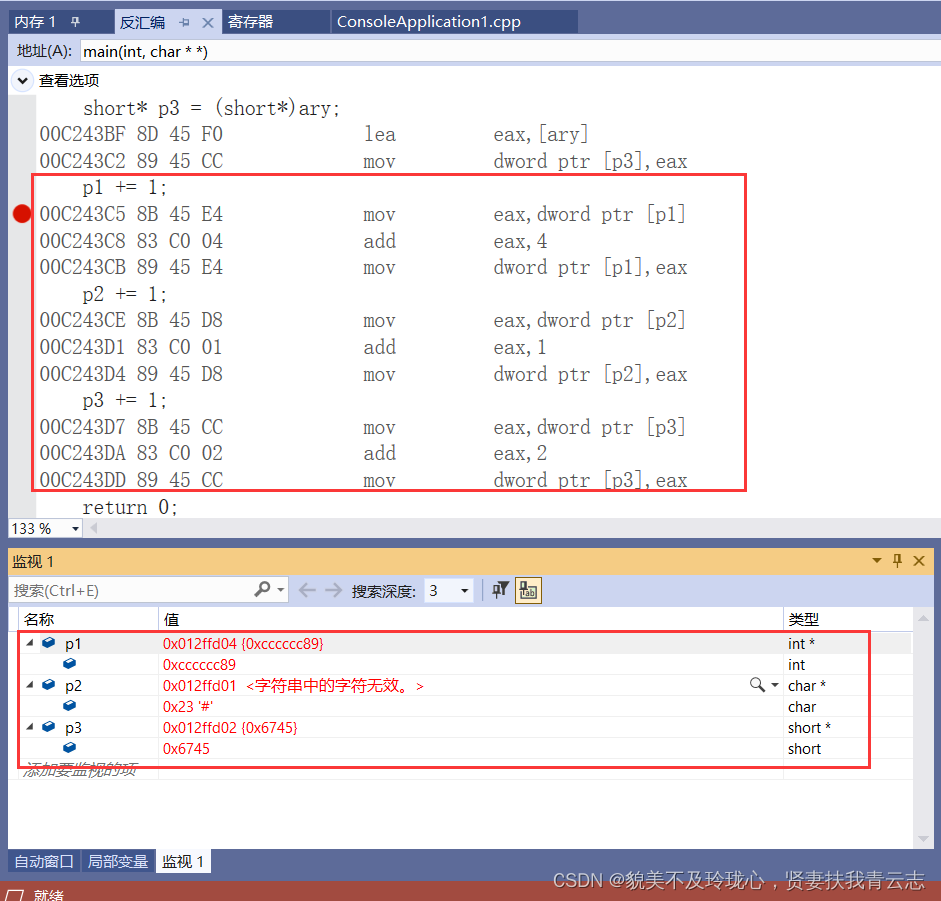
不同类型指针访问同一内存地址

- lea取n地址地址给指针变量p3

movsx是 x86 汇编指令中的一个指令,用于将一个带符号的字节值拓展为一个带符号的双字(32 位)值。[eax]表示从内存地址eax处读取一个字节的值。- 该字节值被加载到寄存器
ecx中,并被符号拓展为一个双字。

movsx是 x86 汇编指令中的一个指令,用于将一个带符号的字(16 位)值拓展为一个带符号的双字(32 位)值。[eax]表示从内存地址eax处读取一个字(16 位)的值。- 该字值被加载到寄存器
ecx中,并被符号拓展为一个双字。
各类型指针寻址方式


- 指针在内存要理解为一种变量,存储的是地址,取这个地址存储值可得数据
- 这里就是取变量ary地址传给指针p1,p2,p3
指针的加1是加上指针类型所占字节数
type *p; // 这里用 type 泛指某类型的指针
// 省略指针赋值代码
p+n 的目标地址 = 首地址 + sizeof( 指针类型 type) * n
type *p, *q; // 这里用type泛指某类型的指针
// 省略指针赋值代码
p-q = ((int)p - (int)q) / sizeof(指针类型type)
引用
引用类型在C++中被描述为变量的别名。C++为了简化操作,对指针的操作进行了封装,产生了引用类型。引用类型实际上就是指针类型,只不过用于存放地址的内存空间对使用者而言是隐藏的。
引用的定义格式为“TYPE & ”,TYPE为数据类型。在C++中是不可以单独定义的,并且在定义时就要进行初始化。引用表示一个变量的别名,对它的任何操作本质上都是在操作它所表示的变量。
引用类型揭密

引用的本质是指针,ref存储变量n地址,本质就是指针
引用类型作为函数参数
引用类型做为参数

指针类型作为参数

总结
摘自《C++反汇编与逆向技术揭秘》作者:钱林松
计算机的工作流程归根结底是输入→处理→输出的过程,而数据正是被处理的对象。作为逆向工作者,需要正确考察数据。对数据的考察有以下两点。
一. 在何处:
数据是代码加工处理的对象,而代码本身也是以二进制形式存放的,对于处理器而言,代码的本质也是数据。我们在分析的时候,会看到不同指令对数据的处理,这时首先要确定数据的存储位置,对于内存中的数据,要查看地址。有了内存地址,才能得到内存属性。我
们需要了解的属性有可读、可写、可执行。藉此,可以知道此数据是否为变量(可读写)、是否为常量(只读)、是否为代码(可执行)等。除了知道属性以外,我们还可以考察进程在内存的布局,如栈区、堆区、全局区、代码区等,藉此,又可以知道数据的作用域。到底是代码还是数据?程序员认为是代码,那就是代码;程序员认为是数据,那就是数据。其中滋味,留待读者在后面的学习中逐步体会
二. 如何解释
得到了内存地址,还是无法得到数据的正确内容,因为缺少解释方式。如“无鸡鸭也可无鱼肉也可无银钱也可”,可以解释为:“无鸡鸭也可,无鱼肉也可,无银钱也可。”也可以解释为:“无鸡,鸭也可;无鱼,肉也可;无银,钱也可。”
这两种方式又分别称为“大端方式”和“小端方式”,出自某个西方童话,内容大意是:有个小人国,争论吃鸡蛋的时候应该是先把鸡蛋的大头敲开,还是应该先把小头敲开;为此国内引发了激烈的讨论,最后导致国家分裂、爆发战争,在这场战争中,国王和一些大臣丧命。
计算机的数据存储也是这样的道理,如果约定了存储的顺序,大家就都能正确写入和读出了,没必要在意当初为什么制定这样的存储顺序。制定字节存储顺序的人可能就是想避免别人问他为什么选择这个方向,故以此典故封堵闲人之口。
一段数据在内存的地址,就确定了它的分区,就可以判断出它所具有的权限:R,W,E;根据该程序的内存布局可以得到变量的作用域;
如何判断一段内存数据的类型?
在内存中存储的数据本身并不包含类型信息,因此无法直接通过查看数据本身来准确确定其类型。数据的类型是由程序在使用数据时进行解释和解析的。
所以最好的办法还是结合该数据使用时的上下文来分析
-
变量声明:如果数据是作为变量存储的,你可以查看变量声明的位置并参考编程语言的规则来确定数据的类型。
-
上下文:有时,数据的类型可以通过上下文得到暗示。程序中可能存在与数据相关的其他代码,这些代码可能会提供关于数据类型的线索。
-
内存布局:某些数据类型在内存中具有特定的模式和布局。例如,整数类型的数据在内存中按照字节顺序存储,而浮点数类型的数据可能遵循IEEE 754标准。通过观察数据在内存中的布局,可以初步推断其可能的类型。
-
数据长度:根据数据所占用的字节数,可以大致猜测其类型。例如,一个字节的数据很可能是
char或bool类型,而四个字节的数据可能是int或float类型。然而,这种方法并不总是可靠的,因为不同的编程语言和平台可能对数据类型的大小有所不同。

![2023年中国工业脱水机行业供需分析:随着自动化和智能化技术的快速发展,销量同比增长4.9%[图]](https://img-blog.csdnimg.cn/img_convert/030a5c77df13fb3cb7a0e91bc4b3d6a4.png)

![web:[极客大挑战 2019]PHP](https://img-blog.csdnimg.cn/c704d85267ba4bd6880c23fef0cb6f8d.png)