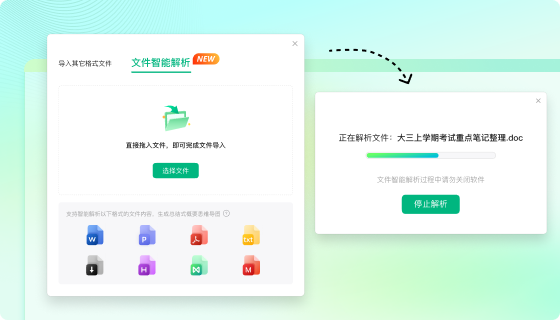
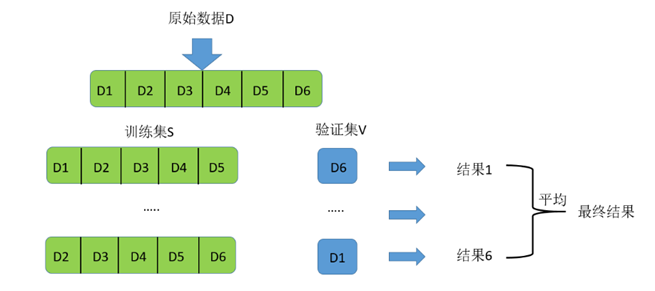
当我们拿到数据集时,首先需要对数据集进行划分训练集和测试集,sklearn提供了相应的函数供我们使用
一、讲解
快速随机划分数据集,可自定义比例进行划分训练集和测试集
二、官网API
官网API
sklearn.model_selection.train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
导包:from sklearn.model_selection import train_test_split
为了方便说明,这里以一个具体的案例进行分析
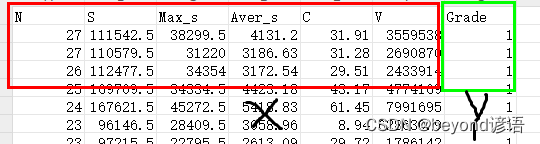
织物起球等级评定,已知织物起球个数N、织物起球总面积S、织物起球最大面积Max_s、织物起球平均面积Aver_s、对比度C、光学体积V这六个特征参数来确定最终的织物起球等级Grade
说白了:六个特征(N、S、Max_s、Aver_s、C、V),来确定最终的等级(Grade)
数据集可以自己简单整个,csv格式即可,我这里使用的是6个自变量X和1个因变量Y
参数:
①*arrays
传入因变量和自变量
这里的因变量为六个特征(N、S、Max_s、Aver_s、C、V)
自变量为最终评定的等级(Grade)
具体官网详情如下:
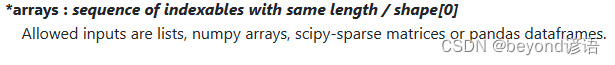
②test_size
若给该参数传入float浮点数,则范围为[0.0,1.0],表示测试集的比例
若给该参数传入int整型数,则表示测试集样本的具体数量
若为None,则设置为train_size参数的补数形式
若该test_size参数和train_size参数的值均为None,则该test_size设置为0.25,按float浮点型对待
具体官网详情如下:

③train_size
若给该参数传入float浮点数,则范围为[0.0,1.0],表示训练集的比例
若给该参数传入int整型数,则表示训练集样本的具体数量
若为None,则设置为test_size参数的补数形式
该参数跟test_size类似
具体官网详情如下:

④random_state
随机种子random_state,如果要是为了对比,需要控制变量的话,这里的随机种子最好设置为同一个整型数
具体官网详情如下:

⑤shuffle
是否在分割前对数据进行洗牌
如果 shuffle=False 则 stratify 必须为 None
具体官网详情如下:

⑥stratify
如果不是 “None”,数据将以分层方式分割,并以此作为类别标签
具体官网详情如下:

返回值:
splitting
返回一个包含训练和测试分割之后的列表
具体官网详情如下:

三、项目实战
①导包
若导入过程报错,pip安装即可
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
②加载数据集
数据集可以自己简单整个,csv格式即可,我这里使用的是6个自变量X和1个因变量Y
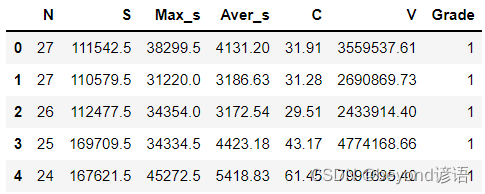
通过pandas读入文本数据集,展示前五行数据
fiber = pd.read_csv("./fiber.csv")
fiber.head(5) #展示下头5条数据信息
③划分数据集
前六列是自变量X,最后一列是因变量Y
参数:
test_size:测试集数据所占比例,这里是0.25,表示测试集占总数据集的25%
train_size:训练集数据所占比例,这里是0.75,表示训练集占总数据集的75%
random_state:随机种子,为了控制变量
shuffle:是否将数据进行打乱
因为我这里的数据集共48个,训练集0.75,测试集0.25,即训练集36个,测试集12个
返回值:
依此返回四个list,分别为训练集的自变量、测试集的自变量、训练集的因变量和测试集的因变量,分别通过X_train, X_test, y_train, y_test进行接收
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
X_train, X_test, y_train, y_test = train_test_split(X,Y,train_size=0.75,test_size=0.25,random_state=42,shuffle=True)
print(X_train.shape) #(36,6)
print(y_train.shape) #(36,)
print(X_test.shape) #(12,6)
print(y_test.shape) #(12,)
根据返回的四个list的shape可以看到数据集已经成功按自定义需求划分