一、查漏补缺、熟能生巧:
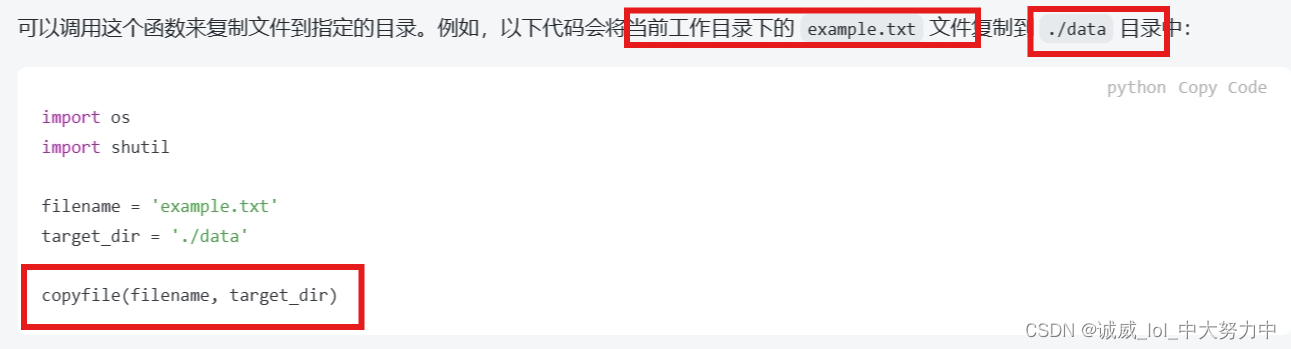
1.关于shutil.copy或者这个copyfile的作用和用法:
将对应的文件复制到对应的文件目录下
2.关于python中dict的键值对的获取方式:
#终于明白了,原来python中的键_值 对的用法就是通过调用dict.keys()和dict.values()实现的
#print(labels.keys())
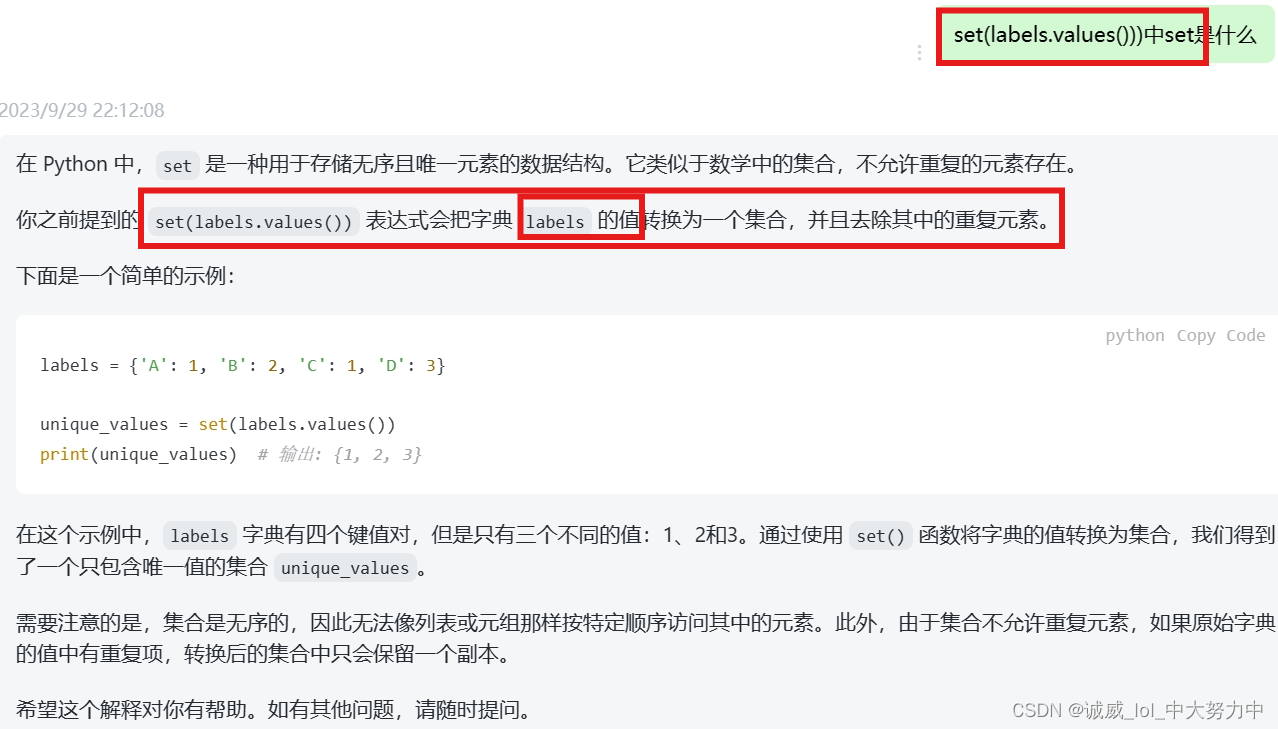
#print(labels.values())3.关于python中set创建1个集合的函数用法:
二、代码解读:
1.引入必要的库:
!pip install d2l
import collections
import math
import os
import shutil
import pandas as pd
import torch
import torchvision
from torch import nn
from d2l import torch as d2l2.将trainLabel.csv文件中的"1,truck"这种每一行的数据存储到1个dict字典数组labels中,这个字典就是键keys是序号1-n,值values就是10个类别的str像“truck,dog”这种
#这个部分是 从csv文件中读取到 所有 labels标签的信息:
data_dir = '/kaggle/input/cifar-10/' #基本的文件路径值
def read_csv_labels(fname):
"""读取fname来给标签字典返回一个文件名"""
with open(fname, 'r') as f: #将这个filename文件打开作为对象f
# 跳过文件头行(列名)
lines = f.readlines()[1:]#lines是一个数组,每个元素是str类型“id ,label”
tokens = [l.rstrip().split(',') for l in lines] #tokens是1个数组,将原来的line按照“,”分为id 和 label
return dict(((name, label) for name, label in tokens)) #返回1个dict字典的数组,由
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
#测试:(name , label)到底都是什么东西,
#print(labels[0][0],' ',labels[0][1])
print('# 训练样本 :', len(labels))
print('# 类别 :', len(set(labels.values())))
print(type(labels))3.对这个竞赛notebool本身提供的数据.zip进行解压到'/kaggle/working/'这个目录下面:
!pip install py7zr
import py7zr
# 将文件从输入目录复制到当前工作目录下(如果需要)
#!cp /kaggle/input/cifar-10/
# 解压缩 .7z 文件
with py7zr.SevenZipFile('/kaggle/input/cifar-10/train.7z', mode='r') as z:
z.extractall()
with py7zr.SevenZipFile('/kaggle/input/cifar-10/test.7z', mode='r') as z:
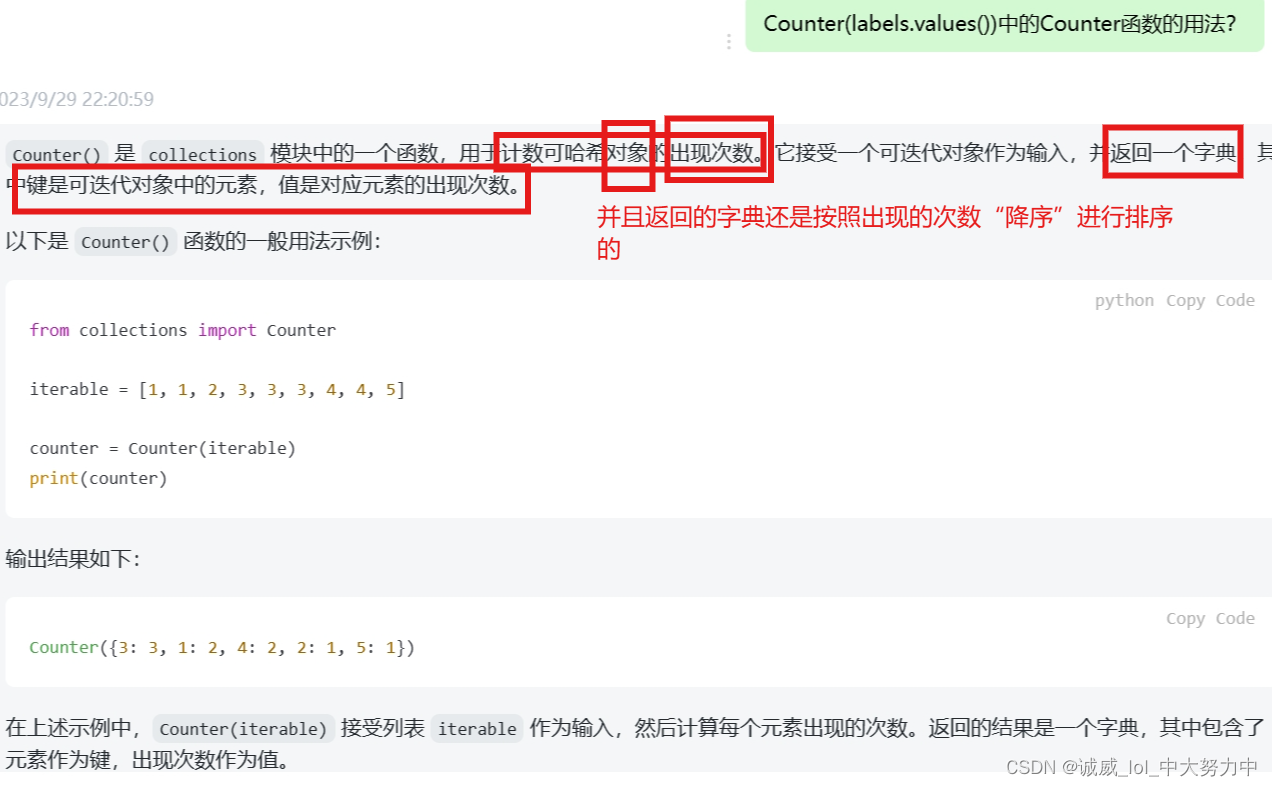
z.extractall()4.关于python中collections库中的Counter函数的用法:
......剩下的代码解读已经在kaggle上面注释好了,以后复盘的时候再搬过来好了。。。

![[尚硅谷React笔记]——第2章 React面向组件编程](https://img-blog.csdnimg.cn/215ab1c6d5de4cd8acefe976c585a768.png)