本章代码gitee仓库:布隆过滤器
文章目录
- 0. 前言
- 1. 布隆过滤器的概念
- 2. 布隆过滤器的实现
- 2.1 哈希函数
- 2.2 插入和判断
- 3. 布隆过滤器的删除
- 4. 布隆过滤器的误判
0. 前言
我们在玩某款游戏的时候,刚注册的话,我们需要取一个昵称,这个昵称不能和其他玩家的重复。
判断这个昵称是否存在,底层可以用哈希表,但是玩家的数量太多了,都是以亿这个量级来就算,那么采用哈希表就会造成大量的空间浪费;如果用位图,但位图一般只能用于处理整型数据。
那么我们就可以采用哈希表+位图,即布隆过滤器来完成检测这个昵称是否已经被注册。
1. 布隆过滤器的概念
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
2. 布隆过滤器的实现
2.1 哈希函数
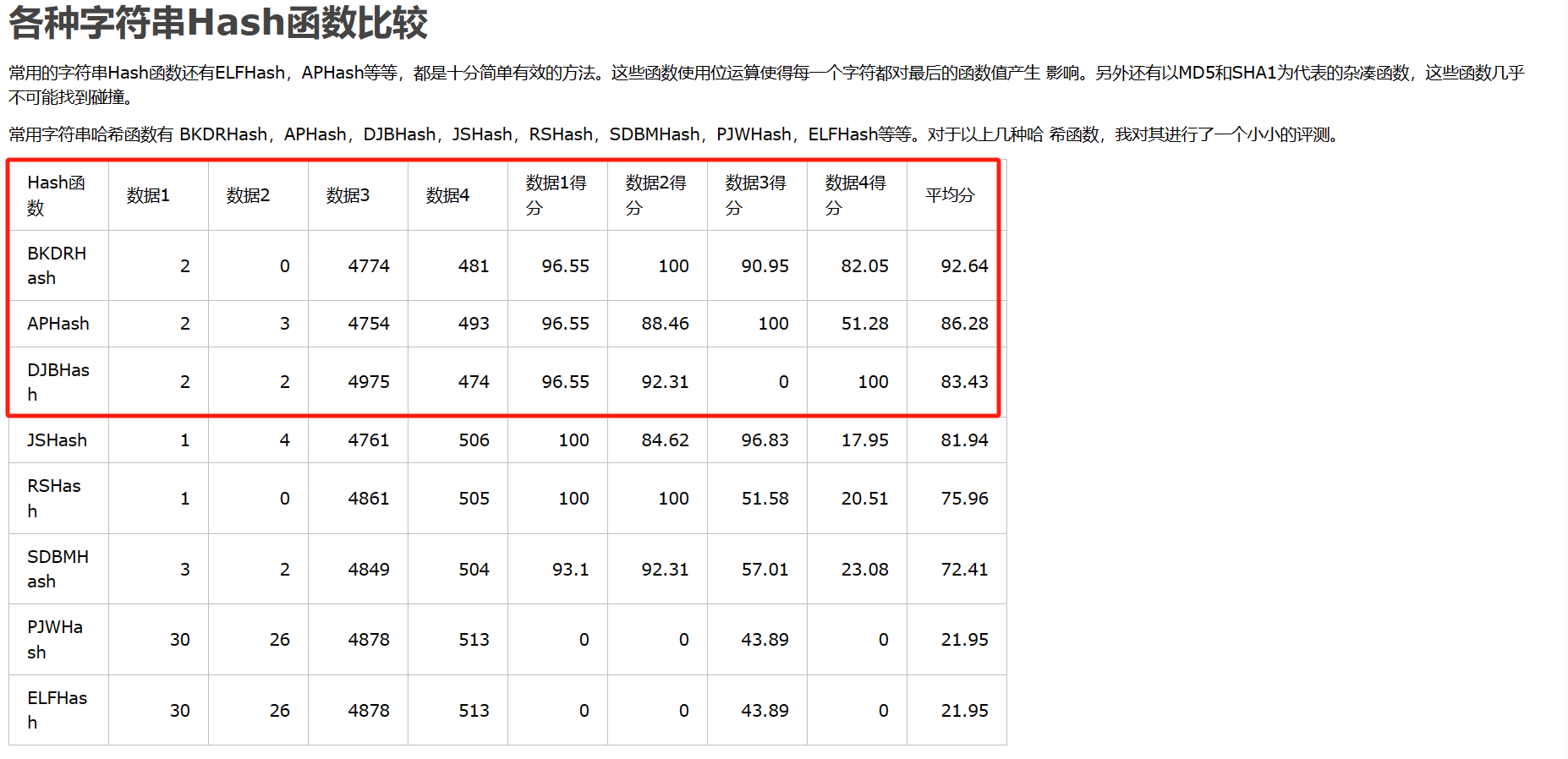
我们这里参考该文章:各种字符串Hash函数
采用排名前三的字符串哈希函数
struct BKDRHash
{
size_t operator()(const string& str)
{
register size_t hash = 0;
for (auto ch : str)
{
hash = hash * 131 + ch;
}
return hash;
}
};
struct APHash
{
size_t operator()(const string& str)
{
register size_t hash = 0;
for (size_t i = 0; i < str.size(); i++)
{
size_t ch = str[i];
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& str)
{
register size_t hash = 5381;
for (auto ch : str)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
因为这里采用的是仿函数,所以我们将这个几个哈希函数定义为结构体,然后重载
operator()进行调用
2.2 插入和判断
template<size_t N, class K = string,class Hash1 = BKDRHash, class Hash2 = APHash,class Hash3 = DJBHash>
class BloomFilter
{
public:
void Set(const K& key)
{
size_t hash1 = Hash1()(key) % N;
_bs.set(hash1);
size_t hash2 = Hash2()(key) % N;
_bs.set(hash2);
size_t hash3 = Hash3()(key) % N;
_bs.set(hash3);
}
bool Test(const K& key)
{
//为真不一定存在,为假一定不存在
size_t hash1 = Hash1()(key) % N;
if (_bs.test(hash1) == false)
return false;
size_t hash2 = Hash2()(key) % N;
if (_bs.test(hash2) == false)
return false;
size_t hash3 = Hash3()(key) % N;
if (_bs.test(hash3) == false)
return false;
return true;
}
private:
bitset<N> _bs;
};
3. 布隆过滤器的删除
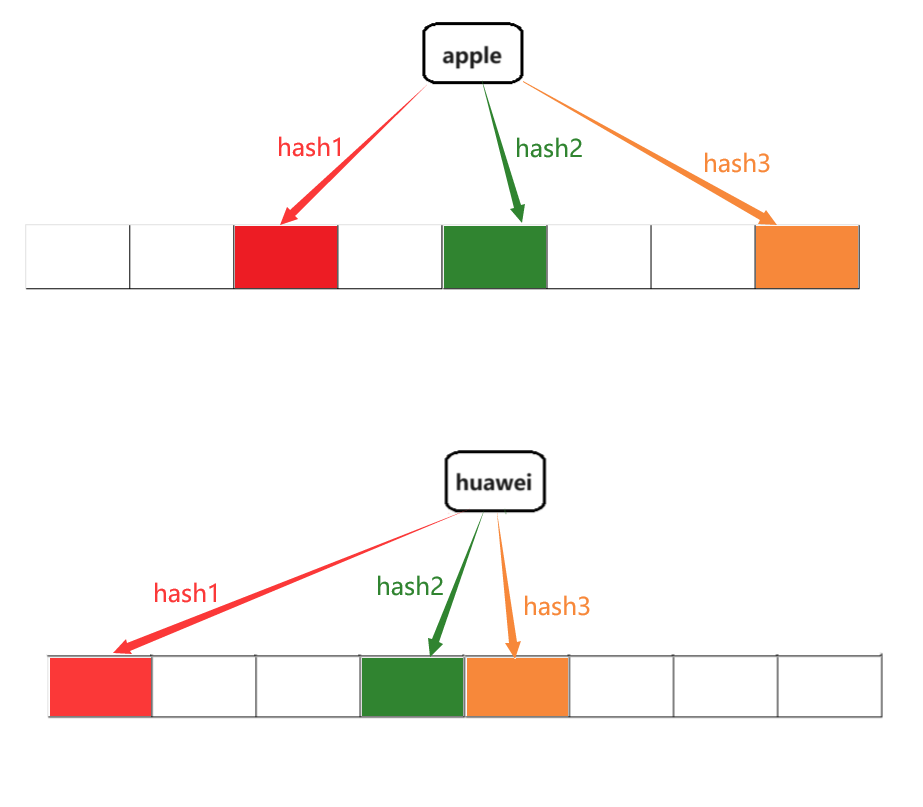
布隆过滤器不能直接支持删除操作,因为删除一个元素的时候,可能会影响其他元素
例如:我们删除
apple时,apple映射的二进制位与huawei里面有一个重叠了,那么这就会影响到huawei这个元素的判定
另外,布隆过滤器的设计初衷就是为了快速查找元素是否存在于集合中,并在一些特定应用中提供高效的去重和查询功能。它不被设计用来维护可变的数据集,因此不支持删除操作。
4. 布隆过滤器的误判
布隆过滤器是存在一定的误判率的,我们可以通过控制哈希函数和布隆过滤器长度来减小误判率
有兴趣可以参考此篇文章详解布隆过滤器的原理,使用场景和注意事项
void t2()
{
srand(time(0));
const size_t N = 10000;
BloomFilter<N*8> bf;
vector<string> v1;
string url = "https://legacy.cplusplus.com/reference/";
for (size_t i = 0; i < N; i++)
{
v1.push_back(url + to_string(i));
}
for (auto& e : v1)
{
bf.Set(e);
}
vector<string> v2;
for (size_t i = 0; i < N; i++)
{
string url = "https://legacy.cplusplus.com/reference/";
url += to_string(999999 + i);
v2.push_back(url);
}
size_t count = 0;
for (auto& e : v2)
{
if (bf.Test(e))
count++;
}
cout << "相似字符串误判率:" << (double)count / (double)N << endl;
vector<string> v3;
for (size_t i = 0; i < N; i++)
{
string url = "www.baidu.com";
url += to_string(i + rand());
v3.push_back(url);
}
size_t countDifferent = 0;
for (auto& e : v3)
{
if (bf.Test(e))
countDifferent++;
}
cout << "不相似字符串误判率:" << (double)countDifferent / (double)N << endl;
}
那么本次的分享就到这里,我们下期再见,如果还有下期的话。