Part14-Query Planning & Optimization I
SQL is Declarative,只告诉想要什么而不需要说怎么做。
IBM System R是第一个实现query optimizer查询优化器的系统
-
Heuristics / Rules
条件触发 静态规则,重写query来remove 低效或者愚蠢的东西,需要examine catalog看一些schema来判断不需要具体data。
-
Cost-based Search
使用一个代价模型来估测执行一个查询计划的代价,需要以某种方式去查看数据,枚举该SQL所有可能的不同查询方案以某种智能的方式去除多余或者愚蠢的方案。
applcation → sql rewriter → parser → binder(负责把sql查询中引用的命名对象转换为某种内部的标识符internal identifier) → tree rewriter → optimizer →
sql query → sql query → abstract syntax Tree → (name→internal ID) → Logical Plan(high level查询要干嘛) → Logical Plan → Physical Plan(DB 实际执行查询语句的方式)
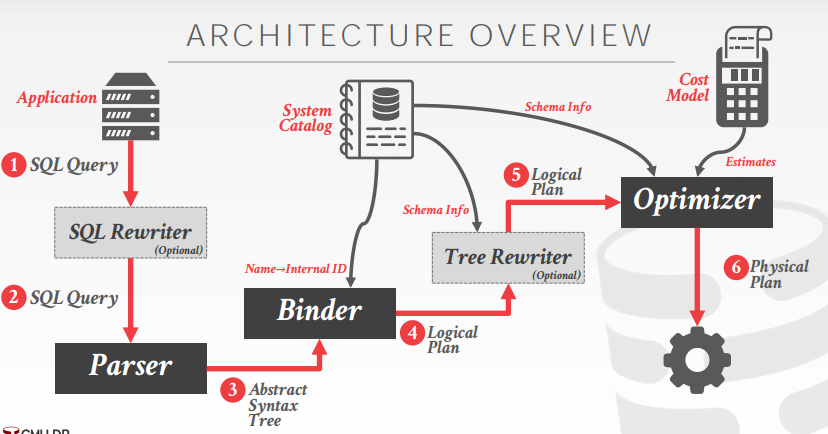
Logical VS. Physical Plans
逻辑计划相当于查询中的关系代数表达式,比如查询计划树种包含了这些关系代数的符号,但是不会说具体要用哪种方式和算法。
物理计划是实际上用来定义查询计划种执行方案的地方,具体要再查询计划种如何使用这些不同的operator,具体哪个index
Query Optimization is NP-HARD
Relational Algebra Equivalences
等价关系代数,以此来对查询计划进行等价的操作和转换,所谓的等价就是如果两个关系代数表达式能够得到相同的元组集合那就认为等价。
Predicate Pushdown
filter before the join
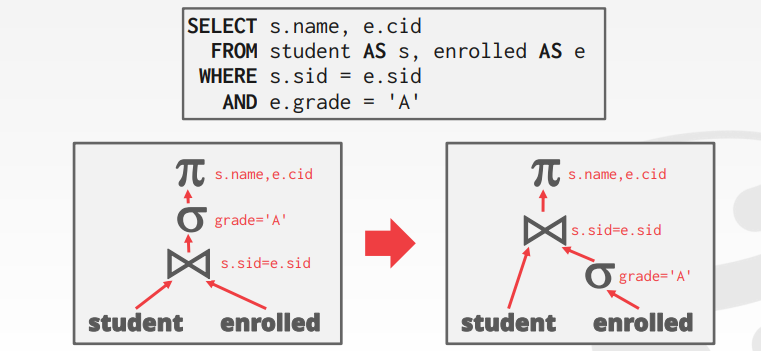
- 尽可能早过滤
- 重新排序 让最具有选择性地先进行过滤
- 拆分复杂的predicate 然后push down

Projection PushDown
尽早投影 以创建更小的tuple 减少中间结果,对行存比较关键,列存不重要。在join之前引入一个projection操作,减少列信息
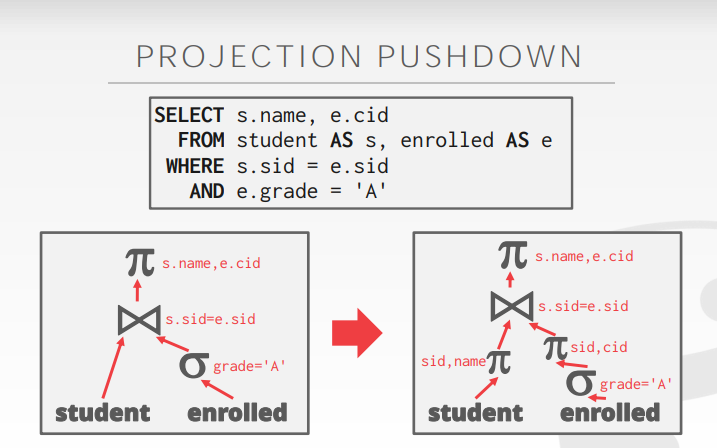
SELECT A1.*
FROM A AS A1 JOIN A AS A2
ON A1.id = A2.id;
# 等价于,中间做了个无意义的join
select * from A;
# 是不是可以用这样的例子来测试一个DB的查询优化
还可以忽略不必要的projections
select * from A AS A1
where exists(select val from A AS A2
where A1.id = A2.id);
# equal to
select * from A;
Merge Predicates
SELECT * FROM A
WHERE val BETWEEN 1 AND 100
OR val BETWEEN 50 AND 150;
# rewrite
SELECT * FROM A
WHERE val BETWEEN 1 AND 150;
查看catalog,比如写一个主键≠null或者写主键=null都会访问catalog 根据scheme进行rewrite
n-way join : 可能有 4 n 4^n 4n种,
Cost Estimation
一个查询需要多久
- CPU:small cost,tough to estimate
- Disk:block transfers
- Memory: Amount of DRAM used
- Network: 分布式情况下考虑rtt messages
真正知道物理代价只有通过去运行,但是代价太高,所以使用代价模型估测,而预估查询的成本是通过在内部维护表的相关信息来做的。
Statistic
internal statistic,维护索引、表、元组中的值的有关的元数据
Manual invocations:
- pg/SQL LITE:ANALYZE
- Oracle/Mysql: ANALYZE TABLE
- SQL Server: UPDATE STATISTICS
- DB2: RUNSTATS