Tsetlin Machines
记录一下学习TM的过程,主要是对书本An Introduction to Tsetlin Machines的学习。
第一章
作者使用了2个例子来举例说明,我们这里选择车辆和飞机来进行举例。
也就通过5个特征,4个轮子,是否载人,是否有翅膀,是否蓝色,是否黄色来进行判断车辆和飞机。
1.1布尔特征
Tsetlin 机器观察它识别的物体(或现象)根据物体的特征。 每个特征都是一个对象属性,要么
是 True 或 False,使其成为布尔值。

就算是同一个类也会有不同特征。
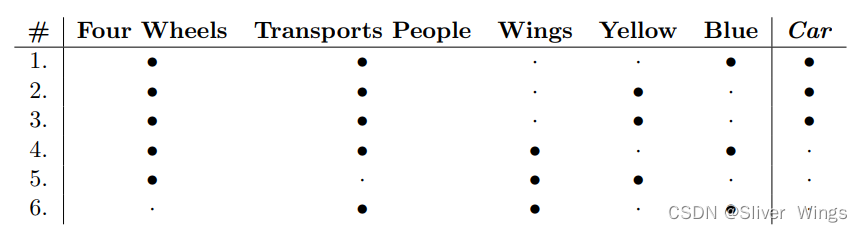
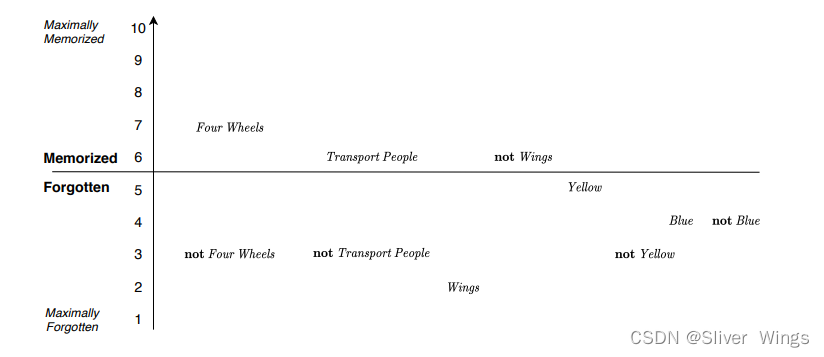
大黑点表示1,小黑点表示0。从上面可以看出,对车辆识别的关键是,是不是四轮,颜色之类的是其次的。
这个表格在后面会用到很多次。
1.2 使用与和非创建模式
if-then规则
if 条件 then 类别
(与)Four Wheels and Transports People then car
可以对应上表当中的1,2,3,4,3个车和1个飞机。
(非) if Four Wheels and Transports People and not Wings then Car .
没有翅膀这个特征是其能分辨汽车和飞机。
特征和否定特征被称为文字。
1.3 通过识别和消除反馈来学习频繁模式

if Four Wheels and Transports People and Blue then Car .它的记忆模式,此后的变化都是在次基础上的。
注意这里是有指明是蓝色车辆,保留在内存中,直到将其删除。如果一辆车出现另一种颜色时,规则不会将该对象识别为汽车(详细的说明在后面)。
这里补充一个概率,我的理解是记忆程度。
使用1-5和6-10来表示记忆程度。1-5表示忘记,6-10表示记住,数字大小表示程度。
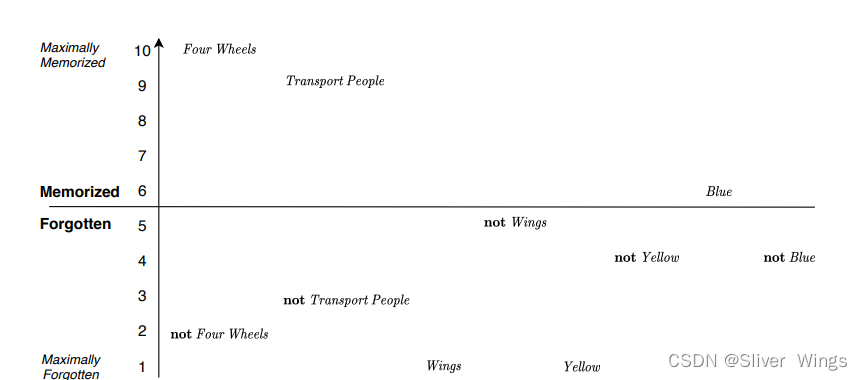
4轮就表示记忆得最深,翅膀和黄色就几乎没有被记忆。
每个特征和它的否定版本共存于记忆之中。如果“四轮”为真,那么“非四轮”就变为“假”,所以TM通过
忘记计算结果为 False 的文字组合,也就是只记忆结果为True的文字。
学习单一规则
理解完整的 Tsetlin 机器如何学习的关键是学习单个 if-then 规则如何自行学习。 通过独立学习,每个规则变得更加独立并且更容易理解。 这样的好处是,独立学习还可以适应并行处理。 多个规则如何间接协调而无需
互相了解,提供简单而有效的方法

随机初始化,每个位置初始值为5。初始化确实不会影响学习的最终结果,因为 Tsetlin 机器是自我纠正的。
这与所谓的神经网络学习形成对比。(神经网络学习对初始化更敏感)
当遇到需要学习的目标的时候会进行下面的操作:
(1) 检测目标文字
(2) 1成立的话,记住该对象的 True 文字。通过增加其在内存中的位置来实现文字,直到10为止。
通过将 False 文字推向最大程度来忘记它们, 通过减少字面量的位置可以忘记它,直到1为止
这种反馈的名称是“识别反馈”,因为它使规则的条件部分模仿观察到的对象。
(3) 也就是1不满足,直接将该文字的所有值全部删除,也就是到1的位置。
这种类型的反馈的名称是擦除反馈,因 它会删除规则的条件部分。
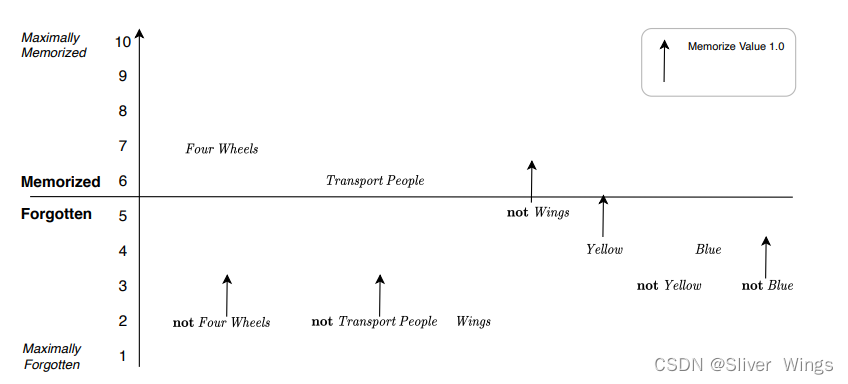
记忆和遗忘速度。 记忆值决定规则记住文字的速度有多快。 相反,遗忘值决定在没有观察的情况下,规则被遗忘的速度有多快。 如果你增加记忆值并减少遗忘值,规则将记住文字的时间更长。 更长时间地记住文字可以让规则
保留更多细节。 在极端情况下,记忆值为 1.0 且忘记值 0.0 使规则记住单个对象的每个 True 文字。相反,记住值 0.0 并忘记值 1.0 会使规则失效 记住任何东西。 通常保持这种关系:忘记值+记住值=1.0。 原因是你可以从另一个获取一个,因此您只需指定其中之一。 或者,您可以将“记忆值”固定为 1.0。
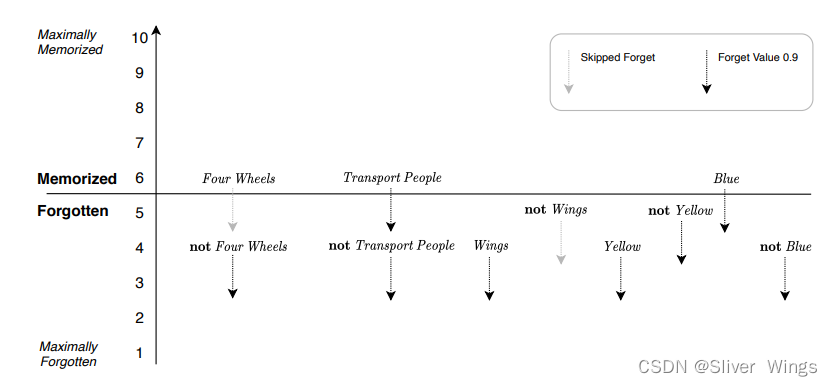
第一个例子遍历表1.1中的数据,使用Memorize Value 0.1和Forget Value 0.9。 考虑一个预测汽车的规则。检测类型为“汽车”,因此“识别”或“删除反馈”均适用。 它有五个真实文字:四轮、载人,没有翅膀,不是黄色,蓝色。 其余的文字都是 False(上面表格对应的第一个)。
一开始,记忆值为忘记状态,也就是处于5的位置,和上面的初始化是一样的,(1)状态肯定为true。
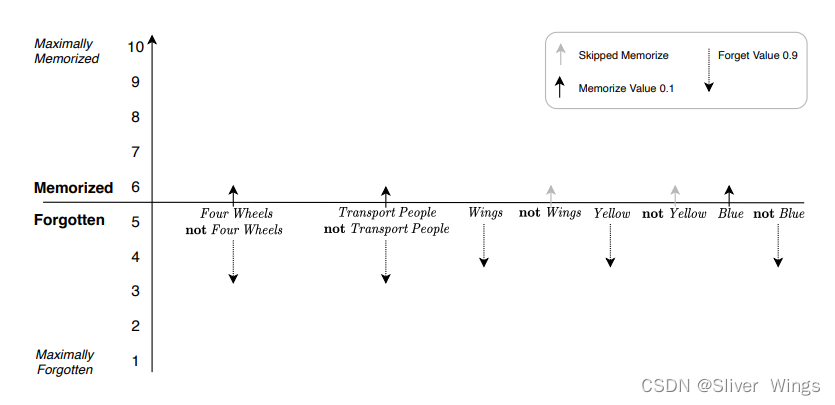
实线箭头可视化了“识别反馈”如何随机增量文字的记忆值。 因为记忆小值为 0.1,只会发生少量增量,因此
短箭头。 四轮、载人和蓝色。 然后不是翅膀也不是黄色留在原处,由图中的灰色箭头表示。这里他们2个没有增加的原因是增加的记忆值是随机的,而TM设置了一个阈值0.5,只有增加的值大于0.5,它的记忆值才会增加,这里他们两个是因为随机化给到的值小于0.5才没有增加。
相反,图中的虚线箭头可视化随机递减 对于 False 文字。 这些箭头被可视化为更长,因为遗忘值更高(0.9)。
现在规则更新为:
if Four Wheels and Transports People and Blue then Car
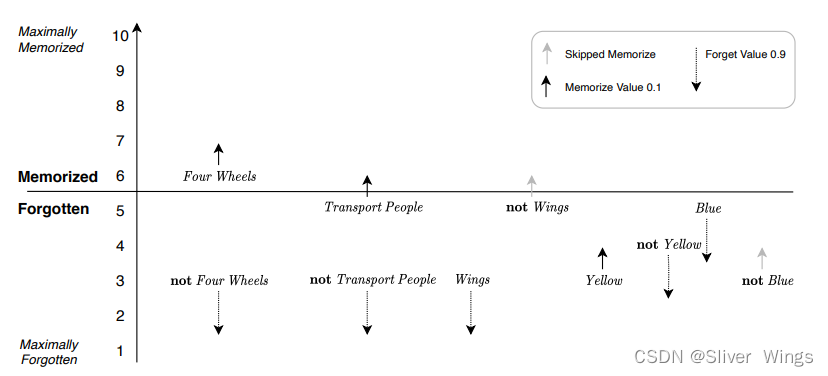
第二个例子对应表格的第二个,这时候车的颜色对不上,因此,使用“删除反馈”。作为可视化,擦除反馈随机减少所有的记忆位置的文字。 执行这些减量,使用四轮和没有翅膀来模拟随机化(由灰色箭头表示)。
新的规则就变成了:
if Four Wheels then Car .
第三个例子对应表格的第三个,这次规则的条件匹配上
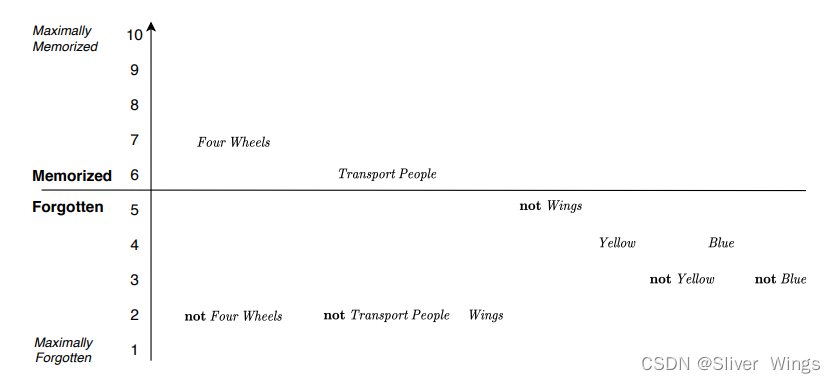
规则就变成了
if Four Wheels and Transports People then Car .
可以发现,变化从一辆车到另一辆车,每种颜色的出现频率太低,难以记住,不是四轮,不是载人,有翅膀很快就被遗忘了,而4轮和载人的特征比较容易记住。
1.4 通过拒绝反馈提高辨别能力
上面我们讨论的是对一个类car的分类,但是4轮,载客满足这个的还有飞机或者其他的。所以需要额外的反馈来区分。
当它面对与其类别不同的物体,直接跳过(2)、(3)Recognize and Erase Feedback,直接进行下面的步骤(4):
(4)通过评估对象的文字来检查规则的条件部分是否为 True。如果条件部分为 True,则记住该对象的所有为 False 的 Forgotten 文字。当前类别选择遗忘的信息。
下面举个例子,
之前是car,现在遇到了plane,对应表格中4,
a Plane with Four Wheels that Transports People, is Blue (not Yellow), and has Wings
not Four Wheels, not Transports People, not Wings, Yellow, and not Blue.
4个车轮,载人,有翅膀,蓝色(非黄色)到 没有4个车轮,不载人,没有翅膀,黄色(非蓝色)
它吧, not Wings没有翅膀变成了条件有5-6
这时条件变成:
if Four Wheels and Transports People and not Wings then Car .
下次规则面临时一架飞机,它不再需要更新,因为它的状况将是错误的,not wings和wings。现在它可以区分汽车和飞机。
1.5 将各个部分放在一起——几条规则如何协调
分类。 Tsetlin 机器通过投票对输入进行分类。也就是说,单个规则本身并不能获得对类别的最终决定权。相反,它为其类别投票,多数票决定输出。
示例:表格中的4,按照之前的学习会得到下面的规则条件:
R1 if Four Wheels and Transports People and not Wings then Car .
R2 if Wings then Plane.
规则 R1 与车辆不匹配,因为它指定的不是 Wings。 因此,汽车没有投票权。 另一方面,规则 R2 匹配。 所以,飞机得到了
投票并赢得多数票。 Tsetlin 机器然后输出 Plane。当然条件可能不止这些,TM越多,需要投票的次数越多。
1.6 学习协调
现已经知道单个规则是如何学习的。 接下来讨论多个规则如何协调学习,在对象分类中发挥不同的作用。
TM通过投票差值协调多个规则的学习。 选票差额是一个整数,用于在获胜类别和失败类别之间创建差额。 如果您将选票差额设置为 2,您就告诉 Tsetlin 机器获胜类别必须比失败类别多出两票。 然后,它必须尝试在学习过程中对其观察到的每个对象满足这一要求。 通过这种方式,Tsetlin 机器创建了补充规则。 在下文中,您可以使用 2 的投票差额来进行说明。
1.观察一个新对象及其类。 观察包括对象的文字(参见第 1.1 节)。
2. 使用文字的真值评估每个规则的条件(参见第 1.2 节)。
3. 计算投票总和(参见第1.5节):
a) 确定条件为 True 的规则。 使用这些进行投票。
b) 将支持该对象类别的票数相加。
c) 减去支持其他类别的票数。
d) 将求和结果称为v。
e) 如果大于 2,则将 v 设置为投票余量 2;如果小于,则将 v 设置为 -2.
4. 遍历每条规则,if(Rand() <=(2-v)/4) 则给出反馈,执行下面规则:
a) 如果规则属于这个类,则提供规则“识别”或“删除”反馈(参见第 1.3 节)。
b) 如果它属于另一个类,则给出规则“拒绝反馈”(参考第 1.4 节)。
5.回到1.