今日,辗转反侧,该💩的代码就是跑不成功,来看看 COCODataSet 到底是怎么写的,本文只参考当前版本的代码,当前版本 PaddleDetection2.5 COCODataSet 源码见附录
COCODataSet 类内部就三个函数:
__init__
parse_dataset
_sample_empty # 该函数供 parse_dataset 调用
来看一下 COCODataSet 的基类实现函数,咱挨个看
__init__
__len__
__call__
__getitem__
check_or_download_dataset
set_kwargs
set_transform
set_epoch
parse_dataset
get_anno
1. 基类parse_dataset
def parse_dataset(self, ):
raise NotImplementedError(
"Need to implement parse_dataset method of Dataset")
该类必须要被继承之后实现该方法,继承该类中必须解析数据集,并将数据集中的内容传给变量 self.roidbs,具体内容之后看, self.roidbs 变量是一个列表,每一项都是一张照片的内容
parse_dataset 唯一要做的一件事就是解析数据并传给变量 self.roidbs
self.roidbs 中一个 item 是:
{'gt_bbox': array([[133.51, 24.77, 366.11, 562.92]], dtype=float32),
'gt_class': array([[14]], dtype=int32),
'h': 640.0,
'im_file': 'dataset/coco/COCO/val2017/000000270705.jpg',
'im_id': array([270705]),
'is_crowd': array([[0]], dtype=int32),
'w': 475.0}
2. 基类__len__
def __len__(self, ):
return len(self.roidbs) * self.repeat
len(self.roidbs) 就是原始数据的内容,self.repeat 是重复次数,所以在__getitem__ 有这么一句:
if self.repeat > 1:
idx %= n
用来进行重复操作
3. 基类__call__
def __call__(self, *args, **kwargs):
return self
做这个操作其实没啥说的了,实例化之后call一下还是返回自己
4. 基类其他不重要函数
- 设置部分,用来设置自身的属性,基本没被调用
def set_kwargs(self, **kwargs):
self.mixup_epoch = kwargs.get('mixup_epoch', -1)
self.cutmix_epoch = kwargs.get('cutmix_epoch', -1)
self.mosaic_epoch = kwargs.get('mosaic_epoch', -1)
def set_transform(self, transform):
self.transform = transform
def set_epoch(self, epoch_id):
self._epoch = epoch_id
- 获取部分:
def get_anno(self):
if self.anno_path is None:
return
return os.path.join(self.dataset_dir, self.anno_path)
获取标注 ann.json 的路径
- 检查数据路径函数,也没被调用,不重要跳过
def check_or_download_dataset(self):
self.dataset_dir = get_dataset_path(self.dataset_dir, self.anno_path,
self.image_dir)
以上函数供 read 在 dataset类 外部调用(之后会讲到)

所以 self.mixup_epoch , self.cutmix_epoch 和 self.mosaic_epoch 默认值都是 -1
5. 基类 __getitem__ 函数
def __getitem__(self, idx):
# ------- 用来进行重复操作的部分 -------
n = len(self.roidbs)
if self.repeat > 1:
idx %= n
# ------- 深拷贝当前的数据项 -------
roidb = copy.deepcopy(self.roidbs[idx])
# 以下仨 if 和数据增强有关
if self.mixup_epoch == 0 or self._epoch < self.mixup_epoch:
idx = np.random.randint(n)
roidb = [roidb, copy.deepcopy(self.roidbs[idx])]
elif self.cutmix_epoch == 0 or self._epoch < self.cutmix_epoch:
idx = np.random.randint(n)
roidb = [roidb, copy.deepcopy(self.roidbs[idx])]
elif self.mosaic_epoch == 0 or self._epoch < self.mosaic_epoch:
roidb = [roidb, ] + [
copy.deepcopy(self.roidbs[np.random.randint(n)])
for _ in range(4)
]
# ------- 设置 curr_iter -------
if isinstance(roidb, Sequence):
for r in roidb:
r['curr_iter'] = self._curr_iter
else:
roidb['curr_iter'] = self._curr_iter
self._curr_iter += 1
# ------- 对当前数据项进行之前的 transform -------
return self.transform(roidb)
6. 基类 __init__ 函数
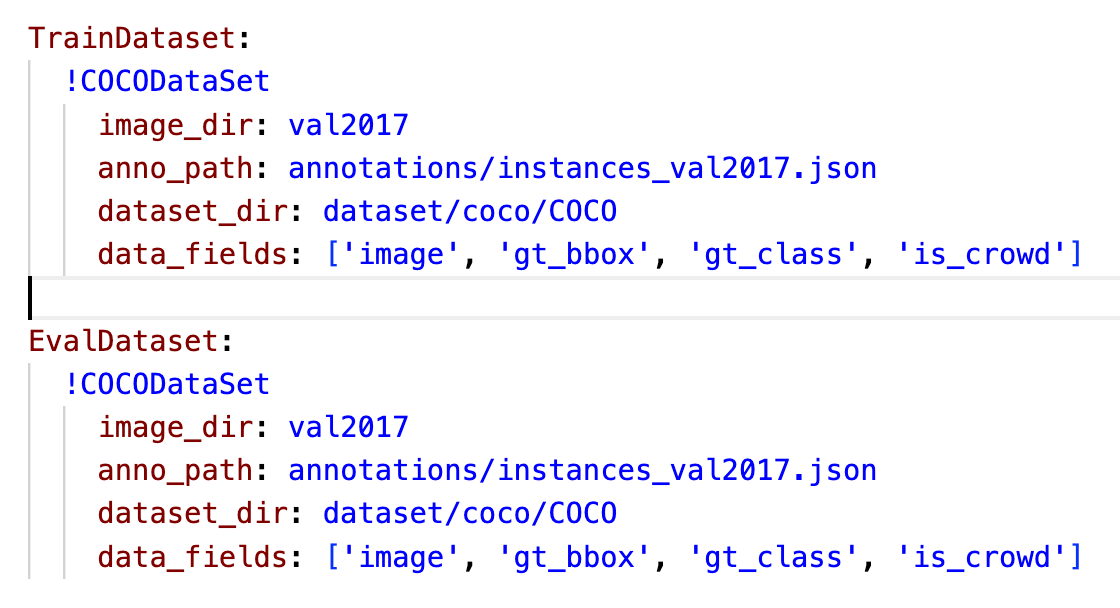
self.dataset_dir = dataset_dir if dataset_dir is not None else ''
self.anno_path = anno_path
self.image_dir = image_dir if image_dir is not None else ''
self.data_fields = data_fields
看上边这4个参数,是和 yaml 文件中的内容是对应的:
基本都在 parse_dataset 调用
self.sample_num = sample_num # parse_dataset 中调用
self.use_default_label = use_default_label # 这个变量可能是 COCO 每个id对应的类名? 暂时没发现使用处
self.repeat = repeat
self._epoch = 0
self._curr_iter = 0
5. 子类 parse_dataset 函数
明天再说,睡了
附录
顺便备份一下当前版本PaddleDetection2.5的 COCODataSet 代码
class COCODataSet(DetDataset):
"""
Load dataset with COCO format.
Args:
dataset_dir (str): root directory for dataset.
image_dir (str): directory for images.
anno_path (str): coco annotation file path.
data_fields (list): key name of data dictionary, at least have 'image'.
sample_num (int): number of samples to load, -1 means all.
load_crowd (bool): whether to load crowded ground-truth.
False as default
allow_empty (bool): whether to load empty entry. False as default
empty_ratio (float): the ratio of empty record number to total
record's, if empty_ratio is out of [0. ,1.), do not sample the
records and use all the empty entries. 1. as default
repeat (int): repeat times for dataset, use in benchmark.
"""
def __init__(self,
dataset_dir=None,
image_dir=None,
anno_path=None,
data_fields=['image'],
sample_num=-1,
load_crowd=False,
allow_empty=False,
empty_ratio=1.,
repeat=1):
super(COCODataSet, self).__init__(
dataset_dir,
image_dir,
anno_path,
data_fields,
sample_num,
repeat=repeat)
self.load_image_only = False
self.load_semantic = False
self.load_crowd = load_crowd
self.allow_empty = allow_empty
self.empty_ratio = empty_ratio
def _sample_empty(self, records, num):
# if empty_ratio is out of [0. ,1.), do not sample the records
if self.empty_ratio < 0. or self.empty_ratio >= 1.:
return records
import random
sample_num = min(
int(num * self.empty_ratio / (1 - self.empty_ratio)), len(records))
records = random.sample(records, sample_num)
return records
def parse_dataset(self):
anno_path = os.path.join(self.dataset_dir, self.anno_path)
image_dir = os.path.join(self.dataset_dir, self.image_dir)
assert anno_path.endswith('.json'), \
'invalid coco annotation file: ' + anno_path
from pycocotools.coco import COCO
coco = COCO(anno_path)
img_ids = coco.getImgIds()
img_ids.sort()
cat_ids = coco.getCatIds()
records = []
empty_records = []
ct = 0
self.catid2clsid = dict({catid: i for i, catid in enumerate(cat_ids)})
self.cname2cid = dict({
coco.loadCats(catid)[0]['name']: clsid
for catid, clsid in self.catid2clsid.items()
})
if 'annotations' not in coco.dataset:
self.load_image_only = True
logger.warning('Annotation file: {} does not contains ground truth '
'and load image information only.'.format(anno_path))
for img_id in img_ids:
img_anno = coco.loadImgs([img_id])[0]
im_fname = img_anno['file_name']
im_w = float(img_anno['width'])
im_h = float(img_anno['height'])
im_path = os.path.join(image_dir,
im_fname) if image_dir else im_fname
is_empty = False
if not os.path.exists(im_path):
logger.warning('Illegal image file: {}, and it will be '
'ignored'.format(im_path))
continue
if im_w < 0 or im_h < 0:
logger.warning('Illegal width: {} or height: {} in annotation, '
'and im_id: {} will be ignored'.format(
im_w, im_h, img_id))
continue
coco_rec = {
'im_file': im_path,
'im_id': np.array([img_id]),
'h': im_h,
'w': im_w,
} if 'image' in self.data_fields else {}
if not self.load_image_only:
ins_anno_ids = coco.getAnnIds(
imgIds=[img_id], iscrowd=None if self.load_crowd else False)
instances = coco.loadAnns(ins_anno_ids)
bboxes = []
is_rbox_anno = False
for inst in instances:
# check gt bbox
if inst.get('ignore', False):
continue
if 'bbox' not in inst.keys():
continue
else:
if not any(np.array(inst['bbox'])):
continue
x1, y1, box_w, box_h = inst['bbox']
x2 = x1 + box_w
y2 = y1 + box_h
eps = 1e-5
if inst['area'] > 0 and x2 - x1 > eps and y2 - y1 > eps:
inst['clean_bbox'] = [
round(float(x), 3) for x in [x1, y1, x2, y2]
]
bboxes.append(inst)
else:
logger.warning(
'Found an invalid bbox in annotations: im_id: {}, '
'area: {} x1: {}, y1: {}, x2: {}, y2: {}.'.format(
img_id, float(inst['area']), x1, y1, x2, y2))
num_bbox = len(bboxes)
if num_bbox <= 0 and not self.allow_empty:
continue
elif num_bbox <= 0:
is_empty = True
gt_bbox = np.zeros((num_bbox, 4), dtype=np.float32)
gt_class = np.zeros((num_bbox, 1), dtype=np.int32)
is_crowd = np.zeros((num_bbox, 1), dtype=np.int32)
gt_poly = [None] * num_bbox
has_segmentation = False
for i, box in enumerate(bboxes):
catid = box['category_id']
gt_class[i][0] = self.catid2clsid[catid]
gt_bbox[i, :] = box['clean_bbox']
is_crowd[i][0] = box['iscrowd']
# check RLE format
if 'segmentation' in box and box['iscrowd'] == 1:
gt_poly[i] = [[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]]
elif 'segmentation' in box and box['segmentation']:
if not np.array(box['segmentation']
).size > 0 and not self.allow_empty:
bboxes.pop(i)
gt_poly.pop(i)
np.delete(is_crowd, i)
np.delete(gt_class, i)
np.delete(gt_bbox, i)
else:
gt_poly[i] = box['segmentation']
has_segmentation = True
if has_segmentation and not any(
gt_poly) and not self.allow_empty:
continue
gt_rec = {
'is_crowd': is_crowd,
'gt_class': gt_class,
'gt_bbox': gt_bbox,
'gt_poly': gt_poly,
}
for k, v in gt_rec.items():
if k in self.data_fields:
coco_rec[k] = v
# TODO: remove load_semantic
if self.load_semantic and 'semantic' in self.data_fields:
seg_path = os.path.join(self.dataset_dir, 'stuffthingmaps',
'train2017', im_fname[:-3] + 'png')
coco_rec.update({'semantic': seg_path})
logger.debug('Load file: {}, im_id: {}, h: {}, w: {}.'.format(
im_path, img_id, im_h, im_w))
if is_empty:
empty_records.append(coco_rec)
else:
records.append(coco_rec)
ct += 1
if self.sample_num > 0 and ct >= self.sample_num:
break
assert ct > 0, 'not found any coco record in %s' % (anno_path)
logger.debug('{} samples in file {}'.format(ct, anno_path))
if self.allow_empty and len(empty_records) > 0:
empty_records = self._sample_empty(empty_records, len(records))
records += empty_records
self.roidbs = records
其基类 DetDataset :
from paddle.io import Dataset
class DetDataset(Dataset):
"""
Load detection dataset.
Args:
dataset_dir (str): root directory for dataset.
image_dir (str): directory for images.
anno_path (str): annotation file path.
data_fields (list): key name of data dictionary, at least have 'image'.
sample_num (int): number of samples to load, -1 means all.
use_default_label (bool): whether to load default label list.
repeat (int): repeat times for dataset, use in benchmark.
"""
def __init__(self,
dataset_dir=None,
image_dir=None,
anno_path=None,
data_fields=['image'],
sample_num=-1,
use_default_label=None,
repeat=1,
**kwargs):
super(DetDataset, self).__init__()
self.dataset_dir = dataset_dir if dataset_dir is not None else ''
self.anno_path = anno_path
self.image_dir = image_dir if image_dir is not None else ''
self.data_fields = data_fields
self.sample_num = sample_num
self.use_default_label = use_default_label
self.repeat = repeat
self._epoch = 0
self._curr_iter = 0
def __len__(self, ):
return len(self.roidbs) * self.repeat
def __call__(self, *args, **kwargs):
return self
def __getitem__(self, idx):
n = len(self.roidbs)
if self.repeat > 1:
idx %= n
# data batch
roidb = copy.deepcopy(self.roidbs[idx])
if self.mixup_epoch == 0 or self._epoch < self.mixup_epoch:
idx = np.random.randint(n)
roidb = [roidb, copy.deepcopy(self.roidbs[idx])]
elif self.cutmix_epoch == 0 or self._epoch < self.cutmix_epoch:
idx = np.random.randint(n)
roidb = [roidb, copy.deepcopy(self.roidbs[idx])]
elif self.mosaic_epoch == 0 or self._epoch < self.mosaic_epoch:
roidb = [roidb, ] + [
copy.deepcopy(self.roidbs[np.random.randint(n)])
for _ in range(4)
]
if isinstance(roidb, Sequence):
for r in roidb:
r['curr_iter'] = self._curr_iter
else:
roidb['curr_iter'] = self._curr_iter
self._curr_iter += 1
# roidb['num_classes'] = len(self.catid2clsid) # COCODataset 80 cls
return self.transform(roidb)
def check_or_download_dataset(self):
self.dataset_dir = get_dataset_path(self.dataset_dir, self.anno_path,
self.image_dir)
def set_kwargs(self, **kwargs):
self.mixup_epoch = kwargs.get('mixup_epoch', -1)
self.cutmix_epoch = kwargs.get('cutmix_epoch', -1)
self.mosaic_epoch = kwargs.get('mosaic_epoch', -1)
def set_transform(self, transform):
self.transform = transform
def set_epoch(self, epoch_id):
self._epoch = epoch_id
def parse_dataset(self, ):
raise NotImplementedError(
"Need to implement parse_dataset method of Dataset")
def get_anno(self):
if self.anno_path is None:
return
return os.path.join(self.dataset_dir, self.anno_path)