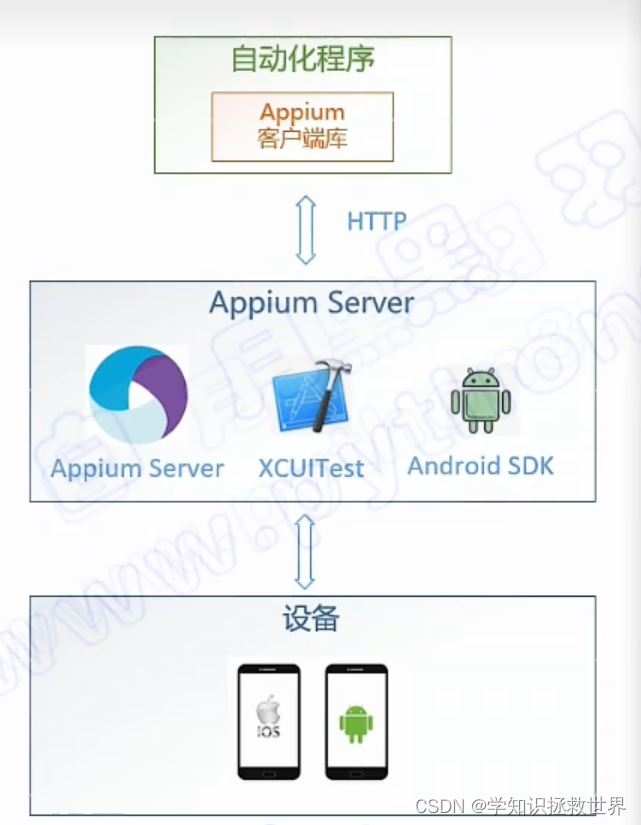
蛋白质在初级水平上由一系列氨基酸链组成。它们可以折叠成3D结构,以执行许多生物功能。最近在图神经网络、扩散模型和3D几何建模方面的突破使得机器学习可以加速发现新蛋白质。在这一部分,我们将重点关注蛋白质科学中的三个人工智能主题,包括蛋白质折叠(蛋白质结构预测)在第6.2节,蛋白质表示学习在第6.3节,蛋白质骨架结构生成在第6.4节。
6.1 概述
作者:Keqiang Yan、Limei Wang、Cong Fu、Tianfan Fu、Yi Liu、Jimeng Sun、Shuiwang Ji
我们首先给出蛋白质不同层次结构的正式定义,然后介绍蛋白质折叠、蛋白质表示学习和蛋白质骨架生成任务。之后,我们介绍了需要考虑的后两个任务的几何约束。该部分的概述如图24所示。
我们首先描述蛋白质的四级结构。(1)氨基酸是蛋白质的基本构建单元。蛋白质由氨基酸链组成,每个氨基酸包含氮(N)、α-碳(C𝛼)、碳(C)和氧(O)原子,以及侧链中的原子(称为R-基团)。侧链决定了氨基酸的类别。氨基酸链也被称为蛋白质的初级结构;(2)基于初级结构,二级结构是基于蛋白质主链内部相互作用而形成的局部折叠结构;(3)三级结构是单个多肽链(多肽链指的是由肽键连接在一起的氨基酸字符串)的三维结构;(4)四级结构描述了多个多肽链之间的关联。它们以不同复杂性级别表征了蛋白质的结构。在本文中,我们主要关注初级和三级结构。
蛋白质结构的符号:从形式上看,全原子级别的蛋白质结构可以表示为

这里 𝒛 = [𝑧 , ..., 𝑧 ] ∈ Z𝑛 是氨基酸类型向量,其中每个 𝑧 表示第 𝑖-个氨基酸的类型,𝑛 表示蛋白质中的氨基酸数量。生物体中用于构建蛋白质的通常发生的氨基酸有20种。氨基酸链代表了蛋白质的初级结构,并折叠成3D结构,其中 C = [C1, ..., C𝑛] ∈ R𝑛×𝑘×3 表示蛋白质的坐标矩阵。请注意,与其他部分不同,我们在本节中使用 C 来表示坐标矩阵,以避免与碳原子 𝐶 的符号冲突。每个 C𝑖 包括氨基酸 𝑖 中所有原子的坐标,包括 𝑁、C𝛼、C、O 和侧链原子。𝑘 是每个氨基酸中原子的最大数量。如果我们只考虑每个氨基酸中的 C𝛼 原子,那么蛋白质结构可以表示为

C𝐶𝛼 = [𝒄𝐶𝛼 , ..., 𝒄𝐶𝛼 ] ∈ R3×𝑛 表示 𝐶𝛼 原子的坐标矩阵。类似地,蛋白质的主链结构可以表示为:
1𝑛𝛼 主链结构可以表示为:

C𝐶𝛼 = [𝒄𝐶𝛼, ..., 𝒄𝐶𝛼] ∈ R3×𝑛,C𝑁 = [𝒄𝑁, ..., 𝒄𝑁] ∈ R3×𝑛,以及 C𝐶 = [𝒄𝐶, ..., 𝒄𝐶] ∈ R3×𝑛 分别表示 𝐶𝛼、𝑁 和 𝐶 原子的坐标矩阵。在接下来的部分中,P 用于表示蛋白质结构的一般表示。

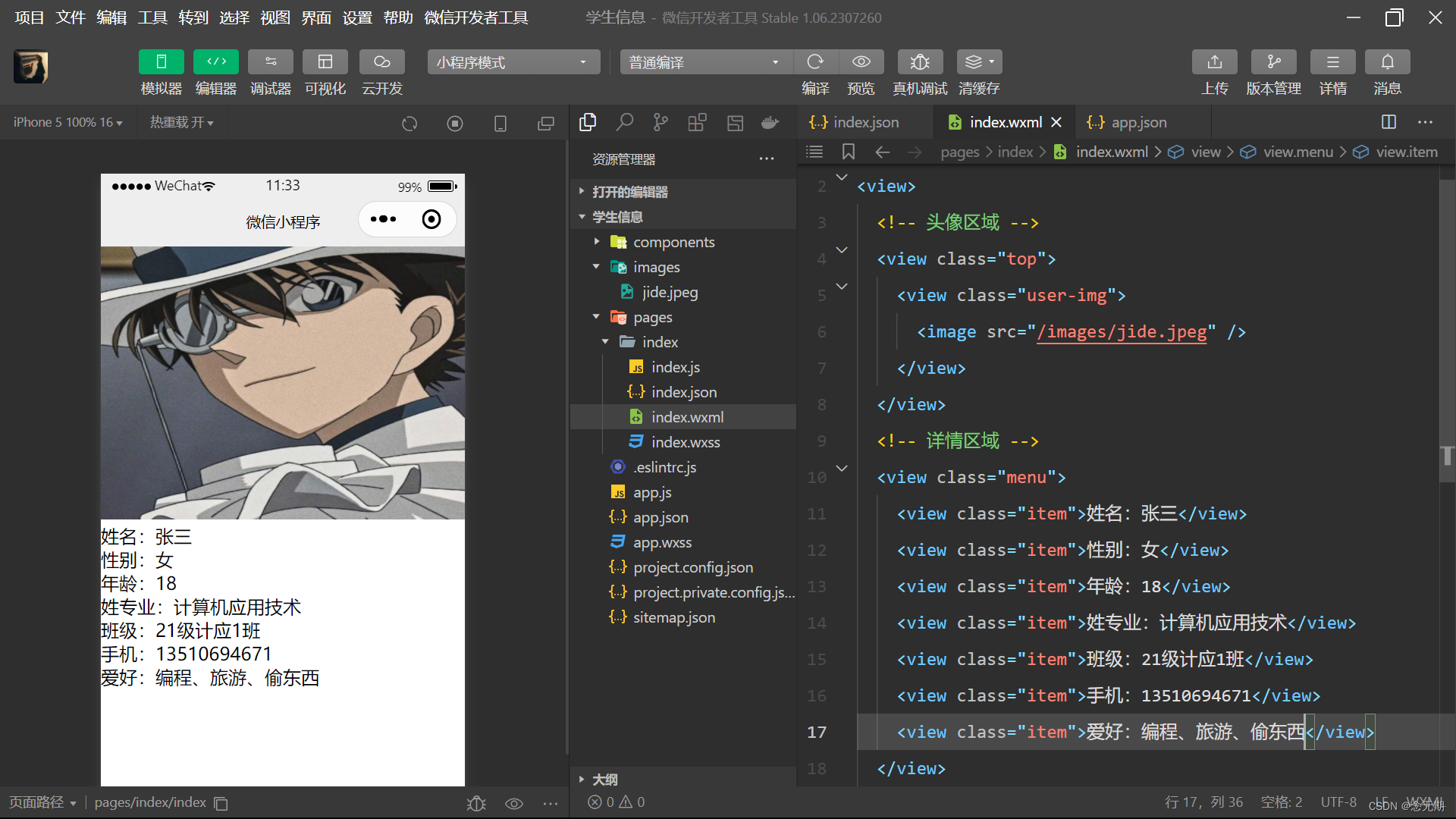
图24:蛋白质科学中任务和方法的概述。在本节中,我们重点关注三个子任务,包括蛋白质折叠、蛋白质表示学习和蛋白质主链生成。蛋白质折叠的方法可以分为两类,即AlphaFold2之前和之后[Jumper等人,2021年]:(1) 两阶段学习:RaptorX-Contact[Wang等人,2017a],AlphaFold1[Senior等人,2020],trRoseTTA[Du等人,2021],(2) 端到端学习:AlphaFold2[Jumper等人,2021],RoseTTAFold[Baek等人,2021],ESMFold[Lin等人,2023a],OpenFold[Ahdritz等人,2022]。蛋白质表示学习的方法分为不变网络,包括IEConv[Hermosilla等人,2021],HoloProt[Somnath等人,2021],MaSIF[Gainza等人,2020, 2023],dMaSIF[Sverrisson等人,2021],ProteinMPNN[Dauparas等人,2022],GearNet[Zhang等人,2023d],ProNet[Wang等人,2023b],PiFold[Gao等人,2023]和CDConv[Fan等人,2023],以及等变网络,包括GVP-GNN[Jing等人,2021]和GBPNet[Aykent和Xia,2022]。对于蛋白质主链生成,方法根据它们使用的结构表示进行分组。具体来说,ProtDiff[Wu等人,2022d],Chroma[Ingraham等人,2022],LatentDiff[Fu等人,2023b]和Genie[Lin和AlQuraishi,2023]使用3D欧几里德坐标作为蛋白质主链结构的结构表示,而RFdiffusion[Watson等人,2022]和FrameDiff[Yim等人,2023]使用帧表示。此外,FoldingDiff[Wu等人,2022d]使用内部角度表示蛋白质主链结构。
蛋白质折叠:蛋白质的三维几何结构在确定其功能方面起着至关重要的作用。蛋白质分子内原子的特定排列和空间组织对其与其他分子(如底物、辅因子、配体和其他蛋白质)的相互作用至关重要。传统的X射线晶体学被认为是一种昂贵且资源密集的确定蛋白质结构的方法[Ilari and Savino 2008]。机器学习方法被提出,可以根据氨基酸序列自动预测蛋白质的结构。蛋白质折叠,也称为蛋白质结构预测,旨在基于氨基酸序列 𝒛 预测蛋白质的三维结构(包括主链和侧链的所有原子的坐标,在方程(100)中表示为 C)。
蛋白质表示学习:蛋白质表示学习旨在学习蛋白质结构的信息表示。学到的表示可以用于广泛的预测任务,包括酶反应分类[Webb等人,1992; Hermosilla等人,2021; Hermosilla和Ropinski,2022; Zhang等人,2023d; Fan等人,2023]、蛋白质逆折叠[Ingraham等人,2019; Jing等人,2021; Hsu等人,2022; Dauparas等人,2022; Gao等人,2023]和蛋白质-配体结合亲和力预测[Wang等人,2004; Liu等人,2015; Öztürk等人,2018; Karimi等人,2019; Somnath等人,2021; Wang等人,2023b],如图26所示。蛋白质表示学习可以显著加速蛋白质筛选和新蛋白质发现的过程。
蛋白质主链结构生成:如上所述,蛋白质主链由一系列氨基酸主链组成,每个主链包含氮(𝑁)、α-碳(𝐶𝛼)和碳(𝐶)原子。这些主链原子决定了蛋白质的二级结构和整体形状,显著影响蛋白质的功能。因此,在新蛋白质设计中,生成蛋白质主链具有极大的重要性。具体而言,蛋白质主链生成任务是学习一个生成模型 𝑝𝜃,该模型可以建模真实蛋白质主链的密度分布 𝑝Pbb,然后我们可以从学习的生成模型中采样出满足𝑝𝜃(Pˆbb)≈𝑝Pbb(Pˆbb)的新蛋白质主链。在实践中,大多数研究将这个问题表述为一个条件生成任务,首先从学习的生成模型中采样出原子位置,然后使用经过训练的逆折叠模型从生成的结构中预测氨基酸类型。
蛋白质主链结构生成任务的目标是创建一个模型分布,可以轻松生成样本以模拟真实数据分布。然而,要实现这一目标,必须解决一些挑战,包括在数据分布和先验分布(如高斯分布)之间建立双射映射、确保分布 𝐸(3)/𝑆𝐸(3)-不变性、使用 𝐸(3)/𝑆𝐸(3)-等变消息传递,以及高效建模蛋白质结构。
在本次调查中,对于蛋白质表示学习和蛋白质主链生成任务,我们主要关注基于结构而不是基于序列的预测和生成方法,原因如下。首先,蛋白质表示学习是一项复杂的任务,需要考虑蛋白质结构和序列两者。蛋白质功能的重要部分受结构影响,不能仅从序列中直接推断出来。而且,结构的变化可以导致相同蛋白质序列的不同性质。其次,在蛋白质生成中,一个关键目标是生成新的蛋白质结构,满足特定的结构约束,如包含特定的亚结构、具有特定的二级结构以及与特定分子和抗原结合。这些几何约束可以作为条件纳入蛋白质结构生成方法中,但不能从蛋白质序列生成的角度直接处理。特别是,使用深度学习方法进行蛋白质生成在很大程度上未被充分探讨,关于这一主题没有太多的研究成果。最近的研究趋势表明扩散模型具有很大的潜力,并取得了最佳性能。因此,在深度学习方法方面,我们在本次调查中专注于扩散模型。
6.2 蛋白质折叠
作者:Tianfan Fu,Alexandra Saxton,Shuiwang Ji,Jimeng Sun
与第5节讨论的由少数几个原子组成的小分子不同,蛋白质是由大量原子组成的大分子(通常为1,000到10,000个),因此在估算其天然结构时面临更大的挑战。在本节中,我们首先明确了蛋白质折叠问题,然后确定了主要挑战,并讨论了现有的方法和数据集。最后,我们指出了未来工作的一些潜在方向。
6.2.1 问题设置
蛋白质折叠,也称为蛋白质结构预测,旨在基于氨基酸序列 𝒛 预测蛋白质的三维结构(包括主链和侧链的所有原子的坐标,在方程(100)中表示为 C)。
6.2.2 技术挑战
具有 𝐸(3)/𝑆𝐸(3)-等变性的生成器:神经网络的设计旨在在应用于经历 𝑆𝐸(3) 变换的蛋白质结构时保持一致性。
物理约束:蛋白质折叠受到基本的物理原则的控制,这些原则决定了蛋白质结构中原子的空间排列。其中之一原则是键长的概念,它指的是参与化学键的原子之间的平均距离。在蛋白质分子中,键合原子之间的距离相对固定,这意味着它们具有特征和明确定义的值。这些固定的键长是由涉及的原子类型和它们之间形成的具体化学键所确定的。另一个原则是任意成对原子之间的距离不能太短,以避免碰撞。因此,必须将这些物理约束纳入端到端模型中。
计算效率:由于蛋白质主链和侧链的灵活性,蛋白质可以采用大量可能的结构。探索这个广阔的结构空间以确定能量最有利的折叠状态在计算上是具有挑战性的。
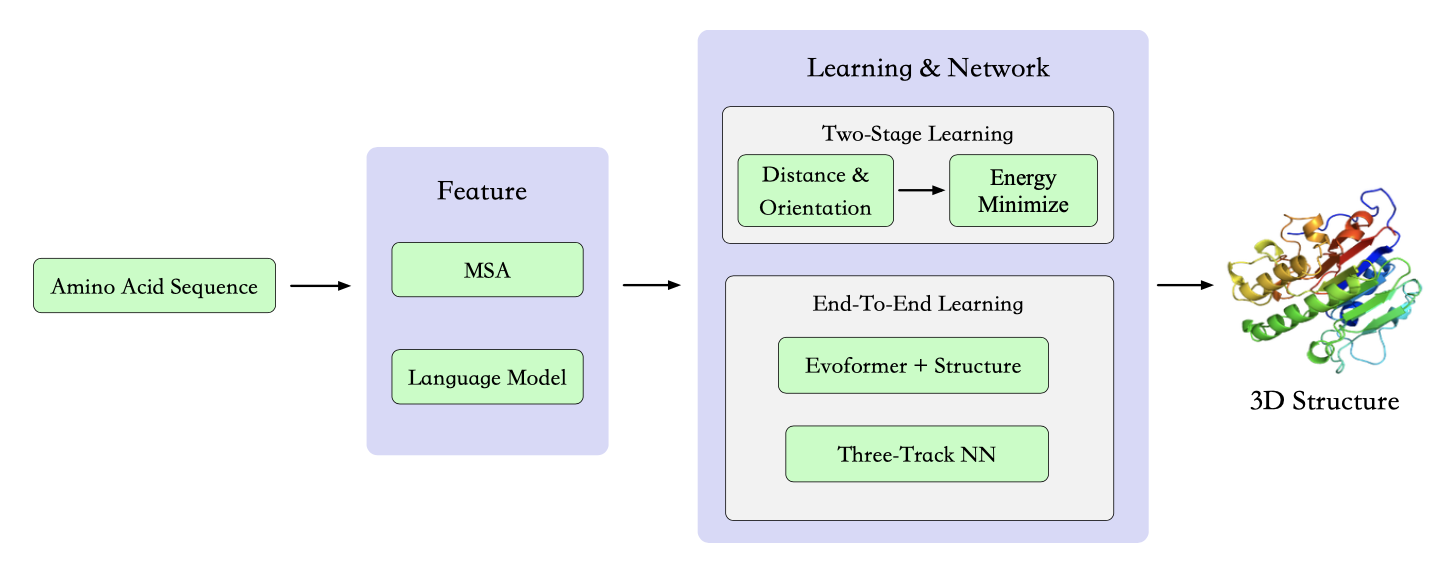
图25:蛋白质折叠算法总结。现有方法,包括RaptorX-Contact[Wang等人,2017a],AlphaFold1[Senior等人,2020],trRoseTTA[Du等人,2021],AlphaFold2[Jumper等人,2021],RoseTTAFold[Baek等人,2021],AlphaFold-Multimer[Evans等人,2021],ESMFold[Lin等人,2023a]和OpenFold[Ahdritz等人,2022],遵循此流程,它们各自的模块总结在表20中。
6.2.3 现有方法
蛋白质折叠的现有工作可以分为两类,即两阶段预测和端到端预测。表20和图25总结了现有方法之间的主要区别。在几何深度学习的发展之前,为了规避直接生成三维坐标的复杂性,大多数早期方法采用了两阶段学习过程:第一阶段是预测成对距离和取向(例如,扭曲角度),而第二阶段是设计可微分的势函数作为优化替代品。成对距离和取向在𝑆𝐸(3)变换下是不变的。杰出的方法包括RaptorX-Contact[Wang等人,2017a],AlphaFold1[Senior等人,2020],trRosetta[Du等人,2021]等,基本上都不是端到端方法。然后,几何深度学习的出现,特别是𝐸(3)/𝑆𝐸(3)神经网络,使得能够建立一个端到端的蛋白质结构预测系统成为可能。具体而言,在2020年,AlphaFold2[Jumper等人,2021]在蛋白质结构预测领域的第14届CASP(蛋白质结构预测关键评估)竞赛中展示出了惊人的准确性(CASP是蛋白质结构预测领域的每两年举行的社区广泛竞赛)。它将Evoformer(transformer的一种变体)与𝑆𝐸(3)-等变结构模块相连接。结构模块旨在将表示转换为三维结构。它首先按顺序生成主链的坐标:对于每个残基,它不是生成全局坐标,而是生成相对于前一个残基的相对位置,由旋转矩阵(三个可学习参数)和过渡矢量(三个可学习参数)参数化。随后出现了一些类似的工作,包括RoseTTAFold[Baek等人,2021],AlphaFold-Multimer[Evans等人,2021],ESMFold[Lin等人,2023a],UniFold[Li等人,2022c],OpenFold[Ahdritz等人,2022]等。
具体来说,受到AlphaFold2的启发,RoseTTAFold [Lin等人,2023a]引入了一种创新的三轨神经网络,使其能够联合建模1D蛋白质序列、2D距离图和3D坐标信息。通过采用这种方法,他们在预测蛋白质折叠结构方面取得了令人印象深刻的精度,与AlphaFold2的性能相媲美。然而,蛋白质结构预测的原始实现非常耗时且资源密集。其中一个主要的计算瓶颈在于多序列比对(MSA)。几乎所有的蛋白质折叠方法(包括AlphaFold2之前和之后的方法)都使用MSA,并在最终性能中起着关键作用。进行MSA的主要动机是识别和理解生物分子的功能和结构约束。通过比对来自不同物种或同一生物体内的序列,研究人员可以识别对于维持分子功能至关重要的保守区域。MSA会在大规模蛋白质结构数据库中穷举搜索,以识别相似的氨基酸序列,以揭示生物进化关系的见解并增强输入特征。然而,由于其蛮力本质,MSA过程通常耗时且资源需求高。为了缓解这个问题,ESMFold [Lin等人,2023a]在氨基酸序列上预训练了一个大型语言模型,并使用它来替代MSA,引入了强大的神经表示,据显示能够显著加速整个过程。ESMFold的其他神经架构遵循了AlphaFold2的方法。OpenFold [Ahdritz等人,2022]开发了AlphaFold2的内存高效版本,并维护了OpenProteinSet,这是最大的公共MSA数据库之一(包含五百万个蛋白质结构)。此外,OpenFold发布了代码,以造福整个社区。AlphaFold-Multimer [Evans等人,2021]通过在训练数据中加入更多的多链蛋白质,增强了AlphaFold在多链蛋白质复合物结构背景下的预测性能。
表20:现有的蛋白质折叠方法总结,包括RaptorX-Contact[Wang等人,2017a],AlphaFold1[Senior等人,2020],trRosetta[Du等人,2021],AlphaFold2[Jumper等人,2021],RoseTTAFold[Baek等人,2021],AlphaFold-Multimer[Evans等人,2021],UniFold[Li等人,2022c],ESMFold[Lin等人,2023a]和OpenFold[Ahdritz等人,2022]。两阶段学习通常包括(1)成对距离和取向的预测和(2)能量最小化。

6.2.4 数据集与基准
蛋白质数据银行(PDB)[Berman等人,2000]是最知名的公共蛋白质结构数据库,其中的蛋白质结构是通过X射线晶体学确定的[Ilari和Savino,2008]。PDB收集、验证和传播实验确定的原子坐标以及相关信息,如实验方法、分辨率和文献参考资料。PDB收录了超过180,000个蛋白质结构,而且PDB中的结构数量不断增长,因为研究人员不断确定和提交新的结构。对于AlphaFold2,数据集来自两个来源。具体而言,75%的训练样本来自Uniclust30的自蒸馏数据集[Mirdita等人,2017];25%来自蛋白质数据银行(PDB)[Berman等人,2000]。它去除了一些重复的样本,最终的数据集包含大约475,000个蛋白质结构。
蛋白质结构预测的关键评估(CASP)是一个每两年举行的竞赛,旨在评估蛋白质结构预测领域的最新方法。CASP为研究人员和计算方法提供了一个平台,以评估他们准确预测蛋白质的三维结构的能力。在CASP期间,参与者会获得一组蛋白质序列,这些序列的实验结构已经确定,但保密。参与者使用他们的计算方法来预测相应的蛋白质结构,而不具备实验结构的任何先验知识。然后对这些预测进行评估,并与实验结构进行比较,以评估预测的准确性和质量。AlphaFold1在2018年举办的CASP13中占据主导地位。两年后,2020年举办的CASP14中,AlphaFold2实现了接近90的全局距离测试(GDT)分数,几乎等同于X射线晶体学的准确性。它成为第一个具有接近实验准确性的蛋白质结构预测方法,并被称为蛋白质折叠的黄金标准。许多后续研究着重于复制AlphaFold2并匹配其性能,包括RoseTTAFold[Baek等人,2021],OpenFold[Ahdritz等人,2022],ESMFold[Lin等人,2023a]等。例如,ESMFold通过使用大型语言模型替代MSA,实现了高达60倍的加速,同时保持准确性[Lin等人,2023a]。
6.2.5 开放研究方向
目前仍存在一些挑战未解决,限制了蛋白质折叠的实际应用。首先,大多数现有方法可以准确预测单链蛋白的结构,但对于多链蛋白来说性能会显著下降。主要原因是多链蛋白比单链蛋白更复杂,而且可用数据有限。其次,大多数现有方法严重依赖MSA,并在处理与训练集和MSA数据库不同的蛋白质时性能显著下降。因此,提高对不同蛋白质的泛化能力是一个关键问题。第三,在现实世界中,蛋白质不是孤立存在的,而是经常与其他蛋白质、RNA和DNA相互作用。因此,在不同背景下预测蛋白质的结构(例如RNA-蛋白质复合物、DNA-蛋白质复合物)也是一个重要挑战,其中可用数据也有限。因此,未来的研究旨在在这些复杂情境下预测蛋白质的结构。
6.3 蛋白质表示学习
作者:Limei Wang,Yi Liu,Cong Fu,Michael Bronstein,Shuiwang Ji
推荐先修内容:第2.3节,第2.4节,第5.2节
与第5节讨论的小分子不同,蛋白质是由大量原子组成的大分子,使蛋白质表示学习变得更具挑战性。在本节中,我们强调与蛋白质表示学习相关的挑战。我们还总结了专门用于蛋白质结构学习的现有方法。
6.3.1 问题设置
蛋白质表示学习的目标是学习一个合适的表示,可以编码给定蛋白质序列和结构的重要信息。良好学习的蛋白质表示可以用于促进许多下游任务,例如我们在本调查中关注的蛋白质性质预测任务。具体来说,蛋白质性质预测任务可以分为两类,即蛋白质级任务和节点级任务。对于蛋白质级任务,例如酶反应分类,我们旨在学习一个函数 𝑓 来预测给定任何蛋白质 P 的属性 𝑦,而 𝑦 可以是实数(回归问题)或分类数(分类问题)。对于节点级任务,例如反向蛋白质折叠,我们旨在学习一个函数 𝑓 来预测第 𝑖 个氨基酸的属性 𝑦𝑖。

图26:蛋白质结构、表示学习方法和下游任务的示意图。蛋白质由一个或多个氨基酸链组成。当两个或更多氨基酸结合形成肽时,水分子被去除,每个氨基酸的剩余部分称为氨基酸残基。图的左侧显示了残基的详细结构。在中间,我们列出了现有的蛋白质表示学习方法,包括GVP-GNN[Jing等人,2021],IEConv[Hermosilla等人,2021],HoloProt[Somnath等人,2021],MaSIF[Gainza等人,2020,2023],dMaSIF[Sverrisson等人,2021],ProteinMPNN[Dauparas等人,2022],GearNet[Zhang等人,2023d],ProNet[Wang等人,2023b],CDConv[Fan等人,2023]和PiFold[Gao等人,2023]。右侧显示了不同的下游任务,包括节点级任务,如蛋白质反向折叠[Ingraham等人,2019]和图级任务,如酶反应预测[Hermosilla等人,2021]。
6.3.2 技术挑战
复杂的蛋白质结构提出了一些需要解决的重大挑战,用于蛋白质表示学习,如下所示。
计算效率:蛋白质表示学习中的一个重大挑战在于蛋白质的大小。蛋白质可以包含数百甚至数千个氨基酸,使其比小分子要大得多。因此,计算效率是一个关键瓶颈。有效的方法应该通过高效处理大型蛋白质的大小,而不会影响预测准确性来应对这一挑战。
多级结构:蛋白质是由氨基酸构成的复杂分子,每个氨基酸包含多个原子,如图26所示。因此,方法应该捕捉氨基酸级别的信息,可能进一步捕捉原子级别的细节,以生成更准确的预测。这需要对蛋白质进行多级表示,这对于机器学习模型的设计来说是具有挑战性的。
保持对称性:方法应该遵循所需的对称性。具体来说,模型的输出应该是 𝑆𝐸(3) 不变的,这意味着预测结果不应随着蛋白质结构的旋转和平移变换而改变。这是因为蛋白质的功能和性质不取决于其在三维空间中的方向或位置,而是取决于其化学成分和原子的空间排列。
表达能力:准确区分不同的蛋白质结构是蛋白质表示学习中的另一个重大挑战。对于不能通过 𝑆𝐸(3) 变换匹配的蛋白质结构,有效的方法应该能够区分它们。这要求方法具有很强的表达能力。
图26:蛋白质结构、表示学习方法和下游任务的示意图。蛋白质由一个或多个氨基酸链组成。当两个或更多氨基酸结合形成肽时,水分子被去除,每个氨基酸的剩余部分称为氨基酸残基。图的左侧显示了残基的详细结构。在中间,我们列出了现有的蛋白质表示学习方法,包括GVP-GNN[Jing等人,2021],IEConv[Hermosilla等人,2021],HoloProt[Somnath等人,2021],MaSIF[Gainza等人,2020,2023],dMaSIF[Sverrisson等人,2021],ProteinMPNN[Dauparas等人,2022],GearNet[Zhang等人,2023d],ProNet[Wang等人,2023b],CDConv[Fan等人,2023]和PiFold[Gao等人,2023]。右侧显示了不同的下游任务,包括节点级任务,如蛋白质反向折叠[Ingraham等人,2019]和图级任务,如酶反应预测[Hermosilla等人,2021]。

6.3.3 现有方法
在第5.2节,我们讨论了关于具有3D结构的小分子表示学习的最新研究,其中提出了不变性和等变性方法来学习准确的表示。然而,蛋白质是具有大量原子和固有多级结构的大分子,如前一节所详细描述的,这带来了重大挑战。因此,不实际将为小分子设计的方法直接应用于蛋白质。在本节中,我们总结了专门设计用于处理蛋白质结构的现有方法,重点关注处理大量原子和捕捉固有多级结构的策略,以及如何构建更强大和具有对称性意识的表示学习方法,如表21所总结的,以解决上述挑战。
现有方法使用不同的策略来处理蛋白质中的大量原子。例如,IEConv [Hermosilla等人,2021]将蛋白质图中的每个原子视为一个节点,并采用多个分层池化层来减少节点数量。此外,池化操作实现了多尺度蛋白质分析,并帮助模型学习不同级别的蛋白质表示。相比之下,方法包括GearNet [Zhang等人,2023d],ProNet [Wang等人2023b],GVP-GNN [Jing等人,2021],ProteinMPNN [Dauparas等人,2022],PiFold [Gao等人,2023]和CDConv [Fan等人,2023]将蛋白质图中的每个氨基酸视为图中的一个节点,并考虑每个氨基酸中的原子信息作为特殊节点和边特征。由于每个氨基酸包含许多原子,这些方法中的图的大小明显小于IEConv [Hermosilla等人,2021]的大小,因此更有效率。
表22. Ingraham等人[2019]整理的CATH 4.2的一些统计信息,Fold数据集[Hou等人,2018; Hermosilla等人,2021],酶反应数据集[Hermosilla等人,2021],酶学委员会(EC)数据集[Gligorijević等人,2021]和基因本体数据集[Gligorijević等人,2021]。我们总结了预测任务、蛋白质样本数量(样本数量)、一个蛋白质中的最大氨基酸数(最大氨基酸数)和一个蛋白质中的平均氨基酸数(平均氨基酸数)。

此外,现有方法捕获蛋白质结构的不同层次。例如,GearNet [Zhang et al. 2023d]仅考虑每个氨基酸中的C𝛼原子,该结构编码器通过利用多视图对比学习和不同的自我预测任务进行训练。GVP-GNN [Jing et al. 2021]以𝒄𝑁 − 𝒄𝐶𝛼,𝒄𝐶 − 𝒄𝐶𝛼,𝒄𝐶𝛼 − 𝒄𝐶𝛼的方向向量作为输入,形成对蛋白质主链结构的完整描述。IEConv [Hermosilla et al. 2021]将每个原子视为一个节点,并考虑了原子之间的欧几里德距离以及具有共价或氢键的最短路径。因此,它可以捕获蛋白质的全原子结构。类似地,ProNet [Wang et al. 2023b]也可以捕获全原子结构。不同之处在于,ProNet将每个氨基酸而不是每个原子视为一个节点。它使用两个主链三角形之间的欧拉角作为边缘特征,并使用侧链中的二面角作为附加的节点特征。这种策略有效地捕获了主链和侧链结构,实现了对蛋白质全原子结构的富有表现力和高效的描述。除了原子坐标,蛋白质表面在理解分子相互作用和蛋白质功能方面起着关键作用。HoloProt [Somnath et al. 2021]不仅考虑C𝛼原子,还包含表面结构以捕获蛋白质的粗略细节。类似地,MaSIF [Gainza et al. 2020, 2023]和dMaSIF [Sverrisson et al. 2021]在各自的方法中特别认识到蛋白质表面的重要性,强调了其在分析和理解蛋白质相互作用中的重要作用。
为构建功能强大且具有对称性的表示学习方法,现有方法学习了每个节点的不同阶表示。如表21所示,大多数现有方法仅考虑标量特征,特征阶数为0。对于GVP-GNN [Jing et al. 2021]和GBPNet [Aykent and Xia 2022],特征阶数为1,因为它将方向向量视为节点和边缘特征。这些方向特征用于更新每个节点的学习特征。然而,目前尚未为蛋白质表示学习设计高阶(和多体)方法,主要是由于蛋白质结构的大规模。探索在蛋白质表示学习中使用在第2节和第5.2节中讨论的高阶(和多体)方法的潜力将是很有趣的。
蛋白质的三维结构表示学习方法在各种任务上进行评估,如氨基酸类型预测和蛋白质功能预测。表22总结了常用的数据集,包括由Ingraham等人整理的CATH 4.2数据集 [2019年],Fold数据集 [Hou等人2018;Hermosilla等人2021],酶反应数据集 [Hermosilla等人2021],酶学委员会(EC)数据集 [Gligorijević等人2021]和基因本体数据集 [Gligorijević等人2021]。
由Ingraham等人整理的CATH 4.2数据集 [2019年] 用于反向折叠任务,也称为计算蛋白质设计(CPD)或固定主链设计,旨在推断可以折叠成给定结构的氨基酸序列。该数据集是基于蛋白质结构的CATH分层分类[Orengo等人1997]收集的,并分为18,024个用于训练,608个用于验证和1,120个用于测试的结构。评估指标包括困惑度和恢复率。困惑度衡量了模型给予留置序列高似然性的能力,而恢复率评估了预测序列与模板的本机序列之间的关系。除了CATH 4.2,还使用了其他一些数据集来测试模型在反向折叠任务上的性能,包括CATH 4.3 [Hsu等人2022],TS 50 [Li等人2014;Jing等人2021]和TS 500 [Qi和Zhang 2020;Gao等人2023]。
Fold数据集 [Hou等人2018;Hermosilla等人2021] 是从SCOPe 1.75数据库 [Murzin等人1995] 中整理的包含16,712个带有3D结构的蛋白质的集合,每个蛋白质都带有1,195个褶叠类别中的一个标签。褶叠类别表示蛋白质的二级结构组成、方向和连接顺序。为了评估模型的泛化能力,使用了三个测试集,即Fold、Superfamily和Family。具体而言,Fold测试集由在训练期间未见过的超级家族的蛋白质组成,Superfamily测试集由在训练期间未见过的家族的蛋白质组成,而Family测试集由在训练期间存在的家族的蛋白质组成。在这三个测试集中,Fold是最具挑战性的,因为它与训练数据集最不相似。该数据集分为12,312个蛋白质用于训练,736个用于验证,718个用于Fold,1,254个用于Superfamily,1,272个用于Family。精确度是褶叠分类任务的评估指标。
酶反应数据集 [Hermosilla等人2021] 包含酶,这些酶是充当生物催化剂的蛋白质,并可以根据它们催化的反应进行酶学委员会(EC)编号的分类 [Webb等人1992]。总共,该数据集包含来自384个类别的37,428个具有3D结构的蛋白质,EC注释从SIFTS数据库 [Dana等人2019] 下载。该数据集分为29,215个蛋白质用于训练,2,562个用于验证和5,651个用于测试,每个EC编号在所有三个分组中都有表示。在此任务中,准确度被用作评估指标。
酶学委员会(EC)数据集[Gligorijević等人2021] 也是酶的一个集合。然而,与形成蛋白质级分类任务的酶反应数据集不同,该数据集基于三级和四级的538个EC编号 [Webb等人1992] 形成了538个二元分类任务。此外,该数据集中收集的酶与酶反应数据集中的不同。总共,该数据集包含19,198个蛋白质,其中15,550个用于训练,1,729个用于验证和1,919个用于测试。这个多标签分类任务使用两个指标进行评估,即以蛋白质为中心的最大F分数(Fmax)和以对为中心的精度-召回曲线下面积(AUPRpair)。有关这些指标的更详细信息,请参阅相关论文[Gligorijević等人2021;Wang等人2022a;Zhang等人2023d;Fan等人2023]。
基因本体数据集 [Gligorijević等人2021] 用于基于基因本体(GO)术语 [Ashburner等人2000] 预测蛋白质功能,并形成多个二元分类任务。具体而言,GO将蛋白质分类为在三个不同本体中组织的具有层次关系的功能类别,分别是生物过程(BP)(有1,943个类别),分子功能(MF)(有489个类别)和细胞组分(CC)(有320个类别)。该数据集分为29,898个蛋白质用于训练,3,322个用于验证和3,415个用于测试。评估指标与酶学委员会(EC)数据集[Gligorijević等人2021] 中使用的指标相同。
除了上述提到的数据集外,Atom3D [Townshend等人2020] 也常用于测试蛋白质表示学习方法的性能。具体而言,Atom3D是一个关于生物分子(包括蛋白质、小分子和核酸)的3D结构的数据集的统一集合。它包括用于与蛋白质相关任务的几个数据集,例如蛋白质界面预测(PIP),残基身份(RES),突变稳定性预测(MSP),配体结合亲和力(LBA),配体效力预测(LEP),蛋白质结构排名(PSR)。有关LBA任务的详细信息,请参阅第8节。
6.3.5 开放性研究方向
尽管蛋白质表示学习近年来取得了显著进展,但仍然存在一些未解决的挑战,某些方向仍然未被充分探索。例如,虽然当前的方法可以有效地捕捉蛋白质的全原子结构,但目前还不确定这些方法是否能准确地捕捉到次要结构中的重要局部亚结构,如𝛼-螺旋和𝛽-折叠,以及它们在三级结构中的空间排列。此外,将可访问表面积和蛋白质结构域纳入蛋白质表示学习方法对于更全面地理解蛋白质的结构和功能非常重要,有可能提高性能。例如,MaSIF [Gainza等人,2020,2023]专注于以网格表示的溶剂排除蛋白质表面。另一方面,dMaSIF [Sverrisson等人,2021]使用定向点云来建模蛋白质表面。与此同时,虽然已经提出了l = 0和l = 1等变方法用于蛋白质表示学习,但目前缺乏高阶方法,这些方法已经广泛用于小分子的研究。
此外,蛋白质动力学是一个重要且不断发展的领域,专注于研究蛋白质随时间的运动、构象变化和相互作用,这对于理解蛋白质的功能和行为至关重要。探索蛋白质动力学的一个方向是利用时间图神经网络(GNN)与我们介绍的蛋白质表示学习方法相结合。通过整合时间信息并考虑蛋白质结构和相互作用的动态特性,时间GNN为揭示蛋白质动力学的复杂性提供了一个有前景的途径。另一个重要方面是蛋白质电路设计,这对于推进我们对蛋白质功能和行为的理解具有巨大潜力。
6.4 蛋白质主链结构生成
作者:Keqiang Yan、Cong Fu、Yi Liu、Shuiwang Ji 推荐先修内容:第5.3节、第5.4节
如上所述,本文重点关注蛋白质主链结构生成的扩散模型。在这里,我们首先详细描述了蛋白质主链结构生成面临的挑战,然后从蛋白质结构表示和扩散过程的两个角度讨论先前的方法如何应对这些挑战。使用扩散模型生成蛋白质的流程如图27所示。
6.4.1 问题设置
蛋白质主链生成任务是学习一个生成模型𝑝𝜃,该模型可以建模真实蛋白质主链的密度分布𝑝Pbb,然后我们可以采样一个满足𝑝𝜃(Pˆbb)≈𝑝Pbb(Pˆbb)的新型蛋白质主链Pˆbb。
6.4.2 技术挑战
复杂的数据分布:生成任务需要从数据分布中采样新的数据点。然而,真实蛋白质结构的分布是未知的、稀疏的,并且难以从中进行采样。因此,在数据分布与先验分布(如高斯分布)之间建立双射映射至关重要,以更好地模拟真实数据分布并减小机器学习方法中的偏差。
分布𝐸(3)/𝑆𝐸(3)不变性:分布𝐸(3)/𝑆𝐸(3)不变性源自真实蛋白质结构分布的性质,需要满足。具体而言,对于从真实数据分布𝑝 Pbb 中采样的蛋白质主链结构 Pbb,如果我们应用3D旋转变换𝑅 ∈ R3×3,其中|𝑅| = ±1用于𝐸(3),𝑅 ∈ R3×3,其中|𝑅| = 1用于𝑆𝐸(3),以及平移变换𝑏 ∈ R3,则给定蛋白质的几何结构保持不变。因此,我们有𝑝Pbb (Pbb) = 𝑝Pbb (𝑅Pbb+𝑏) 对于真实数据分布𝑝Pbb 来说是成立的。因此,为了更好地模拟真实数据分布并最小化机器学习方法中的偏差,需要将分布𝐸(3)/𝑆𝐸(3)不变性编码到生成流程中。
𝐸(3)/𝑆𝐸(3)等变网络:为了实现分布𝐸(3)/𝑆𝐸(3)不变性,神经网络应满足等变性质。如上所述,两个经过群变换的相同蛋白质结构应满足𝑝Pbb (Pbb) = 𝑝Pbb (𝑅Pbb + 𝑏)。对于三维空间中的蛋白质,首先,我们可以通过减去坐标的均值值来使坐标具有零重心,从而自然满足了分布的平移不变性。因此,我们只需要考虑旋转不变性,即𝑝Pbb (Pbb) = 𝑝Pbb (𝑅Pbb)应该成立。通过总概率规则,我们有𝑝(Pbb) = ∫ 𝑝(Pbb|𝒁)𝑝(𝒁)𝑑𝒁,其中𝒁表示潜变量。类似地,我们还有𝑝(𝑅Pbb) = ∫ 𝑝(𝑅Pbb|𝑅𝒁)𝑝(𝑅𝒁)𝑑𝑅𝒁。
如果我们从零中心的高斯分布中采样潜变量𝒁,那么𝑝(𝑅𝒁) = 𝑝(𝒁)可以很容易地满足。为了实现𝑝(𝑅Pbb|𝑅𝒁) = 𝑝(Pbb|𝒁),我们应该使从𝒁到Pbb的网络对𝑅具有等变性。因此,𝑝(𝑅Pbb) = 𝑝(Pbb)成立,分布𝐸(3)/𝑆𝐸(3)不变性得到满足。
计算效率:高效建模蛋白质结构也至关重要。除了前面提到的挑战之外,值得注意的是,蛋白质结构的探索空间非常广阔,而已知的蛋白质结构有限。因此,需要建立优雅的蛋白质表示,不仅可以简化建模难度,还可以最小化机器学习模型中的几何偏差。
6.4.3 现有方法
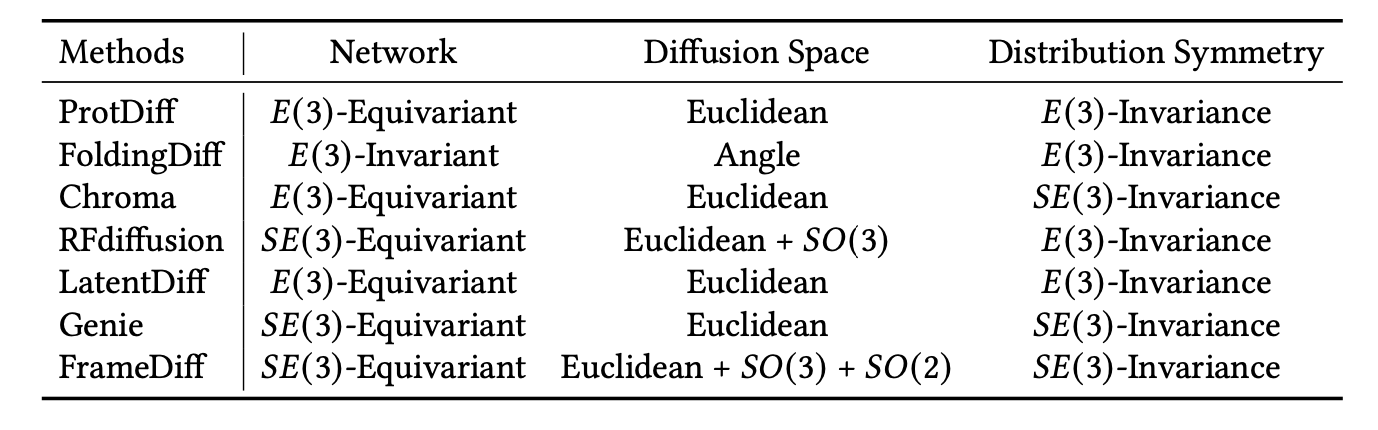
蛋白质结构表示:为了解决蛋白质结构建模的效率问题,最近的方法要么仅生成蛋白质主链结构[Wu等人,2022d;Trippe等人,2022;Fu等人,2023b;Lin和AlQuraishi,2023;Yim等人,2023],要么首先生成蛋白质主链结构,然后预测全原子级别的蛋白质结构[Ingraham等人,2022;Watson等人,2022],因为完整蛋白质结构的复杂性和广泛的探索空间。在建模蛋白质主链结构时,使用不同的3D表示,导致不同的建模成本和扩散过程。具体而言,ProtDiff[Trippe等人,2022]、Chroma[Ingraham等人,2022]、LatentDiff[Fu等人,2023b]和Genie[Lin和AlQuraishi,2023]通过α碳位置Pbb表示蛋白质主链结构,而不考虑𝑁、𝐶、𝑂原子的位置。LatentDiff进一步将蛋白质主链结构编码为紧凑的潜在空间,以降低建模复杂性。FoldingDiff[Wu等人,2022d]和RFdiffusion[Watson等人,2022]都基于𝐶𝛼、𝑁、𝐶原子的位置表示蛋白质主链结构。然而,FoldingDiff[Wu等人,2022d]使用氨基酸链上的相对键和扭转角度,而RFdiffusion[Watson等人,2022]使用𝐶𝛼的3D位置和表示每个残基在全局参考框架中的刚体方向的3×3旋转矩阵。最近,FrameDiff[Yim等人,2023]进一步考虑了𝑂原子的位置,通过𝐶𝛼的3D位置、3×3旋转矩阵和𝑂的旋转扭转角度表示蛋白质主链结构。前述工作的表示、结构粒度级别和建模空间总结在表23中。

图27. 使用扩散模型生成蛋白质的流程。该过程从将蛋白质主链结构扩散到高斯噪声开始,然后使用学习的去噪网络对其进行去噪,以生成新的蛋白质结构。蛋白质主链可以用不同的方式表示,如坐标、坐标系或内部角度。针对每种表示方法,都提出了不同的方法。对于坐标表示,方法包括ProtDiff[Trippe等人,2022]、Chroma[Ingraham等人,2022]、LatentDiff[Fu等人,2023b](坐标位于潜在空间中)和Genie[Lin和AlQuraishi,2023]。对于坐标系表示,方法包括FrameDiff[Yim等人,2023]和RFdiffusion[Watson等人,2022]。对于内部角度表示,方法是FoldingDiff[Wu等人,2022d]。
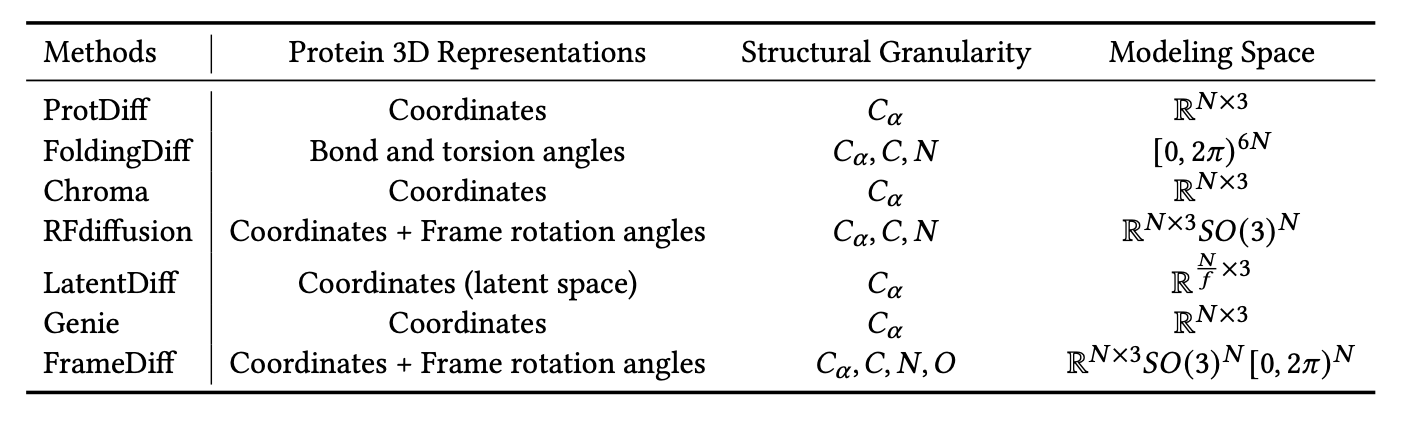
表23. 总结了先前研究中使用的蛋白质三维表示方法以及相应的蛋白质结构粒度级别和建模空间。 𝑁 表示氨基酸的数量。 𝑓 表示LatentDiff中的下采样因子。其中,ProtDiff [Wu等人,2022d]、Chroma [Ingraham等人,2022] 和 Genie [Lin和AlQuraishi,2023] 仅考虑α碳的位置,LatentDiff [Fu等人,2023b] 考虑了潜在空间中的节点位置,而FoldingDiff [Wu等人,2022d] 和 RFdiffusion [Watson等人,2022] 进一步考虑了蛋白质主链结构中碳和氮原子的位置。FrameDiff [Yim等人,2023] 考虑了蛋白质主链结构中的所有原子。
扩散模型:鉴于不同的蛋白质结构表示方法,需要建立相应的扩散过程来解决蛋白质主链生成中的挑战,包括建立数据分布和先验分布之间的双射映射以实现采样,确保分布 𝐸(3)/𝑆𝐸(3)-不变性,以及神经网络的 𝐸(3)/𝑆𝐸(3)-等变性属性。
ProtDiff [Trippe等人,2022]、LatentDiff [Fu等人,2023b] 和 Genie [Lin和AlQuraishi,2023] 使用了α碳的三维欧几里得坐标,其扩散过程相对简单。具体来说,ProtDiff、LatentDiff 和 Genie 使用零均值分布来消除在三维空间中的平移影响,从而实现分布平移不变性。此外,LatentDiff将蛋白质结构编码到潜在空间中以降低建模复杂性。此外,为了解决旋转变换的影响,ProtDiff 和 LatentDiff 使用了𝐸(3)-等变网络 EGNN 并实现了分布 𝑂 (3)-不变性,而 Genie 通过使用𝑆𝐸(3)-等变的 IPA 层实现了分布 𝑆𝑂 (3)-不变性,这对反射敏感。为了实现蛋白质结构的采样,还建立了用于三维坐标的前向和反向扩散过程,类似于图像领域中的使用方式。这种结构表示的一个限制是仅考虑了主链结构中α碳的位置,还需要额外的生成步骤来生成𝑁、𝐶 和 𝑂 原子的位置。
如上所述,扩散模型需要将原始数据转化为高斯噪声,并学习一个去噪网络,以模拟和生成来自高斯噪声的真实数据。大多数方法通过添加各向同性高斯噪声来转换欧几里得坐标,这看起来像一个不相关的扩散过程,可能会破坏一些蛋白质的常见结构约束。因此,这些模型需要额外的设计来从数据中学习这些相关性。为了避免这种情况,Chroma [Ingraham等人,2022] 引入了一个相关的扩散过程,将蛋白质转化为随机折叠聚合物,并使用设计的协方差模型来编码链和旋转半径的约束。此外,Chroma设计了一个可以以次二次方的规模捕获远程信息的随机图神经网络,并且该网络预测成对残基几何关系,然后以𝑆𝐸(3)-等变的方式优化三维蛋白质结构。
FoldingDiff [Wu等人,2022d] 使用主链结构上的键和扭转角度,假设主链沿着化学键的长度遵循实际约束。由于键和扭转角度具有 𝐸(3)-不变性,因此使用了简单的序列模型来实现分布 𝐸(3)-不变性。为了实现从高斯噪声中进行采样的过程,FoldingDiff将类似于坐标的前向和反向扩散过程应用于键角度和扭转角度,尽管键角度和扭转角度属于紧致黎曼流形而不是欧几里得空间。
RFdiffusion [Watson等人,2022] 和 FrameDiff [Yim等人,2023] 使用了由α碳的三维位置和氨基酸平面的相对旋转角度组成的框架表示。具体来说,为了实现分布 𝑆𝐸(3)-不变性,FrameDiff使用零均值分布来消除在三维空间中的平移影响,并实现了α碳的三维位置的分布平移不变性。此外,为了解决旋转变换的影响,FrameDiff通过使用𝑆𝐸(3)-等变的IPA层实现了分布 𝑆𝑂(3)-不变性,该层对反射敏感。而 RFdiffusion 将 RoseTTAFold,一种强大的蛋白质结构预测方法,修改为去噪网络,并实现了𝑆𝐸(3)-等变性质。为了实现从高斯噪声中进行采样的过程,与之前在欧几里得空间中建立的扩散过程不同,FrameDiff 提出了用于氨基酸平面旋转矩阵的坚实 𝑆𝑂 (3) 扩散前向和反向过程,这些矩阵属于紧致黎曼流形。此外,对于 RFdiffusion,应该向旋转矩阵添加噪声,因此采用了 𝑆𝑂 (3) 流形上的布朗运动。FrameDiff 和 RFdiffusion 中α碳位置的扩散过程类似于 ProtDiff 和 Chroma。此外,RFdiffusion 使用了一种自我调节机制,将去噪网络的输出用作后续去噪步骤的模板输入,类似于 AlphaFold2 中的循环机制[Jumper等人,2021]。先前工作的扩散空间和实现的分布对称性总结在表24中。
表24. 展示了不同蛋白质表示的扩散过程以及先前工作实现的分布对称性。其中,ProtDiff [Wu等人,2022d]、FoldingDiff [Wu等人,2022d] 和 LatentDiff [Fu等人,2023b] 实现了分布 𝐸(3)-不变性,并将手性蛋白质结构视为相同,而Chroma [Ingraham等人,2022]、RFdiffusion [Watson等人,2022]、Genie [Lin和AlQuraishi,2023] 和 FrameDiff [Yim等人,2023] 实现了分布 𝑆𝐸(3)-不变性,并具有更好的生成性能。
6.4.4 数据集和基准。
目前,蛋白质主链结构生成任务没有标准的基准数据集。早期的蛋白质主链生成方法通常是在来自PDB [Berman等人,2000]或其他蛋白质结构库的选定蛋白质结构上进行评估。具体来说,ProtDiff 使用了4269个单链蛋白质结构,氨基酸数量范围在[40, 128]之间,而FoldingDiff 使用了CATH [Ingraham等人,2019] 数据集,包括24316个用于训练的结构,3039个用于验证,和3040个用于测试。Chroma [Ingraham等人,2022] 查询具有2.6 Å或更好分辨率的非膜蛋白质X射线结构,并额外添加了1725个非冗余抗体结构,总共有28819个结构。在RFdiffusion [Watson等人,2022] 中,RoseTTAFold (RF) 预先在多个数据来源的混合数据上进行了预训练,包括PDB中的单体/同源物和异源物结构,AlphaFold2数据,具有pLDDT > 0.758的负蛋白质相互作用示例,然后RFdiffusion 在用于RF训练的PDB中的单体结构上进行训练。LatentDiff 从蛋白质数据银行 (PDB) [Berman等人,2000] 和AlphaFold蛋白质结构数据库 (AlphaFold DB) [Jumper等人,2021;Varadi等人,2022] 中筛选出约100,000个训练数据。Genie 使用了8766个蛋白质域,其中3942个域的残基数最多为128个,来自结构蛋白质分类 (SCOPe) 数据集,而FrameDiff 使用了20312个来自PDB [Berman等人,2000] 的蛋白质主链进行训练。在评估模型性能时,广泛使用的指标包括scTM分数(分数越高越好)以及生成的蛋白质主链结构与训练结构的新颖性。
6.4.5 开放研究方向。
最近的蛋白质生成模型主要关注蛋白质结构的主链水平,但无法一步生成全原子水平的蛋白质结构。此外,最近的方法主要设计用于随机蛋白质结构生成或在给定蛋白质亚结构的条件下生成。另一个潜在的方向是生成满足期望属性的蛋白质结构。