我们知道Java中的IO模型分为BIO和NIO模型,BIO是BlCKING IO的简称而NIO当中的N有两层意思,一个是从java1.4开始出现的NEW IO,今天我们来聊一聊为什么传统的BIO会慢以及它并不适合大量的连接,我们先来看一段简单的代码,这段代码就是一个简单的BIO服务端:
public class BioServer {
public static void main(String[] args) throws Exception {
ServerSocket serverSocket = new ServerSocket();
serverSocket.bind(new InetSocketAddress(9090));
while (true) {
TimeUnit.SECONDS.sleep(1);
Socket accept = serverSocket.accept();
new Thread(() -> {
try {
InputStream inputStream = accept.getInputStream();
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
}这段代码逻辑我就不解释了,我们着重关注bind方法和accept方法,我们把这个代码打包丢到linux系统去执行,看看这一段代码都涉及到哪些系统调用,这里会涉及到一些linux的知识,主要是strace命令的使用,它可以追踪应用程序与操作系统之间的交互,也就是调用了哪些系统函数,也可以叫做系统调用,比如 strace ls命令的效果(后面还有好大一串,没有全部截图出来):
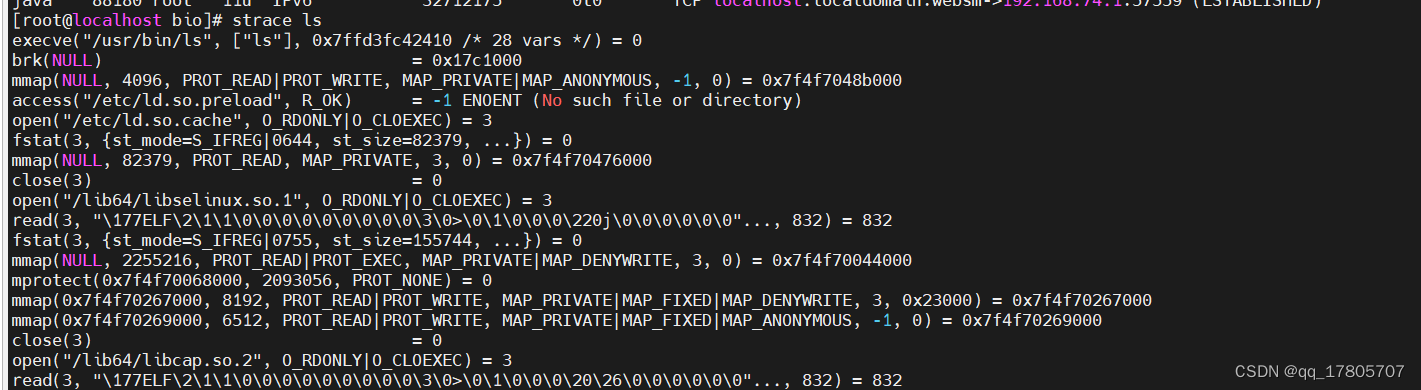
strace命令只会跟踪主线程的活动信息,所以一般我们会加上-ff也就是strace -ff ls ,这样不仅仅会跟踪主线程的活动,也会跟踪子线程的活动,我们此次要追踪的java bioserverde 的命令如下:
strace -ff -o out java -cp chat-1.0-SNAPSHOT.jar com.tianjun.chat.bio.BioServer
这个命令的意思就是把这个JVM进程下面的所有的子线程的活动全部输出到一out开头的文件中,执行之后的效果如下图:
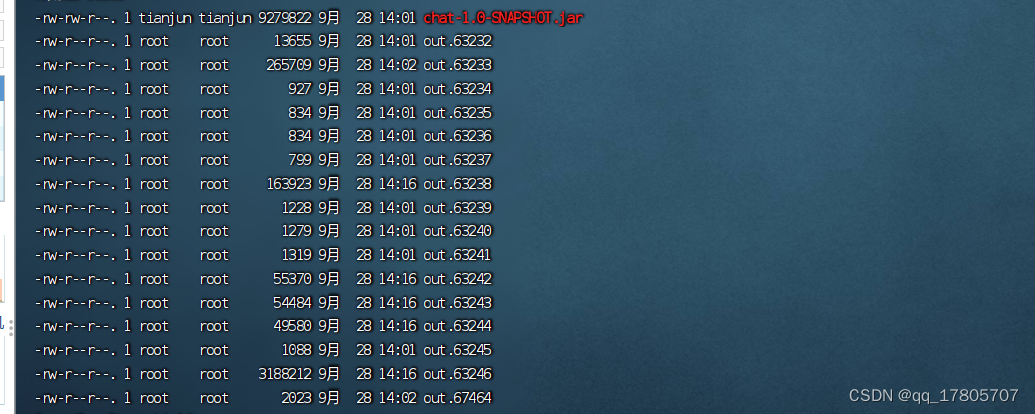
那么输出的信息,一般的第一个是进程id,第二个是主线程id也就是说图中的63232是jvm进程id,63233是main线程的线程id:
 我们知道任何一个应用程序在linux中都会表示程一个文件,并且都会有一对应的文件描述符,我们可以用lsof -p pid来查看应用程序打开了哪些文件(描述符)
我们知道任何一个应用程序在linux中都会表示程一个文件,并且都会有一对应的文件描述符,我们可以用lsof -p pid来查看应用程序打开了哪些文件(描述符)
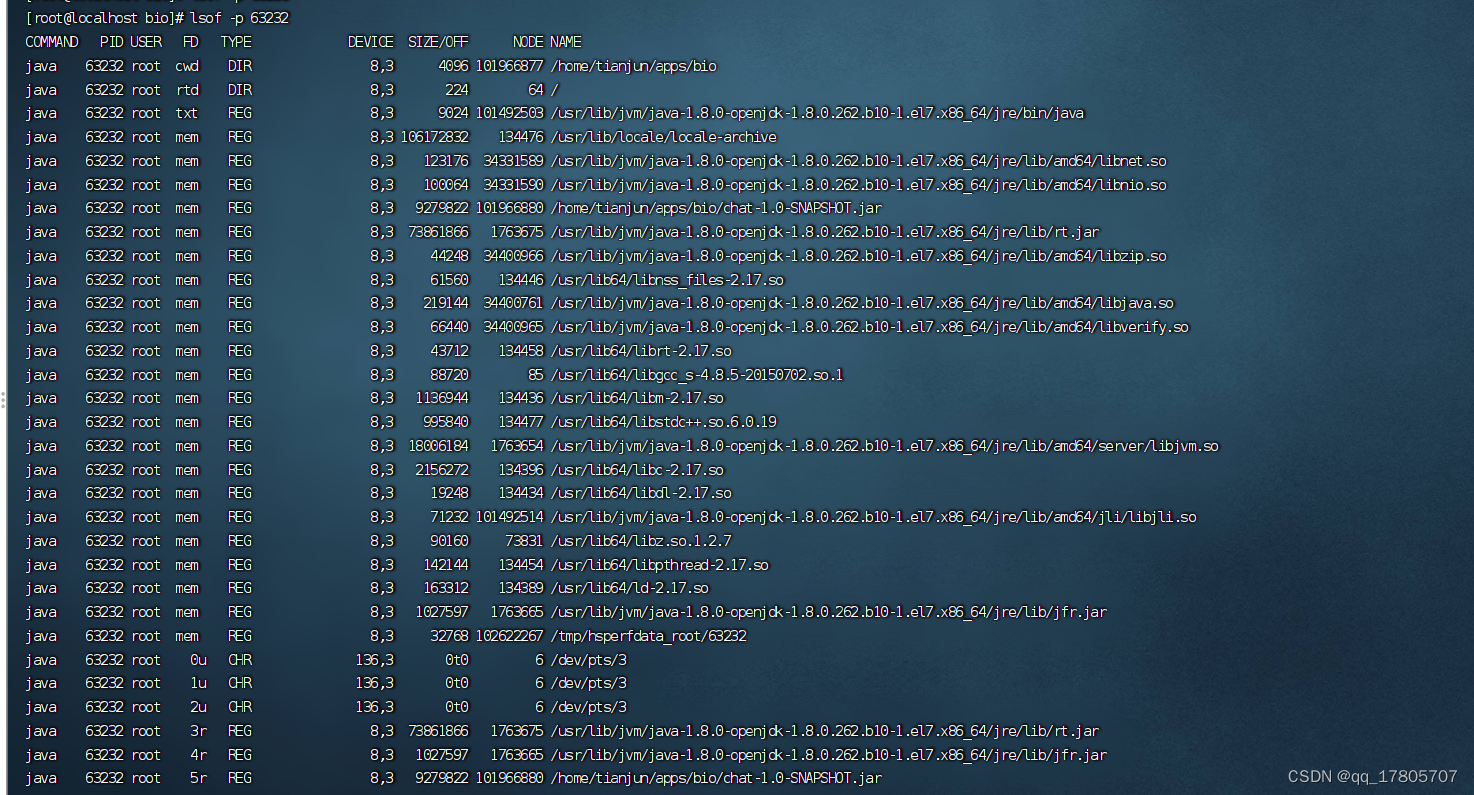 有很多,截图不全,我们也可以去/proc/pid/fd下面去看,区别就是没有显示一些系统的so文件,其中的012,相信大家都知道对应着标准输入、标准输出、错误输出:
有很多,截图不全,我们也可以去/proc/pid/fd下面去看,区别就是没有显示一些系统的so文件,其中的012,相信大家都知道对应着标准输入、标准输出、错误输出:
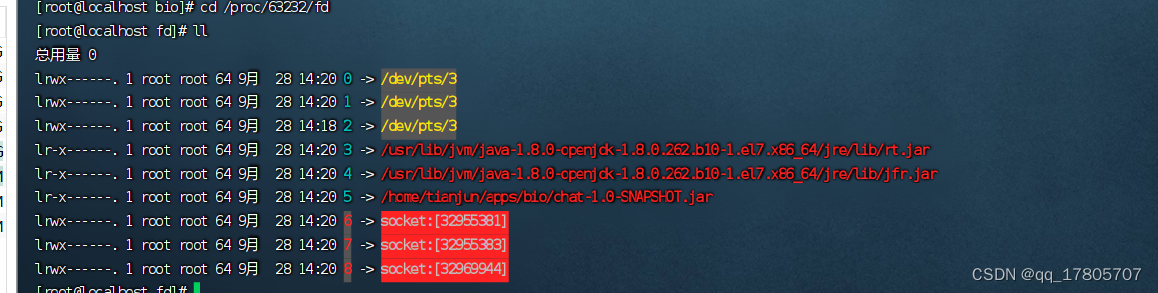
我们的重点还是放到out.63233这个文件当中去,我们用cat命令查看内容会发现一写关键字,比如bind,accept等,我们先来看bind:

这其实对应的也就是java代码中的bind方法
我们知道BIO之所以成为阻塞,意思是没有连接连过来的时候就会一直等着,也就是Socket accept = serverSocket.accept();这一行代码会一直阻塞住,直到有客户端连接过来,我们继续往后翻文件会发现阻塞在poll这里:
 直到有客户端连接进来,就会出现下面的accept那一行,我们继续往后翻,会发现clone字眼:
直到有客户端连接进来,就会出现下面的accept那一行,我们继续往后翻,会发现clone字眼: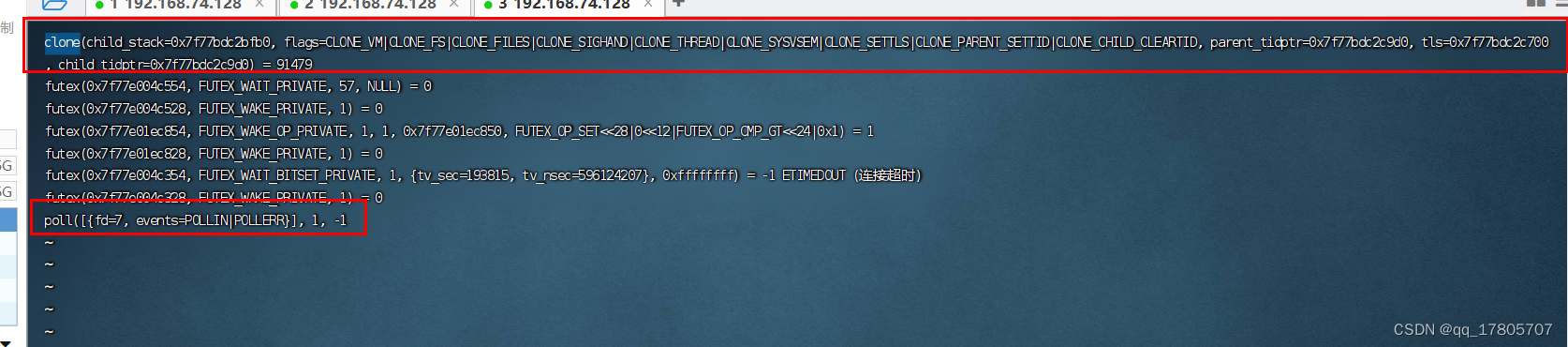
clone这一行的意思就是fork一个子线程出来处理任务,这时候我们可以用lsof命令看会多了一条数据,也就是clone出来的子线程,我们在上图看到文件内容阻塞在了poll,等待下一个连接进来,循环往复
总结一下:传统的BIO模型中,所涉及到的系统调用主要是三个(当然这里还涉及到tcp三次握手,不在本文讨论范围)
- bind,绑定端口
- accept,等待客户端连接
- clone,fork子线程处理数据
所以传统BIO的“慢”体现在两点:
- 等待客户端连接是阻塞的
- 每个连接都需要fork一个子线程来处理