笔记整理:郭荣辉,天津大学硕士
链接:https://arxiv.org/abs/2305.19987
动机
归纳知识图谱补全是预测训练期间没有观察到的新实体之间缺失的三元组的任务。虽然大多数归纳知识图谱补全方法假定所有实体都是新的,但它们不允许在推理时出现新关系。这一限制使得现有的方法无法适当地处理现实世界中新实体伴随着新关系的知识图谱。本文中提出了一个归纳知识图片嵌入方法(INductive knowledge GRAph eMbedding),INGRAM,它可以在推理时生成新关系和新实体的嵌入。给定一个知识图谱,首先将关系图定义为由关系和它们之间的亲和力权重组成的加权图。基于关系图和原始知识图谱,INGRAM将学习如何使用注意力机制聚集邻居嵌入生成关系和实体嵌入。实验结果表明,INGRAM在不同的归纳学习场景中优于14种不同的最先进的方法。
亮点
INGRAM的亮点主要包括:
(1)INGRAM是第一个引入关系级聚合的方法,使模型可以通用于新关系。
(2)与一些依赖大型语言模型的归纳方法不同,INGRAM只根据给定的知识图谱的结构进行推断。
(3)由于INGRAM的完全归纳能力,INGRAM可以通过在一个可操作的、部分观察到的集合上训练INGRAM来生成嵌入,并简单地将其应用于一个全新的集合而无需重新训练。
概念及模型
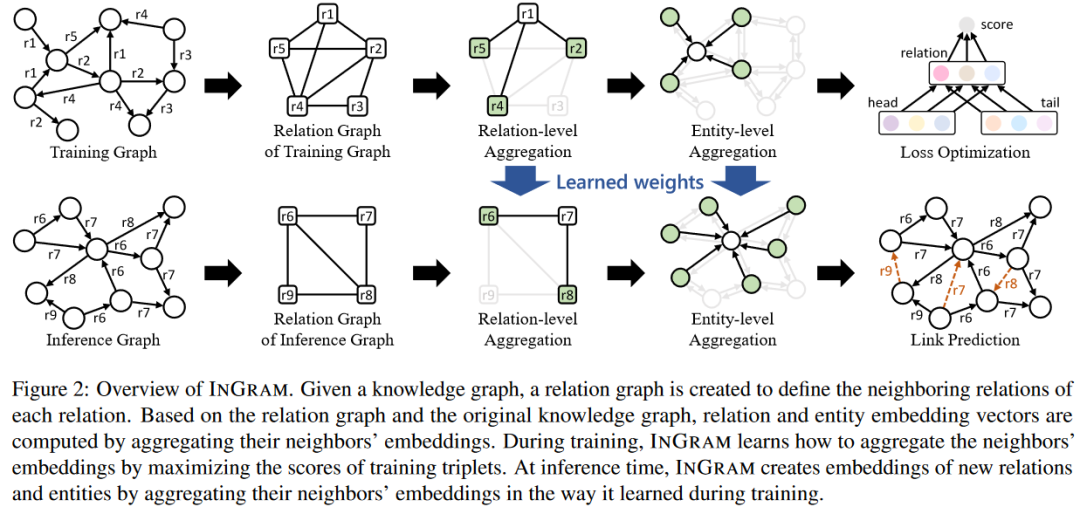
图2展示了当所有关系和实体都是新的时候INGRAM的概况。一个关键的想法是定义一个关系图,其中一个节点对应一个关系,而边的权重表示关系之间的亲和力。一旦关系图被定义,就可以为每个关系指定相邻的关系。考虑到关系图和原始知识图,关系和实体的嵌入向量是通过对其邻居的嵌入进行基于注意力的聚合来计算的。聚合过程通过训练知识图谱中的三元组的可信度分数最大化来进行优化。INGRAM在训练中学习的是如何聚集相邻的嵌入来生成关系和实体嵌入。在推理时,INGRAM根据从给定的推理知识图谱中计算出的新关系图和训练期间学到的注意力权重,通过聚合邻居的嵌入来生成新的关系和实体的嵌入。
问题定义和设置
在归纳知识图谱嵌入中,通常给定两个图谱,一个训练图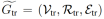 和一个推理图
和一个推理图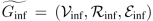 ,其中分别代表实体集、关系集和三元组集。在模型训练时,本文将训练图中的实体集合进行划分
,其中分别代表实体集、关系集和三元组集。在模型训练时,本文将训练图中的实体集合进行划分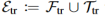 ,前者作为已知三元组集进行训练,后者用来优化预测。同时将推理图的三元组集进行划分
,前者作为已知三元组集进行训练,后者用来优化预测。同时将推理图的三元组集进行划分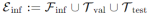 。在调整模型的超参数时,使用
。在调整模型的超参数时,使用 来计算嵌入,使用
来计算嵌入,使用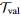 评估模型表现。最后在进行推理时,使用
评估模型表现。最后在进行推理时,使用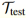 来评价模型表现。
来评价模型表现。
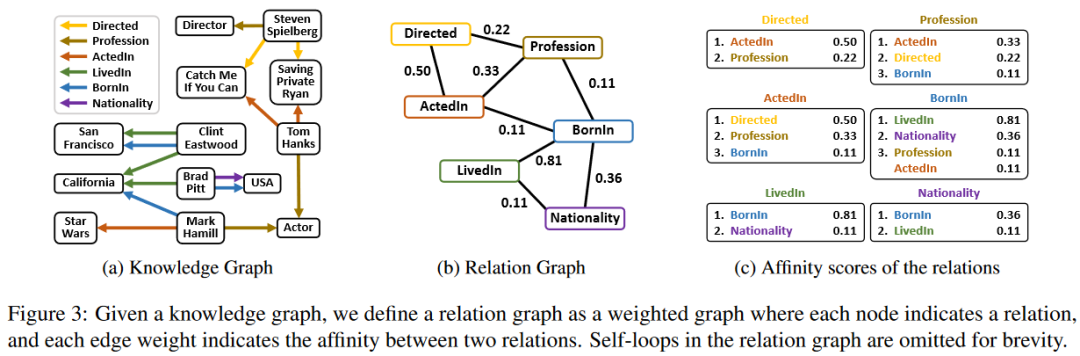
定义关系图
给定一个知识图谱,本文将关系图定义为一个加权图,其中每个节点对应一个关系,每条边的权重表示两个关系之间的亲疏关系。图3是一个例子,为了简单起见,在图中省略了关系图中的反向关系和自循环。本文通过考虑两个关系之间共享多少个实体以及它们共享同一个实体的频率来衡量两个关系之间的亲和性。需要注意的是关系图的目标不是识别完美的相似关系集,而是定义一个关系的合理邻域,其表示向量可以用来创建目标关系的嵌入。
通过基于关系图的聚合来更新关系表示向量
通过知识图谱定义关系图A,可以用A来指定每个关系的相邻关系。本文通过聚合自己和相邻关系的表示向量来更新每个关系的表示。具体来说,定义前向传播如下:

其中的注意力值定义为:
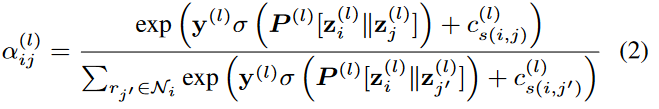
在公式(1)和公式(2)中,主要通过使用注意力机制来更新关系表示向量,同时考虑每个相邻关系的相对重要性和关系之间的亲和力。
通过实体级别的聚合来表示实体
假设有一个实体的初始特征向量,用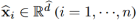 表示。本文通过汇总其邻居的表示向量、其自身的向量以及与实体相邻的关系的表示向量来更新实体自身的表示向量。
表示。本文通过汇总其邻居的表示向量、其自身的向量以及与实体相邻的关系的表示向量来更新实体自身的表示向量。
首先,为了得到实体的自循环的注意权重,计算与实体相邻关系表示向量的平均。
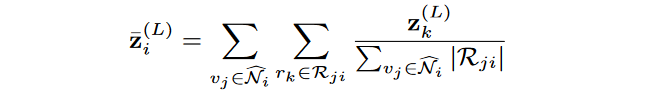
然后通过以下方式更新实体表示向量:
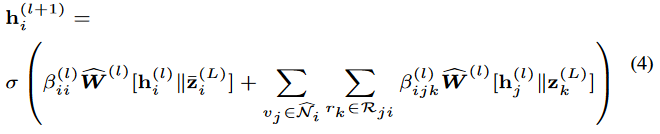
其中,注意力系数定义为:
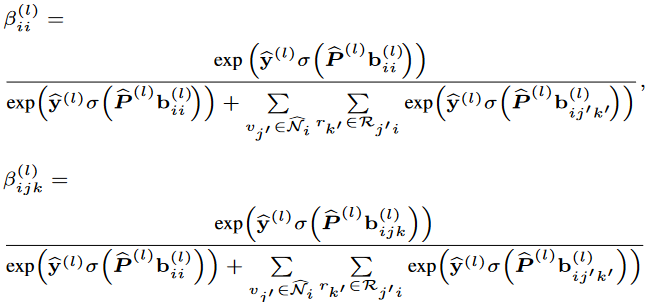
其中在公式(4)中的表示通过在每个聚合步骤中纳入关系表示向量无缝地扩展了GATv2。通过不断更新,最终实体的表示向量被用来建模关系-实体的相互作用。
关系-实体交互的建模
为了模拟关系和实体嵌入之间的相互作用,本文使用了DistMult的一个变种,通过以下方式定义评分函数。
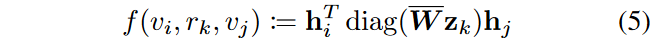
基于边际的排序损失定义为:
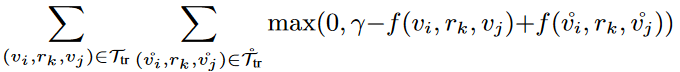
给定 ,可以创建对应的关系图,并使用学到的INGRAM的模型参数计算关系和实体嵌入向量。算法1显示了整个过程。基于
,可以创建对应的关系图,并使用学到的INGRAM的模型参数计算关系和实体嵌入向量。算法1显示了整个过程。基于 上生成的实体和关系的嵌入向量,可以预测丢失的三联体。例如,为了解决
上生成的实体和关系的嵌入向量,可以预测丢失的三联体。例如,为了解决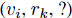 ,可将每个实体
,可将每个实体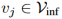 插入给定的三元组中,并使用公式(5)计算得分。预测缺失的实体为最高得分的实体。
插入给定的三元组中,并使用公式(5)计算得分。预测缺失的实体为最高得分的实体。

实验
数据集
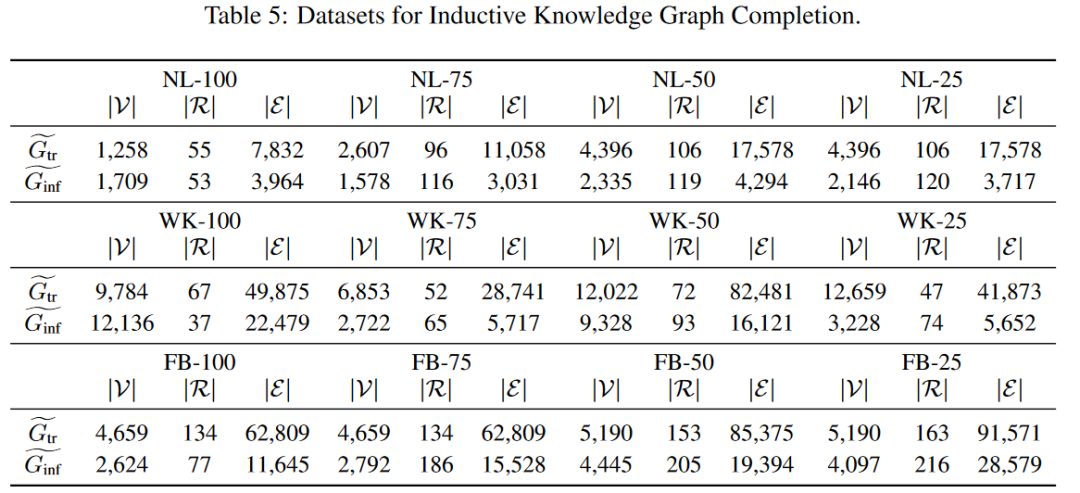
本节在不同的数据集上进行实验,使用三个基准(NELL995、Wikidata68K、FB15K237)创建了12个数据集。对于每个基准,通过改变具有新关系的三元组的百分比来创建四个数据集: 100%,75%,50%和25%。每个数据集的统计信息见表5。
归纳链路预测
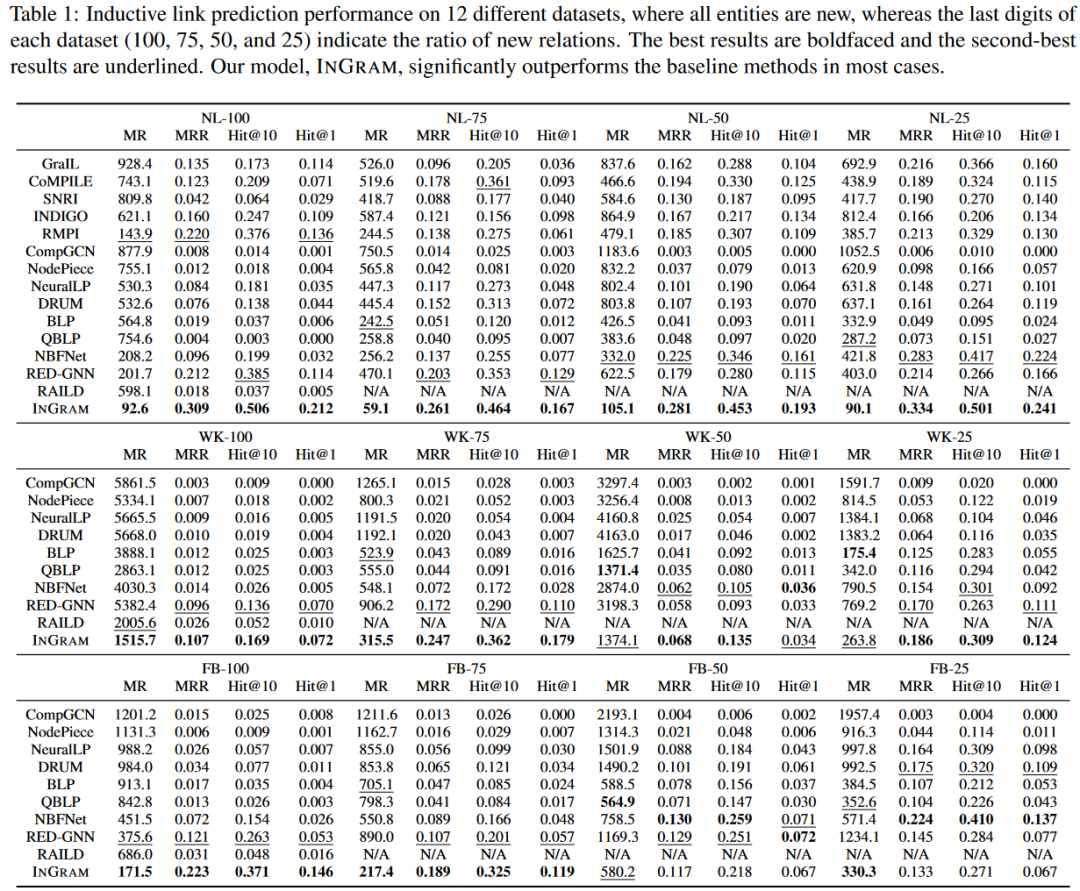
本文使用标准指标来衡量各方法的归纳链路预测的性能: MR(↓)、MRR(↑)、Hit@10(↑)和Hit@1(↑)。表1显示了12个不同数据集的结果,其中所有实体都是新的,每个数据集都有不同的新关系比例。在这些数据集中,INGRAM和最佳基线方法之间的性能差距在所有指标上都是相当大的。这表明INGRAM是关系归纳推理的最有效方法。
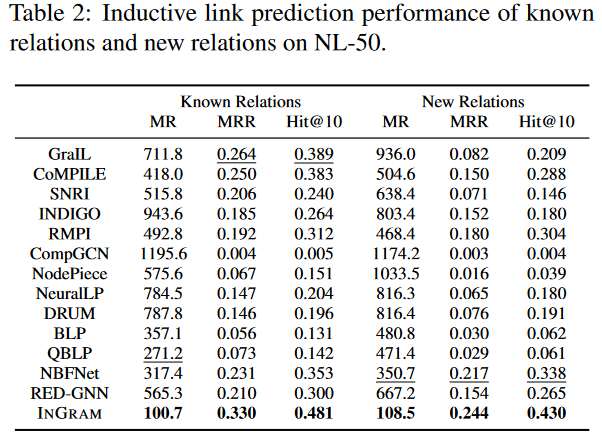
在表2中分析了NL-50上具有已知关系和新关系的三元组的模型性能。所有的方法在已知关系上的表现都比新关系好。另外,对于基线方法,已知关系和新关系之间的性能差距很大。可以看到,对于已知关系和新关系,INGRAM的性能在所有指标上都比最好的基线方法好很多。
用已知的关系进行归纳链接
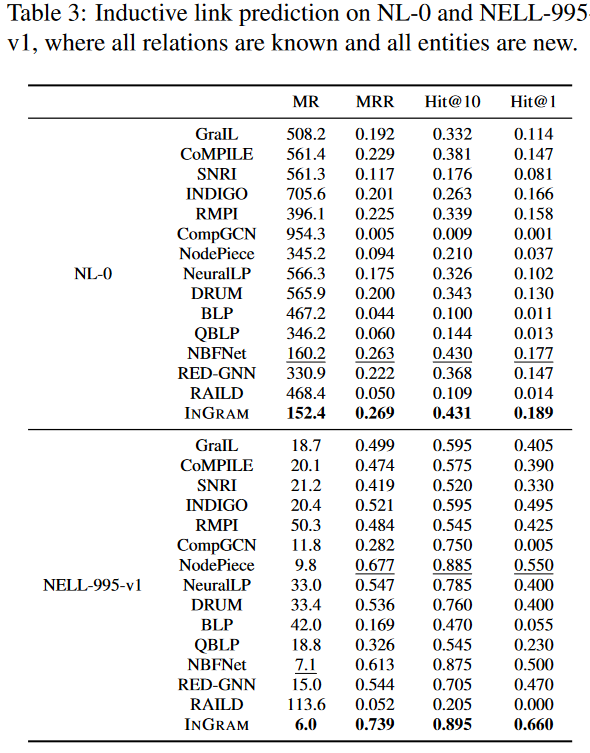
尽管INGRAM被设计为考虑在推理时出现新关系的情况,本文也对传统的归纳链接预测场景进行了实验,其中所有关系都是已知的,所有实体都是新的。表3显示了对NL-0和NELL-995-v1的归纳链路预测结果,其中所有实体都是新的,所有关系都是已知的。可以看到,INGRAM在所有指标上都优于所有基线。尽管INGRAM没有像其他基线那样学习特定的关系模式,但INGRAM在关系的归纳推理上显示出合理的性能,同时对关系的半归纳和归纳推理有额外的概括能力。
总结
本文考虑了具有挑战性和现实性的归纳学习场景,其中新实体伴随着新关系。本文提出的方法,INGRAM,可以生成只在推理时出现的新关系和实体的嵌入。INGRAM只根据给定的知识图的结构进行推理,不需要任何关于实体和关系的额外信息或丰富的语言模型的帮助。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。