title: “重新认识mysql”
createTime: 2022-03-06T15:52:41+08:00
updateTime: 2022-03-06T15:52:41+08:00
draft: false
author: “ggball”
tags: [“mysql”]
categories: [“db”]
description: “”
文章目录
- title: "重新认识mysql" createTime: 2022-03-06T15:52:41+08:00 updateTime: 2022-03-06T15:52:41+08:00 draft: false author: "ggball" tags: ["mysql"] categories: ["db"] description: ""
- mysql 的客户端和服务端结构
- bin目录下的可执行文件
- unix环境下启动mysql server
- windows下启动mysql server
- 客户端连接服务端的过程
- 服务器处理客户端请求
mysql 的客户端和服务端结构
客户端负责接收用户的命令,并且发送给服务端
服务端负责接收客户端的命令,并进行处理,返回给客户端
bin目录下的可执行文件

unix环境下启动mysql server
mysqld
mysqld 这个可执行文件就代表着 MySQL 服务器程序,运行这个可执行文件就可以直接启动一个服务器进程。但这个命令不常用,我们继续往下看更牛逼的启动命令。
mysqld_safe
mysqld_safe 是一个启动脚本,它会间接的调用 mysqld ,而且还顺便启动了另外一个监控进程,这个监控进程在服务器进程挂了的时候,可以帮助重启它。另外,使用 mysqld_safe 启动服务器程序时,它会将服务器程序的出错信息和其他诊断信息重定向到某个文件中,产生出错日志,这样可以方便我们找出发生错误的原因。
mysql.server
mysql.server 也是一个启动脚本,它会间接的调用 mysqld_safe ,在调用 mysql.server 时在后边指定 start参数就可以启动服务器序了,就像这样:
mysql.server start
需要注意的是,这个 mysql.server 文件其实是一个链接文件,它的实际文件是 …/support-files/mysql.server。我使用的 macOS 操作系统会帮我们在 bin 目录下自动创建一个指向实际文件的链接文件,如果你的操作系统没有帮你自动创建这个链接文件,那就自己 创建一个呗~ 别告诉我你不会创建链接文件,上网搜搜呗~
另外,我们还可以使用 mysql.server 命令来关闭正在运行的服务器程序,只要把 start 参数换成 stop 就好了:
mysql.server stop
mysqld_multi
其实我们一台计算机上也可以运行多个服务器实例,也就是运行多个 MySQL 服务器进程。 mysql_multi 可执行文件可以对每一个服务器进程的启动或停止进行监控。这个命令的使用比较复杂,本书主要是为了讲清楚 MySQL 服务器和客户端运行的过程,不会对启动多个服务器程序进行过多唠叨。
windows下启动mysql server
手动启动
双击bin目录下mysqld文件即可
以服务的方式启动
有些时候需要长时间运行程序或者开机自启某些程序,这时候就需要把这个程序注册为windows服务
"完整的可执行文件路径" --install [-manual] [服务名]
其中的 -manual 可以省略,加上它的话表示在 Windows 系统启动的时候不自动启动该服务,否则会自动启动。
服务名 也可以省略,默认的服务名就是 MySQL 。比如我的 Windows 计算机上 mysqld 的完整路径是:
C:\Program Files\MySQL\MySQL Server 5.7\bin\mysqld
所以如果我们想把它注册为服务的话可以在命令行里这么写:
"C:\Program Files\MySQL\MySQL Server 5.7\bin\mysqld" --install
在把 mysqld 注册为 Windows 服务之后,我们就可以通过下边这个命令来启动 MySQL 服务器程序了:
net start MySQL
当然,如果你喜欢图形界面的话,你可以通过 Windows 的服务管理器通过用鼠标点点点的方式来启动和停止服务
(作为一个程序猿,还是用黑框框吧~)。关闭这个服务也非常简单,只要把上边的 start 换成 stop 就行了,就像这样:
net stop MySQL
启动mysql客户端
bin目录下有启动脚本 mysqladmin 、 mysqldump 、 mysqlcheck 等等等等,最重要的是mysqld
启动命令
mysql -h主机名 -u用户名 -p密码
各个参数的意义如下: |参数名|含义| |:–😐:–| | -h |表示服务器进程所在计算机的域名或者IP地址,如果服务器进程就运行在本机的话,可以省略这个参数,或者填 localhost 或者 127.0.0.1 。也可以写作 --host=主机名 的形式。| | -u |表示用户名。也可以写作 --user=用户名 的形式。| | -p |表示密码。也可以写作 --password=密码 的形式。总的说,像 h、u、p 这样名称只有一个英文字母的参数称为短形式的参数,使用时前边需要加单短划线,像 host、user、password 这样大于一个英文字母的参数称为长形式的参数,使用时前边需要加双短划线。
例子
mysql -hlocalhost -uroot -p123456
客户端连接服务端的过程
客户端进程向服务器进程发送请求并得到回复的过程本质上是一个进程间通信的过程。
三种方式
- TCP/IP
- windows下使用命名管道或者共享内存
- unix下使用Unix域套接字文件
服务器处理客户端请求
客户端进程向服务器进程发送一段文本(MySQL语句),服务器进程处理后再向客户端进程发送一段文本(处理结果)
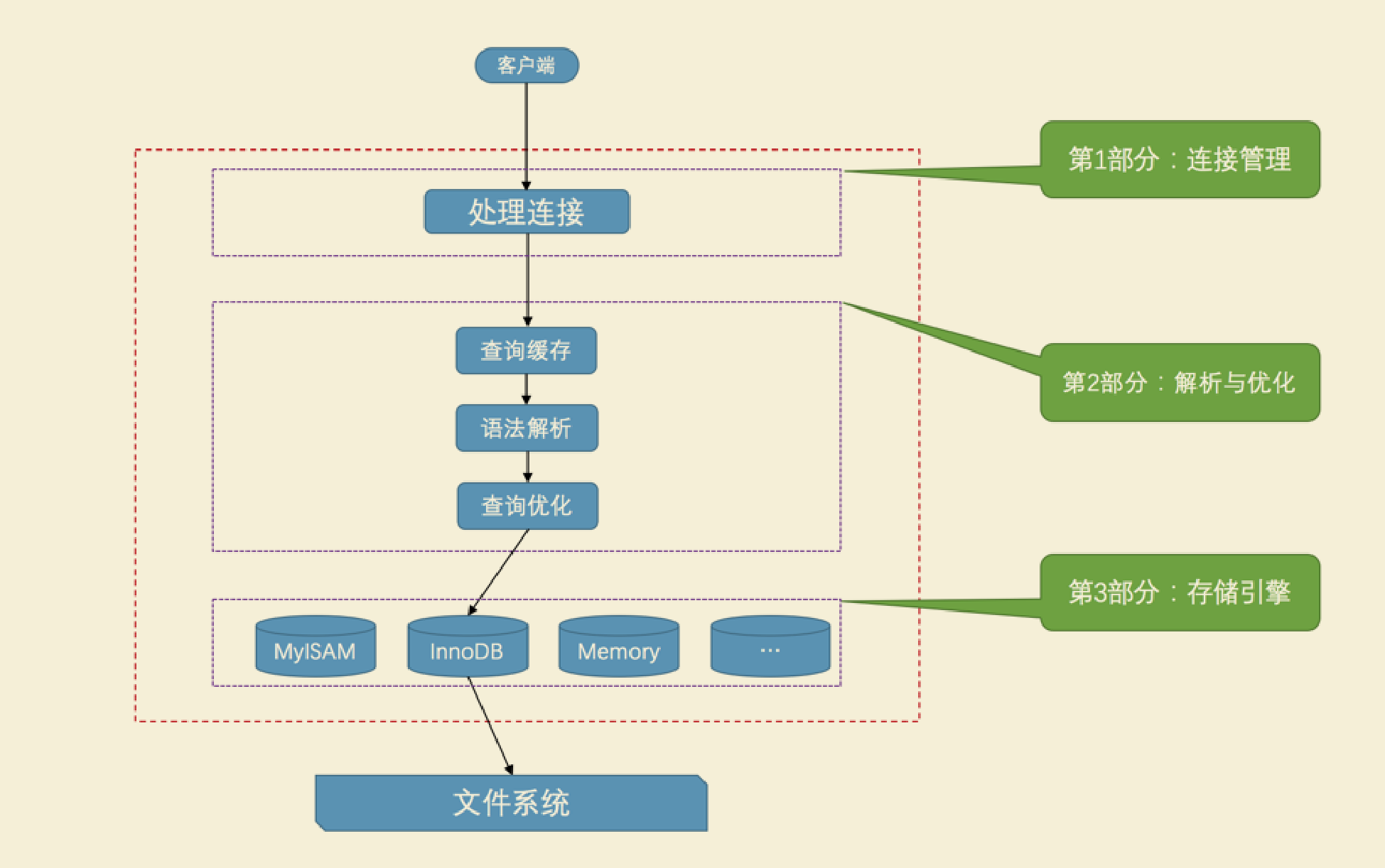
-
连接管理
不管是用以上三种的哪种,mysql服务端都会开启一个线程去连接请求过来的客户端,当客户端与服务端断开连接时,连接不会立马被销毁,而是被缓存起来,待下个客户端连接使用,好处就是避免线程频繁的开启和销毁,减小对系统性能的影响 -
处理链接
- 查询缓存
如果两个查询请求在任何字符上的不同(例如:空格、注释、大小写),都会导致缓存不会命中。另外,如果查询请求中包含某些系统函数、用户自定义变量和函数、一些系统表,如mysql 、information_schema、 performance_schema数据库中的表,那这个请求就不会被缓存。以某些系统函数举例,可能同样的函数的两次调用会产生不一样的结果,比如函数 NOW ,每次调用都会产生最新的当前时间,如果在一个查询请求中调用了这个函数,那即使查询请求的文本信息都一样,那不同时间的两次查询也应该得到不同的结果,如果在第一次查询时就缓存了,那第二次查询的时候直接使用第一次查询的结果就是错误的!
不过既然是缓存,那就有它缓存失效的时候。MySQL的缓存系统会监测涉及到的每张表,只要该表的结构或者数据被修改,如对该表使用了INSERT 、 UPDATE 、 DELETE 、 TRUNCATE TABLE 、 ALTER TABLE 、 DROP TABLE 或 DROP DATABASE语句,那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除!
tips:
- 查询缓存
虽然查询缓存有时可以提升系统性能,但也不得不因维护这块缓存而造成一些开销,比如每次都要去查询缓存中检索,查询请求处理完需要更新查询缓存,维护该查询缓存对应的内存区域。从MySQL 5.7.20开始,不推荐使用查询缓存,并在MySQL 8.0中删除。
- 语法解析
如果查询缓存没有命中,接下来就需要进入正式的查询阶段了。因为客户端程序发送过来的请求只是一段文本而已,所以 MySQL 服务器程序首先要对这段文本做分析,判断请求的语法是否正确,然后从文本中将要查询的表、各种查询条件都提取出来放到MySQL服务器内部使用的一些数据结构上来。 - 查询优化
现在已经获取到需要操作的表的信息,搜索条件等,但是有这些,往往执行效率不是最好的,mysql的优化程序会帮你将sql做些优化,如外连接转换为内连接、表达式简化、子查询转为连接吧啦吧啦的一堆东西
- 存储引擎
以上的操作都还没涉及到真正操作数据,储存引擎才会真正操作数据,我们都知道数据存在表里的一行一行记录,这只是逻辑上的,实际上数据是以什么样的结构,什么样的方式存到磁盘上的,就是储存引擎该做的事。
各种不同的存储引擎向上边的 MySQL server 层提供统一的调用接口(也就是存储引擎API),包含了几十个底层函数,像"读取索引第一条内容"、“读取索引下一条内容”、"插入记录"等等。
常用的储存引擎
| 名称 | 功能 |
|---|---|
| ARCHIVE | 用于数据存档(行被插入后不能再修改) |
| BLACKHOLE | 丢弃写操作,读操作会返回空内容 |
| CSV | 在存储数据时,以逗号分隔各个数据项 |
| FEDERATED | 用来访问远程表 |
| InnoDB | 具备外键支持功能的事务存储引擎 |
| MEMORY | 置于内存的表 |
| MERGE | 用来管理多个MyISAM表构成的表集合 |
| MyISAM | 主要的非事务处理存储引擎 |
| NDBMySQL | 集群专用存储引擎 |