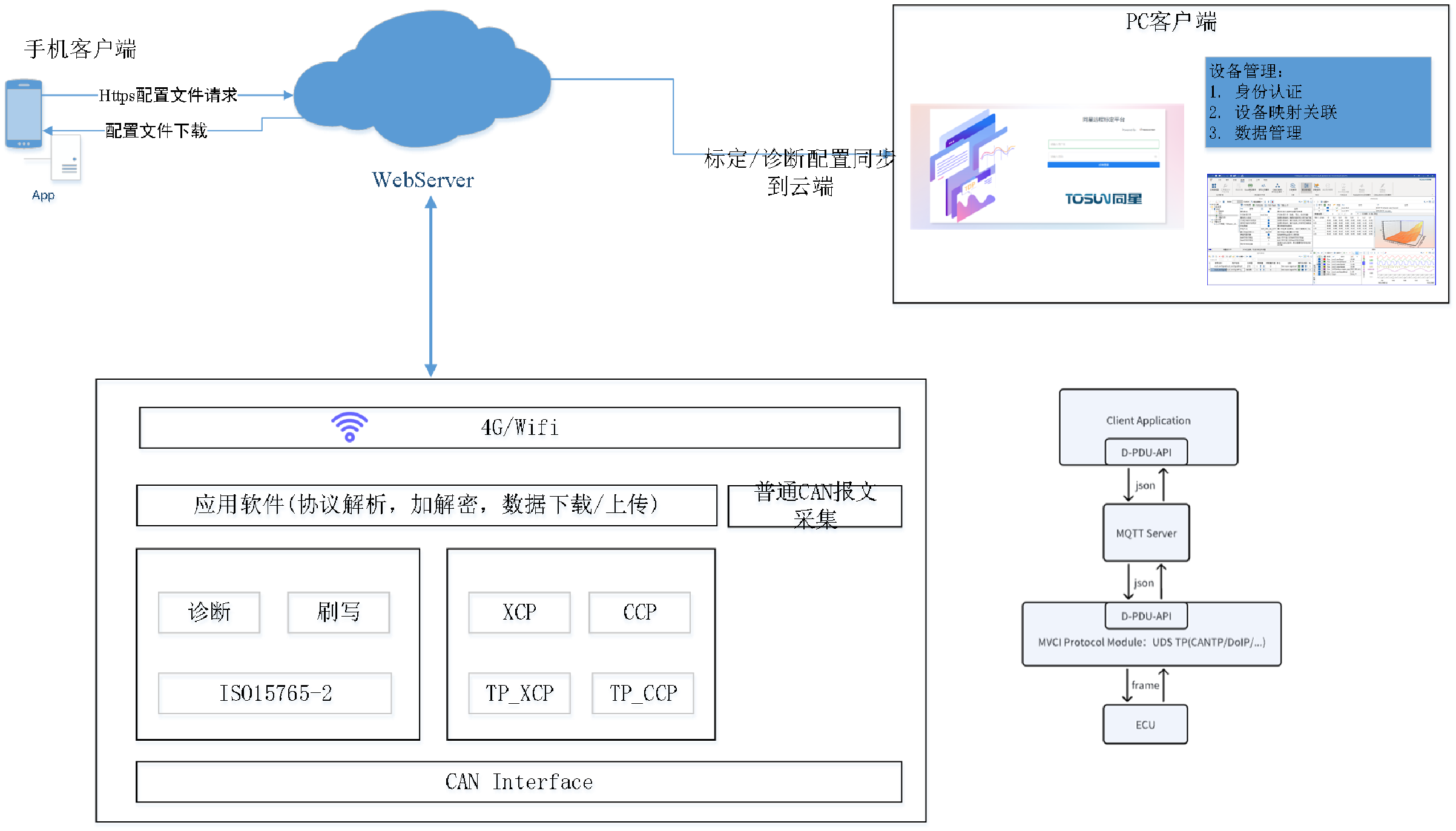
一、前言
百川官网:https://www.baichuan-ai.com/
模型权重:https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat
记录一下 baichuan 2 的 tokenizer 及 chat 数据构建格式。
二、数据处理代码
根据官方 github 的 finetune 代码,将其 preprocessing 方法抽离单独测试。为方便记录,代码中的注释暂时假设每个汉字为一个token,且 input_ids 的注释和实际 id 不保证对应。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
path = "Baichuan2-13B-Chat"
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True)
user_tokens = [195]
assistant_tokens=[196]
ignore_index = -100
model_max_length = 10
def preprocessing(example):
input_ids = []
labels = []
for message in example["conversations"]:
from_ = message["from"]
value = message["value"]
value_ids = tokenizer.encode(value)
if from_ == "human":
input_ids += user_tokens + value_ids
labels += [tokenizer.eos_token_id] + [ignore_index] * len(value_ids)
# input_ids = <reserved_106> 你 是 谁
# labels = </s> -100 -100 -100
else:
input_ids += assistant_tokens + value_ids
labels += [ignore_index] + value_ids
# input_ids = <reserved_106> 你 是 谁 <reserved_107> 我 是 木 尧
# labels = </s> -100 -100 -100 -100 我 是 木 尧
input_ids.append(tokenizer.eos_token_id)
labels.append(tokenizer.eos_token_id)
# input_ids = <reserved_106> 你 是 谁 <reserved_107> 我 是 木 尧 </s>
# labels = </s> -100 -100 -100 -100 我 是 木 尧 </s>
# 切片 截断前 model_max_length 个 token
input_ids = input_ids[:model_max_length]
labels = labels[:model_max_length]
input_ids += [tokenizer.pad_token_id] * (model_max_length - len(input_ids))
labels += [ignore_index] * (model_max_length - len(labels))
# input_ids = <reserved_106> 你 是 谁 <reserved_107> 我 是 木 尧 </s> <unk> <unk> <unk> ... <unk>
# labels = </s> -100 -100 -100 -100 我 是 木 尧 </s> -100 -100 -100 ... -100
input_ids = torch.LongTensor(input_ids)
labels = torch.LongTensor(labels)
attention_mask = input_ids.ne(tokenizer.pad_token_id) # ne 即 not equal 不等于,不等于unk则为true即mask掉,等于则为false
# input_ids = <reserved_106> 你 是 谁 <reserved_107> 我 是 木 尧 </s> <unk> <unk> <unk> ... <unk>
# labels = </s> -100 -100 -100 -100 我 是 木 尧 </s> -100 -100 -100 ... -100
# attention_mask = True True True True True True True True True True True True True ... True
return {
"input_ids": input_ids,
"labels": labels,
"attention_mask": attention_mask,
}
example 数据格式及运行测试:
preprocessing({
"system": "",
"conversations": [
{
"from": "human",
"value": "你是谁"
},
{
"from": "yayi",
"value": "我是木尧"
}
]
})
# Output:
# {'input_ids': tensor([ 195, 92067, 196, 6461, 93334, 95562, 2, 0, 0, 0]),
# 'labels': tensor([ 2, -100, -100, 6461, 93334, 95562, 2, -100, -100, -100]),
# 'attention_mask': tensor([ True, True, True, True, True, True, True, False, False, False])}
案例分析:
- 百川2用预留的 token 表示 human 和 assistant 的内容,上面例子会转化成:
<reserved_106>你是谁<reserved_107>我是木尧</s><unk><unk> ... <unk>。<reserved_106>(id=195)表示 human 输入。<reserved_107>(id=196)表示 assistant 输出。
- 首先,遍历
conversations中的每一轮 human 和 assistant:- input_ids:前面拼上各自的标识符(
<reserved_106>、<reserved_107>)之后拼接各自内容对应的 token ids。 - labels:对于 human 的内容,其标识符对应位置是
</s>(的id),其他位置是 -100,不计算这些 loss 和梯度;对于 assistant 的内容,其标识符对应位置是 -100,其他位置和 input_ids 一致。(为啥开始不是-100而是</s>呢?issue里找到了答案,详见总结部分)
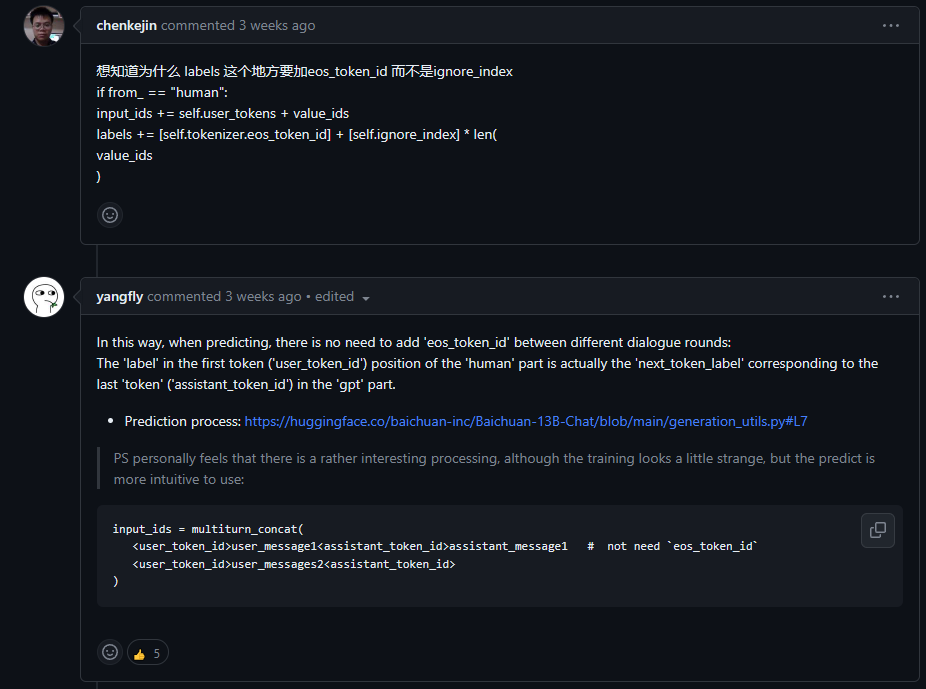
- input_ids:前面拼上各自的标识符(
- 然后,分别在 input_ids 和 labels 追加结束符
</s>,并根据 model_max_length 填充 pad token 即<unk>,或超长截断,并转成 tensor; - 最后,构造 attention_mask,非 pad token 的部分全是 true,pad token 部分全是 false,忽略后面这些填充位置的 attention 计算。
三、总结

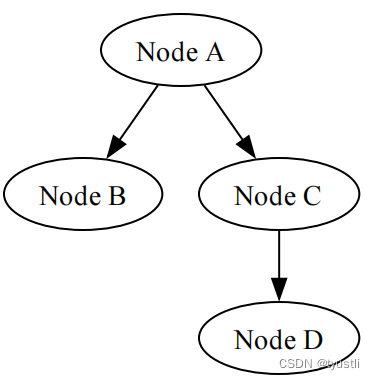
上图是简单做了页PPT,以多轮数据为例。把 user_token_id 对应位置的 label 设置为结束符 </s>,推理时拼接多轮时就不用拼接结束符了。因为 human 的第一个token(位于’user_token_id’位置)实际上是与 assistant 部分中最后一个token(‘assistant_token_id’)对应的’next_token_label’。
附上 baichuan2 词表的前 2000 个token(从101: <reserved_12> 到 1088: <reserved_999> 都是预留的 token):
0 <unk>
1 <s>
2 </s>
3 <SEP>
4 <CLS>
5 \n
6 \t
7 <img>
8 <img/>
9 </img>
10 <h2>
11 <h2/>
12 </h2>
13 <td>
14 <td/>
15 </td>
16 <strong>
17 <strong/>
18 </strong>
19 <table>
20 <table/>
21 </table>
22 <tr>
23 <tr/>
24 </tr>
25 <li>
26 <li/>
27 </li>
28 <b>
29 <b/>
30 </b>
31 <h3>
32 <h3/>
33 </h3>
34 <br>
35 <br/>
36 </br>
37 <h4>
38 <h4/>
39 </h4>
40 <h5>
41 <h5/>
42 </h5>
43 <p>
44 <p/>
45 </p>
46 <h1>
47 <h1/>
48 </h1>
49 <tbody>
50 <tbody/>
51 </tbody>
52 0
53 1
54 2
55 3
56 4
57 5
58 6
59 7
60 8
61 9
62 +
63 -
64 =
65 ,
66 。
67 !
68 ?
69 、
70 :
71 ¥
72 .
73 !
74 ?
75 ...
76 。。。
77 。。。。。。
78 《
79 》
80 【
81 】
82 『
83 』
84 ```
85 <!--
86 -->
87 ---
88 <!DOCTYPE>
89 ;
90 .
91 =
92 <
93 >
94 -
95 +
96 %
97 ‼
98 ㊣
99 /
100 |
101 <reserved_12>
102 <reserved_13>
103 <reserved_14>
104 <reserved_15>
......
1085 <reserved_996>
1086 <reserved_997>
1087 <reserved_998>
1088 <reserved_999>
1089 <0x00>
1090 <0x01>
1091 <0x02>
1092 <0x03>
......
1341 <0xFC>
1342 <0xFD>
1343 <0xFE>
1344 <0xFF>
1345 ▁t
1346 ▁a
1347 in
......
1996 ▁know
1997 ▁sec
1998 研究
1999 ▁these