与Oracle普通视图仅存储查询定义不同,物化视图(Materialized View)会将查询结果"物化"并保存下来,这意味着物化视图会消耗存储空间,物化的数据需要一定的刷新策略才能和基表同步,在使用和管理上比普通视图要略复杂。
目录
一、物化视图简介
1.1 物化视图应用场景
1.2 物化视图的类型
二、物化视图创建
2.1 通过语句创建物化视图
2.2 通过注册创建物化视图
三、物化视图刷新
3.1 刷新类型
3.1.1 全量刷新(refresh complete)
3.1.2 增量刷新(refresh fast)
3.2 刷新模式
3.2.1 手动刷新(on demand)
3.2.1.1 使用dbms_mview.refresh刷新指定物化视图
3.2.1.2 使用dbms_mview.refresh_all_mviews刷新所有物化视图
3.2.1.2 使用dbms_mview.refresh_dependent刷新某基表上的所有物化视图
3.2.2 事务级自动刷新(on commit)
3.2.3 语句级自动刷新(on statement)
3.2.4 定期刷新(start with … next)
四、查询重写
一、物化视图简介
物化视图主要用在OLAP环境,可以提前运行大量运算并保存结果,为后续查询加速。
1.1 物化视图应用场景
为什么要使用物化视图?假设一个场景,用户每天都需要分析销售数据,而每天产生的数据量都非常庞大,在原始数据上直接运行查询SQL(例如进行sum,avg的操作),速度会非常缓慢。传统的查询优化手段,例如索引、分区、并行执行等,在这种场景下都无法将速度提升到一个可接受的范围。
对于这种问题,传统的解决方案是建立一张中间表,提前运行查询SQL并将结果保存下来,当用户查询的时候直接查询结果表。此解决方案虽然可以大幅提升相应时间,但也存在两个问题:
- 对于应用,原先访问的是基表,现在需要访问结果表,意味着应用代码需要修改。
- 结果表需要手动的刷新,如果需要频繁的全量刷新很麻烦。
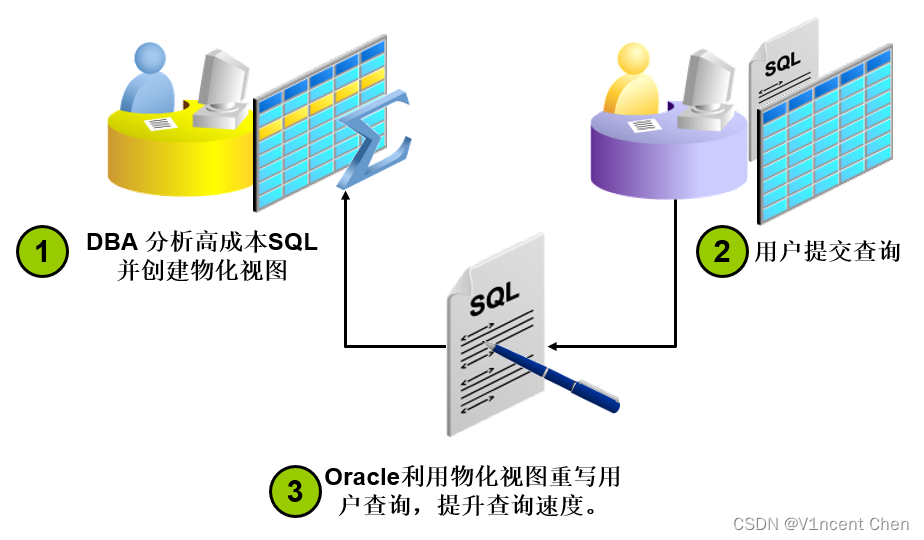
而利用Oracle物化视图则可以完美解决上述问题:
- 物化视图也是预先计算出结果并保存,利用"查询重写"(Query Rewirte)的特定,优化器如果发现可以通过物化视图提升速度,那么会直接改写原SQL,转而查询物化视图,这个操作对应用和用户是完全透明的(应用不需要知道物化视图的存在)。
- 物化视图有各种刷新策略,可以很好的适应复杂的数据刷新场景。
1.2 物化视图的类型
物化视图根据其查询SQL的特点,可以分为下面3类:
- 聚合物化视图,查询定义中包含例如sum(), avg(), count()等聚合函数,这类视图用来预先计算统计数据。
- 连接物化视图,查询定义中不包含聚合函数,仅包含连接,这类视图用来预先计算一些高成本的连接。
- 嵌套物化视图,查询定义中引用了其他的物化视图,这类视图通常用来作为一些大物化视图的中间结果集,可以被多个物化视图重复引用,以防止类似的结果集在多个物化视图中重复计算很多次。
二、物化视图创建
物化视图可以通过create materialized view语句直接创建,如果你已经在使用中间表,也可以将其注册为物化视图。
2.1 通过语句创建物化视图
物化视图是通过 create materialized view 语句创建的,在创建时可以指定物化视图的特性。我们以Oracle自带的sample schema下SH用户下的sales和customers表为示例:
create materialized view sales_mv
build immediate
refresh complete
enable query rewrite
as
select c.cust_id,s.channel_id,sum(amount_sold) sold_sum
from sales s, customers c
where s.cust_id=c.cust_id
group by c.cust_id,s.channel_id
order by c.cust_id,s.channel_id;
语法解释:
- create materialized view 指定创建物化视图,sales_mv是物化视图的名称,和普通视图一样,你也在后面用括号为每列显式指定名称。
- build immediate 创建时立刻填充数据,另一个选项是build defferred,创建时不填充数据
- refresh complete 全量刷新,对应的还有增量刷新。你可以在创建时或创建后手动执行,全量刷新会执行物化视图的定义SQL,可能较费时。
- enable query rewrite 允许利用物化视图查询重写(会话参数query_rewrite_enabled也要设置为True)。
- as 后面的就是物化视图的查询SQL,这里和普通视图一样。
当物化视图创建成功时,Oracle会创建下列对象:
- 一个容器表(Container Table),用来存放物化视图的数据,容器表的名称和物化视图相同。
- 物化视图自己。
- 如果是聚合物化视图,还会额外创建一个包含聚合函数的索引(基于函数的索引),如果是连接或嵌套物化视图,则不会创建。
你可以通过多dba_objects或dba_indexes查询到这些对象:
select owner,object_name,object_type,status from dba_objects where object_name='SALES_MV';
select owner,index_name,index_type,table_name from dba_indexes where table_name='SALES_MV';
由于示例创建的是聚合物化视图,所以会额外创建一个基于函数的索引(索引类型是:function-based normal)。
2.2 通过注册创建物化视图
有的时候你可能已经创建好了中间表,如果再创建一个物化视图,那么可能会重复进行复杂的计算。你可以将你创建的表作为容器表注册为物化视图,注册后同样可以查询重新或使用物化视图刷新策略。
我们删除刚才创建的物化视图,用注册的方式重新创建。
drop materialized view sales_mv;
当物化视图删除后,上面创建的3个对象也就一并删除了。
先创建一个中间表:
create table sales_mv as
select c.cust_id,s.channel_id,sum(amount_sold) sold_sum
from sales s, customers c
where s.cust_id=c.cust_id
group by c.cust_id,s.channel_id
order by c.cust_id,s.channel_id;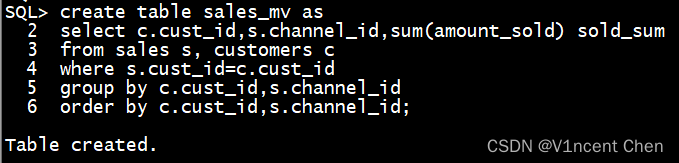
将其注册为物化视图,物化视图的注册是通过on prebuilt table子句完成的:
create materialized view sales_mv
on prebuilt table without reduced precision
enable query rewrite
as
select c.cust_id,s.channel_id,sum(amount_sold) sold_sum
from sales s, customers c
where s.cust_id=c.cust_id
group by c.cust_id,s.channel_id
order by c.cust_id,s.channel_id;
语法解释:
- 物化视图的名称必须和容器表的名称相同。
- on prebuilt table 指示基于同名的表创建创建物化视图
- without reduced precision 限制物化视图列的数据类型必须和容器表匹配,否则创建失败。
注意:当通过注册创建物化视图时,Oracle不会为聚合物化视图创建一个基于函数的索引(你需要自己创建合适的索引)。同时就算你删除物化视图,其容器表也不会被删除,这里和语句创建的物化视图不同。
三、物化视图刷新
由于基表的数据在不断变化,所以物化视图必须要有一定的刷新策略来保持更新。
3.1 刷新类型
当基表的数据变化时,物化视图中的数据也需要定期刷新,刷新的类型有2种:
- 全量刷新
- 增量刷新
3.1.1 全量刷新(refresh complete)
全量刷新可以在创建物化视图时通过build immediate语句指定,或者在创建物化视图后,你随时可以手动进行全量刷新。全量刷新会清空物化视图数据,重新执行定义SQL语句并重新插入数据,这个操作通常比较慢。
如果物化视图创建时指定了build deferred,那么在物化视图可以使用前,必须要进行一次全量刷新。
3.1.2 增量刷新(refresh fast)
增量刷新,又叫快速刷新(Fast Refresh),是通过记录基表数据变化,仅刷新视图变化的数据部分,相比全量刷新速度要快很多。
增量刷新分为2种:
- 一种是基于日志的增量刷新,这种方式每个物化视图引用的基表都需要创建一个日志来记录数据变更。
- 另一种是基于分区变更追踪(Partition Change Tracking)的刷新,这种刷新会移除物化视图特定分区的数据然后重新计算。
在建立基于日志快速刷新的物化视图时,首先要用 create materialized view log 语句为视图的基表建立物化视图日志,用来跟踪基表的数据变更。
分区变更追踪刷新(PCT Refresh),视图的基表是分区表,当对分区进行维护操作时,只能选用这种增量刷新方式。
3.2 刷新模式
根据物化视图刷新模式,可以分为以下几类:
- on demand: 手动刷新,默认模式,物化视图不会自动刷新,用户根据自己的需求通过调用存储过程来刷新物化视图。
- on commit: 自动刷新(事务级),每当基表上有事务提交时都会刷新物化视图。
- on statement: 自动刷新(语句级),每当基表上有DML语句时,都会刷新物化视图。
- start with … next : 定期刷新,通过start with和next关键字,指定一个起始时间和间隔,物化视图将以指定的间隔自动刷新
3.2.1 手动刷新(on demand)
on demand 代表手动刷新,这是默认的模式,Oracle不会主动的刷新物化视图。用户根据需要自己调用dbms_view包来完成视图的刷新,常用的刷新存储过程有:
- dbms_mview.refresh 刷新1个或多个物化视图
- dbms_mview.refresh_all_mviews 刷新所有的物化视图
- dbms_mview.refresh_dependent 刷新所有基于指定基表(或物化视图)的物化视图
3.2.1.1 使用dbms_mview.refresh刷新指定物化视图
使用dbms_mview.refresh可以刷新单个或多个物化视图,刷新上面创建的sales_mv视图:
begin
dbms_mview.refresh(
list => 'SALES_MV',
method => 'F'
);
end;/
参数解释:
- list: 要刷新的物化视图列表,如果有多个物化视图,用逗号隔开即可。
- method: 刷新方式,可选择的值有 C 全量刷新 / F 快速刷新 / P 基于PCT的快速刷新 / ? 尝试快速刷新,如果失败则全量刷新
3.2.1.2 使用dbms_mview.refresh_all_mviews刷新所有物化视图
dbms_mview.refresh_all_mviews可以用来刷新所有的物化视图:
declare
failures number;
begin
dbms_mview.refresh_all_mviews(
number_of_failures => failures,
method => 'C',
refresh_after_errors => TRUE
);
end;
/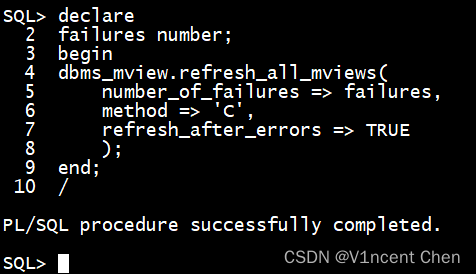
参数解释:
- number_of_failures 是一个输出参数,返回刷新失败的物化视图数量
- method 选择C代表是全量刷新
- refresh_after_errors 物化视图刷新失败时会继续刷新其他视图
3.2.1.2 使用dbms_mview.refresh_dependent刷新某基表上的所有物化视图
dbms_mview.refresh_dependent 可以刷新指定基表或物化视图之上建立的所有物化视图,这个存储过程适合那些单张基表上建立了多个物化视图的场景,例如sales表有大范围数据更新,而上面建立了多张视图,逐一刷新太麻烦,那么就可以用这个存储过程仅刷新基于sales表建立的视图:
declare
failures number;
begin
dbms_mview.refresh_dependent(
number_of_failures => failures,
list => 'sales, customers',
method => 'C',
refresh_after_errors => TRUE
);
end;
/
上面的示例刷新了基于sales, customers表建立的所有物化视图
3.2.2 事务级自动刷新(on commit)
on commit 表示事务级的自动刷新,当物化视图的任意基表上有事务提交时,都会自动刷新物化视图。这种刷新方式可以保证视图和基表数据的一致性,此时物化视图刷新会变成事务的一部分,所以如果单个事务更新了大量的数据会,那么提交时物化视图的刷新工作量会非常大,降低提交的效率。因此建议尽量保持事务短小,可以提升刷新速度。
create materialized view log on sales with rowid, sequence(cust_id, channel_id, amount_sold) including new values;
create materialized view log on customers with rowid, sequence(cust_id) including new values;
create materialized view sales_mv_oncmt
build immediate
refresh fast on commit
enable query rewrite
as
select c.cust_id, s.channel_id, sum(amount_sold) sold_sum
from sales s, customers c
where s.cust_id=c.cust_id
group by c.cust_id, s.channel_id
order by c.cust_id, s.channel_id;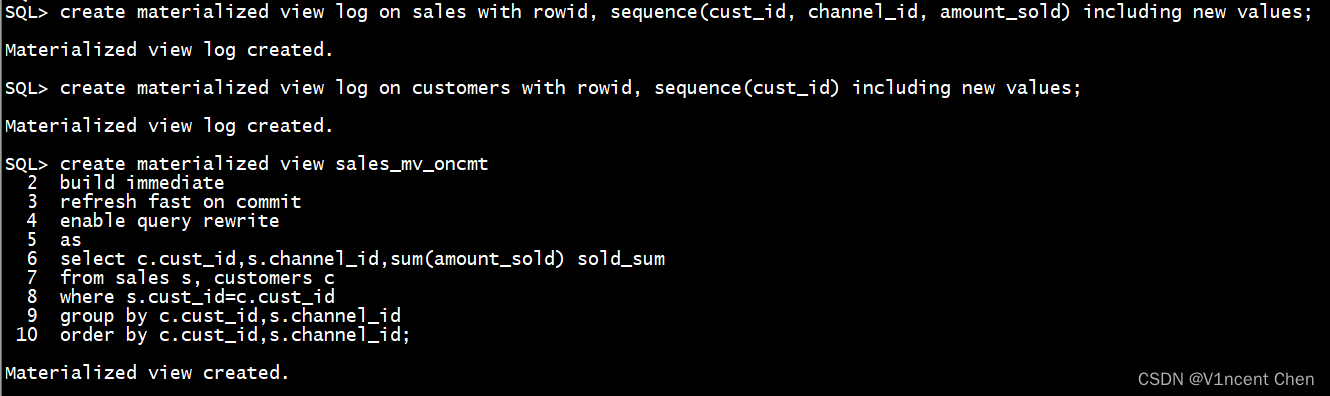
语法解释:
- 这里使用了快速刷新(refresh fast)因此创建物化视图前要先建立物化视图日志。
- create materialized view log 语句创建物化视图日志。
- with rowid 代表要将数据的rowid记录到日志中
- sequence 也是上面with子句的一部分,代表提供额外的排序信息
- (columns1, columns2 …) 物化视图引用到的所有列都要记录进日志。
- including new values 指示日志将数据变更的新值和旧值一起记录进日志。
3.2.3 语句级自动刷新(on statement)
on statement 表示语句级的自动刷新,这种模式只能在创建物化视图时指定。当物化视图的任意基表执行DML语句时(不需要提交),都会刷新物化视图。这种刷新方式会让视图与基表在任何时间都保持同步,如果基表上的DML回滚了,那么物化视图中的变化同样也会回滚。
使用on statement这种刷新频率必须配合快速刷新模式(refresh fast)使用,由于在DML执行过程中需要额外的刷新物化视图操作,所以会降低DML语句的效率。
此外,on statement刷新模式还有一些使用场景限制,物化视图基表的连接必须是星型(star schema)或雪花型(snowflake),即有一个中心表事实表(fact table)通过主-外键与维度表(dimension table)连接,事实表的主键必须包含在物化视图中,Oracle会自动在事实表的主键上创建一个索引来提升刷新速度。
create materialized view sales_mv_onstmt
build immediate
refresh fast on statement
as
select s.rowid, c.cust_first_name, c.cust_last_name, s.amount_sold
from sh.sales s, sh.customers c
where s.cust_id = c.cust_id;3.2.4 定期刷新(start with … next)
如果物化视图需要定期刷新,那么则可以选用start with … next 来为物化视图指定一个刷新间隔,start with子句指定首次自动刷新时间,next子句指定后续刷新间隔(从start with指定首次刷新开始)。如果忽略的start with子句,那么则以当前日期开始计算后续的刷新间隔,如果忽略了next子句,那么物化视图只会在start with指定的时间刷新一次。
create materialized view sales_mv_interval
refresh complete start with sysdate + 4/24
next next_day(trunc(sysdate), 'Monday') + 12/24
as select * from customers;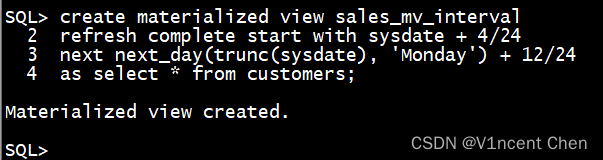
语法解释:
- start with sysdate + 4/24 表示今日4:00首次刷新
- next next_day(trunc(sysdate), 'Monday') + 12/24 表示以后每个周一的12:00刷新一次
四、查询重写
物化视图建立后,优化器就可以利用物化视图来进行查询重写了,用户对基表的查询可能会被物化视图替代,从而提升执行速度。查询重写对用户和应用都是透明的,但是其也需要满足一定条件:
- 建立物化视图时,必须包含enable query rewrite子句。
- 用户会话的 query_rewirte_enable 参数必须设置为True(默认)或者force
query_rewirte_enable 参数有3个值:
- false 禁用查询重写
- true 允许查询重写,优化器将根据成本自行选择是否使用
- force 强制使用查询重写