Apache Lucene : Flush, Commit
Elasticsearch 是一个基于 Apache Lucene 构建的搜索引擎。 它利用 Lucene 的倒排索引、查询处理和返回搜索结果等功能来执行搜索。 它还扩展了 Lucene 的功能,添加分布式处理功能以支持大型数据集的搜索。 让我们看一下 Apache Lucene 的功能,这些功能使 Elasticsearch 能够执行这些角色。
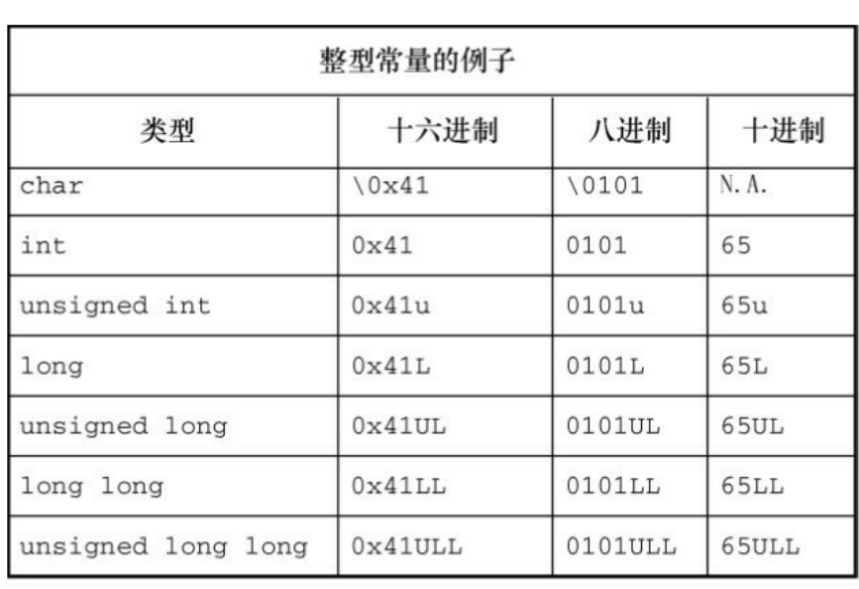
Apache Lucene: Flush
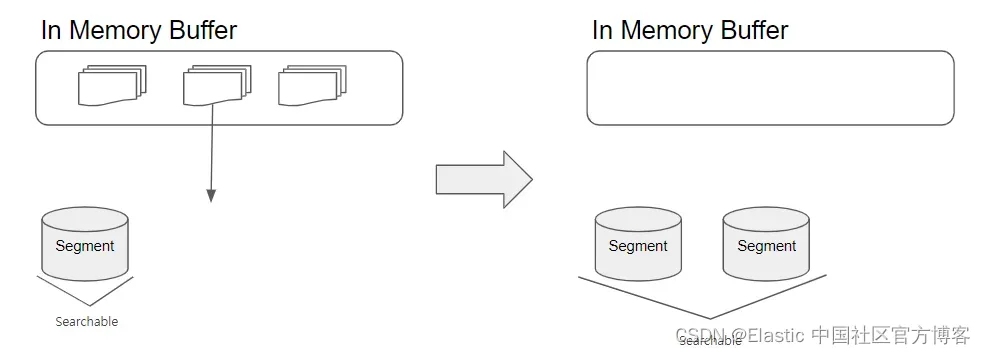
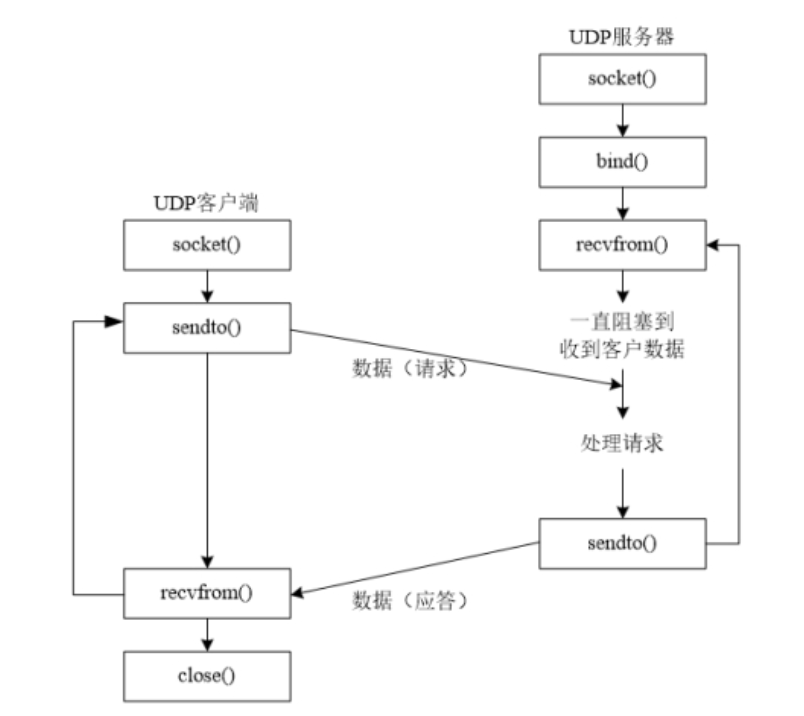
当收到文档索引请求时,Lucene 会为文档创建一个倒排索引并将其存储在内存缓冲区中。 当执行索引、更新或删除文档等操作时,Lucene 将这些更改保存在内存缓冲区中,并定期将它们刷新(flush)到磁盘。
刷新(flush)是指将索引文档从易失性内存缓冲区(例如 RAM)移动到物理段的过程。 执行刷新有以下好处:
- 改进的性能:如果索引文档存储在内存中,则每次执行搜索时都必须从内存中读取它们。 将文档刷新到磁盘可以提高搜索性能。
- 数据丢失预防:如果发生内存丢失,索引文档可能会丢失。 将文档刷新到磁盘可以防止数据丢失。
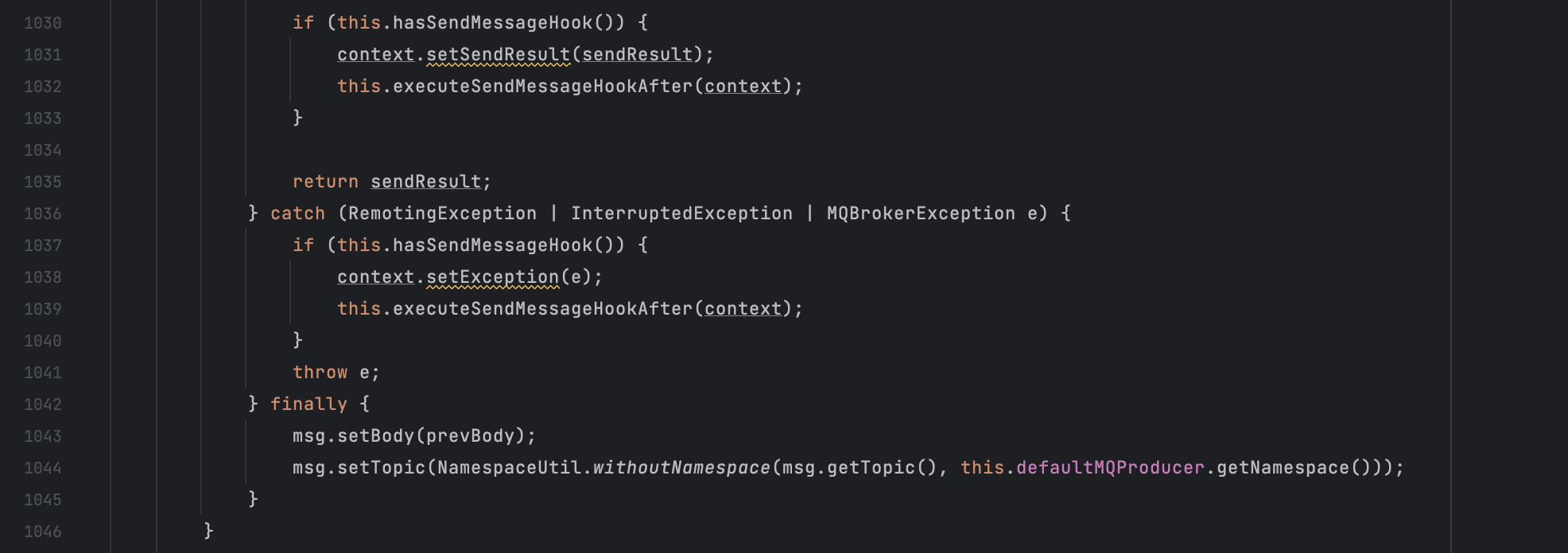
private ExternalReaderManager createReaderManager(RefreshWarmerListener externalRefreshListener) throws EngineException {
boolean success = false;
ElasticsearchReaderManager internalReaderManager = null;
try {
try {
final ElasticsearchDirectoryReader directoryReader = ElasticsearchDirectoryReader.wrap(
// DirectoryReader.open() !
DirectoryReader.open(indexWriter),
shardId
);
internalReaderManager = new ElasticsearchReaderManager(directoryReader);
// lastCommittedSegmentInfos
lastCommittedSegmentInfos = store.readLastCommittedSegmentsInfo();
ExternalReaderManager externalReaderManager = new ExternalReaderManager(internalReaderManager, externalRefreshListener);
success = true;
return externalReaderManager;
} catch (IOException e) {
maybeFailEngine("start", e);
try {
indexWriter.rollback();
} catch (IOException inner) { // iw is closed below
e.addSuppressed(inner);
}
throw new EngineCreationFailureException(shardId, "failed to open reader on writer", e);
}
} finally {
if (success == false) { // release everything we created on a failure
IOUtils.closeWhileHandlingException(internalReaderManager, indexWriter);
}
}
}- DirectoryReader.open() 方法打开 DirectoryReader 来读取索引文档。 此方法检查需要刷新的段,并在必要时刷新它们。
- 代码 lastCommitedSegmentInfos = store.readLastCommissedSegmentsInfo(); 读取最后提交的段信息。 该信息用于确定哪些段需要刷新。
Apache Lucene: Commit
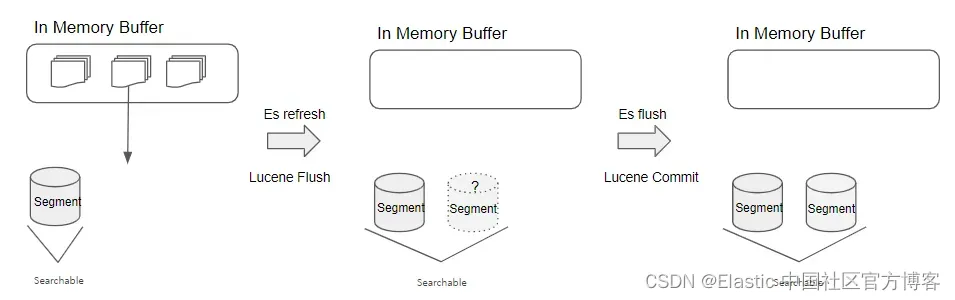
Lucene 的 flush 操作只能保证数据传输到系统的页缓存(page cache)中,但不能保证文件真正安全地写入磁盘。
因此,Lucene 会定期执行同步操作,通过 fsync 系统调用将内核系统页缓存的内容与当前写入磁盘的内容进行同步。 这个操作称为 Lucene 提交 (commit)。
什么是系统的页面缓存?
系统的页缓存是操作系统存储在内存中的数据缓存。 操作系统使用页面缓存,以便程序可以从硬盘读取数据,而不必直接访问内存。 在页面缓存中存储数据有以下好处:
- 它提高了程序性能,因为程序可以从硬盘读取数据,而无需直接访问内存。
- 它减少了磁盘读取次数,从而可以延长硬盘的使用寿命。
fsync系统调用是什么?
fsync 系统调用是用于将文件内容永久写入磁盘的系统调用。 它将文件的内容从操作系统的页面缓存复制到磁盘,然后更新磁盘上的标头(有关文件的大小、内容、格式、创建、修改日期和权限的信息)。
通过执行这些操作,Apache Lucene 确保索引文档不仅存储在操作系统的页面缓存中,而且永久存储在磁盘上,从而防止数据丢失。
更多阅读:Elasticsearch:Elasticsearch 中的 refresh 和 flush 操作指南