多线程
互斥锁
原子变量
自旋锁
C++11新特性
智能指针
首先智能指针是一个类,超过类的作用域会进行析构,所以不用担心内存泄漏。Unique_ptr(独占指针):规定一个智能指针独占一块内存资源。当两个智能指针同时指向一块内存,编译报错。 不允许拷贝构造函数和赋值操作符(将拷贝构造和复制函数声明成private或者delete),但是支持移动构造函数。
unique_ptr<string> p3 (new string ("i am jiang douya"));
unique_ptr<string> p4;
p4 = p3;//此时会报错!!
------------------------------------------
unique_ptr<int> pInt(new int(5));
// 转移所有权
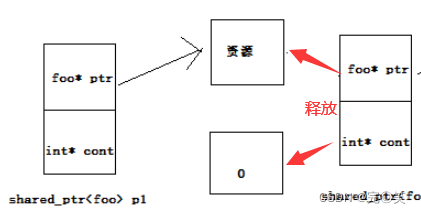
unique_ptr<int> pInt2 = std::move(pInt); shared_ptr(共享指针):多个智能指针可以指向相同对象,该对象和其相关资源会在“最后一个引用被销毁”时候释放。共享指针的实现原理:维护了一个引用技术的指针类型变量my_count,专门用于引用计数。使用拷贝构造或者赋值构造时,引用计数+1,当引用计数为0时,释放资源。
template <typename T>
class mysharedPtr {
public:
mysharedPtr(T* p = NULL);
~mysharedPtr();
mysharedPtr(const mysharedPtr<T>& other);
mysharedPtr<T>& operator=(const mysharedPtr<T>& other);
private:
T* m_ptr;
unsigned int* m_count;
}; 共享指针因存在循环引用的问题,会造成内存泄漏。 Weak_ptr(弱引用指针):weak_ptr的构造和析构不会引起引用计数的增加或减少。我们可以将其中一个改为weak_ptr指针就可以了。
class B{
public:
weak_ptr<A> psa;
~B(){ cout << "B delete\n"; }
};
--------------------------------------
#include <iostream>
#include <memory>
using namespace std;
class B;
class A{
public:
shared_ptr<B> psb;
~A(){ cout << "A delete\n"; }
};
class B{
public:
shared_ptr<A> psa;
~B(){ cout << "B delete\n"; }
};
int main(){
shared_ptr<B> pb(new B());
shared_ptr<A> pa(new A());
pb->psa = pa;
pa->psb = pb;
cout << pb.use_count() << endl;
cout << pa.use_count() << endl;
return 0;
} 腾讯 shared_ptr在多线程情况下有哪些安全隐患?
shared_ptr类所管理的对象放在堆上,可以被多个shared_ptr所访问,是一个临界资源,多个线程访问时候会出现线程安全问题。shared_ptr类里面有两个成员变量(一个是指向资源的指针,一个是资源被引用的次数),其中shared_ptr类底层对引用计数的访问会加锁和解锁,是线程安全的。比如说现在有这样的场景:A线程创建了一个shared_ptr对象指向该资源,并使引用计数为1。然后B线程开始创建了一个shared_ptr对象指向该资源,但是引用计数还没有+1,此时A线程释放资源。那B线程再执行就会出现这个野指针问题。
std::function & std::bind
std::function是一个函数包装器模板。它是一种通用的可调用对象的封装,允许将函数、函数指针、成员函数指针、lambda 表达式和其他可调用对象存储为一个单一的对象,并且可以在需要时进行调用。std::bind 主要用于参数绑定生成目标函数,一般用于生成回调函数。特别的,回调函数是成员函数的情况,会使用this指针和可能会使用占位符。
class Solution{
public:
bool compare(int x,int y){
return x > y;
}
void mysort2(vector<int>& nums){
sort(nums.begin(),nums.end(), std::bind(&Solution::compare, this, std::placeholders::_1, std::placeholders::_2));
}
};Lambda表达式
引入前提:在我们编程的过程中,我们常定义一些只会调用一次的函数,这样我们就还得老老实实写函数名、写参数,其实还挺麻烦的。但是C++ 11 引入Lambda 表达式用于定义并创建匿名的函数对象,就可以简化我们的编程工作了。
原理:编译器会把一个lambda表达式生成一个匿名类的匿名对象,并在类中重载函数调用运算符。
使用场景:如果你在实际编写过程中遇到这类情况(每个条件下都会调用相同或相似的代码块,并且代码块里面都大量使用了函数里的变量)这时候考虑两个问题:1.代码块中使用的一堆一堆的变量都用传参的方式来传递吗?如果那一堆参数里面又加了几个参数,并且代码块都要用到,是要把函数传参接口改一下,在对每一个调用的地方改一下吗?
void TestFun()
{
int a, b, c;
..... // 巴拉巴拉的一堆变量
// 代码块改成如下 使用&还是=或者既有&又有=根据自己实际情况决定
// param可以看做这个lambda中不同的变量
auto lambdaFun = [&](int param) -> void {
// 这里是可以直接调用到TestFun中的变量
// 使用a、b、c....一堆变量
}
if (条件1)
{
lambdaFun(param1);
}
if (条件2)
{
lambdaFun(param2);
}
if (条件3)
{
lambdaFun(param3);
}
}
移动语义
好处:移动语义允许对象之间的资源所有权转移,而不是进行昂贵的数据复制。这在处理大型数据结构或对象时,可以显著提高性能,避免不必要的复制操作。
使用场景:1.C++标准库中的容器支持移动语义,可以在插入、删除元素时,通过移动语义提高性能。2.C++11引入的std::unique_ptr和std::shared_ptr等智能指针,使用移动语义管理资源的所有权,确保在适当的时候正确释放资源。
STL中相关数据结构和底层结构
vector & List (国电南自)
数据结构:vector底层是一段线性空间(动态数组),List底层是双向链表。
内存分配:vector在内存分配连续的内存块,可以进行随机访问,但在插入和删除元素的时候可能需要移动其他元素,List通过结点存储指针,可以灵活的插入和删除元素。
内存占用上:vector相比List占用更少的内存空间,因为存储元素时候不需要额外的指针。
vector扩容:当 vector 的大小和容量相等(size==capacity)也就是满载时,如果再向其添加元素,那么 vector 就需要扩容。扩容的步骤->1.完全弃用现有的内存空间,重新申请更大的内存空间2.将旧内存空间中的数据,按原有顺序移动到新的内存空间中 3.最后将旧的内存空间释放。上述也就解释了为啥vector 容器在进行扩容后,与其相关迭代器可能会失效的原因。
resize和reserve区别:1reserve的作用是更改vector的容量(capacity);resize()函数改变的是容器的大小,调用resize(n)后,容器的size即为n。2reserve(n),如果n大于vector当前的容量,reserve会对vector进行扩容,其他情况都不会进行扩容;resize(n)后,容器的size即为n,比原来的变小之后,后面的会被截断,比原来的变大之后,后面的会被填充新的元素。3.reserve是容器预留空间,但在空间内不真正创建元素对象,不能引用容器内的元素;resize可以引用容器内的对象。
vector & deque
数据结构:deque底层是双端数组,可以对头端进行插入和删除操作。
vector和deque之间的区别:1.vector对头部元素的插入删除效率低,数据量越大,效率越低,当需要向序列两端频繁的添加或删除元素时,应首选 deque 容器 2.vector访问内部元素时的速度比deque快,这和二者之间的内部实现有关。在内存中deque是一段一段连续的内存空间,段与段之间不一定连续,段的首地址由数组进行维护。
map & unorderd_map
数据结构:map 使用红黑树来存储元素,因此它的元素是有序的,而 unordered_map 使用哈希表来存储元素,因此它的元素是无序的。
使用场景:红黑树的插入、删除和查找操作的时间复杂度都是 O(log n) ,哈希表的平均时间复杂度为 O(1),最坏时间复杂度为 O(n)。因此,map 在数据量较小的情况下,查询速度会比 unordered_map 更快;而当数据量很大时,unordered_map 的查询速度会比 map 更快,因为哈希表的查询效率更高,且其插入和删除操作的时间复杂度也比较稳定。
set
数据结构红黑树
红黑树(国电南自)
红黑树是一个特殊的二叉查找树,二插查找树左结点小于根结点,根结点小于右结点。二叉查找树的缺点:二叉查找树是一种非平衡树,由于插入数据的顺序,可能会导致结点都倾向于一侧,然后二叉查找树就退化成链表时间复杂度也从o(logn)变成o(n)
红黑树的特点:左根右,根叶黑,不红红(路径上不允许出现连续俩个红色),黑路同(从根结点开始到任何叶结点经历的黑结点是一样的)
红黑树的插入规则:a:先查找,确定插入位置,插入新结点 b:新结点是根--染为黑色 c:新结点非根-- 染为红色 黑叔:旋转+染色 LL形:右单旋,父换爷+染色 RR形:左单旋,父换爷+染色 LR形:左,右双旋,儿换爷+染色 RL形:右,左双旋,儿换爷+染色 红叔:染色+变新(不需要进行旋转)。
红黑树平衡性:红黑树保持了树的平衡(保证了任意一条路径不长于其他路径的二倍),确保了在最坏情况下的操作复杂度为 O(log n)。这使得在插入、删除和搜索等操作上的性能可以得到保证。
继承,多态
虚函数
虚函数的原理
C++实现虚函数的原理是虚表指针+虚函数表。单纯的含有虚函数的类创建的对象,编译器为这个对象的内存布局中会添加一个隐藏的虚函数指针的成员;子类继承父类(父类含有虚函数,但是子类没有重写父类的虚函数),子类对象的内存布局是虚函数指针(和父类的虚函数指针不一样,但是虚函数表里面存放的函数地址是相同的),父类成员,子类成员;子类继承父类(父类含有虚函数,子类重写父类的虚函数),子类对象的内存布局是虚函数指针(和父类的虚函数 指针不一样,并且虚函数表里面存放的函数地址是子类的),父类成员,子类成员。
虚函数和纯虚函数的区别(国电南自)
1.虚函数是有实现的,可以在基类中提供默认实现,派生类可以选择是否重写它。2.纯虚函数没有实现,只有声明,派生类必须提供实现,否则派生类也将成为抽象类。(作用)3.虚函数通过动态绑定在运行时决定调用哪个函数版本。4.定义纯虚函数是为了实现一个接口,起到一个规范的作用,规范继承这个类的程序必须实现这个函数。
静态绑定与动态绑定
灵感:子类对象(子类对象,父类对象)
静态类型:静态类型在编译的时候是已知的,它是变量声明时的类型。
动态类型:动态类型则是变量表示的内存中的对象的类型,动态类型直到运行时才能确定。
绑定:是将变量和函数名转换为地址的过程
静态类型绑定:编译时绑定,1.非虚函数的调用在编译的时候绑定 2.通过对象对虚函数的的调用也是静态绑定。因为上述的两种情况,对象的类型是确定不变的即我们无论如何都不可能令对象的静态类型和动态类型不一致。
动态类型绑定:运行时绑定,只有当我们通过指针或者引用调用虚函数时才能发生
虚继承
解决多继承时的命名冲突和冗余数据问题,使得在派生类中只保留一份间接基类的成员。具体的操作就是在继承方式前面加上 virtual 关键字就是虚继承
//间接基类A
class A{
protected:
int m_a;
};
//直接基类B
class B: virtual public A{ //虚继承
protected:
int m_b;
};
//直接基类C
class C: virtual public A{ //虚继承
protected:
int m_c;
};
//派生类D
class D: public B, public C{
public:
void seta(int a){ m_a = a; } //正确
void setb(int b){ m_b = b; } //正确
void setc(int c){ m_c = c; } //正确
void setd(int d){ m_d = d; } //正确
private:
int m_d;
};为啥构造函数不能是虚函数,析构函数可以是虚函数
构造函数不是虚函数:如果构造函数是虚函数,构造函数将通过虚函数表进行调用,虚函数表存储在内存空间的,所以使用虚构造函数进行实例化,综上构造函数不能是虚函数。
析构函数可以是虚函数:当基类的析构函数不是虚函数,且通过指向派生类对象的基类指针来删除派生类对象时,可能会产生内存泄漏。
深浅拷贝之间的区别?
在对象的拷贝过程中对于对象成员的拷贝方式的不同。浅拷贝:拷贝出来的对象和原对象会共享相同的内存区域。当原对象和拷贝对象同时存在时,如果其中一个对象修改了共享的内存区域,那么另一个对象也会受到影响。深拷贝:拷贝出来的对象会有自己独立的内存空间,不会和原对象共享。
C++14/17/20新特性
c++17
1.构造函数模板推导。在c++17前构造一个模板类对象,需要指明类型,c++17之后不需要指明。
pair<int, double> p(1, 2.2); // before c++17
pair p(1, 2.2); // c++17 自动推导
vector v = {1, 2, 3}; // c++172.结构化绑定(解构)数组、pair、tuple、map和自定义数据类型。
c和c++区别、概念相关面试题
右值引用
右值概念:指的则是只能出现在等号右边的变量(或表达式)。如运算操作(加减乘除,函数调用返回值等)产生的中间结果。
右值的引用:就是给右值取别名。
模板
有时两个或多个函数或类的功能是相同的,但仅仅因为数据类型不同,就要分别定义多个函数或类。通过增加模板头的方式 template<typename T>,返回数据类型,可以压缩定义多个函数或类。
函数指针和指针函数
函数指针:函数指针就是指向函数的指针变量。每一个函数都有一个入口地址,该入口地址就是函数指针所指向的地址。函数指针的应用场景是回调。我们调用别人提供的 API函数,称为Call;如果别人的库里面调用我们的函数,就叫Callback。
指针函数:指针函数是指带指针的函数,即本质是一个函数,函数返回类型是某一类型的指针。
emplace_back & push_back
push_back() 在向容器尾部添加元素时,会先创建这个元素(临时对象),然后再将这个元素拷贝或移动到容器中(若是拷贝的话,还需要在结束后销毁之前创建的这个元素);
emplace_back() 则是直接在容器尾部创建这个元素,省去了拷贝或移动元素的过程。
注意:如果直接添加对象,那么都只会发生拷贝构造或者移动构造
初始化列表
表现:使用初始化列表显式的初始化类的成员,而没使用初始化列表的构造函数是对类的成员赋值,并没有进行显式的初始化(以下简称这种方式为赋值 == 默认构造+赋值)。
必须使用初始化列表的场景:1.成员类型是没有默认构造函数的类。若没有提供显示初始化式,则编译器隐式使用成员类型的默认构造函数,若类没有默认构造函数,则编译器尝试使用默认构造函数将会失败。2.const 成员或引用类型的成员。因为 const 对象或引用类型只能初始化,不能对他们赋值。
重写,重载的区别?
表现上:重写是派生类重定义基类的虚函数,既会覆盖基类的虚函数(多态)。重载是函数名相同,参数列表不同(参数类型、参数顺序),不能用返回值区分。
作用效果:重写是父类指针和引用指向子类的实例时,通过父类指针或引用可以调用子类的函数,这就是C++的多态。重载是编译器根据函数不同的参数列表,将函数与函数调用进行早绑定。
特殊情况:若某一重载版本的函数前面有virtual关键字修饰,则表示它是虚函数,但它也是重载的一个版本。若派生类重写函数是一个重载版本,那么基类的其他同名重载函数将在子类中隐藏。
C语言中typdef struct node{} & struct node{}
C语言:若struct node{}这样来定义结构体的话。在申请node 的变量时,需要struct node n;若用typedef,可以这样写typedef struct node{}NODE,在申请变量时就可以这样写NODE n;
区别就在于使用时,是否可以省去struct这个关键字。
C++:在c++中可以不需要typedef就可以Student stu2是因为在c++中struct也是一种类,所以可以直接使用Student stu2来定义一个Student的对象,但c中去不可以。
迭代器
概念:迭代器是一个类,迭代器相当于容器和操纵容器的算法之间的中介。通过迭代器可以读取他指向的元素。它模拟了指针的一些功能(底层封装了指针),通过重载了指针的一些操作符,如-->、*、++、--等。
分类:正向迭代器、常量正向迭代器,反向迭代器,反向常量迭代器。
注意:vector在删除元素时,会出现迭代器失效的问题,所以在使用erase时要返回下一个元素的迭代器。
自己迷惑的点
转义字符
转义字符是一种特殊的字符,它们以反斜杠线(\)开头,后跟一个或多个字符,用于表示一些在普通文本中无法直接表示的字符或控制字符。这些转义字符允许您在字符串中包含诸如换行符、制表符、引号等特殊字符,或者用于表示不可见字符和其他特殊目的。
\r:回车
\n: 换行
\0:空字符
空格和空字符
空格用于可视排版,而空字符用于在内存中表示字符串的结束。
静态成员变量和函数
1.静态成员变量的定义和初始化必须在类的外部
2.定义并初始化一个静态成员