9月25日,阿里云开源通义千问140亿参数模型Qwen-14B及其对话模型Qwen-14B-Chat,免费可商用。
 立马就到了GitHub去fork。
立马就到了GitHub去fork。
GitHub:
GitHub - QwenLM/Qwen: The official repo of Qwen (通义千问) chat & pretrained large language model proposed by Alibaba Cloud.
官方的技术资料也下载了,看这里==>https://qianwen-res.oss-cn-beijing.aliyuncs.com/QWEN_TECHNICAL_REPORT.pdf
这个模型的表现怎么样?
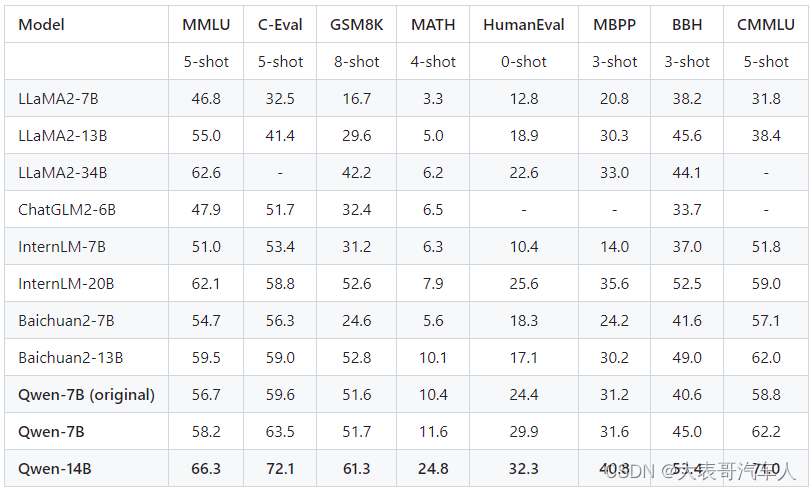
Qwen-14B和Qwen-7B模型相比同规模模型表现更好,其能力包括自然语言理解、知识、数学计算和推理、代码生成、逻辑推理等。虽然Qwen-14B仍与GPT-3.5和GPT-4有差距,但表现不俗。实验结果见表格,更多细节请查看技术备忘录:https://qianwen-res.oss-cn-beijing.aliyuncs.com/QWEN_TECHNICAL_REPORT.pdf。

学习或调试大模型需要【安装哪些软件】?
- python 3.8及以上版本
- pytorch 1.12及以上版本,推荐2.0及以上版本
- 建议使用CUDA 11.4及以上(GPU用户、flash-attention用户等需考虑此选项)
【安装pytorch】 传送门==>pytorch 下载安装全流程详细教程_pytorch官网下载教程_Deep Learning小舟的博客-CSDN博客
该装的都装好了?好的,上车吧!
快!快告诉我【如何使用】大模型!
提供简单的示例来说明如何利用🤖 ModelScope和🤗 Transformers快速使用Qwen-7B和Qwen-7B-Chat。
ModelScope是一个开源平台,允许用户在生产中可视化、监视和分析机器学习模型。
看这里==>https://github.com/modelscope/modelscope
看看都需要安装哪些依赖库。在工程中有一个文件叫做requirements.txt,打开

transformers
Transformers提供API和工具,方便下载和训练最先进的预训练模型。使用预训练模型可以降低计算成本、碳足迹,并节省训练模型所需的时间和资源。这些模型支持不同类型的常见任务,例如:
📝 自然语言处理:文本分类、命名实体识别、问答、语言建模、摘要、翻译、多项选择和文本生成。
🖼️ 计算机视觉:图像分类、目标检测和分割。
🗣️ 音频:自动语音识别和音频分类。
🐙 多模态:表格问答、光学字符识别、从扫描文档中提取信息、视频分类和视觉问答。
传送门==>https://huggingface.co/docs/transformers/index
accelerate
Accelerate是一个库,通过添加仅四行代码,使得相同的PyTorch代码可以在任何分布式配置下运行!简而言之,实现规模化的训练和推理变得简单、高效和适应性强。
传送门==>https://huggingface.co/docs/accelerate/index
tiktoken
tiktoken是一个快速的BPE分词器,可与OpenAI的模型配合使用。
传送门==>https://github.com/openai/tiktoken
einops
灵活强大的张量操作,使代码易读且可靠。支持numpy、pytorch、tensorflow、jax等多种框架。
传送门==>einops · PyPI
transformers-stream-generator
这是一种基于Huggingface/Transformers的文本生成方法,它返回一个生成器,在推理期间实时流出每个标记。
传送门==>transformers-stream-generator · PyPI
scipy
SciPy提供了用于优化、积分、插值、特征值问题、代数方程、微分方程、统计学和许多其他类别问题的算法。
传送门==>SciPy
【安装以上依赖库】,打开cmd,cd到工程目录路径下,输入如下命令行代码
pip install -r requirements.txt