文章目录
- 前言
- 一、第一部分:实现一个顺序的web代理
- HTTP/1.0 GET请求
- 请求标头
- 端口号
- 二、第二部分:处理多个并发请求
- 三、第三部分:缓存web对象
- 最大缓存大小
- 最大对象大小
- 驱逐政策
- 同步
- 总结
前言
一个本硕双非的小菜鸡,备战24年秋招。刚刚看完CSAPP,真是一本神书啊!遂尝试将它的Lab实现,并记录期间心酸历程。
代码下载
官方网站:CSAPP官方网站
以下是官方文档翻译:
代理实验室:编写一个高速缓存的Web代理
在这个实验室中,您将编写一个简单的可缓存web对象的HTTP代理。在实验室的第一部分,您将设置代理来接受传入的连接、读取和解析请求,将请求转发到web服务器,读取服务器的响应,并将这些响应转发到相应的客户端。这第一部分将涉及到学习基本的HTTP操作,以及如何使用套接字来编写通过网络连接进行通信的程序。在第二部分中,您将升级代理以处理多个并发连接。这将向您介绍处理并发性,这是一个关键的系统概念。在第三部分,也是最后一部分中,您将使用最近访问的web内容的简单主存缓存向代理添加缓存。
一、第一部分:实现一个顺序的web代理
实现一个连续的web代理
第一步是实现一个基本的处理HTTP/1.0 GET请求的顺序代理。其他请求类型,如POST,严格上是可选的。
启动时,代理应该侦听将在命令行上指定编号的端口上的传入连接。一旦建立了连接,您的代理应该阅读来自客户端的整个请求并解析该请求。它应该确定客户端是否发送了有效的HTTP请求;如果是,它可以建立自己到适当的web服务器的连接,然后请求客户端指定的对象。最后,您的代理应该读取服务器的响应并将其转发给客户端。
HTTP/1.0 GET请求
当最终用户在web浏览器的地址栏中输入像http://www.cmu.edu/hub/index.html这样的URL时,浏览器将向代理发送HTTP请求,该请求以可能类似于的行开始:
GET http://www.cmu.edu/hub/index.html HTTP/1.1
在这种情况下,代理应该将请求解析为以下字段:主机名www.cmu.edu;路径或查询以及后面的所有内容/hub/index.html。这样,代理可以确定它应该打开www.cmu.edu的连接,并发送它自己的HTTP请求:
GET /hub/index.html HTTP/1.0
请注意,HTTP请求中的所有行都以回车位“\r”结尾,后面是换行符“\n”。同样重要的是,每个HTTP请求都由一个空行终止:“\r\n”。
在上面的例子中,您应该注意到,web浏览器的请求行以HTTP/1.1结束,而代理的请求行以HTTP/1.0结束。现代的web浏览器将生成HTTP/1.1请求,但是您的代理应该处理它们并将它们转发为HTTP/1.0请求。
重要的是要考虑到HTTP请求,即使是HTTP/1.0 GET请求的子集,也可能非常复杂。本教科书描述了HTTP事务的某些细节,但您应该参考RFC 1945以获得完整的HTTP/1.0规范。理想情况下,根据RFC 1945的相关部分,您的HTTP请求解析器将完全健壮,除了一个细节:虽然规范允许多行请求字段,但您的代理不需要正确处理它们。当然,您的代理不应该因为格式错误的请求而提前中止。
人话:从类似于GET http://www.cmu.edu/hub/index.html HTTP/1.1读取主机名、端口、路径等信息,然后与服务器建立连接,并接受写回客户端。
可以参考书中671的TINY Web服务器
HTTP请求具体可参考知乎大佬李志华的图,写的是真清楚
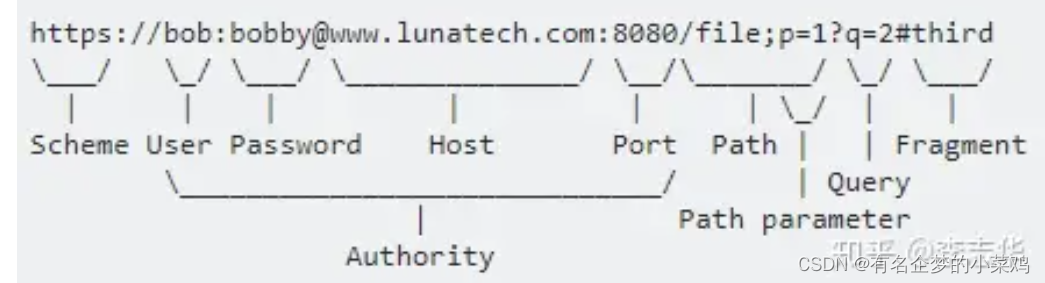
逻辑就是先读取,再解析出关键信息,最后拼装成新的请求
读取用到的是Rio_readinitb函数和Rio_readlineb函数。
解析需要设置新函数,可参考书中parse_uri函数,注释写的很清楚。
拼装放到请求标头部分。
代码:
//将URI解析为一个主机名、文件路径和一个端口号
void parse_uri(char* uri, char* hostname, char* filepath, char* port) {
/*URL输入为 http://www.cmu.edu:80/hub/index.html*/
/*拿到http://这一段后面的路径*/
char* ptr = strstr(uri, "//");
/*等于空是相对uri,因为相对uri没有http://,那么取/*/
if (ptr == NULL) {
char* temp = strstr(uri, "/");
if (temp != NULL) {
strcpy(filepath, temp); //把文件路径拿出
strcpy(port, "80"); //默认端口号80
return;
}
//uri默认协议http
ptr = uri;
}
else {
ptr += 2; //这是绝对uri,取文件路径开头,我个人觉得是把头部那个//跳过去
}
char* pos = strstr(ptr, ":"); //取端口号
if (pos != NULL) {
int num;
char* temp = strstr(pos, "/"); //拿path文件路径
if (temp != NULL) {
sscanf(pos + 1, "%d%s", &num, filepath); //加1跳/,num是端口号的数值,path是文件路径
}
else {
//没有path
sscanf(pos + 1, " %d", &num);
}
sprintf(port, "%d", num);
*pos = '\0'; //加结束符
}
else {
char* temp = strstr(ptr, "/"); //拿path文件路径
if (temp != NULL) {
strcpy(filepath, temp);//把文件路径拿出
*temp = '\0'; //加结束符
}
strcpy(port, "80"); //默认端口号80
}
strcpy(hostname, ptr);
return;
}
请求标头
本实验室的重要请求头是主机、用户代理、连接和代理连接头:
- 始终发送一个主机标头。虽然这种行为在技术上不受HTTP/1.0规范的认可,但有必要从某些Web服务器,特别是那些服务器使用虚拟主机的响应。
主机标头描述了结束服务器的主机名。例如,要访问http://www.cmu.edu/hub/index.html,您的代理将发送以下标题:
Host: www.cmu.edu
web浏览器可能会将它们自己的主机标头附加到它们的HTTP请求中。如果是这种情况,那么您的代理应该使用与浏览器相同的主机头。 - 您可以选择始终发送以下用户代理标头:
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3)
Gecko/20120305 Firefox/10.0.3
报头提供在两个单独的行上,因为它不适合在写入程序中作为一行发送,但是您的代理应该将报头作为一行发送。
User-Agent标头标识客户端(根据操作系统和浏览器等参数),而web服务器通常使用标识信息来操作它们所服务的内容。发送这个特定的用户代理:字符串可能会在内容和多样性方面改善你在简单的telnet风格的测试中得到的材料。 - 始终发送以下Connection标头:
Connection: close - 始终发送以下Proxy-Connection标头:
Proxy-Connection: close
Connection和Proxy-Connectio标头用于指定在第一次请求/响应交换完成后,连接是否将保持活动状态。让您的代理为每个请求打开一个新的连接是完全可以接受的(也是建议的)。指定close为这些标头的值,将提醒web服务器,您的代理打算在第一次请求/响应交换后关闭连接。
为方便起见,所描述的User-Agent头的值作为proxy.c中的字符串常数提供给您。
最后,如果浏览器作为HTTP请求的一部分发送任何其他请求头,那么您的代理应该不变地转发它们。
请求报头这里需要注意,在proxy.c文件的开头已经写好了三个。这就是客户端发送的三个特殊的请求头。
代码:
static const char *user_agent_hdr = "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3\r\n";
static const char *conn_hdr = "Connection: close\r\n";
static const char *proxy_conn_hdr = "Proxy-Connection: close\r\n";
然后构造新的发送到终端服务器请求,注释写的很清楚。
/*构造新的发送到终端服务器请求*/
void build_request(rio_t *rio, char *newrequest, char* method, char* hostname, char* filepath, char* port) {
sprintf(newrequest, "%s %s HTTP/1.0\r\n", method, filepath);
char buf[MAXLINE];
/*读取请求报文*/
while (Rio_readlineb(rio, buf, MAXLINE) > 0) {
if (!strcmp(buf, "\r\n")) break; //读到了空行(每个HTTP请求都由一个空行终止:“\r\n”。),表示请求头结束
/*四个特殊的请求头*/
if (strstr(buf, "Host:") != NULL) continue; //Host自行设置
if (strstr(buf, "User-Agent:") != NULL) continue; //Host自行设置
if (strstr(buf, "Connection:") != NULL) continue; //Connection自行设置
if (strstr(buf, "Proxy-Connection:") != NULL) continue; //Proxy-Connection自行设置
sprintf(newrequest, "%s%s", newrequest, buf); // 其他请求头直接原封不动加入请求中
}
// 添加上请求的必要信息
sprintf(newrequest, "%sHost: %s:%s\r\n", newrequest, hostname, port);
sprintf(newrequest, "%s%s", newrequest, user_agent_hdr);
sprintf(newrequest, "%s%s", newrequest, conn_hdr);
sprintf(newrequest, "%s%s", newrequest, proxy_conn_hdr);
sprintf(newrequest, "%s\r\n", newrequest);
}
端口号
这个实验室有两种重要的端口号类型: HTTP请求端口和代理的侦听端口。
HTTP请求端口是HTTP请求的URL中的一个可选字段。也就是说,URL的形式可能是http://www.cmu.edu:8080/hub/index.html,在这种情况下,您的代理应该连接到端口8080上的主机www.cmu.edu,而不是默认的HTTP端口,即端口80。无论URL中是否包含该端口号,您的代理都必须正常工作。
侦听端口是代理应该用来侦听传入连接的端口。代理应该接受一个指定代理的监听端口号的命令行参数。例如,使用以下命令,代理应该监听端口15213上的连接:
linux> ./proxy 15213
您可以选择任何非特权侦听端口(大于1024和小于65536),只要它不被其他进程使用。由于每个代理必须使用一个唯一的监听端口,并且许多人将同时在每台机器上工作,因此提供了脚本port-for-user.pl来帮助您选择自己的个人端口号。使用它可以根据您的用户ID生成端口号:
linux> ./port-for-user.pl droh
droh: 45806
port-for-user.pl返回的端口p总是偶数。所以,如果你需要一个额外的端口号,比如对于小服务器,你可以安全地使用端口p和p + 1。
请不要选择你自己的随机端口。如果您这样做了,您就有干扰其他用户的风险。
端口号这里其实之前已经写过了,在parse_uri函数中,这里放主函数和处理HTTP事务的doit函数,注释写的很清楚。
doit函数代码:
/*处理HTTP事务*/
void doit(int fd) {
int serverfd;
int n;
char buf[MAXLINE];//定义内存位置
char version[MAXLINE];
char method[MAXLINE];//客户端请求方法
char hostname[MAXLINE];
char filepath[MAXLINE];
char port[MAXLINE];
char newrequest[MAXLINE];
char uri[MAXLINE];
rio_t rio, serverrio;
/*读和解析请求行*/
Rio_readinitb(&rio, fd); //初始化一个缓冲区,并把一个文件描述符与缓冲区联系起来
/*从文件rio读出下一个文本行,将它复制到内存位置buf,最多读MAXLINE-1*/
//Rio_readlineb(&rio, buf, MAXLINE);//包装函数:从内部读缓冲区复制一个文本行,当缓冲区变空时,会自动调用read重新填满缓冲区
if (!Rio_readlineb(&rio, buf, MAXLINE)) {
return;
}
printf("Request headers:\n");
printf("%s", buf);
sscanf(buf, "%s %s %s", method, uri, version);
/*只使用Get方法,如果客户端请求其他方法,发送一个错误信息并返回主程序*/
if (strcasecmp(method, "GET")) {
printf("Not implemented");
return;
}
/*读并且忽略任何请求报头*/
/*从GET请求中解析URI*/
parse_uri(uri, hostname, filepath, port);
/*构造新的发送到终端服务器请求*/
build_request(&rio, newrequest, method, hostname, filepath, port);
/*与服务端建立连接*/
serverfd = Open_clientfd(hostname, port); //客户端调用open_clientfd建立与服务器的连接,该服务器运行着在主机hostname上,并在端口号port上监听连接请求。返回一个打开的套接字描述符
if (serverfd < 0) {
fprintf(stderr, "connect to real server err"); //输出标准错误
return;
}
/*发送请求报文*/
Rio_readinitb(&serverrio, serverfd);
Rio_writen(serverfd, newrequest, strlen(newrequest)); //从位置newrequest传送strlen(newrequest)个字节到描述符serverfd
/*接受并转发给客户端*/
while ((n = Rio_readlineb(&serverrio, buf, MAXLINE)) != 0) {
printf("get %d bytes from server\n", n);
Rio_writen(fd, buf, n); //从位置buf传送n个字节到描述符fd
}
Close(serverfd); //关闭文件描述符
}
主函数代码:
int main(int argc, char **argv)
{
int listenfd, connfd;
socklen_t clientlen;
char hostname[MAXLINE], port[MAXLINE];
struct sockaddr_storage clientaddr;
if (argc != 2) {
fprintf(stderr, "usage :%s <port> \n", argv[0]);
exit(1);
}
signal(SIGPIPE, SIG_IGN); //防止收到SIGPIPE信号而过早终止
//打开监听端口
listenfd = Open_listenfd(argv[1]);
// 死循环监听端口,如果有请求进入就提供服务。
while (1) {
clientlen = sizeof(clientaddr);
connfd = Accept(listenfd, (SA*)&clientaddr, &clientlen);
Getnameinfo((SA*)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);
printf("Accepted connection from (%s, %s)\n", hostname, port);
doit(connfd); // 提供服务的函数
Close(connfd); //关闭文件描述符
}
printf("%s", user_agent_hdr);
return 0;
}
注意,应记得写函数定义和加入csapp.h
#include <stdio.h>
#include "csapp.h"
/* Recommended max cache and object sizes */
/*推荐最大缓存和对象大小*/
#define MAX_CACHE_SIZE 1049000
#define MAX_OBJECT_SIZE 102400
/* You won't lose style points for including this long line in your code */
/*你不会因为在你的代码中包含这长行而失去样式点*/
static const char *user_agent_hdr = "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3\r\n";
static const char* conn_hdr = "Connection: close\r\n";
static const char* proxy_conn_hdr = "Proxy-Connection: close\r\n";
void doit(int fd);
void parse_uri(char* uri, char* hostname, char* filepath, char* port);
void build_reqheader(rio_t* rio, char* newrequest, char* method, char* hostname, char* filepath, char* port);
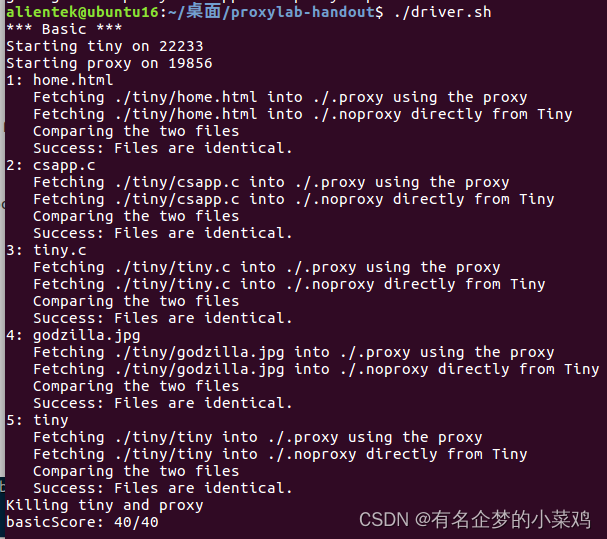
先make编译,然后执行./driver.sh,成功了
二、第二部分:处理多个并发请求
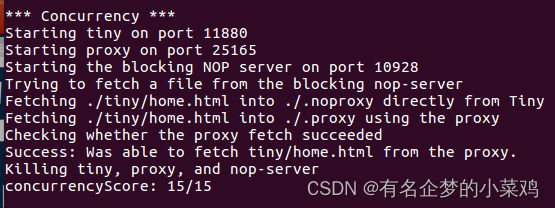
一旦您有了一个工作的顺序代理,您应该修改它以同时处理多个请求。实现并发服务器的最简单的方法是生成一个新的线程来处理每个新的连接请求。其他的设计也是可能的,如教科书第12.5.5节中描述的预线程服务器。
- 请注意,线程应该以分离模式运行,以避免内存泄漏。
- CS: APP3e教科书中描述的 open clientfd端和open listenfd功能是基于现代和协议独立的获取信息功能,因此是线程安全的。
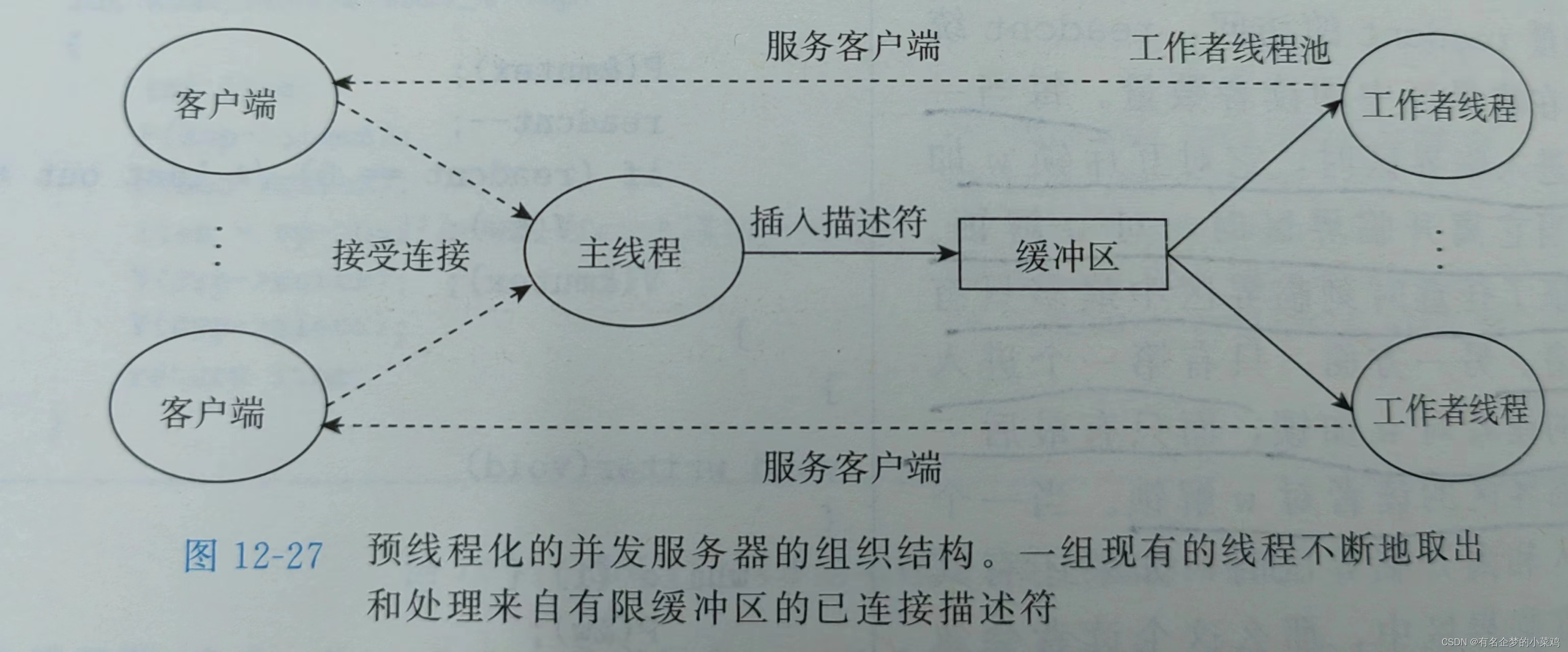
采用多线程方式实现处理多个并发请求,主线程只负责监听窗口,当有一个客户端连接的时候,创建一个分线程去为这个客户端提供服务。但是这种方法的缺点是我们为每一个新客户端创建一个新线程导致不小的代价。可以使用如图所示的生产者-消费者模型降低这种开销。
服务区是由一个主线程和一组工作者线程构成的,主线程不断接受来自客户端的连接请求,并将得到的连接描述符放在一个有限缓冲区中,每个工作者线程反复地从共享缓冲区中取出描述符为客户端服务,然后等待下一个描述符。
可以仿照709页代码
代码:
#include "sbuf.h"
#define NTHREADS 4 // 最大线程数
#define SBUFSIZE 16 // 缓冲区大小
sbuf_t sbuf; //连接描述符缓冲区
在main中添加
int main(int argc, char **argv)
{
int listenfd, connfd;
socklen_t clientlen;
char hostname[MAXLINE], port[MAXLINE];
struct sockaddr_storage clientaddr;
pthread_t tid;
if (argc != 2) {
fprintf(stderr, "usage :%s <port> \n", argv[0]);
exit(1);
}
signal(SIGPIPE, SIG_IGN); //防止收到SIGPIPE信号而过早终止
//打开监听端口
listenfd = Open_listenfd(argv[1]);
sbuf_init(&sbuf, SBUFSIZE); //创建一个有fd个槽的空的、有界的、共享的FIFO缓冲区。
/*创建工作线程*/
for (int i = 0; i < NTHREADS; i++) {
Pthread_create(&tid, NULL, thread, NULL);
}
// 死循环监听端口,如果有请求进入就提供服务。
while (1) {
clientlen = sizeof(clientaddr);
connfd = Accept(listenfd, (SA*)&clientaddr, &clientlen);
Getnameinfo((SA*)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);
printf("Accepted connection from (%s, %s)\n", hostname, port);
sbuf_insert(&sbuf, connfd); //将信号缓冲区写入文件描述符
//doit(connfd); // 提供服务的函数
//Close(connfd); //关闭文件描述符
}
//printf("%s", user_agent_hdr);
return 0;
}
记得添加thread函数:
void* thread(void* vargp) {
Pthread_detach(Pthread_self());
while (1) {
int connfd = sbuf_remove(&sbuf);
doit(connfd);
Close(connfd);
}
}
这里用到了一个sbuf.h/c库,可以去官网下载,也可以复制创建自己的。官网h 官网C
sbuf.h
#ifndef __SBUF_H__
#define __SBUF_H__
#include "csapp.h"
/* $begin sbuft */
typedef struct {
int *buf; /* Buffer array */
int n; /* Maximum number of slots */
int front; /* buf[(front+1)%n] is first item */
int rear; /* buf[rear%n] is last item */
sem_t mutex; /* Protects accesses to buf */
sem_t slots; /* Counts available slots */
sem_t items; /* Counts available items */
} sbuf_t;
/* $end sbuft */
void sbuf_init(sbuf_t *sp, int n);
void sbuf_deinit(sbuf_t *sp);
void sbuf_insert(sbuf_t *sp, int item);
int sbuf_remove(sbuf_t *sp);
#endif /* __SBUF_H__ */
sbuf.c
/* $begin sbufc */
#include "csapp.h"
#include "sbuf.h"
/* Create an empty, bounded, shared FIFO buffer with n slots */
/* $begin sbuf_init */
void sbuf_init(sbuf_t *sp, int n)
{
sp->buf = Calloc(n, sizeof(int));
sp->n = n; /* Buffer holds max of n items */
sp->front = sp->rear = 0; /* Empty buffer iff front == rear */
Sem_init(&sp->mutex, 0, 1); /* Binary semaphore for locking */
Sem_init(&sp->slots, 0, n); /* Initially, buf has n empty slots */
Sem_init(&sp->items, 0, 0); /* Initially, buf has zero data items */
}
/* $end sbuf_init */
/* Clean up buffer sp */
/* $begin sbuf_deinit */
void sbuf_deinit(sbuf_t *sp)
{
Free(sp->buf);
}
/* $end sbuf_deinit */
/* Insert item onto the rear of shared buffer sp */
/* $begin sbuf_insert */
void sbuf_insert(sbuf_t *sp, int item)
{
P(&sp->slots); /* Wait for available slot */
P(&sp->mutex); /* Lock the buffer */
sp->buf[(++sp->rear)%(sp->n)] = item; /* Insert the item */
V(&sp->mutex); /* Unlock the buffer */
V(&sp->items); /* Announce available item */
}
/* $end sbuf_insert */
/* Remove and return the first item from buffer sp */
/* $begin sbuf_remove */
int sbuf_remove(sbuf_t *sp)
{
int item;
P(&sp->items); /* Wait for available item */
P(&sp->mutex); /* Lock the buffer */
item = sp->buf[(++sp->front)%(sp->n)]; /* Remove the item */
V(&sp->mutex); /* Unlock the buffer */
V(&sp->slots); /* Announce available slot */
return item;
}
/* $end sbuf_remove */
/* $end sbufc */
记得更改makefile,把sbuf添加进去。
# Makefile for Proxy Lab
#
# You may modify this file any way you like (except for the handin
# rule). You instructor will type "make" on your specific Makefile to
# build your proxy from sources.
CC = gcc
CFLAGS = -g -Wall
LDFLAGS = -lpthread
all: proxy
csapp.o: csapp.c csapp.h
$(CC) $(CFLAGS) -c csapp.c
proxy.o: proxy.c csapp.h
$(CC) $(CFLAGS) -c proxy.c
sbuf.o: sbuf.c sbuf.h
$(CC) $(CFLAGS) -c sbuf.c
proxy: proxy.o csapp.o sbuf.o
$(CC) $(CFLAGS) proxy.o csapp.o sbuf.o -o proxy $(LDFLAGS)
# Creates a tarball in ../proxylab-handin.tar that you can then
# hand in. DO NOT MODIFY THIS!
handin:
(make clean; cd ..; tar cvf $(USER)-proxylab-handin.tar proxylab-handout --exclude tiny --exclude nop-server.py --exclude proxy --exclude driver.sh --exclude port-for-user.pl --exclude free-port.sh --exclude ".*")
clean:
rm -f *~ *.o proxy core *.tar *.zip *.gzip *.bzip *.gz
不难:
三、第三部分:缓存web对象
在实验室的最后一部分,您将向代理添加一个缓存,该代理将最近使用的Web对象存储在内存中。HTTP实际上定义了一个相当复杂的模型,通过这个模型,web服务器可以提供关于它们所服务的对象应该如何缓存的说明,并且客户端可以指定如何代表它们使用缓存。但是,您的代理将采用一种简化的方法。
当您的代理从服务器接收到一个web对象时,它应该在将该对象传输到客户端时将其缓存到内存中。如果另一个客户端从同一台服务器请求相同的对象,则代理不需要重新连接到服务器;它可以简单地重新发送缓存的对象。
显然,如果您的代理要缓存所请求的每个对象,那么它将需要无限数量的内存。此外,由于一些web对象比其他对象大,可能一个巨大的对象会消耗整个缓存,从而阻止其他对象被缓存。为了避免这些问题,您的代理应该同时具有最大缓存大小和最大缓存对象大小。
最大缓存大小
代理的整个缓存应具有以下最大大小:
MAX_CACHE_SIZE = 1 MiB
在计算其缓存的大小时,代理必须只计算用于存储实际web对象的字节;应该忽略任何无关的字节,包括元数据。
首先设置好推荐最大缓存和对象大小,官方已经在文件中帮我们写好了。我们要做的是设置好cache
/*推荐最大缓存和对象大小*/
#define MAX_CACHE_SIZE 1049000
/*cache中每一行*/
typedef struct {
char buf[MAX_OBJECT_SIZE];
char url[MAXLINE];
int size; //缓存块大小
int valid;//当前行是否有效1或0
int timestamp; //时间戳
} cacheLine;
/*cache*/
typedef struct {
cacheLine line[CACHELINE];
int readcnt, currentTime;
sem_t mutex, writer;
} cache_t;
cache_t cache;
最大对象大小
代理应只缓存不超过以下最大大小的web对象:
MAX_OBJECT_SIZE = 100 KiB
为了方便起见,这两个大小限制都是作为proxy.c中的宏提供的。
实现正确缓存的最简单方法是为每个活动连接分配一个缓冲区,并在从服务器接收到的数据时积累数据。如果缓冲区的大小曾经超过了最大的对象大小,则可以丢弃该缓冲区。如果在超过最大对象大小之前读取了web服务器的整个响应,则可以缓存该对象。使用此方案,您的代理将用于web对象的最大数据量如下,其中T是活动连接的最大数量:
MAX_CACHE_SIZE + T * MAX_OBJECT_SIZE
官方已经在文件中帮我们写好了
#define MAX_OBJECT_SIZE 102400
写好cache初始函数
void cache_init()
{
cache.readcnt = 0;
cache.currentTime = 0;
Sem_init(&cache.mutex, 0, 1);
Sem_init(&cache.writer, 0, 1);
for (int i = 0; i < CACHELINE; i++) {
cache.line[i].valid = 0;
cache.line[i].timestamp = 0;
cache.line[i].size = 0;
}
}
/*对cache具体行赋值*/
void cacheWrite(char* buf, char* url, int size)
{
if (size > MAX_OBJECT_SIZE) return;
int idx = -1;
for (int i = 0; i < CACHELINE; i++) {
if (cache.line[i].valid == 0) {
idx = i;
break;
}
}
if (idx == -1) {
//LRU
int mxTime = 0;
for (int i = 0; i < CACHELINE; i++) {
if (cache.line[i].valid && cache.currentTime - cache.line[i].timestamp > mxTime) {
mxTime = cache.currentTime - cache.line[i].timestamp;
idx = i;
}
}
}
P(&cache.writer);
strcpy(cache.line[idx].buf, buf);
strcpy(cache.line[idx].url, url);
cache.line[idx].size = size;
cache.line[idx].timestamp = ++cache.currentTime;
cache.line[idx].valid = 1;
V(&cache.writer);
}
驱逐政策
代理的缓存应使用接近最近使用最少的(LRU)驱逐策略的驱逐策略。它不一定是严格的LRU,但它应该是相当接近的东西。注意,读取对象和写入对象都视为使用该对象。
/*成功时返回缓存中的idx,出错时返回-1*/
int getCacheIndex(char* url)
{
int ret = -1;
for (int i = 0; i < CACHELINE; i++) {
if (cache.line[i].valid && !strcmp(cache.line[i].url, url)) {
ret = i;
}
}
return ret;
}
同步
对缓存的访问必须是线程安全的,并且确保缓存访问不受竞争条件可能是实验室这一部分更有趣的方面。事实上,有一个特殊的要求,即多个线程必须能够同时从缓存中读取。当然,一次只允许一个线程写入缓存,但是阅读器必须不存在这种限制。
因此,使用一个大的独占锁来保护对缓存的访问并不是一个可以接受的解决方案。您可能希望探索一些选项,如分区缓存、使用Psthewe读-写器锁或使用信号量来实现自己的读-写器解决方案。在任何一种情况下,您都不必执行严格的LRU驱逐策略,这将使您在支持多个读者方面提供一些灵活性。
最后要在doit函数里调用我们写好的cache函数
在头这里加入
char uriBackup[MAXLINE];
然后在这里加入strcpy(uriBackup, uri);
sscanf(buf, "%s %s %s", method, uri, version);
strcpy(uriBackup, uri);
/*只使用Get方法,如果客户端请求其他方法,发送一个错误信息并返回主程序*/
if (strcasecmp(method, "GET")) {
printf("Not implemented");
return;
}
紧接着就是调用
int idx = getCacheIndex(uri);
if (idx != -1) {
P(&cache.mutex);
cache.readcnt++;
if (cache.readcnt == 1)
P(&cache.writer);
V(&cache.mutex);
Rio_writen(fd, cache.line[idx].buf, cache.line[idx].size);
P(&cache.mutex);
cache.readcnt--;
if (cache.readcnt == 0)
V(&cache.writer);
V(&cache.mutex);
printf("Cached\n");
return;
}
然后在接受并转发给客户端中也有更改,注意Rio_writen传入的第二个参数改成newrequest了。
int cacheSize = 0;
memset(buf, 0, sizeof buf);
/*接受并转发给客户端*/
while ((n = Rio_readlineb(&serverrio, newrequest, MAXLINE)) != 0) {
printf("get %d bytes from server\n", n);
Rio_writen(fd, newrequest, n); //从位置buf传送n个字节到描述符fd
strcat(buf, newrequest);
cacheSize += n;
}
cacheWrite(buf, uriBackup, cacheSize);
这是doit更改后的总代码
/*处理HTTP事务*/
void doit(int fd) {
int serverfd;
int n;
char buf[MAXLINE];//定义内存位置
char version[MAXLINE];
char method[MAXLINE];//客户端请求方法
char hostname[MAXLINE];
char filepath[MAXLINE];
char port[MAXLINE];
char newrequest[MAXLINE];
char uri[MAXLINE];
char uriBackup[MAXLINE];
rio_t rio, serverrio;
/*读和解析请求行*/
Rio_readinitb(&rio, fd); //初始化一个缓冲区,并把一个文件描述符与缓冲区联系起来
/*从文件rio读出下一个文本行,将它复制到内存位置buf,最多读MAXLINE-1*/
//Rio_readlineb(&rio, buf, MAXLINE);//包装函数:从内部读缓冲区复制一个文本行,当缓冲区变空时,会自动调用read重新填满缓冲区
if (!Rio_readlineb(&rio, buf, MAXLINE)) {
return;
}
printf("Request headers:\n");
printf("%s", buf);
sscanf(buf, "%s %s %s", method, uri, version);
strcpy(uriBackup, uri);
/*只使用Get方法,如果客户端请求其他方法,发送一个错误信息并返回主程序*/
if (strcasecmp(method, "GET")) {
printf("Not implemented");
return;
}
int idx = getCacheIndex(uri);
if (idx != -1) {
P(&cache.mutex);
cache.readcnt++;
if (cache.readcnt == 1)
P(&cache.writer);
V(&cache.mutex);
Rio_writen(fd, cache.line[idx].buf, cache.line[idx].size);
P(&cache.mutex);
cache.readcnt--;
if (cache.readcnt == 0)
V(&cache.writer);
V(&cache.mutex);
printf("Cached\n");
return;
}
/*读并且忽略任何请求报头*/
/*从GET请求中解析URI*/
parse_uri(uri, hostname, filepath, port);
/*构造新的发送到终端服务器请求*/
build_request(&rio, newrequest, method, hostname, filepath, port);
/*与服务端建立连接*/
serverfd = Open_clientfd(hostname, port); //客户端调用open_clientfd建立与服务器的连接,该服务器运行着在主机hostname上,并在端口号port上监听连接请求。返回一个打开的套接字描述符
if (serverfd < 0) {
fprintf(stderr, "connect to real server err"); //输出标准错误
return;
}
/*发送请求报文*/
Rio_readinitb(&serverrio, serverfd);
Rio_writen(serverfd, newrequest, strlen(newrequest)); //从位置newrequest传送strlen(newrequest)个字节到描述符serverfd
int cacheSize = 0;
memset(buf, 0, sizeof buf);
/*接受并转发给客户端*/
while ((n = Rio_readlineb(&serverrio, newrequest, MAXLINE)) != 0) {
printf("get %d bytes from server\n", n);
Rio_writen(fd, newrequest, n); //从位置buf传送n个字节到描述符fd
strcat(buf, newrequest);
cacheSize += n;
}
cacheWrite(buf, uriBackup, cacheSize);
Close(serverfd); //关闭文件描述符
}
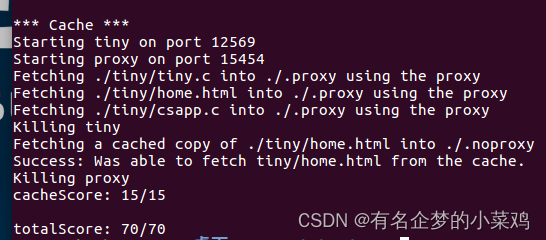
最后也是成功实现!
总结
这一章纯是大杂烩,将9、11、12章的重点内容全都结合到了一起,对网络传输、多线程并发和cache的学习是很有帮助的。这也是csapp的最后一个lab,至此成功收官!
历经一个半月的学习我感觉我自己收获颇丰,自我感觉还是纸上得来终觉浅,绝知此事要躬行。对于计算机系统的基础知识有了更具体更深入的了解。