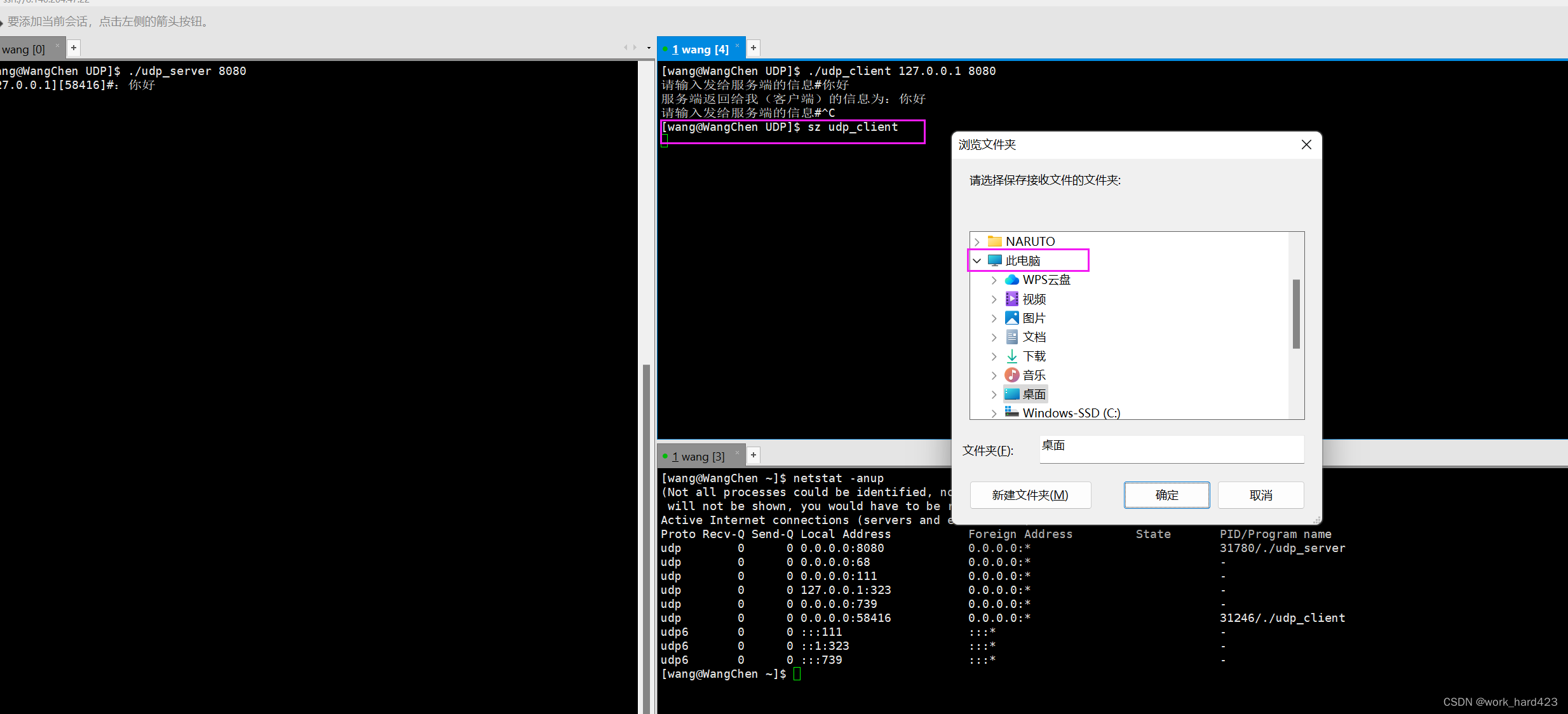
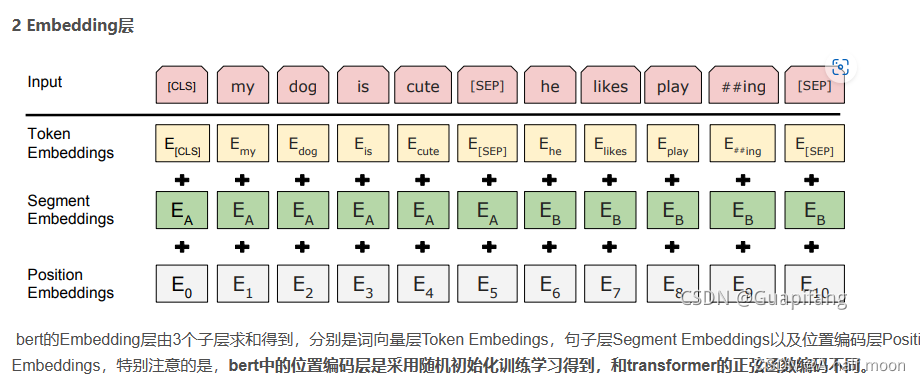
一、简介
在深度学习领域,Normalization用得很多,BN(Batch Normalization)于2015年由 Google 提出,开创了Normalization 先河;2016年出了LN(layer normalization)和IN(Instance Normalization);2018年也就是今年,Kaiming提出了GN(Group normalization),成为了ECCV 2018最佳论文提名。(其实还有很多Normalization的方法,因为用得也不是很多,这里只重点介绍这四种。)
1、独立同分布(i.i.d)
首先我们需要知道,机器学习领域有个很重要的假设:ID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。那BatchNorm的作用是什么呢?BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。(独立同分布的数据可以简化常规机器学习模型的训练、提升机器学习模型的预测能力,这已经是一个共识。)
为了得到服从i.i.d独立同分布的数据,在把数据喂给机器学习模型之前,“白化(whitening)”是一个重要的数据预处理步骤。白化一般包含两个目的:(得到独立同分布数据)
(1)去除特征之间的相关性 —> 独立;
(2)使得所有特征具有相同的均值和方差 —> 同分布。
白化最典型的方法就是PCA白化,在此不再赘述。(摘自文章)
2、Internal Covariate Shift
各种Normalization方法的提出基本都是为了解决“Internal Covariate Shift”问题的,那么什么是“Internal Covariate Shift”呢?
下面引入“Internal Covariate Shift”的概念:如果ML系统实例集合<X,Y>中的输入值X的分布老是变,这不符合IID假设,网络模型很难稳定地学规律,这不得引入迁移学习才能搞定吗,我们的ML系统还得去学习怎么迎合这种分布变化啊。对于深度学习这种包含很多隐层的网络结构,在训练过程中,因为各层参数不停在变化,所以每个隐层都会面临covariate shift的问题,也就是在训练过程中,隐层的输入分布老是变来变去,这就是所谓的“Internal Covariate Shift”。Internal指的是深层网络的隐层,是发生在网络内部的事情,而不是covariate shift问题只发生在输入层。(摘自文章)
换一种说法,对于神经网络的各层输出,由于它们经过了层内操作(比如激活函数)作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。由于是对层间信号的分析,也即是“internal”的来由。
简而言之,每个神经元的输入数据不再是“独立同分布”的。所以“Internal Covariate Shift”会导致什么问题呢?
(1)各层参数需要不断适应新的输入数据分布,降低学习速度。(学习率不能大,训练速度缓慢)
(2)深层输入的变化可能趋向于变大或者变小,导致浅层落入饱和区,使得学习过早停止。(容易梯度饱和、消失)
(3)每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能谨慎地选择。(调参困难)
3、Normalization的通用公式
我们首先给出Normalization的通用公式:
其中x代表某个神经元处在过激活函数之前的值。对照于这一公式,下面我们来梳理主流的几种规范化方法。
二、Batch-Normalization —— 纵向规范化
BN目前已经成为了调参师面试必问题之一了。同时,BN层也慢慢变成了神经网络不可分割的一部分了,相比其他优化操作比如dropout,L1、L2正则化, momentum,影子变量等等,BN是最无可替代的。
首先定义一个概念:激活输入值(就是深度神经网络中每个隐层在进行非线性变换处理前的数据,即BN一定是用在激活函数之前的!!)
1、为什么用BN
BN的提出是为了解决“Internal Covariate Shift”问题的,其基本思想为:能不能让每个隐层节点的激活输入值的分布固定下来呢?这样就避免了“Internal Covariate Shift”问题了。(可以理解为对深层神经网络每个隐层神经元的激活输入值做简化版本的白化操作)
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个X=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,在极大或极小的值处函数的导数接近0),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因。而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个激活输入值的分布强行拉回到均值为0方差为1的标准正态分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域(例如sigmoid函数的中间的部分),这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
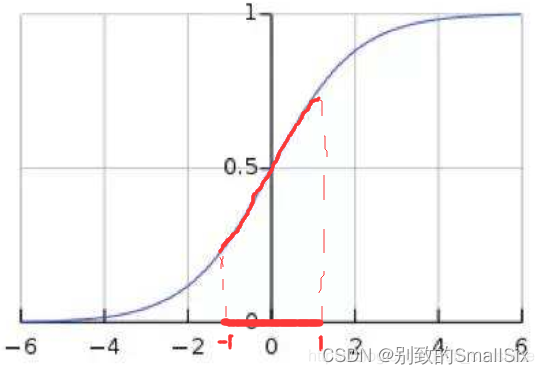
经过BN后,目前大部分激活输入值都落入非线性函数的线性区内(近似线性区域),其对应的导数远离导数饱和区,这样来加速训练收敛过程。
但是很明显,看到这里,稍微了解神经网络的读者一般会提出一个疑问:如果都通过BN,那么不就跟把非线性函数替换成线性函数效果相同了?这意味着什么?我们知道,如果是多层的线性函数变换其实这个深层是没有意义的,因为多层线性网络跟一层线性网络是等价的。这意味着网络的表达能力下降了,这也意味着深度的意义就没有了。所以BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shifty=scale∗x+shift),每个神经元增加了scale和shift参数,这两个参数是通过训练学习到的(可学习参数),意思是通过scale和shift参数把激活输入值从标准正态分布左移或者右移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于把非线性函数的值从正中心周围的线性区往非线性区动了动。
核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。
2、BN怎么操作
对于Mini-Batch SGD(一定是针对batch数据)来说,一次训练过程里面包含m个训练实例,其具体BN操作就是对于隐层内每个神经元(BN层是对于每个神经元做归一化处理,甚至只需要对某一个神经元进行归一化,而不是对一整层网络的神经元进行归一化。)的激活输入值来说,进行如下变换:
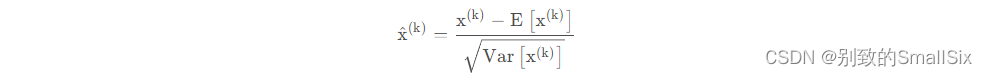
变换的意思是:某个神经元对应的原始的激活输入值x通过减去mini-Batch内m个实例获得的m个激活输入值的均值E(x)并除以求得的方差Var(x)来进行转换。
上文说过经过这个变换后某个神经元的激活x变成了均值为0,方差为1的正态分布,目的是把激活输入值往后续要进行的非线性变换的线性区拉动,增大导数值,增强反向传播信息流动性,加快训练收敛速度。但是这样会导致网络表达能力下降,为了防止这一点,每个神经元增加**两个调节参数(scale和shift)**来进行“再变换”,这两个参数是通过训练来学习到的,用来对变换后的激活反变换,使得网络表达能力增强,即对变换后的激活进行如下的scale和shift操作,这其实是变换的反操作:
![]()
上述过程论文中的描述为:

注:第三步多了一个ε,这里的ε是一个很小的数,目的是为了避免由分母等于0带来的系统错误。
3、Inference
在Inference阶段,因为没有mini-batch,看似好像无法求得实例集合的均值和方差。但是我们还是有办法的。既然没有从Mini-Batch数据里可以得到的统计量,那就想其它办法来获得这个统计量,就是均值和方差。
可以用从所有训练实例中获得的统计量来代替Mini-Batch里面m个训练实例获得的均值和方差统计量,那么在推理的时候直接用全局统计量即可:因为每次做Mini-Batch训练时,都会有那个Mini-Batch里m个训练实例获得的均值和方差,现在要全局统计量,只要把每个Mini-Batch的均值和方差统计量记住,然后对这些均值和方差求其对应的数学期望即可得出全局统计量,即:
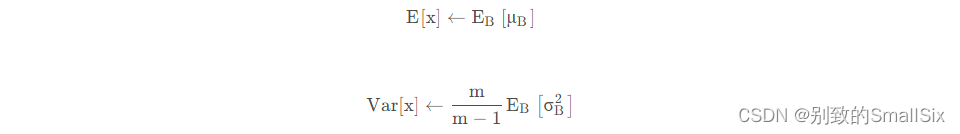
有了均值E[x]和方差Var[x],每个隐层神经元也已经有对应训练好的Scaling参数γ和Shift参数ε,那么在推理过程中进行BN采取如下方式:(通过简单的合并计算推导就可以得出这个结论)
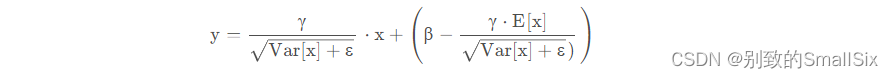
4、BatchNorm的优势与局限
(1)BatchNorm的优势如下:
(a)极大提升了训练速度,收敛过程大大加快;
(b)还能增加分类效果,一种解释是这是类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout也能达到相当的效果;
(c)另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等。
(2)局限:
(a)由于BN与mini-batch的数据分布紧密相关,故而mini-batch的数据分布需要与总体的数据分布近似相等。因此BN适用于batch size较大且各mini-batch分布相近似的场景下(训练前需进行充分的shuffle)。不适用于动态网络结构和RNN。
(b)其次,BN只在训练的时候用,inference的时候不会用到,因为inference的输入不是批量输入。这也不一定是BN的缺点,但这是BN的特点。
三、Layer normalization —— 横向规范化
在前面谈到,标准化的作用就是改良数据分布。
BN的操作是,对同一批次的数据分布进行标准化,得出的均值方差,其可信度受batch size影响。很容易可以想到,如果我们对小batch size得出均值方差,那势必和总数据的均值方差有所偏差。这样就解释了BN的第一个缺点:BN特别依赖batch Size。
与BN仅针对单个神经元不同,LN综合考虑整个一层的信息,计算该层输出的平均值和方差作为规范化标准,对该层的所有输出施行同一个规范化操作,即对同一层网络的输出做一个标准化。注意,同一层的输出是单个图片的输出,比如对于一个batch size为32的神经网络训练,会有32个均值和方差被得出,每个均值和方差都是由单张图片的所有channel之间做一个标准化得到的。这么操作,就使得LN不受batch size的影响。
同时,LN可以很好地用到序列型网络如RNN中。
同时,LN在训练过程和inference过程都会用到,这就是和BN有很大的差别了。
1、计算方式
LN的计算方式如下:
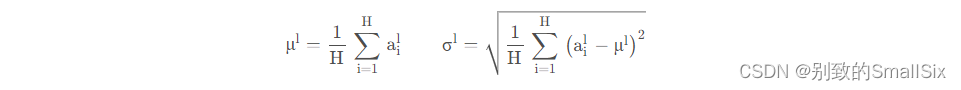
H是某个隐藏层的神经元数量。
2、LN vs BN
BN 的一个缺点是需要较大的 batchsize 才能合理估训练数据的均值和方差,这导致内存很可能不够用,同时它也很难应用在训练数据长度不同的 RNN 模型上。
Layer Normalization (LN) 的一个优势是不需要批训练,在单条数据内部就能归一化。
更形象一点的描述如下:
(1)BN是“竖”着来的,各个维度分别做规范化,所以与batch size有关系;
(2)LN是“横”着来的,对于一个样本,不同的神经元neuron间做规范化;
图示如下:
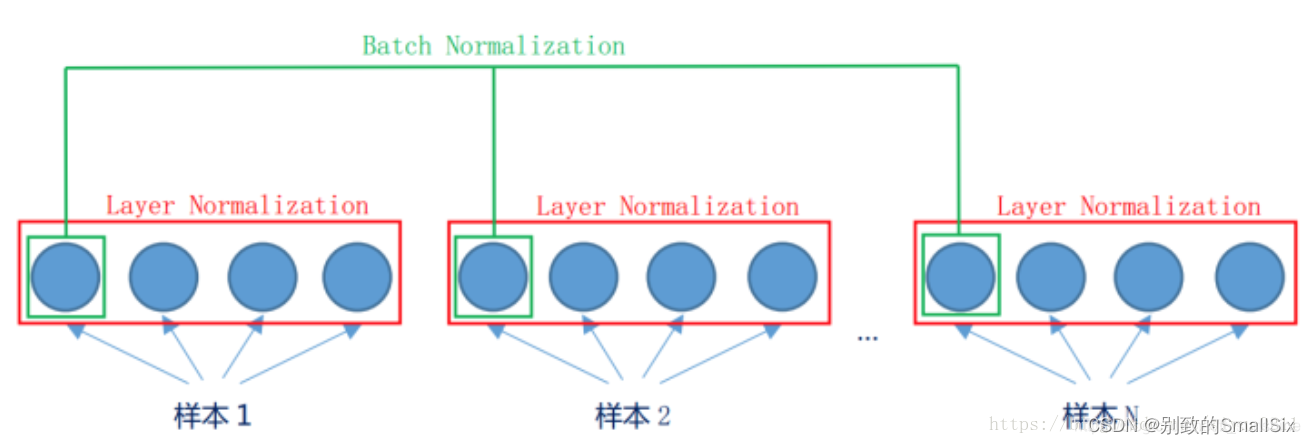
(3)相较于BN,LN不受mini-batch的均值和方差的影响,可用于mini-batch较小时的场景、动态网络结构和RNN;
(4)此外,由于无需保存mini-batch的均值和方差,节省了存储空间。然而,对于相似度相差较大的特征(比如颜色和大小),LN会降低模型的表示能力,此种情形下BN更好(因为BN可对单个神经元训练得到)。
四、Weight Normalization —— 参数规范化
BN和LN将规范化应用于输入数据x,WN则对权重进行规范化。WN是在训练过程中,对网络参数进行标准化。这也是一个很神奇的操作。不过效果表现上,是被BN、LN虐了。还不足以成为主流的标准化方法,所以在这里只是稍微提一下。(效果不是很好,仅提一下。)
WN将权重向量分解为权重大小和方向两部分:
![]()
WN不依赖于输入数据的分布,故可应用于mini-batch较小的情景且可用于动态网络结构。此外,WN还避免了LN中对每一层使用同一个规范化公式的不足。
总的来看,LN、BN属于将特征规范化,WN是将参数规范化。三种规范化方式尽管对输入数据的尺度化(scale)参数来源不同,但其本质上都实现了数据的规范化操作。
五、Instance Normalization —— 实例规范化
Instance norm和Batch norm的区别只有一点不同,那就是BN是作用于一个batch,而IN则是作用于单个样本。也就是说,BN是同一个batch中所有样本的同一层特征图抽出来一起求mean和variance,而IN只是对一个样本中的每一层特征图求mean和variance。这么说的话似乎Instance norm只对3D特征有用,也就是只对图像特征有用。(如果是一维特征,那么用了instance norm结果还是自身,因为参与计算的值只有1个,毫无意义.。。。)
这里就不展开了,后面会有具体的图来形象描述。
六、Group Normalization —— 组规范化
又是何恺明大佬的巨作,ECCV2018最佳论文提名。
现状:目前LN和IN都没做到完全代替BN(其实现在看来GN也没法取代BN)。GN的提出,就解决了BN所遇到的问题(batch size太大的话会out of memory)。GN对系统的优化程度完全不依赖Batch size有多大。我们来看一张图:
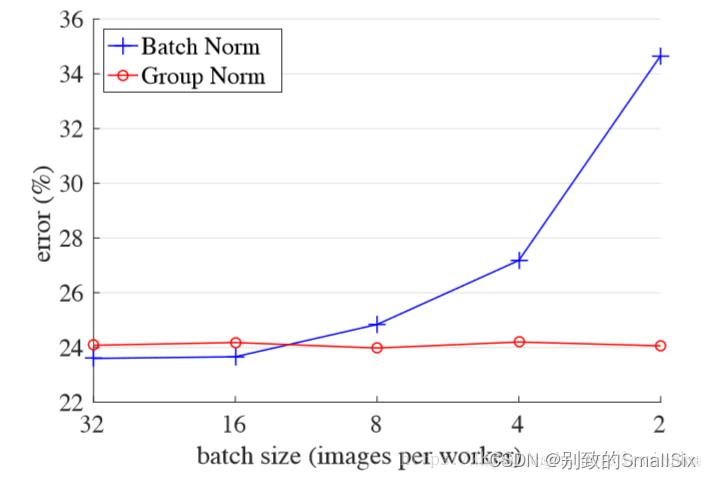
GN在很小的batch size就是稳定的,而BN在batch size不大的情况下,效果就会差很多。这看起来是令人兴奋的。先看看GN是怎么操作的:
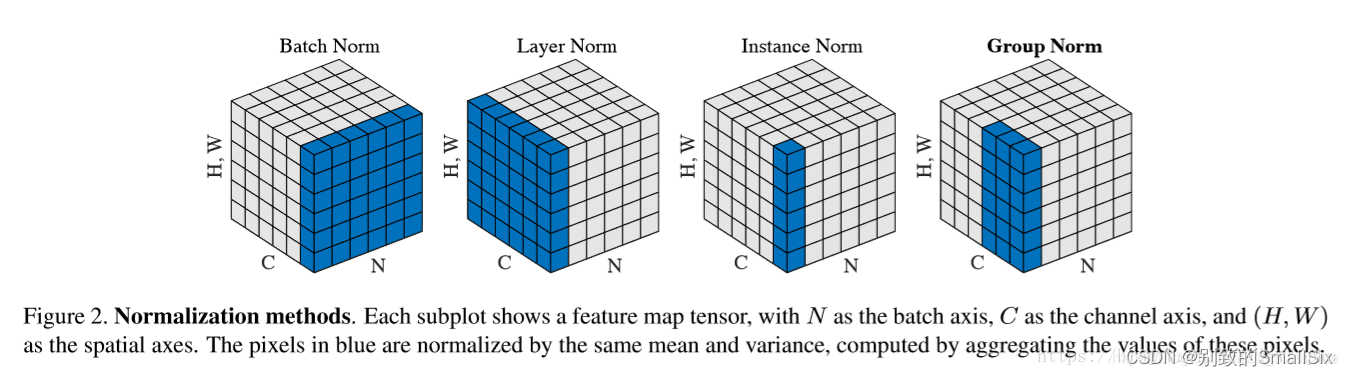
上图描述了BN, LN, IN和GN四种norm方式。用更简单的语言来讲,各种Norm之间的差别只是针对的维度不同而已。
(1)BatchNorm:batch方向做归一化,算NHW的均值;
(2)LayerNorm:channel方向做归一化,算CHW的均值;
(3)InstanceNorm:一个channel内做归一化,算H*W的均值;
(4)GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;
七、总结
从最广为人知的BN着手讲解:
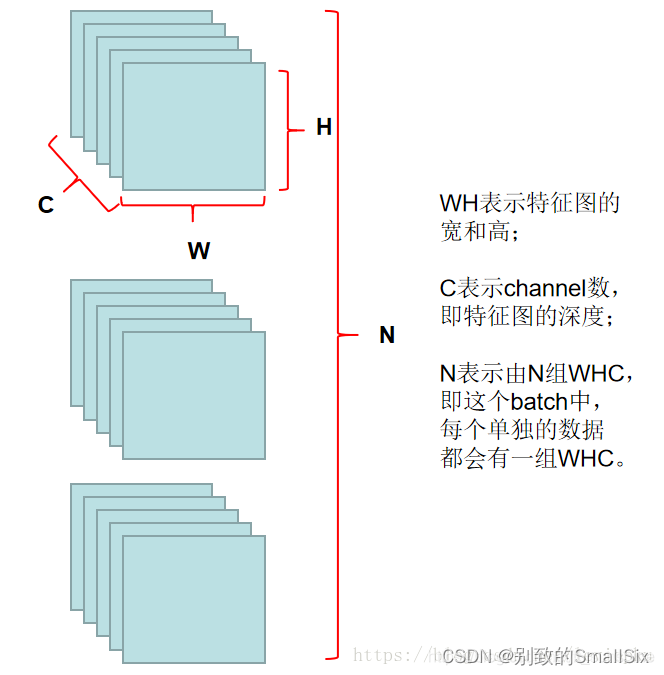
在一层层的网络之间传递的数据,我们叫做hidden feature,即隐藏特征图。我们的隐藏特征图通常有4个维度,包括长、宽、depth和batch数。hidden feature的深度由上一参数层的filters数量决定,batch数就是我们设的batch size。
那么,我们的hidden feature就可以看作一个4维张量,包含(N, C,H, W)这四个维度。N对应的就是batch数,而C对应的就是channel数,即depth。注意区分四个维度分别的含义。
如上图所示,BN是在N维度上做的Norm,N越大那么,N维度上Norm的效果就越好。实际上,我认为上图画得不够好,因为一开始我看这张图的时候,就被迷惑了好久,所以为了更好解释这些维度之间的差别,我重新画了一遍上图,用我自己的方式:(摘自大佬博客)
对于BN来讲,norm的操作range是下图:
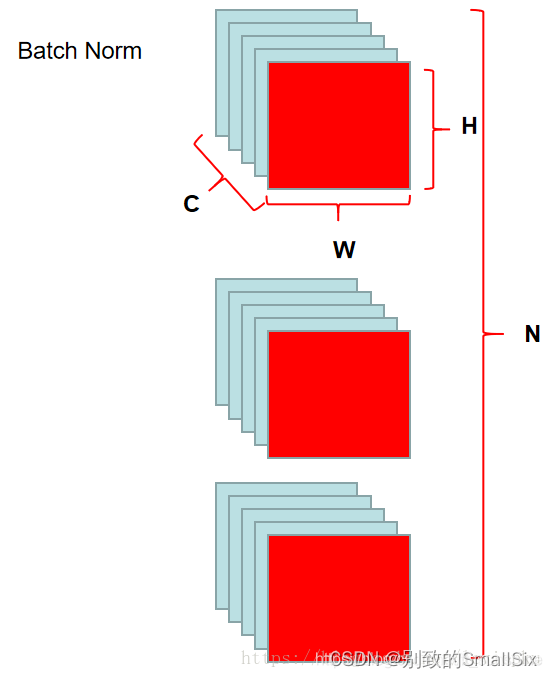
红色标记就是norm的操作range,通过这种方法,可以简单标出LN和IN:

我相信,通过上面这几张图,BN/LN/IN之间的差别是一目了然的。以此来引导出我们今天的主角——Group Norm。
GN也只是在操作维度上进行了一丢丢改进而已。他的做法比较贴近LN,可是比LN成功得多。 看一下图就知道了:
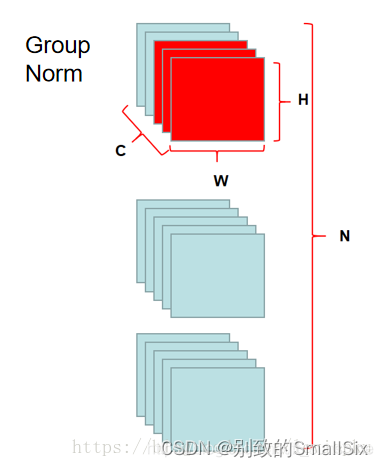
GN并不像LN那样把channel维度所有channel进行一个Normalization,而是以分组的形式获得一个组的Norm即Group Normalization。就像作者自己比较的说法:
LN和IN只是GN的两种极端形式。
我们对channel进行分组,分组数为G,即一共分G组。 当G=1时,GN就是LN了;当G=C时,GN就是IN了。这也是一个有趣的比较,类似于GN是LN和IN的一个tradeoff。文章里对G的默认值是32。
八、题外话:normalization 有效的原因?
我们以下面这个简化的神经网络为例来分析。(摘自知乎大佬文章)
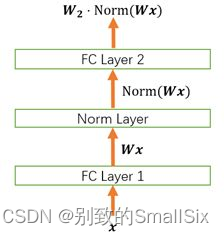
1、权重伸缩不变性
权重伸缩不变性(weight scale invariance) 指的是:当权重W按照常量λ进行伸缩时,得到的规范化后的值保持不变,即:
![]()
其中
上述规范化方法均有这一性质,这是因为,当权重W伸缩时,对应的均值和标准差均等比例伸缩,分子分母相抵。

权重伸缩不变性可以有效地提高反向传播的效率。
由于
因此,权重的伸缩变化不会影响反向梯度的 Jacobian 矩阵,因此也就对反向传播没有影响,避免了反向传播时因为权重过大或过小导致的梯度消失或梯度爆炸问题,从而加速了神经网络的训练。
权重伸缩不变性还具有参数正则化的效果,可以使用更高的学习率。
由于
因此,浅层的权重值越大,其梯度就越小。这样,参数的变化就越稳定,相当于实现了参数正则化的效果,避免参数的大幅震荡,提高网络的泛化性能。
2、Normalization 的数据伸缩不变性
数据伸缩不变性(data scale invariance) 指的是,当数据x按照常量λ进行伸缩时,得到的规范化后的值保持不变,即:
![]()
其中
数据伸缩不变性仅对 BN、LN 和 IN和GN成立。因为这四者对输入数据进行规范化,因此当数据进行常量伸缩时,其均值和方差都会相应变化,分子分母互相抵消。而 WN 不具有这一性质。
数据伸缩不变性可以有效地减少梯度弥散,简化对学习率的选择。
对于某一层神经元而言,展开可得:
每一层神经元的输出依赖于底下各层的计算结果。如果没有正则化,当下层输入发生伸缩变化时,经过层层传递,可能会导致数据发生剧烈的膨胀或者弥散,从而也导致了反向计算时的梯度爆炸或梯度弥散。
加入 Normalization 之后,不论底层的数据如何变化,对于某一层神经元而言,其输入
永远保持标准的分布,这就使得高层的训练更加简单。从梯度的计算公式来看:
数据的伸缩变化也不会影响到对该层的权重参数更新,使得训练过程更加鲁棒,简化了对学习率的选择。
参考:深度学习中的Normalization总结(BN/LN/WN/IN/GN)-CSDN博客