目录
1. 创新点
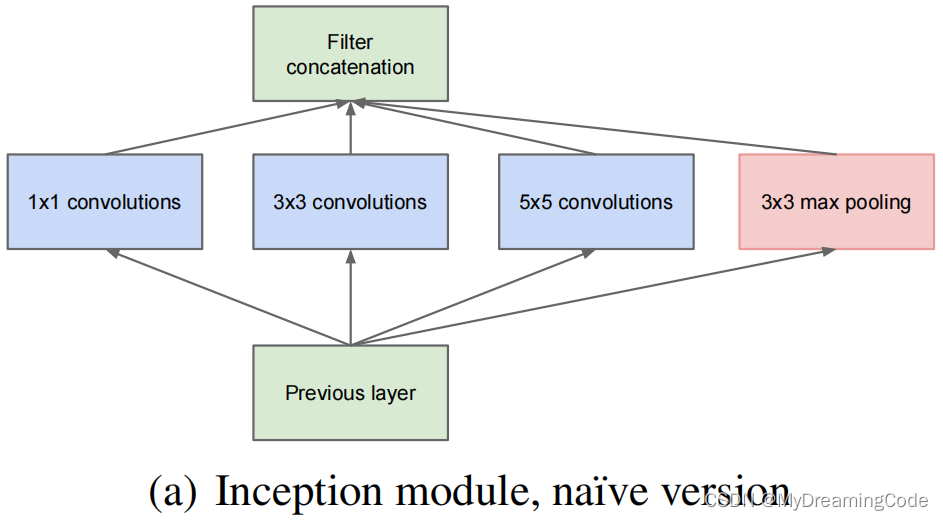
1.1 引入Inception结构
1.2 1×1卷积降维
1.3 两个辅助分类器
1.4 丢弃全连接层,使用平均池化层
2. 网络结构
3. 知识点
3.1 torch.cat
3.2 关于self.training
3.3 关于load_state_dict中的strict
4. 代码
4.1 model.py
4.2 train.py
4.3 predict.py
5. 结果
1. 创新点
1.1 引入Inception结构
作用:融合不同尺度的特征信息
注意:每个分支所得特征矩阵的宽、高必须相同
下图来自:Going deeper with convolutions
1.2 1×1卷积降维

channels: 512
a.不使用1×1卷积核降维
使用:64个5×5卷积核进行卷积
参数:5×5×512×64=819,200
b.使用1×1卷积核降维
使用:24个1×1卷积核进行卷积
1.3 两个辅助分类器
内容:GoogLeNet有三个输出层(两个为辅助分类层)

Going deeper with convolutions文章里:
- An average pooling layer with 5×5 filter size and stride 3, resulting in an 4×4×512 output for the (4a), and 4×4×528 for the (4d) stage.
- A 1×1 convolution with 128 filters for dimension reduction and rectified linear activation.
- A fully connected layer with 1024 units and rectified linear activation.
- A dropout layer with 70% ratio of dropped outputs.
- A linear layer with softmax loss as the classifier (predicting the same 1000 classes as the main classifier, but removed at inference time).
1.4 丢弃全连接层,使用平均池化层
作用:大大减少模型的参数
2. 网络结构


Inception层太多,列出几个:


3. 知识点
3.1 torch.cat
import torch
a = torch.Tensor([1, 2, 3])
b = torch.Tensor([4, 5, 6])
c = [a, b]
print(torch.cat(c))
# tensor([1., 2., 3., 4., 5., 6.])3.2 关于self.training
使用model.train()和model.eval()控制模型的状态
在model.train()模式下self.training=True
在model.eval()模式下self.training=False
3.3 关于load_state_dict中的strict
为True:有什么要什么,每一个键都有(默认为True)
为False:有什么要什么,没有的就不要
missing_keys和unexpected_keys:缺失的、不期望的键
4. 代码
4.1 model.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_use=True, init_weight=False):
super(GoogLeNet, self).__init__()
self.aux_use = aux_use
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) # ceil_mode默认向下取整 True为向上取整
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_use:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # 自适应平均池化 指定输出(H,W)
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weight:
self._initialize_weights_()
def forward(self, x):
# N×3×224×224
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.inception3a(x)
x = self.inception3b(x)
x = self.maxpool3(x)
x = self.inception4a(x)
if self.training and self.aux_use:
aux1 = self.aux1(x)
x = self.inception4b(x)
x = self.inception4c(x)
x = self.inception4d(x)
if self.training and self.aux_use:
aux2 = self.aux2(x)
x = self.inception4e(x)
x = self.maxpool4(x)
x = self.inception5a(x)
x = self.inception5b(x)
x = self.avgpool(x)
x = torch.flatten(x, start_dim=1)
x = self.dropout(x)
x = self.fc(x)
if self.training and self.aux_use:
return x, aux1, aux2
return x;
def _initialize_weights_(self):
for v in self.modules():
if isinstance(v, nn.Conv2d):
nn.init.xavier_uniform_(v.weight)
if v.bias is not None:
nn.init.constant_(v.bias, 0)
if isinstance(v, nn.Linear):
nn.init.xavier_uniform_(v.weight)
if v.bias is not None:
nn.init.constant_(v.bias, 0)
# set BasicConv2d class
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x;
# set Inception class
class Inception(nn.Module):
# 各分支最后的输出宽高要一样
def __init__(self, in_channels, ch11, ch33_reduce, ch33, ch55_reduce, ch55, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch11, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch33_reduce, kernel_size=1),
BasicConv2d(ch33_reduce, ch33, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch55_reduce, kernel_size=1),
BasicConv2d(ch55_reduce, ch55, kernel_size=5, padding=2)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, dim=1)
# set InceptionAux class
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output:[batch,128,4,4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# Input: Aux1(batch,512,14,14) Aux2(batch,528,14,14)
x = self.averagePool(x)
# output: Aux1(batch,512,4,4) Aux2(batch,528,4,4)
x = self.conv(x)
# output:Aux1、Aux2(batch,128,4,4)
x = torch.flatten(x, start_dim=1)
x = F.dropout(x, 0.5, training=self.training)
# batch × 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# batch × 1024
x = self.fc2(x)
# batch × num_classes
return x
4.2 train.py
import os
import sys
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import json
from model import GoogLeNet
import torch.optim as optim
from tqdm import tqdm
def main():
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
data_transform = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]),
'val': transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
}
data_root = os.path.abspath(os.getcwd())
image_path = os.path.join(data_root, 'data_set', 'flower_data')
assert os.path.exists(image_path), 'file:{} is not exist!'.format(image_path)
# set dataset
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, 'train'), transform=data_transform['train'])
val_dataset = datasets.ImageFolder(root=os.path.join(image_path, 'val'), transform=data_transform['val'])
train_num = len(train_dataset)
val_num = len(val_dataset)
# write dict into file
flower_list = train_dataset.class_to_idx
class_dict = dict((k, v) for v, k in flower_list.items())
json_str = json.dumps(class_dict, indent=4)
with open('./class_indices.json', 'w') as file:
file.write(json_str)
# set dataloader
batch_size = 32
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
print('using {} images for training, {} images for validation.'.format(train_num, val_num))
net = GoogLeNet(num_classes=5, aux_use=True, init_weight=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0003)
epochs = 30
best_acc = 0.0
save_path = './GoogLeNet.pth'
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
epoch_loss = 0.0
train_bar = tqdm(train_loader)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
output, aux1_output, aux2_output = net(images.to(device))
loss0 = loss_function(output, labels.to(device))
loss1 = loss_function(aux1_output, labels.to(device))
loss2 = loss_function(aux2_output, labels.to(device))
loss = loss0 + 0.3 * loss1 + 0.3 * loss2
loss.backward()
optimizer.step()
# print statistics
epoch_loss += loss.item()
train_bar.desc = 'train epoch[{}/{}] loss:{:.3f}'.format(epoch + 1, epochs, loss)
# validate
net.eval()
acc = 0.0
with torch.no_grad():
val_bar = tqdm(val_loader)
for step, data in enumerate(val_bar):
val_images, val_labels = data
outputs = net(val_images.to(device))
predict_y = torch.argmax(outputs, dim=1)
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_acc = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epoch + 1, epoch_loss / train_steps, val_acc))
if val_acc > best_acc:
best_acc = val_acc
torch.save(net.state_dict(), save_path)
print('Finished Training!')
if __name__ == '__main__':
main()
4.3 predict.py
import os
import torch
import torchvision
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
import json
from model import GoogLeNet
def main():
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
img_path = './sunflower.jpg'
assert os.path.exists(img_path), 'file:{} is not exist!'.format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N,C,H,W]
img = transform(img)
img = torch.unsqueeze(img, dim=0)
# read class_dict
json_path = './class_indices.json'
assert os.path.exists(json_path), 'file:{} is not exist!'.format(json_path)
with open(json_path, 'r') as file:
class_dict = json.load(file)
# create model
net = GoogLeNet(num_classes=5, aux_use=False).to(device)
# load model weights
weight_path = './GoogLeNet.pth'
assert os.path.exists(weight_path), 'file:{} is not exist!'.format(weight_path)
# unexpected_keys里面存放的是辅助分类器aux1与aux2的权重
missing_keys, unexpected_keys = net.load_state_dict(torch.load(weight_path, map_location=device), strict=False)
net.eval()
with torch.no_grad():
outputs = torch.squeeze(net(img.to(device))).cpu()
predict = torch.softmax(outputs, dim=0)
predict_class = torch.argmax(predict).numpy()
print_res = 'class:{} probability:{:.3f}'.format(class_dict[str(predict_class)], predict[predict_class])
plt.title(print_res)
for i in range(len(predict)):
print('class:{:10} probability:{:.3f}'.format(class_dict[str(i)], predict[i]))
plt.show()
if __name__ == '__main__':
main()
5. 结果

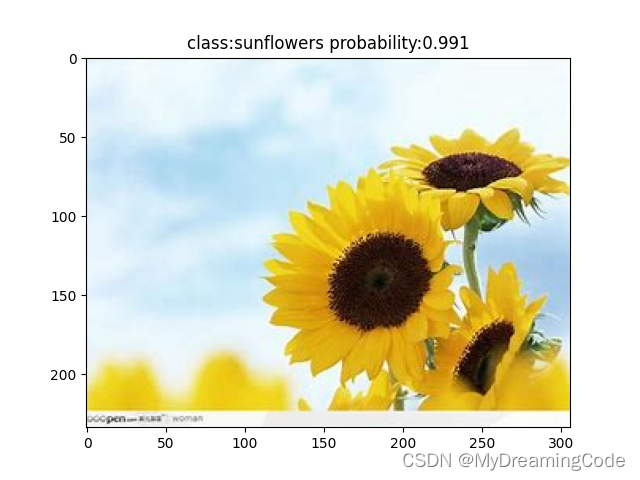


![[C++网络协议] 优于select的epoll](https://img-blog.csdnimg.cn/f805f2d56473425a8acdde87d8b3cbc6.png)