目录
HTTP 协议
认识 URL
HTTP 请求
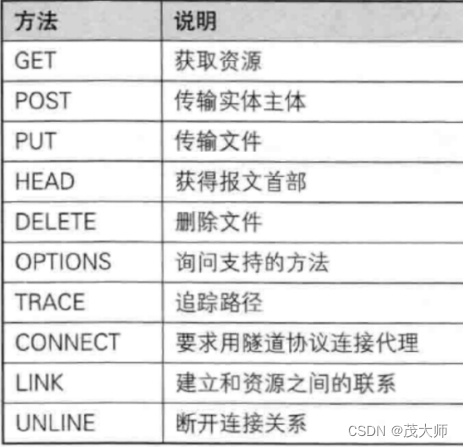
认识方法
HTTP 响应
认识状态码
总结
HTTP 请求的构造
Form 表单构造
AJAX 构造
Postman 构造
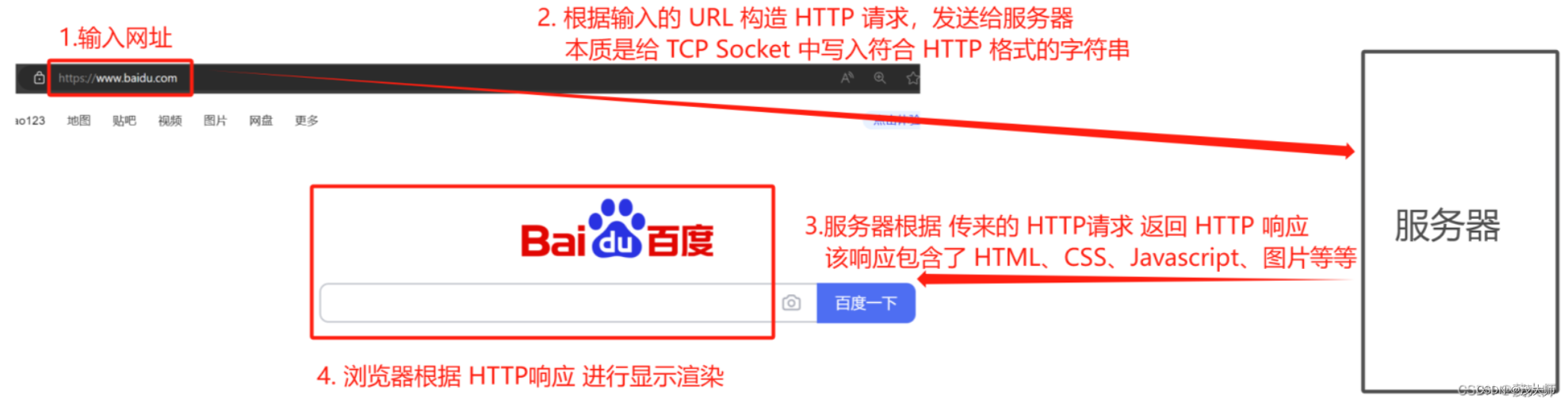
HTTP 协议
- 应用层使用最广泛的协议
- 浏览器 基于 HTTP协议 获取网站
- 是 浏览器 和 服务器 之间的交互桥梁
- HTTP协议 基于传输层的 TCP协议 实现
- HTTP 全称为 HyperText Transfer Protocol,中文翻译为 超文本传输,意思是不仅能传输文本,还可传输图片、视频、音频等二进制数据
认识 URL
- 绿色部分:指 协议方案名
- 青色部分:指 服务器地址、域名,通过 DNS 可转化为 IP 地址
- 黄色部分:指 服务器端口号,描述的是哪个程序
- 橙色部分:指 带层次的文件路径,找到程序管辖下的哪个文件
- 蓝色部分:指 查询字符串(query string),获取资源时候所带的参数
- 紫色部分:指 片段标识符
注意:
- 一个 URL 其中有些部分可以省略
- 当端口被省略时,浏览器提供默认端口
- HTTP协议 默认端口为 80,HTTPS协议默认端口为 443
- 当然这里的 带层次的文件路径 并未省略,/ 也是路径,为 HTTP 服务器的 根目录
- HTTP服务器 是系统上的一个进程,通常委托该 服务器 管理系统上的一个特定的目录,同时在这个目录里的资源都可以让外面进行访问
- 当然所管理的 根目录 可以为系统上的任意一个目录,具体看服务器的配置
- 不同路径 拿到的网页资源是不同的
补充:
- 当我们在百度搜索框中输入你好
图一:浏览器 URL 框中所显示的 URL
图二:复制浏览器 URL 框中的 URL ,并粘贴到记事本中所显示的 URL
- 注意这两个 URL 实际是一样的,唯一的不同是中文 "你好" 变成了一串有规律的字符码
- %E4%BD%A0%E5%A5%BD 称为 urlencode(转义字符),将中文 "你好" 重新转译为 % + 16进制数,如果此处不进行编码,直接写中文,浏览器可能就无法正确识别,从而访问出错!
- urlencode 为编码工具,就有与之对应的 urldecode 解码工具
- 通常 urlencode 和 urldecode 都是 浏览器 或 HTTP 服务器内置的行为,一般写代码不会涉及,仅需知道该概念即可


阅读下面内容之前,我们需要了解并熟悉 Fiddle 工具的使用,可点击下方链接阅读
Fiddle 安装使用
HTTP 请求
1.首行
- 红框代表 HTTP 的方法
- 篮框代表 URL,唯一资源定位符,标识互联网上唯一的资源的位置(资源在服务器的哪个目录下的哪个文件)
- 绿框代表 HTTP 的版本号
2.请求头 header
- 按 行 组织的键值对,每一行均为一个键值对,键和值之间使用 :和 空格 来分割
- 每个 键和值 均有固定含义,均为 HTTP协议 定义好的
Host
- 描述服务器所在的地址和端口
Content-Length
- 表示 body 中的数据长度
Content-Type
- 表示请求的 body 中的数据格式
User-Agent
- 描述 操作系统 和 浏览器 的版本,现今主要用来区分 PC端 和 移动端,并返回不同的页面
Referer
- 描述 当前页面 是从 哪个页面 跳转来的
- 通过 地址栏输入地址 或 直接点击收藏夹 是没有 Referer 的
Cookie
- 本质是 浏览器 给网页提供的 本地存储数据 的机制
- Cookie 通过 键值对 的方式来组织数据
- 为了保证安全,网页 默认不允许访问 主机硬盘
- 但 Cookie 对 浏览器 访问 硬盘 做出了明确的限制,仅能访问限制区域
- 服务器会通过 HTTP响应 报头部分(Set-Cookie 字段),让浏览器的 Cookie 进行相应存储,所以 Cookie 中的数据来自于服务器
- Cookie 存储在浏览器中,其实就是存储在硬盘中
- Cookie 在存储时,按照 浏览器 + 域名 的形式进行细分的
- 不同的浏览器,各自存储自己的 Cookie,同一浏览器不同域名,也对应着不同的 Cookie
- Cookie 一般还有过期时间,意味着 Cookie 到达 过期时间 ,浏览器便会自动删除 Cookie,所以 Cookie 并不是永久存储在硬盘中
- 客户端通过 Cookie 来保存当前 服务器和客户端 交互的中间状态
- 当客户端访问浏览器的时候,会自动将 Cookie 内容带入到请求中,从而服务器便能知道当前客户端的具体情况,因为一台服务器是为多个客户端提供服务!
3.空白行
- 首图红框部分即为空白行
- HTTP协议 并未规定报头部分的键值对的数量,从而空白行便为 报头(header) 的结束标记,即 报头 和 正文 之间的分隔符
- HTTP 在传输层依赖 TCP 协议,而 TCP 又是面向字节流的,如果无 空白行,便会出现经典的 粘包问题
4.正文 body
- 不是每个请求均有正文部分
- 正文存放数据的内容和格式一般由程序员自主定义

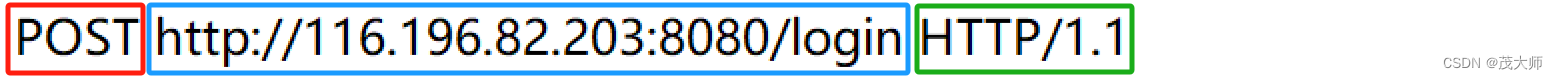

认识方法
- 方法描述了 HTTP请求 的语义
- 在实际的开发中 GET 和 POST 是最常见的两个方法
GET 请求常见的几种形式:
- 在浏览器地址栏直接输入 URL 访问
- HTML 中的 link、script、img、a 等标签
- 通过 JavaScript 构造 GET 请求
POST 请求常见几种形式:
- 登录操作
- 上传文件操作
注意:
- GET 请求无正文 body,POST 请求一般有正文 body
- 上图的各方法说明是 HTTP设计者的设计初心,但在实际开发中,这些说明仅供参考
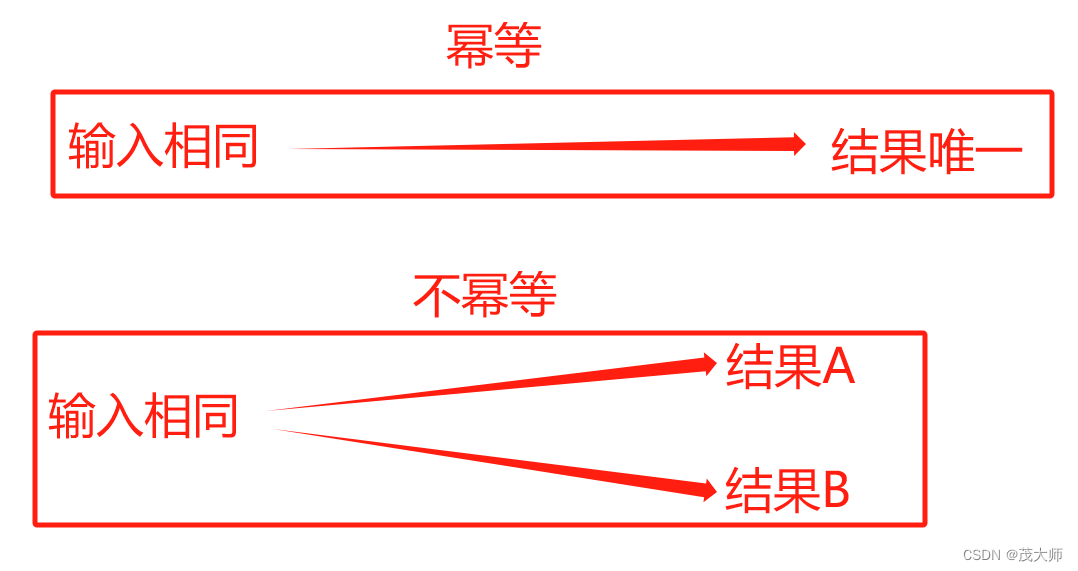
GET 和 POST 典型区别:
- GET 和 POST 没有本质区别,大部分场景下都能相互代替,但是在使用习惯上差异相对较大
- GET 进行信息的传递一般放在 query string 中,POST 传递信息一般通过 正文 body
- GET 请求一般是从服务器获取数据,POST 请求一般是用于给服务器提交数据
- GET 可以被缓存,POST 一般不能缓存(把请求的结果保存下来,下次请求则不需要真请求,直接读取缓存结果就行)
- GET 一般会被设计成幂等, POST 不要求幂等
HTTP 响应
1.首行
- 红框代表 HTTP 的版本号
- 绿框为状态码
2.响应报头 header
- 键值对结构
3.空白行
- 首图红框部分即为空白行
- HTTP协议 并未规定报头部分的键值对的数量,从而空白行便为 报头(header) 的结束标记,即 报头 和 正文 之间的分隔符
- HTTP 在传输层依赖 TCP 协议,而 TCP 又是面向字节流的,如果无 空白行,便会出现经典的 粘包问题
4.正文
- 正文可为 json 数据、HTML、CSS、JavaScript、图片 等等
- 此处正文为 json 数据


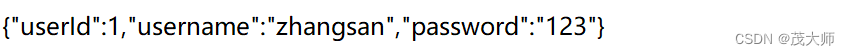
认识状态码
- 状态码描述了 HTTP响应 的结果
1XX Informational(信息性状态码) 接收的请求正在处理 2XX Success(成功状态码) 请求正常处理完毕 3XX Redirection(重定向状态码) 需要进行附加操作以完成请求 4XX Client Error(客户端错误状态码) 服务器无法处理请求 5XX Server Error(服务器错误状态码) 服务器请求出错
- 以下列举几种常见的状态码
200 OK
- 最常见的一个状态码,表示访问成功
404 Not Found
- 表示没有找到资源
- 当输入 URL 访问对方资源服务器上相应资源时,如果该 URL 标识的资源不存在,便出现 404
403 Forbidden
- 表示访问被拒绝
- 有些页面通常需要用户有一定权限才能访问,如 用户仅在登录后才能访问的页面 ,如果用户未登录,直接访问该页面,则会出现 403
405 Method Not Allowed
- 表示对方服务器不支持该方法
- 如对方服务器仅支持 GET 、POST 方法,其余 PUT、DELETE 等方法不支持,如果使用这些不支持的 HTTP请求方法 来请求服务器,则出现 405
500 Internal Server Error
- 表示服务器内部出现错误
- 一般是服务器内部代码执行出现错误、一些异常情况(服务器异常崩溃),便会出现 500
504 Gateway Timeout
- 表示扮演网关或代理的服务器无法在规定时间内获得想要的响应
- 当服务器负载比较大的时候,服务器处理单条请求的时候消耗的时间就会很长,便可能会导致出现超时的情况,便会出现 504
- Gateway 代表网关,就是一个网络的入口或出口,通常代指一个机房的入口服务器
- 一般 192.168.1.1 这种 IP 为网关 IP
302 Move temporarily
- 表示临时重定向
- 在登录页面经常见到 302 ,用于实现登录功能后自动跳转到主页,响应报文的 header 部分会包含一个 Location 字段,表示要跳转到哪个页面
301 Move Permanently
- 表示永久重定向
- 当浏览器收到该 HTTP响应状态码,后续的请求都会被自动改为新地址
- 通过 Location 字段来表示要重定向到新的地址
总结
HTTP协议中程序员可自定义:
- URL 中的路径
- URL 中的 query string
- header中的键值对
- header中的 cookie的键值对
- 正文 body
HTTP 请求的构造
Form 表单构造
代码示例
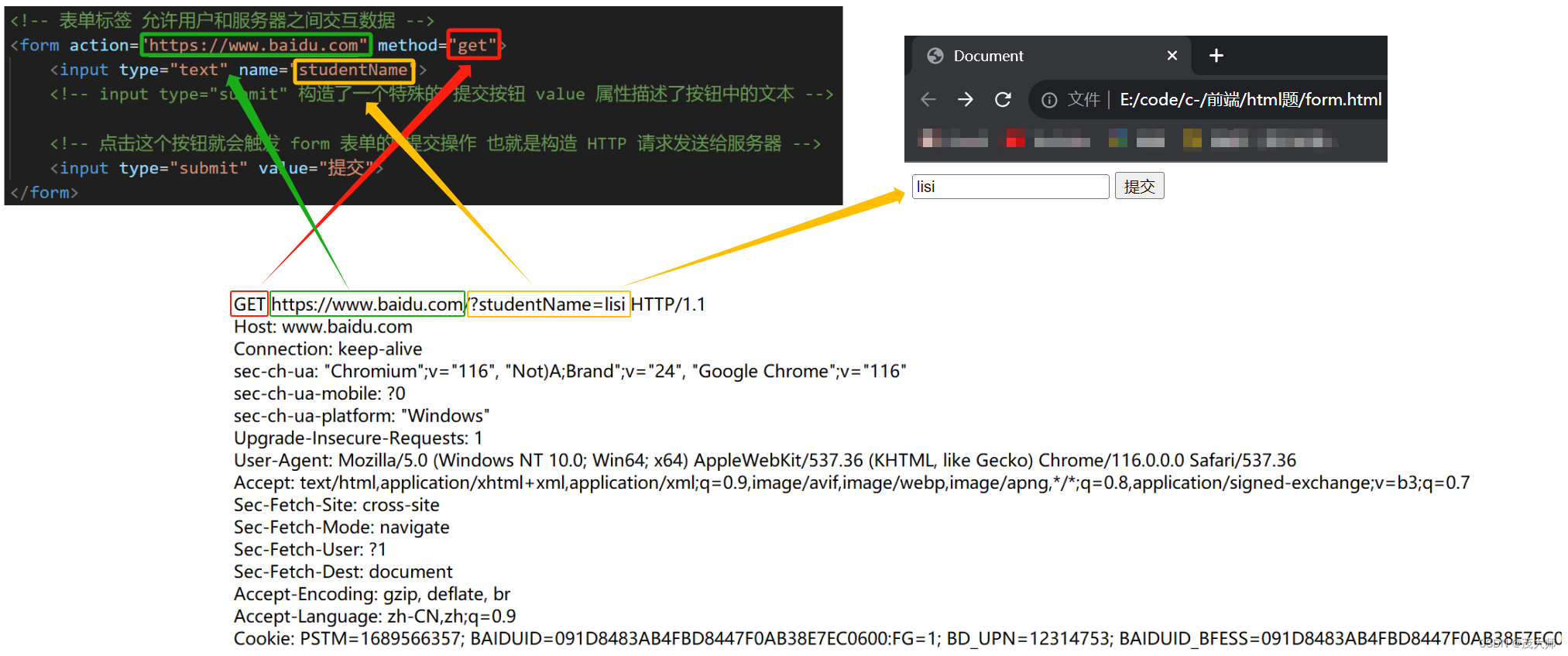
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <!-- 表单标签 允许用户和服务器之间交互数据 --> <form action="https://www.baidu.com" method="get"> <input type="text" name="studentName"> <!-- input type="submit" 构造了一个特殊的 提交按钮 value 属性描述了按钮中的文本 --> <!-- 点击这个按钮就会触发 form 表单的 提交操作 也就是构造 HTTP 请求发送给服务器 --> <input type="submit" value="提交"> </form> </body> </html>页面操作
- 我们使用 Fiddle 将我们构造的请求进行抓包
- 根据上图我们可以清楚的看到,通过 Form 表单 能构造一个 GET 请求
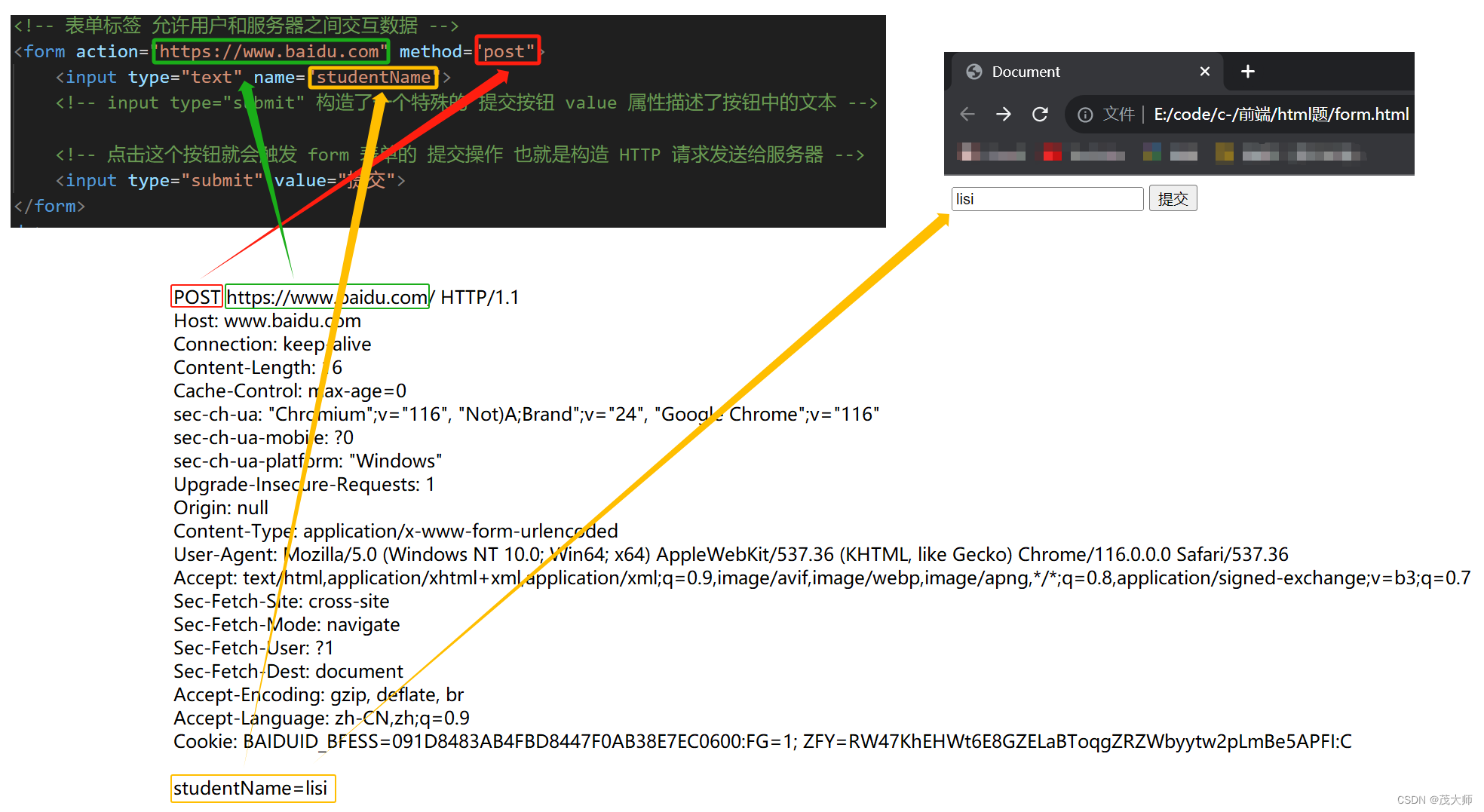
- 当然我们也可以通过 Form 表单构造一个 POST 请求
注意:
- studentName = lisi 这一键值对,GET 请求将其放在 query string 中,而 POST 请求将其放在 正文 body 中,能很好的对应上文讲述的 GET 和 POST 的区别
- Form 标签仅能构造 GET 和 POST 请求 ,无法构造 PUT、DELETE 等请求
AJAX 构造
- 全称 Asynchronous Javascript And XML(异步 JavaScript 和 XML)
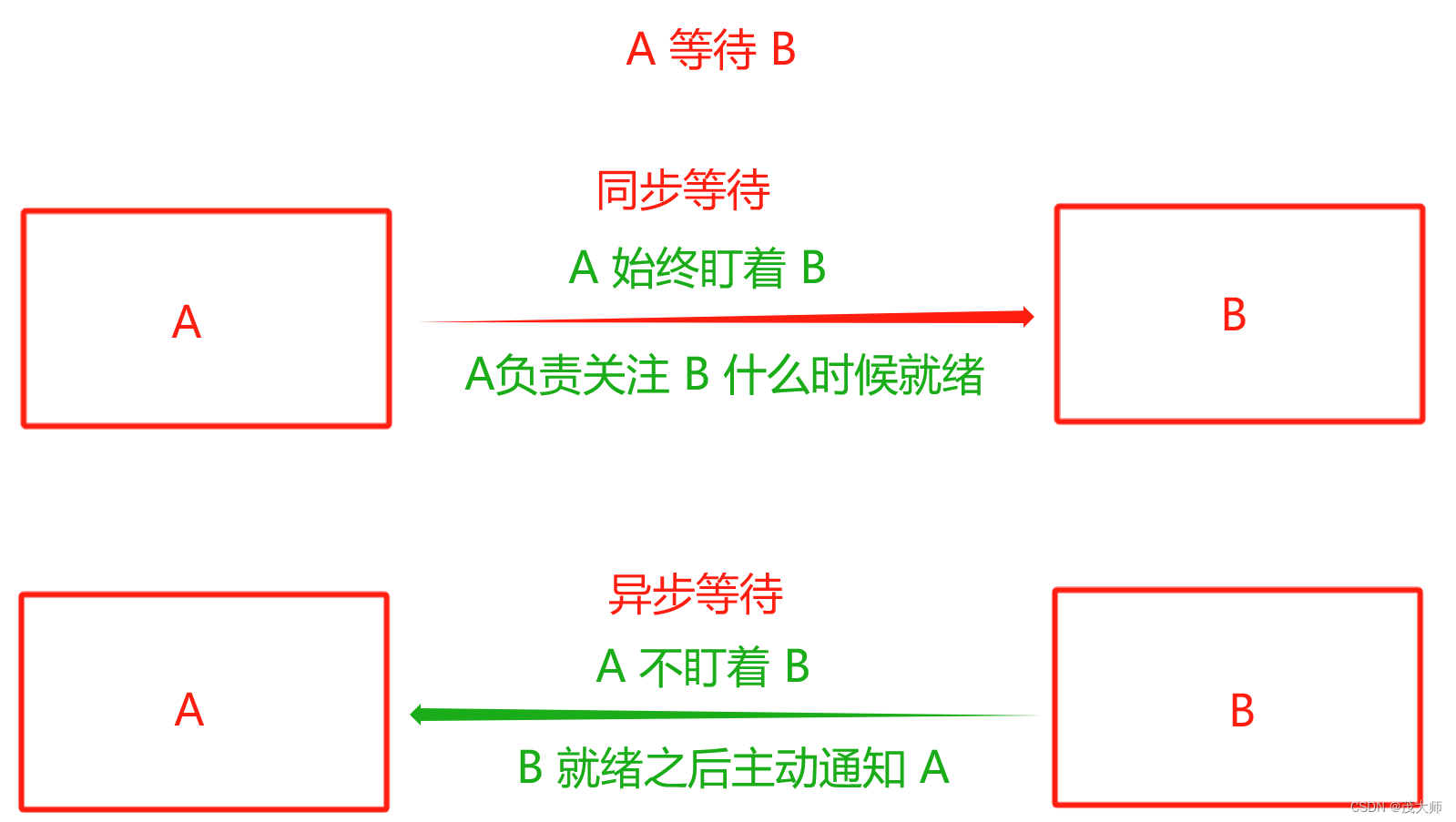
理解 Asynchronous (异步)
- 在 HTML 中,使用 AJAX 构造发送 HTTP 请求,此时为异步等待
- 当执行完发送请求代码后,就可以立即往下执行剩下代码,而不必等待服务器响应回来,当服务器响应回来之后,再由浏览器通知到代码中
代码示例
- 此处我们引入 jquery 来进行 AJAX 请求的构造
- jquery 的 api 对原生 api 进行了封装,使用起来简便很多
步骤一:
步骤二:
步骤三:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <!-- 引入 jquery --> <script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.7.1/jquery.js"></script> <script> $.ajax({ type:'get', url:'https://www.baidu.com?studentName=lisi', // 此处 success 就声明了一个回调函数,就会在服务器响应返回到浏览器的时候触发该回调 // 正是此处的 回调 体现了 "异步" success: function(data) { console.log("在服务器返回响应到达浏览器之前,浏览器触发该回调,通知到代码中!") } }); console.log("浏览器立即往下执行后续代码!"); </script> </body> </html>
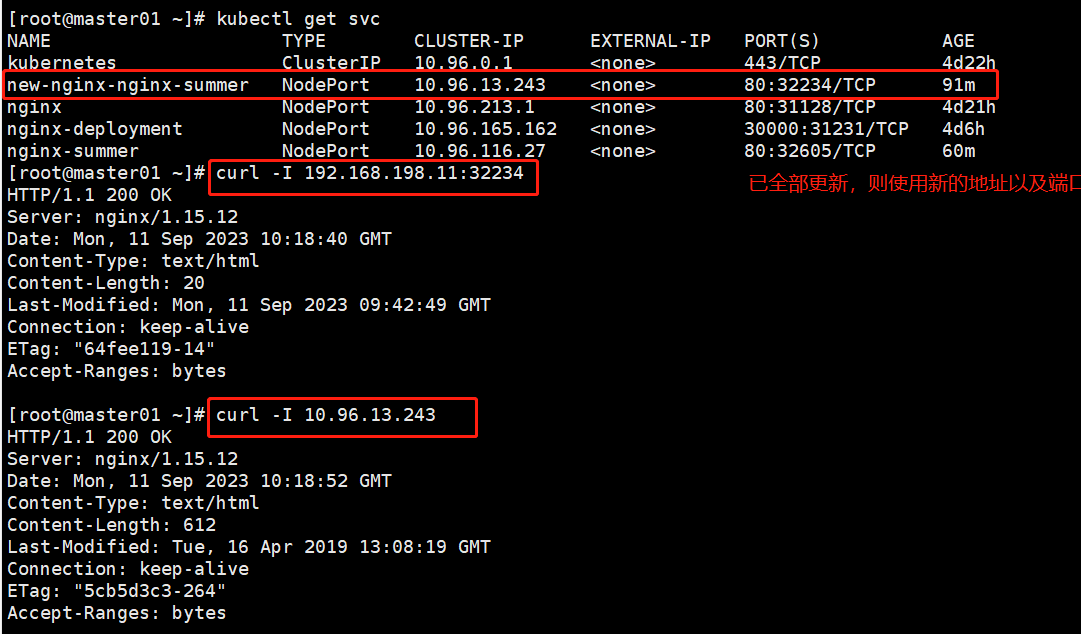
- 我们使用 Fiddle 将我们构造的请求进行抓包
注意:
- AJAX 的功能更强,不仅支持 GET 和 POST,同时也支持 DELETE、PUT 等方法
- AJAX 构造的请求可以灵活设置 header
- AJAX 发送请求的 正文body 也可以灵活设置
Postman 构造
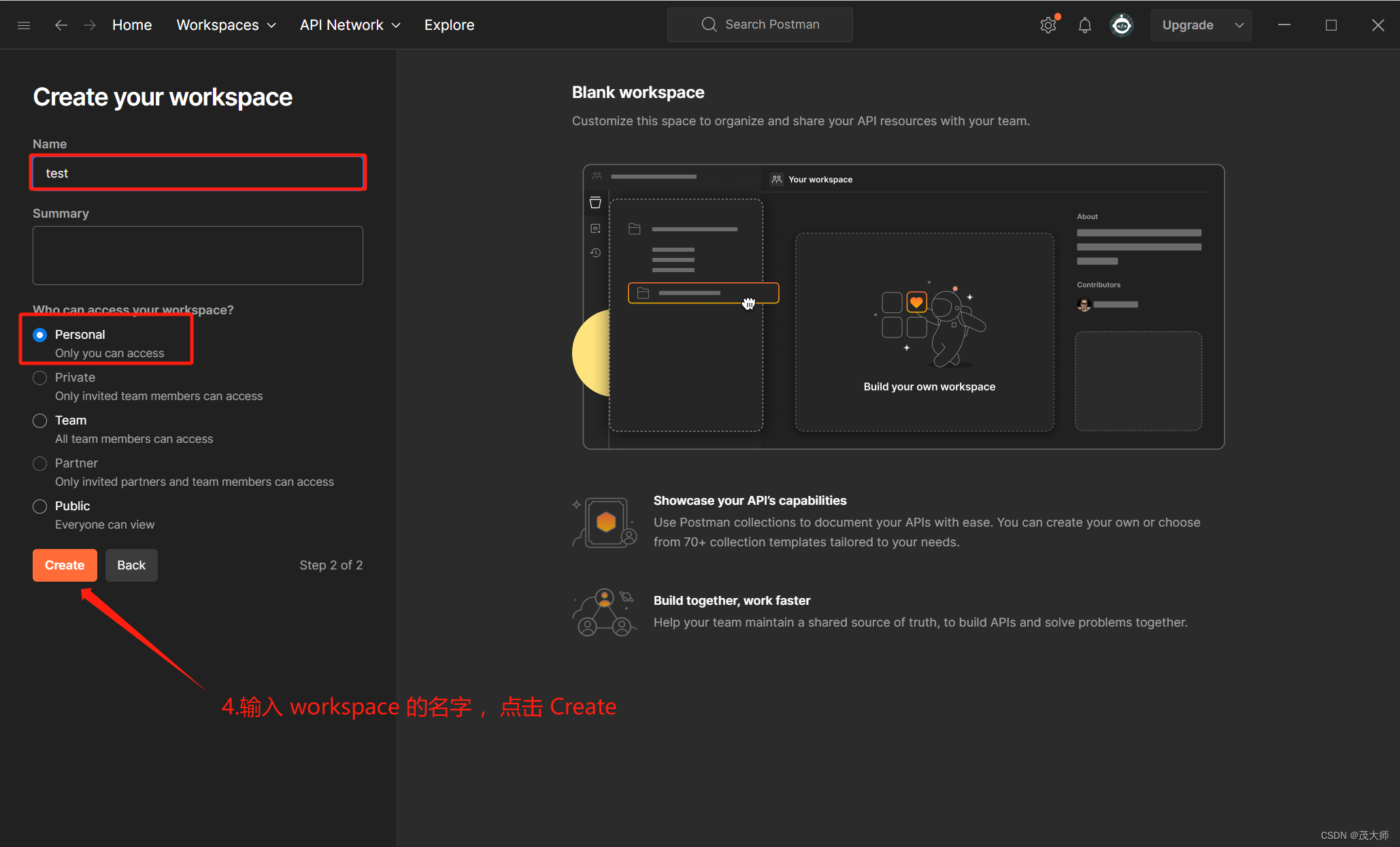
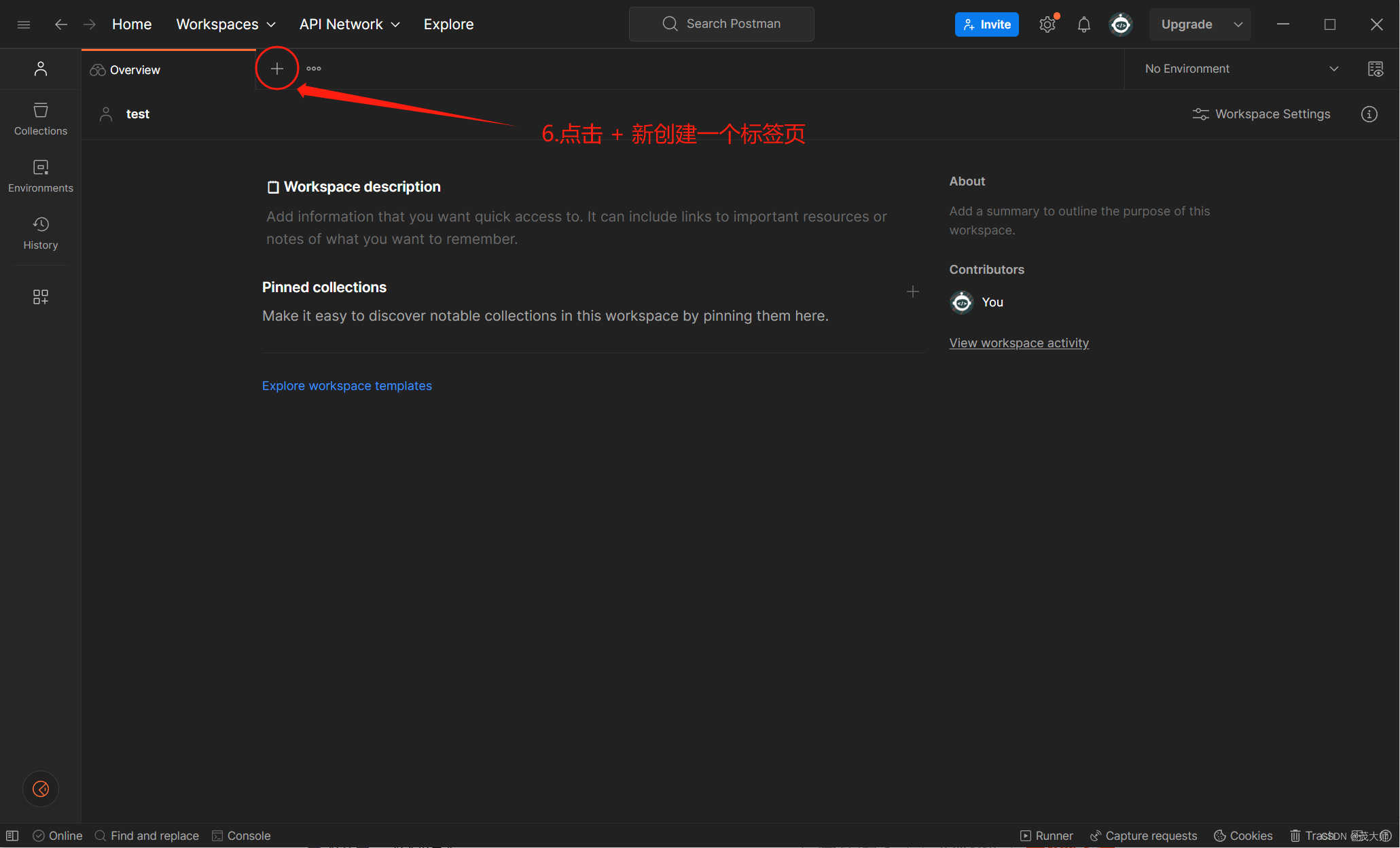
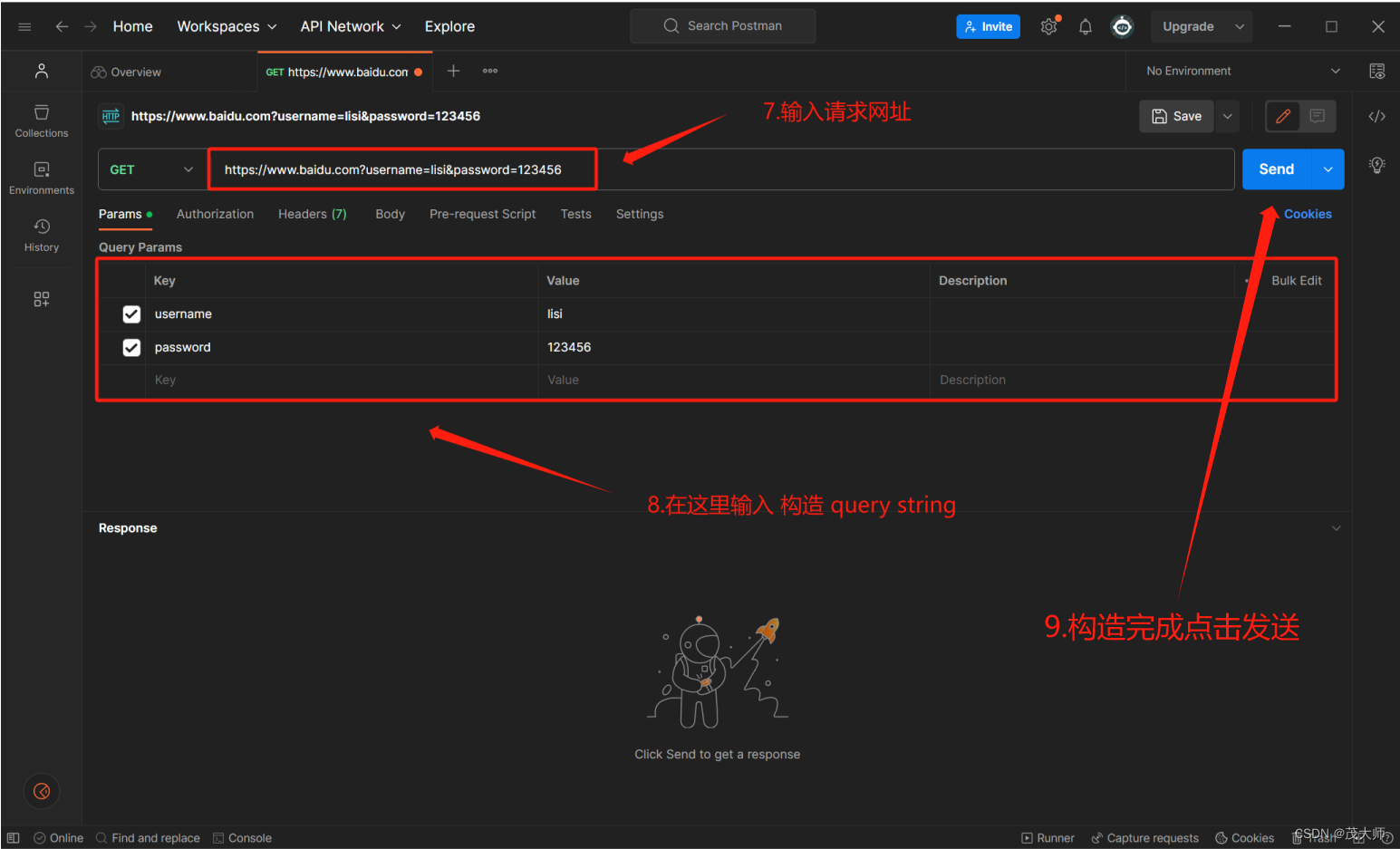
- 使用第三方工具,更加便捷的构造 HTTP 请求
步骤一:
步骤二:
步骤三:打开安装好的 Postman,先进行注册登录,在进行下面步骤
步骤四:
步骤五:
步骤六:
步骤七:
- 完成以上步骤,我们便可以使用 Postman 来构造一个 HTTP 请求了!
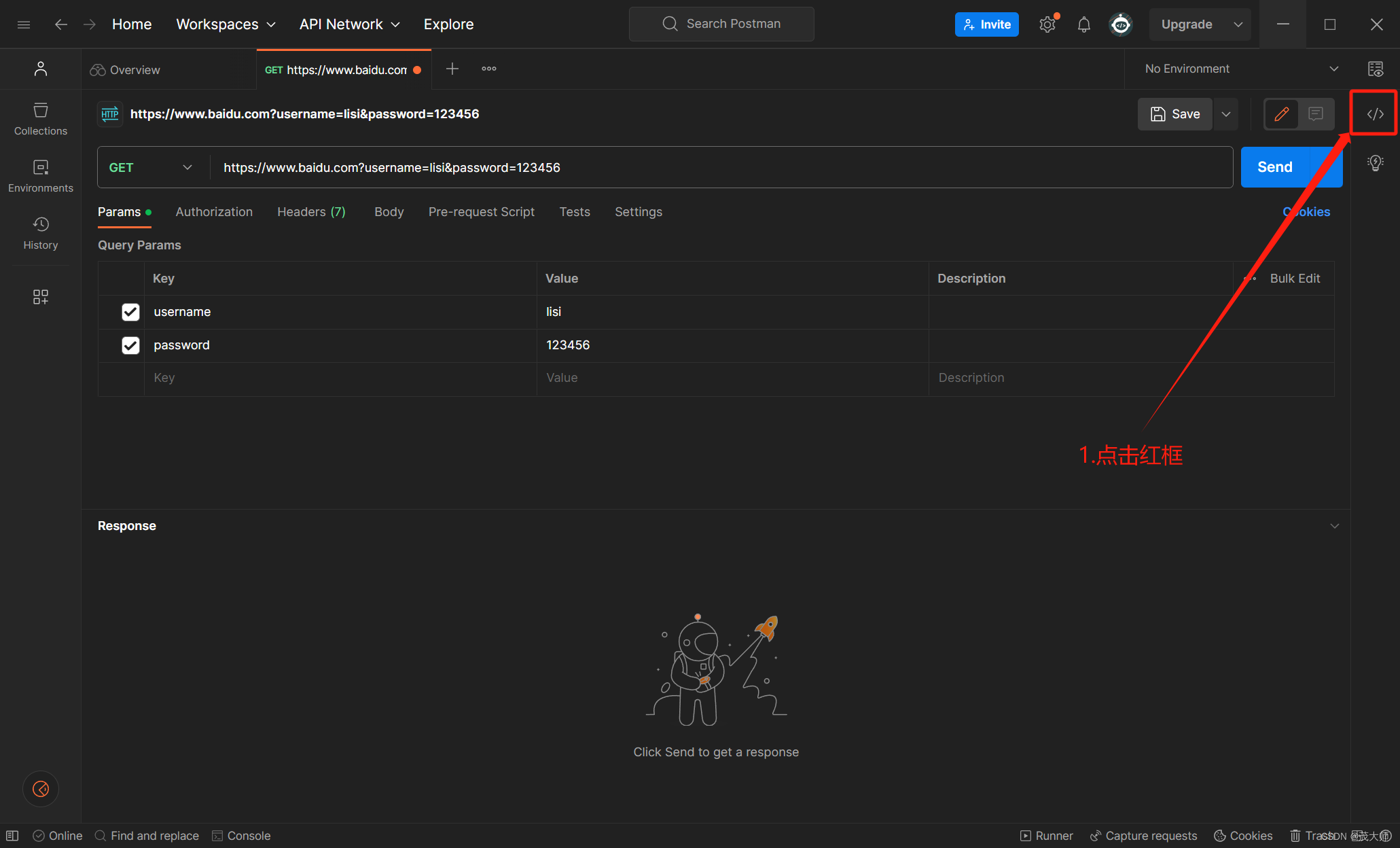
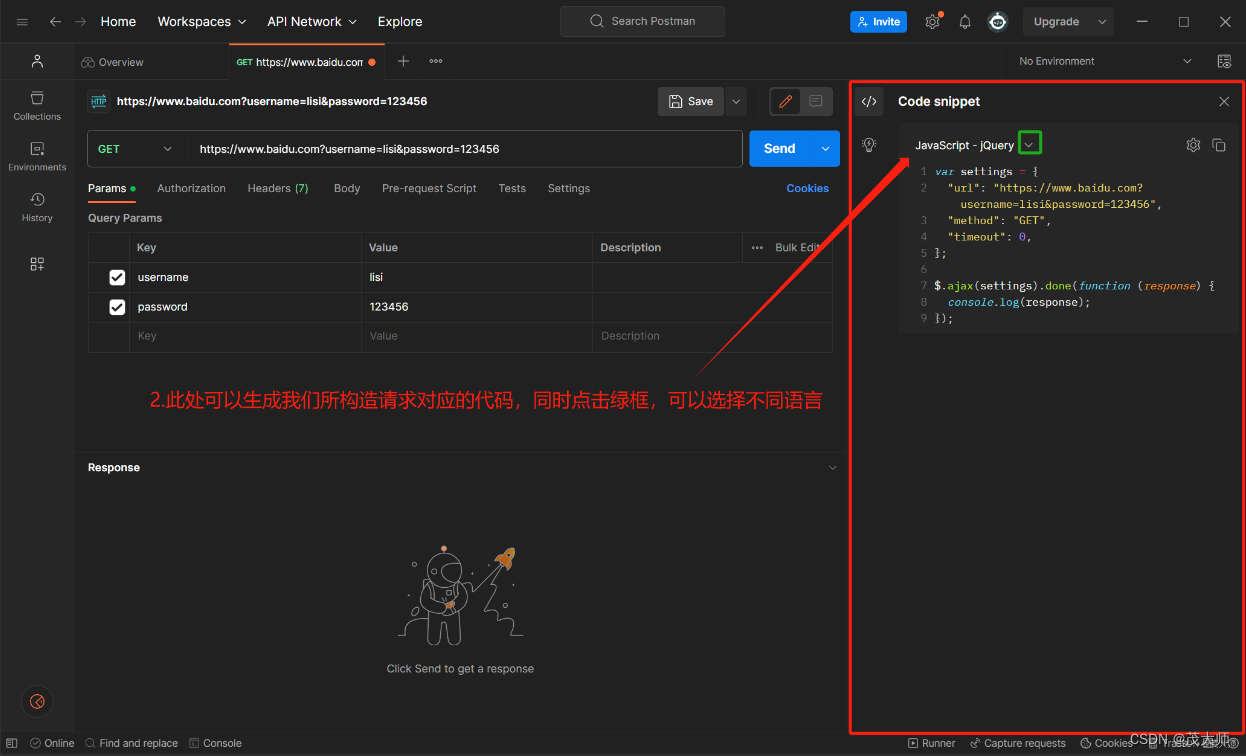
注意:
- Postman 还有一个很好用的功能,可以生成构造请求的对应代码
步骤一:
步骤二: