Base 64概述和应用场景
概述
Base64就是将二进制数据转换为字符串的一种算法。
应用场景
- 邮件编码
xml或则json存储二进制内容- 网页传递数据
URL - 数据库中以文本形式存放二进制数据
- 可打印的比特币钱包地址
base58Check(hash校验) - 网页上可以将图片直接使用
Base64表达 - 公私密钥的文本文件
Base16(16进制)
Base16是4位, 一个Unicode字符编码需要8位 ,那就需要将一个字符分解成2部分。编码字节的值,对应Base64的值如下对照表:
| 字节值 | Base64编码 |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
| 6 | 6 |
| 7 | 7 |
| 8 | 8 |
| 9 | 9 |
| 10 | A |
| 11 | B |
| 12 | C |
| 13 | D |
| 14 | E |
| 15 | F |
从零开始实现Base16编解码
代码如下:
#include <iostream>
using namespace std;
static const char BASE16_ENC_TAB[] = "0123456789ABCDEF";
// '0'~'9' => 48~57, 'A'~'E' => 65~70
static const char BASE16_DEC_TAB[128] =
{
-1, // 0
-1, -1, -1, -1, -1,-1, -1, -1, -1, -1, // 1-10
-1, -1, -1, -1, -1,-1, -1, -1, -1, -1, // 11-20
-1, -1, -1, -1, -1,-1, -1, -1, -1, -1, // 21-30
-1, -1, -1, -1, -1,-1, -1, -1, -1, -1, // 31-40
-1, -1, -1, -1, -1,-1, -1, 0, 1, 2, // 41-50
3, 4, 5, 6, 7, 8, 9, -1, -1, -1, // 51-60
-1, -1, -1, -1, 10, 11, 12, 13, 14, 15, // 61-70 'A'~'F'
};
int Base16Encode(const unsigned char* in, int size, char* out)
{
for (int i = 0; i < size; i++)
{
//1 一个字节取出高4位和低4位
char h = (in[i] >> 4) ; // 以为
char l = (in[i] & 0x0f); // 0000 1111 //去掉高4位
// 0~15映射到对应的字符
out[i * 2] = BASE16_ENC_TAB[h];
out[i * 2 + 1] = BASE16_ENC_TAB[l];
}
// base 16转码后空间扩大一倍 4位转成一个字符 1字节转成两个字符
return size * 2;
}
/**
* 将Base16字符转换成常规字符串
*/
int Base16Decode(const string &in, unsigned char* out)
{
// 将两个字符拼成一个字节
for (int i = 0; i < in.size(); i+=2)
{
unsigned char ch = in[i]; //高位转换的字符
unsigned char lh = in[i + 1]; // 低位转换的字符
// 上面拿到的还是个字符, 要转换成原始的数据
unsigned char h = BASE16_DEC_TAB[ch];
unsigned char l = BASE16_DEC_TAB[lh];
//out[i/2] = (h <<4) + l;
out[i / 2] = h << 4 | l;
}
return in.size() / 2;
}
int main()
{
cout << "Test Base16" << endl;
const unsigned char data[] = "测试Base16";
int len = sizeof(data);
char out1[1024] = { 0 };
int res = Base16Encode(data, len, out1);
cout << res << ":" << out1 << endl;
string code(out1);
unsigned char out2[1024] = { 0 };
res = Base16Decode(code, out2);
cout << res << ":" << out2 << endl;
return 0;
}
Base64(64进制)
首先查看Base64的值码对应表
| 字节值 | Base64编码 | 字节值 | Base64编码 | 字节值 | Base64编码 | 字节值 | Base64编码 | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w | |||
| 1 | B | 17 | R | 33 | h | 49 | x | |||
| 2 | C | 18 | S | 34 | i | 50 | y | |||
| 3 | D | 19 | T | 35 | j | 51 | z | |||
| 4 | E | 20 | U | 36 | k | 52 | 0 | |||
| 5 | F | 21 | V | 37 | l | 53 | 1 | |||
| 6 | G | 22 | W | 38 | m | 54 | 2 | |||
| 7 | H | 23 | X | 39 | n | 55 | 3 | |||
| 8 | I | 24 | Y | 40 | o | 56 | 4 | |||
| 9 | J | 25 | Z | 41 | p | 57 | 5 | |||
| 10 | K | 26 | a | 42 | q | 58 | 6 | |||
| 11 | L | 27 | b | 43 | t | 59 | 7 | |||
| 12 | M | 28 | c | 44 | s | 60 | 8 | |||
| 13 | N | 29 | d | 45 | t | 61 | 9 | |||
| 14 | O | 30 | e | 46 | u | 62 | + | |||
| 15 | P | 31 | f | 47 | v | 63 | / |
Base64编码要求把3个8位字节(3*8=24), 之后在6位的前面补两个0, 形成8位一个字节的形式。如果剩下的字符不足3个字节, 则用0填充,输出字符使用=,因此编码后输出的文本末尾可能会出现1或2个=。
Open SSL BIO接口
BIO包含了多种接口,用于控制在BIO_METHOD中不同实现函数, 包括6种filter型和8种source/sink型应用场景。- BIO_new创建一个BIO对象.
- 数据源:
source/sink类型的BIO是数据源BIO_new(BIO_s_mem()),生存内存是数据源对象 - 过滤:filter BIO就是把数据从一个BIO转换到另外一个BIO或应用接口 BIO_new(BIO_f_base64())
- BIO链:一个BIO链通常包括一个source BIO和一个或多个filter BIO BIO_push(b64_bio, mem_bio);
- 写编码, 读解码 BIO_write BIO_read_ex
Open SSL BIO实现Base64编解码
#include <iostream>
#include <openssl/bio.h>
#include <openssl/evp.h>
#include <openssl/buffer.h>
using namespace std;
int Base64Encode(const unsigned char* in, int len, char* out_base64)
{
if (!in || len < 0 || !out_base64)
{
return 0;
}
//创建内存源
auto mem_bio = BIO_new(BIO_s_mem());
if (!mem_bio) return 0;
// base64 filter
auto b64_bio = BIO_new(BIO_f_base64());//这个接口在头文件 evp.h
if (!b64_bio)
{
BIO_free(mem_bio); //释放申请成功的空间
return 0;
}
// 形成BIO链表
//b64-mem
// 形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果
BIO_push(b64_bio, mem_bio); // 2个链表(从链表头部,代表整个链表)
//write 是编码 3字节 => 4字节 不足3字节补充0 和等于号
int re = BIO_write(b64_bio, in, len); //将数据写入到链表头
if (re < 0)
{
// 写入失败, 清空整个链表节点
BIO_free_all(b64_bio);
return 0;
}
// 刷新缓存, 写入链表的mem
BIO_flush(b64_bio);
// 从链表源内存读取
BUF_MEM* p_data = nullptr; // 需要引入
BIO_get_mem_ptr(b64_bio, &p_data); //拿到编码数据了
int out_size = 0;
if (p_data)
{
memcpy(out_base64, p_data->data, p_data->length);
out_size = p_data->length;
}
//执行完后, 清理空间
BIO_free_all(b64_bio);
return out_size;
}
int Base64Decode(const char* in, int len, unsigned char* out_data)
{
if (!in || len <= 0 || !out_data)
{
return 0;
}
// 内存源
auto mem_bio = BIO_new_mem_buf(in, len);
if (!mem_bio)
{
return 0;
}
// base64 过滤器
auto b64_bio = BIO_new(BIO_f_base64());
if (!b64_bio)
{
BIO_free(mem_bio);
return 0;
}
//形成BIO链条
BIO_push(b64_bio, mem_bio);
//读取 解码 4字节转3字节
size_t size = 0;
BIO_read_ex(b64_bio, out_data, len, &size);
BIO_free_all(b64_bio);
return size;
}
int main(int argc, char argv[])
{
cout << "Test openssl BIO base64" << endl;
unsigned char data[] = "测试Base64数据";
int len = sizeof(data);
char out[1024];
int ret = Base64Encode(data, len, out);
if (ret)
{
out[ret] = '\0';
}
cout << "base64:" << out << endl;
unsigned char out_data[1024] = { 0 };
//ret = Base64Decode(out, sizeof(out), out_data);// 这里不能用sizeof() , 用计算字符长度
ret = Base64Decode(out, strlen(out), out_data);
cout << "encode :" << out_data << endl;
}
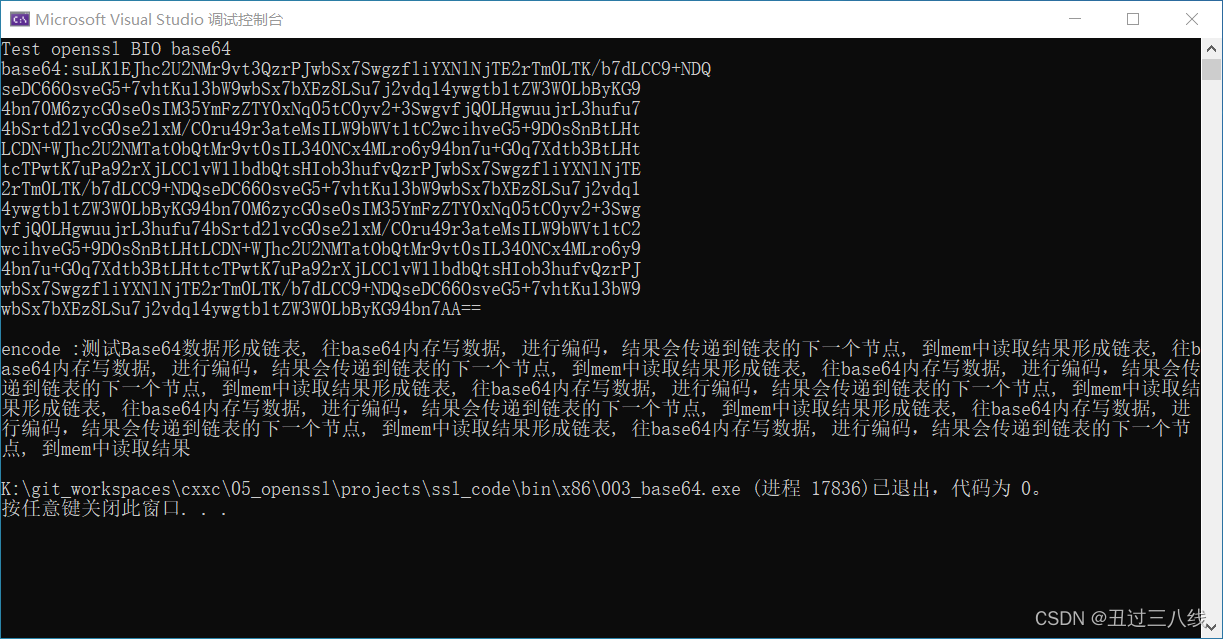
Open SSL做Base64编码换行
Open SSL做Base64在做编码操作的时候,默认情况下遇到64字节(不同平台不确定,)的时候就会进行换行操作。
例如将上面的输入内容改得过长.
unsigned char data[] = "测试Base64数据形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果";
执行的编码结果就会出现换行操作, 如下图所示:
只需要在写入待编码码内容前进行参数设置,就可以使其不换行
//超过长度不还行
BIO_set_flags(b64_bio, BIO_FLAGS_BASE64_NO_NL);
编码方法的整体代码如下:
int Base64Encode(const unsigned char* in, int len, char* out_base64)
{
if (!in || len < 0 || !out_base64)
{
return 0;
}
//创建内存源
auto mem_bio = BIO_new(BIO_s_mem());
if (!mem_bio) return 0;
// base64 filter
auto b64_bio = BIO_new(BIO_f_base64());//这个接口在头文件 evp.h
if (!b64_bio)
{
BIO_free(mem_bio); //释放申请成功的空间
return 0;
}
// 形成BIO链表
//b64-mem
// 形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果
BIO_push(b64_bio, mem_bio); // 2个链表(从链表头部,代表整个链表)
//超过长度不还行
BIO_set_flags(b64_bio, BIO_FLAGS_BASE64_NO_NL);
//write 是编码 3字节 => 4字节 不足3字节补充0 和等于号
//编码数据每64直接会加一个\n换行符号,并且结尾时也有换行符号
int re = BIO_write(b64_bio, in, len); //将数据写入到链表头
if (re < 0)
{
// 写入失败, 清空整个链表节点
BIO_free_all(b64_bio);
return 0;
}
// 刷新缓存, 写入链表的mem
BIO_flush(b64_bio);
// 从链表源内存读取
BUF_MEM* p_data = nullptr; // 需要引入
BIO_get_mem_ptr(b64_bio, &p_data); //拿到编码数据了
int out_size = 0;
if (p_data)
{
memcpy(out_base64, p_data->data, p_data->length);
out_size = p_data->length;
}
//执行完后, 清理空间
BIO_free_all(b64_bio);
return out_size;
}
执行结果,如下,编码的内容已经不会再换行了。
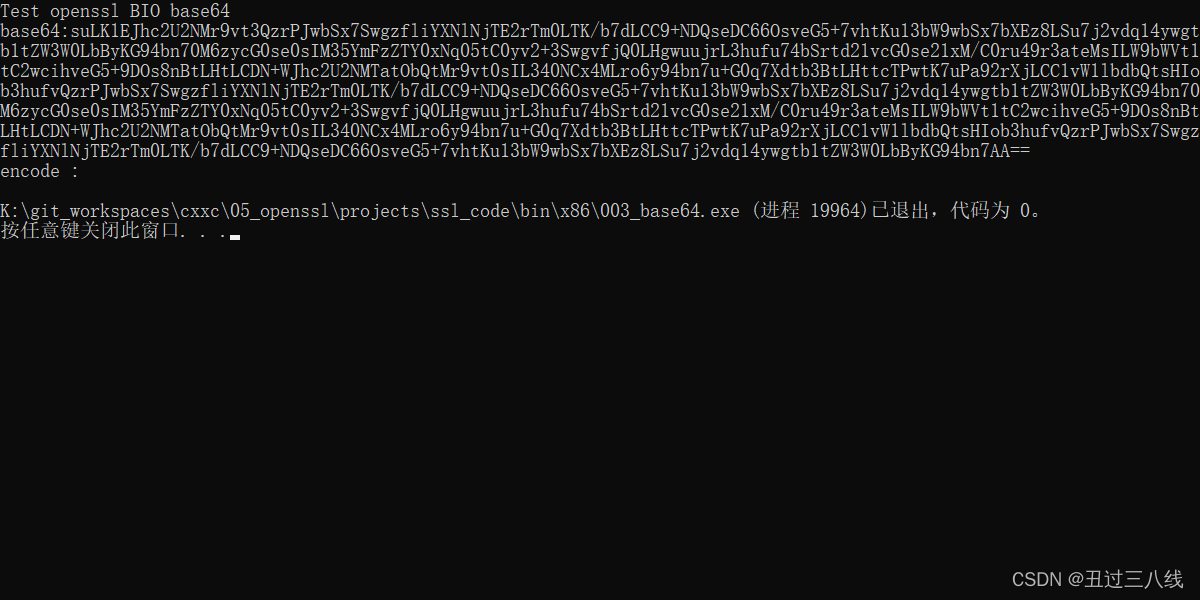
从上可以看出, 如果没有了末尾的换行符号。解码的时候又出现无法解码的问题, 因为解码是按照末尾的\n来执行结尾的。因为如下,如果我再编码内容的后面加上\n即可正确的进行解码操作了.
int main(int argc, char argv[])
{
cout << "Test openssl BIO base64" << endl;
unsigned char data[] = "测试Base64数据形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果形成链表, 往base64内存写数据, 进行编码,结果会传递到链表的下一个节点, 到mem中读取结果";
int len = sizeof(data);
char out[1024];
int ret = Base64Encode(data, len, out);
if (ret)
{
out[ret] = '\0';
}
cout << "base64:" << out << endl;
// 手动加下行结尾的符号
out[ret] = '\n';
out[ret+1] = '\0';
unsigned char out_data[1024] = { 0 };
//ret = Base64Decode(out, sizeof(out), out_data);// 这里不能用sizeof() , 用计算字符长度
ret = Base64Decode(out, strlen(out), out_data);
cout << "encode :" << out_data << endl;
}
另外一种解决办法就是直接也在解码代码中也加上对换行符号的忽略.
int Base64Decode(const char* in, int len, unsigned char* out_data)
{
if (!in || len <= 0 || !out_data)
{
return 0;
}
// 内存源
auto mem_bio = BIO_new_mem_buf(in, len);
if (!mem_bio)
{
return 0;
}
// base64 过滤器
auto b64_bio = BIO_new(BIO_f_base64());
if (!b64_bio)
{
BIO_free(mem_bio);
return 0;
}
//形成BIO链条
BIO_push(b64_bio, mem_bio);
//取消默认读取换行符号做结束的操作
BIO_set_flags(b64_bio, BIO_FLAGS_BASE64_NO_NL);
//读取 解码 4字节转3字节
size_t size = 0;
BIO_read_ex(b64_bio, out_data, len, &size);
BIO_free_all(b64_bio);
return size;
}
执行的结果都可以OK了。
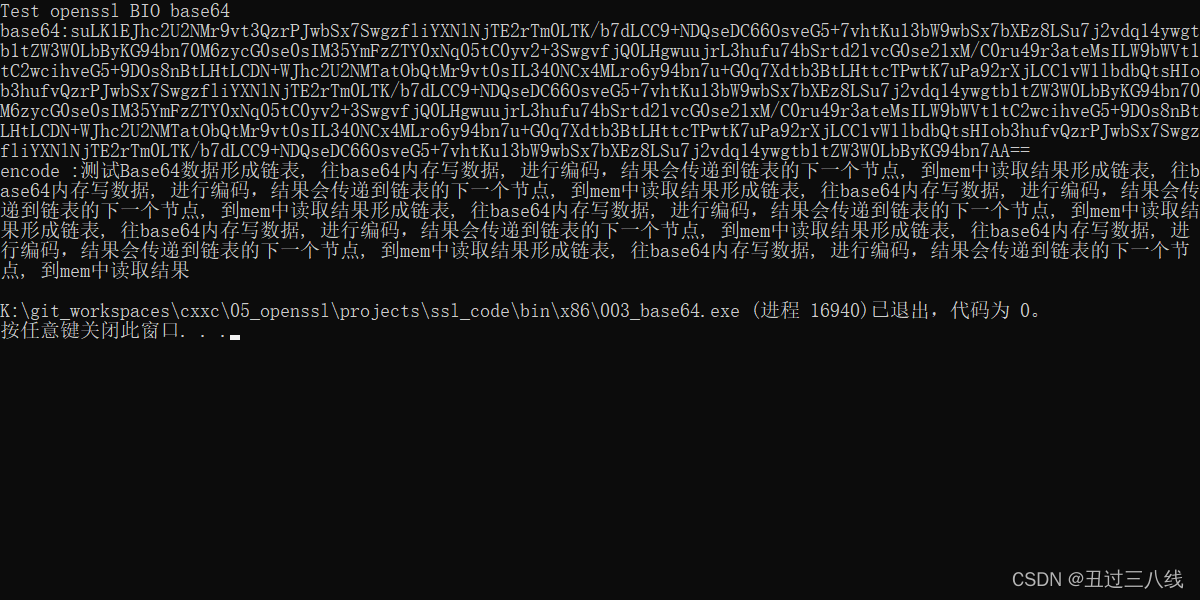
综上问题, 编解码必须要一致。
Base58
由于Base64的方式存在一些问题,比如+,/在一些传输内容时容易出现特殊字符问题,还有0/O/o, l(小写母L),I(大写字母i)在某些情况下肉眼不易区分。Base58去掉了0(数字0)、 O(大写字母o)、l(小写字母L)、I(大写字母i),以及两个特殊字符+,/.一共去掉了6个字符,就剩下了58个字符。
| 字节值 | Base58编码 | 字节值 | Base58编码 | 字节值 | Base58编码 | 字节值 | Base58编码 | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 16 | H | 32 | Z | 48 | q | |||
| 1 | 2 | 17 | J | 33 | a | 49 | r | |||
| 2 | 3 | 18 | K | 34 | b | 50 | s | |||
| 3 | 4 | 19 | L | 35 | c | 51 | t | |||
| 4 | 5 | 20 | M | 36 | d | 52 | u | |||
| 5 | 6 | 21 | N | 37 | e | 53 | v | |||
| 6 | 7 | 22 | P | 38 | f | 54 | w | |||
| 7 | 8 | 23 | Q | 39 | g | 55 | x | |||
| 8 | 9 | 24 | R | 40 | h | 56 | y | |||
| 9 | A | 25 | S | 41 | i | 57 | z | |||
| 10 | B | 26 | T | 42 | j | |||||
| 11 | C | 27 | U | 43 | k | |||||
| 12 | D | 28 | V | 44 | m | |||||
| 13 | E | 29 | W | 45 | n | |||||
| 14 | F | 30 | X | 46 | o | |||||
| 15 | G | 31 | Y | 47 | p |
辗转相除法
- 两个数的最大公约数等于它们中较小的数和两数只差的最大公约数
- 欧几里德算法,是求最大公约数的算法
- 两个数的最大公约数是指同时整除它们的最大正整数。辗转相除法的基本原理是两个数的最大公约数等于它们中较小的数和两数只差的最大公约数。
- 如果要将1234转换成58进制;
- 1234 除以 58 ,商21, 余数为16,查表得
H。 - 用21除以58, 商0, 余数为21, 查表得
N。 - 如果待转的数前面又0直接附加编码1来代表,有多少个就附加多少个。
Base56输出字节数
- 在编码后字符串中, 是从58个字符中选择,需要表示的位数是 l o g 2 58 log_{2}58 log258, 每一个字母代表的信息是 l o g 2 58 log_{2}58 log258.
- 输入的字节: (length *8)位。
- 预留的字符数量就是 ( l e n g t h ∗ 8 ) / l o g 2 58 (length*8)/log_{2}58 (length∗8)/log258